
DataPipeline丨「自定义」数据源,解决复杂请求逻辑外部数据获取难题
A公司专注为各种规模和复杂程度的金融投资机构提供一体化投资管理系统,系统主要由投资组合管理、交易执行管理、实时监控管理、风险管理等功能模块构成。随着企业管理产品数量的不断增多,大量数据分散在各券商系统中且数据存储格式各异,难以管理和利用。
为帮助投资机构最大限度地提高投资决策和运营效率,A公司需要实时监控自己的用户在各个交易平台的基本信息、余额、订单交易情况,并根据分析结果及时给出投资建议。
A公司的这种情况并不是个例。目前,越来越多的企业在数据传输的需求场景中,除了从上游不同业务数据库中实时、定时分配到下游系统之外,还有许多需求场景需要从外部合作商、供应商中获取业务数据。
如果想要每天从企业外部系统中获取数据,通常会采用什么方法呢?
一些用户给出的答案是:根据需要编写不同的脚本,手动调用第三方系统提供的API接口,在抓取数据后,自行编写清洗逻辑,最后实现数据落地。
然而随着第三方系统的日益增多,如果按原有方式会带来过多的脚本维护成本和数据传输任务管理成本。为解决上述痛点,DataPipeline在新版本的数据同步任务中增加了「自定义数据源」功能,用户可以通过上传JAR包的方式自定义获取数据逻辑。新功能支持任意的MySQL、Oracle、SQLServer、Hive、HBase等常见数据源,冷门数据库等(如腾讯云TDSQL),常用的API调用,用户自定义的SDK,或者通过Python抓取数据等。
一、「自定义数据源」提供的价值
通过「自定义数据源」,用户可以:
- 统一管理数据获取逻辑,快速合并JAR减少脚本开发量。
- 当上游发生变化时,不需要对每一个数据传输任务进行调整。
- 可结合DataPipeline的数据解析功能、清洗工具和目标初始化功能减少整体开发量,并提供监控和预警。
二、如何使用「自定义数据源」功能
用户可通过以下四步使用「自定义数据源」功能:
- 创建自定义数据源,并上传JAR包(或调取已上传过的JAR包)。
- 选择数据存放的目的地。
- 使用清洗工具完成数据解析逻辑。
- 配置目的地表结构,即可完成所有配置。
关于「自定义数据源」的核心页面:
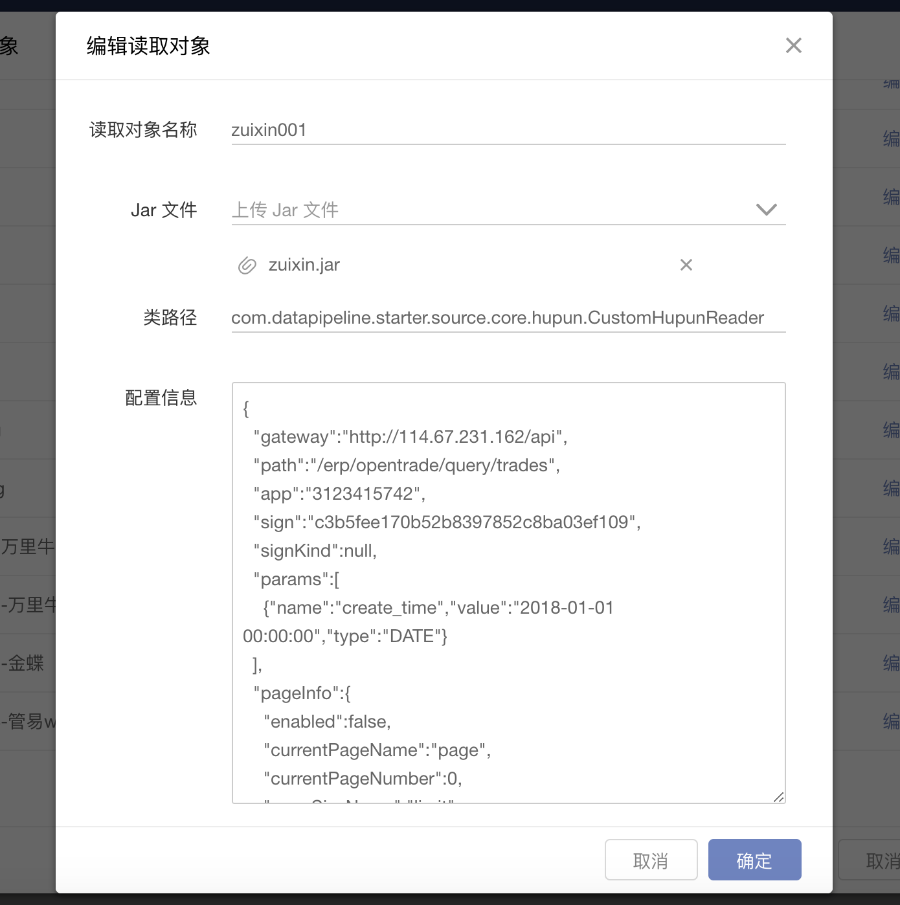
1. 用户在选择自定义数据源和目的地后,需要在读取设置步骤中上传JAR包
- 用户可以上传新的JAR包,也可以点击拖放框选择历史已经上传的JAR用作本次任务。
- 用户通过填充类路径和读取数据所需要的配置信息即可完成数据源读取逻辑。
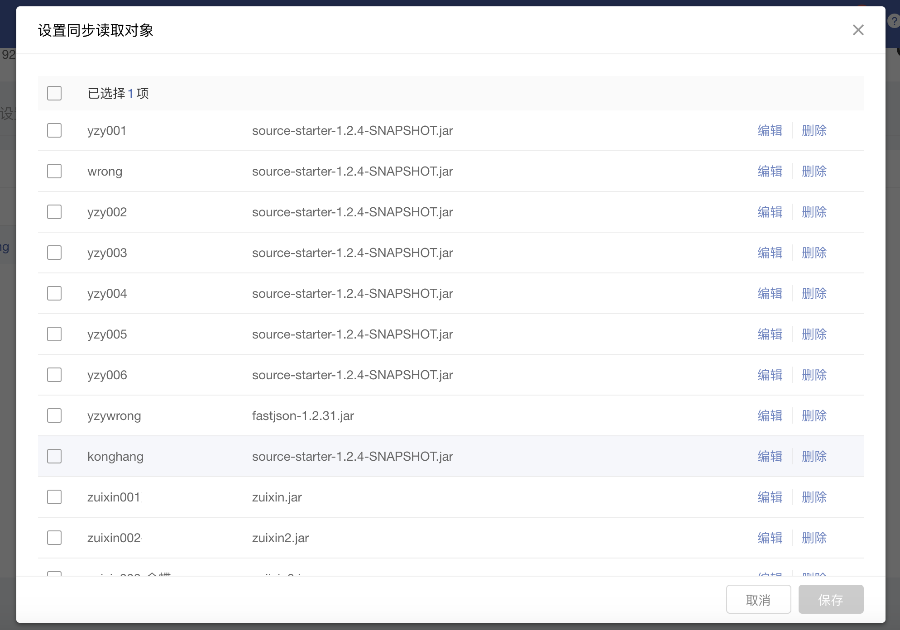
2. 用户可以在一个任务中选择一个或多个读取对象,每个读取对象可以映射到目标表的表中
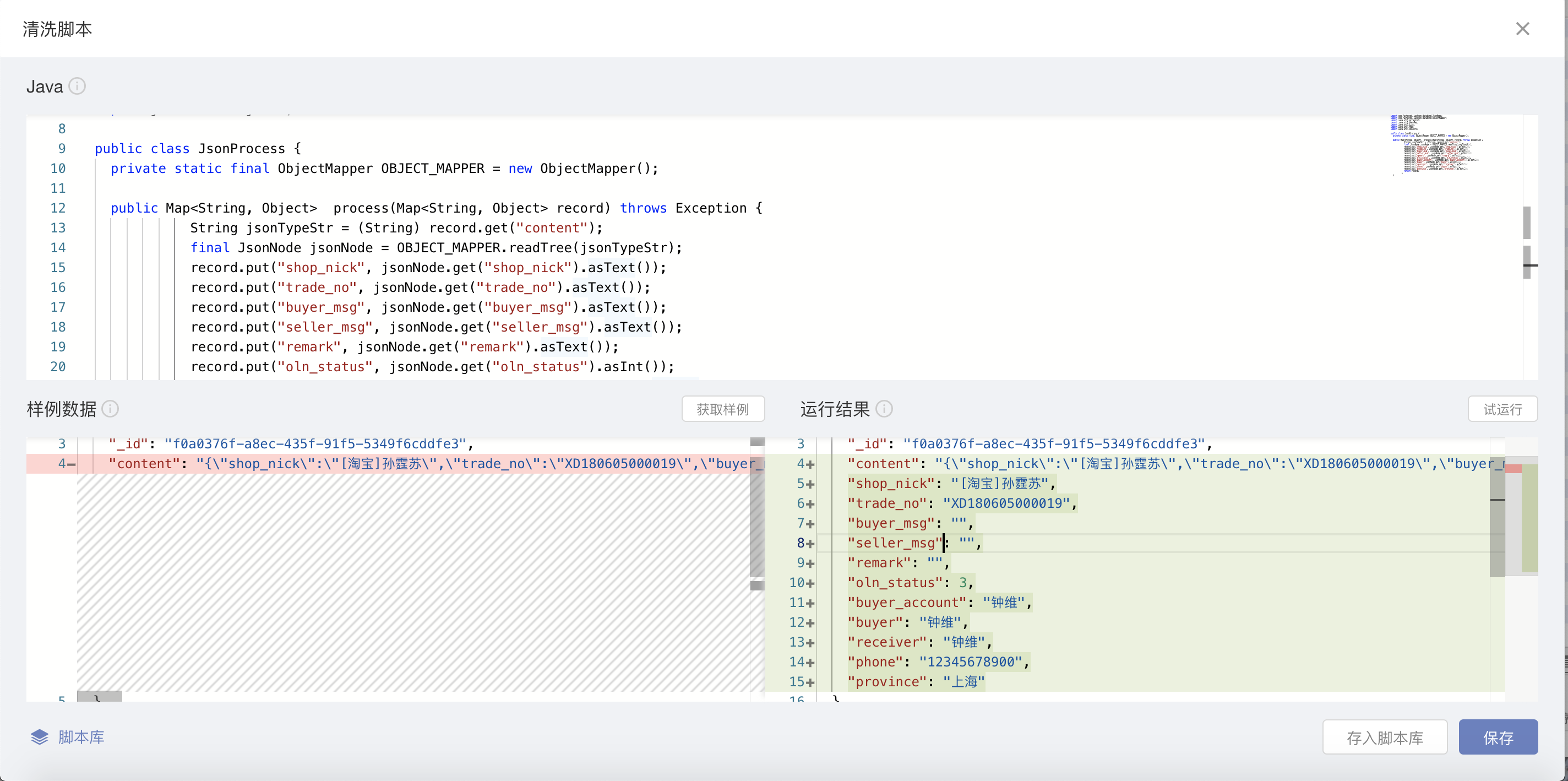
3. 完成读取设置后,在写入设置步骤中先确定每个读取对象的数据解析逻辑
- DataPipeline会提供JSON解析样例,用户也可以参考样例,自定义解析逻辑。
- 「样例数据」模块会显示通过读取对象配置获取的数据。
- 完成清洗脚本内容后,在「运行结果」模块点击「试运行」即可看到最终写入到目的地的数据格式。
4. 完成解析逻辑后,用户可以手动添加名称并选择对应的数据类型 ,来完成目的地表结构

完成所有配置后点击「立即激活」即可执行数据传输任务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号