吴恩达深度学习笔记 course4 week1 作业2
Residual Networks
Welcome to the second assignment of this week! You will learn how to build very deep convolutional networks, using Residual Networks (ResNets). In theory, very deep networks can represent very complex functions; but in practice, they are hard to train. Residual Networks, introduced by He et al., allow you to train much deeper networks than were previously practically feasible.
In this assignment, you will:
- Implement the basic building blocks of ResNets.
- Put together these building blocks to implement and train a state-of-the-art neural network for image classification.
This assignment will be done in Keras.
Before jumping into the problem, let's run the cell below to load the required packages.
import numpy as np
from keras import layers
from keras.layers import Input, Add, Dense, Activation, ZeroPadding2D, BatchNormalization, Flatten, Conv2D, AveragePooling2D, MaxPooling2D, GlobalMaxPooling2D
from keras.models import Model, load_model
from keras.preprocessing import image
from keras.utils import layer_utils
from keras.utils.data_utils import get_file
from keras.applications.imagenet_utils import preprocess_input
import pydot
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
from keras.utils import plot_model
from resnets_utils import *
from keras.initializers import glorot_uniform
import scipy.misc
from matplotlib.pyplot import imshow
%matplotlib inline
import keras.backend as K
K.set_image_data_format('channels_last')
K.set_learning_phase(1)
1 - The problem of very deep neural networks
Last week, you built your first convolutional neural network. In recent years, neural networks have become deeper, with state-of-the-art networks going from just a few layers (e.g., AlexNet) to over a hundred layers.
The main benefit of a very deep network is that it can represent very complex functions. It can also learn features at many different levels of abstraction, from edges (at the lower layers) to very complex features (at the deeper layers). However, using a deeper network doesn't always help. A huge barrier to training them is vanishing gradients: very deep networks often have a gradient signal that goes to zero quickly, thus making gradient descent unbearably slow. More specifically, during gradient descent, as you backprop from the final layer back to the first layer, you are multiplying by the weight matrix on each step, and thus the gradient can decrease exponentially quickly to zero (or, in rare cases, grow exponentially quickly and "explode" to take very large values).
During training, you might therefore see the magnitude (or norm) of the gradient for the earlier layers descrease to zero very rapidly as training proceeds:

The speed of learning decreases very rapidly for the early layers as the network trains
You are now going to solve this problem by building a Residual Network!
2 - Building a Residual Network
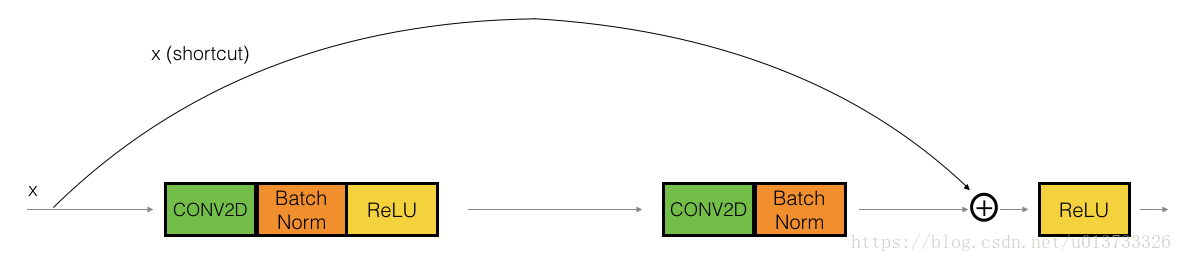
In ResNets, a "shortcut" or a "skip connection" allows the gradient to be directly backpropagated to earlier layers:

The image on the left shows the "main path" through the network. The image on the right adds a shortcut to the main path. By stacking these ResNet blocks on top of each other, you can form a very deep network.
We also saw in lecture that having ResNet blocks with the shortcut also makes it very easy for one of the blocks to learn an identity function. This means that you can stack on additional ResNet blocks with little risk of harming training set performance. (There is also some evidence that the ease of learning an identity function--even more than skip connections helping with vanishing gradients--accounts for ResNets' remarkable performance.)
Two main types of blocks are used in a ResNet, depending mainly on whether the input/output dimensions are same or different. You are going to implement both of them.
2.1 - The identity block
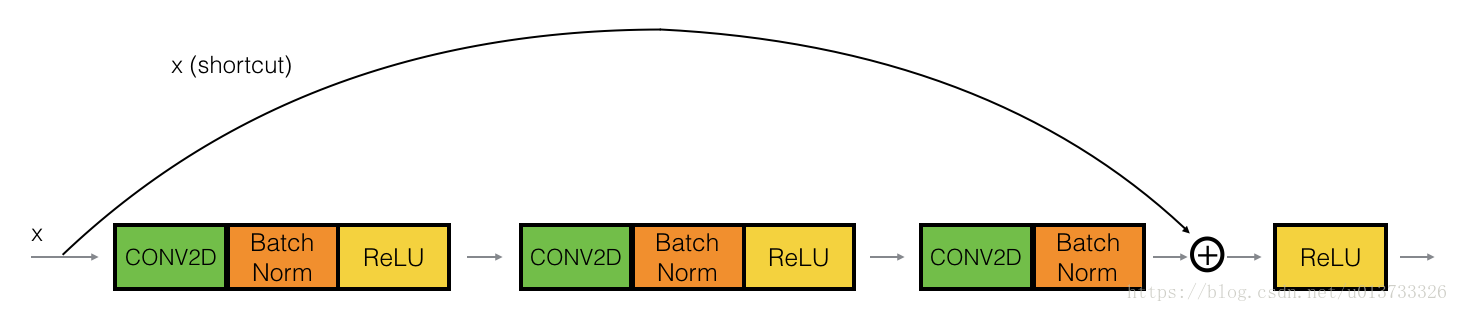
The identity block is the standard block used in ResNets, and corresponds to the case where the input activation (say a[l]a[l]) has the same dimension as the output activation (say a[l+2]a[l+2]). To flesh out the different steps of what happens in a ResNet's identity block, here is an alternative diagram showing the individual steps:

The upper path is the "shortcut path." The lower path is the "main path." In this diagram, we have also made explicit the CONV2D and ReLU steps in each layer. To speed up training we have also added a BatchNorm step. Don't worry about this being complicated to implement--you'll see that BatchNorm is just one line of code in Keras!
In this exercise, you'll actually implement a slightly more powerful version of this identity block, in which the skip connection "skips over" 3 hidden layers rather than 2 layers. It looks like this:

Here're the individual steps.
First component of main path:
- The first CONV2D has F1F1 filters of shape (1,1) and a stride of (1,1). Its padding is "valid" and its name should be
conv_name_base + '2a'. Use 0 as the seed for the random initialization. - The first BatchNorm is normalizing the channels axis. Its name should be
bn_name_base + '2a'. - Then apply the ReLU activation function. This has no name and no hyperparameters.
Second component of main path:
- The second CONV2D has F2F2 filters of shape (f,f)(f,f) and a stride of (1,1). Its padding is "same" and its name should be
conv_name_base + '2b'. Use 0 as the seed for the random initialization. - The second BatchNorm is normalizing the channels axis. Its name should be
bn_name_base + '2b'. - Then apply the ReLU activation function. This has no name and no hyperparameters.
Third component of main path:
- The third CONV2D has F3F3 filters of shape (1,1) and a stride of (1,1). Its padding is "valid" and its name should be
conv_name_base + '2c'. Use 0 as the seed for the random initialization. - The third BatchNorm is normalizing the channels axis. Its name should be
bn_name_base + '2c'. Note that there is no ReLU activation function in this component.
Final step:
- The shortcut and the input are added together.
- Then apply the ReLU activation function. This has no name and no hyperparameters.
Exercise: Implement the ResNet identity block. We have implemented the first component of the main path. Please read over this carefully to make sure you understand what it is doing. You should implement the rest.
- To implement the Conv2D step: See reference
- To implement BatchNorm: See reference (axis: Integer, the axis that should be normalized (typically the channels axis))
- For the activation, use:
Activation('relu')(X) - To add the value passed forward by the shortcut: See reference
# GRADED FUNCTION: identity_block
def identity_block(X, f, filters, stage, block):
"""
Implementation of the identity block as defined in Figure 3
Arguments:
X -- input tensor of shape (m, n_H_prev, n_W_prev, n_C_prev)
f -- integer, specifying the shape of the middle CONV's window for the main path
filters -- python list of integers, defining the number of filters in the CONV layers of the main path
stage -- integer, used to name the layers, depending on their position in the network
block -- string/character, used to name the layers, depending on their position in the network
Returns:
X -- output of the identity block, tensor of shape (n_H, n_W, n_C)
"""
# defining name basis
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
# Retrieve Filters
F1, F2, F3 = filters
# Save the input value. You'll need this later to add back to the main path.
X_shortcut = X
# First component of main path
X = Conv2D(filters = F1, kernel_size = (1, 1), strides = (1,1), padding = 'valid', name = conv_name_base + '2a', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2a')(X)
X = Activation('relu')(X)
### START CODE HERE ###
# Second component of main path (≈3 lines)
X = Conv2D(filters = F2, kernel_size = (f, f), strides = (1,1), padding = 'same', name = conv_name_base + '2b', kernel_initializer = glorot_uniform(seed=0))(X)
X =BatchNormalization(axis = 3, name = bn_name_base + '2b')(X)
X = Activation('relu')(X)
# Third component of main path (≈2 lines)
X = Conv2D(filters = F3, kernel_size = (1, 1), strides = (1,1), padding = 'same', name = conv_name_base + '2c', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2c')(X)
# Final step: Add shortcut value to main path, and pass it through a RELU activation (≈2 lines)
X = Add()([X,X_shortcut])
X = Activation('relu')(X)
### END CODE HERE ###
return X
tf.reset_default_graph()
with tf.Session() as test:
np.random.seed(1)
A_prev = tf.placeholder("float", [3, 4, 4, 6])
X = np.random.randn(3, 4, 4, 6)
A = identity_block(A_prev, f = 2, filters = [2, 4, 6], stage = 1, block = 'a')
test.run(tf.global_variables_initializer())
out = test.run([A], feed_dict={A_prev: X, K.learning_phase(): 0})
print("out = " + str(out[0][1][1][0]))
Expected Output:
| out | [ 0.94822985 0. 1.16101444 2.747859 0. 1.36677003] |
2.2 - The convolutional block
You've implemented the ResNet identity block. Next, the ResNet "convolutional block" is the other type of block. You can use this type of block when the input and output dimensions don't match up. The difference with the identity block is that there is a CONV2D layer in the shortcut path:

The CONV2D layer in the shortcut path is used to resize the input xx to a different dimension, so that the dimensions match up in the final addition needed to add the shortcut value back to the main path. (This plays a similar role as the matrix WsWs discussed in lecture.) For example, to reduce the activation dimensions's height and width by a factor of 2, you can use a 1x1 convolution with a stride of 2. The CONV2D layer on the shortcut path does not use any non-linear activation function. Its main role is to just apply a (learned) linear function that reduces the dimension of the input, so that the dimensions match up for the later addition step.
The details of the convolutional block are as follows.
First component of main path:
- The first CONV2D has F1F1 filters of shape (1,1) and a stride of (s,s). Its padding is "valid" and its name should be
conv_name_base + '2a'. - The first BatchNorm is normalizing the channels axis. Its name should be
bn_name_base + '2a'. - Then apply the ReLU activation function. This has no name and no hyperparameters.
Second component of main path:
- The second CONV2D has F2F2 filters of (f,f) and a stride of (1,1). Its padding is "same" and it's name should be
conv_name_base + '2b'. - The second BatchNorm is normalizing the channels axis. Its name should be
bn_name_base + '2b'. - Then apply the ReLU activation function. This has no name and no hyperparameters.
Third component of main path:
- The third CONV2D has F3F3 filters of (1,1) and a stride of (1,1). Its padding is "valid" and it's name should be
conv_name_base + '2c'. - The third BatchNorm is normalizing the channels axis. Its name should be
bn_name_base + '2c'. Note that there is no ReLU activation function in this component.
Shortcut path:
- The CONV2D has F3F3 filters of shape (1,1) and a stride of (s,s). Its padding is "valid" and its name should be
conv_name_base + '1'. - The BatchNorm is normalizing the channels axis. Its name should be
bn_name_base + '1'.
Final step:
- The shortcut and the main path values are added together.
- Then apply the ReLU activation function. This has no name and no hyperparameters.
Exercise: Implement the convoluti onal block. We have implemented the first component of the main path; you should implement the rest. As before, always use 0 as the seed for the random initialization, to ensure consistency with our grader.
- Conv Hint
- BatchNorm Hint (axis: Integer, the axis that should be normalized (typically the features axis))
- For the activation, use:
Activation('relu')(X) - Addition Hint
# GRADED FUNCTION: convolutional_block
def convolutional_block(X, f, filters, stage, block, s = 2):
"""
Implementation of the convolutional block as defined in Figure 4
Arguments:
X -- input tensor of shape (m, n_H_prev, n_W_prev, n_C_prev)
f -- integer, specifying the shape of the middle CONV's window for the main path
filters -- python list of integers, defining the number of filters in the CONV layers of the main path
stage -- integer, used to name the layers, depending on their position in the network
block -- string/character, used to name the layers, depending on their position in the network
s -- Integer, specifying the stride to be used
Returns:
X -- output of the convolutional block, tensor of shape (n_H, n_W, n_C)
"""
# defining name basis
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
# Retrieve Filters
F1, F2, F3 = filters
# Save the input value
X_shortcut = X
##### MAIN PATH #####
# First component of main path
X = Conv2D(F1, kernel_size = (1, 1), strides = (s,s), name = conv_name_base + '2a',padding = 'valid', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2a')(X)
X = Activation('relu')(X)
### START CODE HERE ###
# Second component of main path (≈3 lines)
X = Conv2D(F2, kernel_size = (f, f), strides = (1,1), name = conv_name_base + '2b',padding = 'same', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2b')(X)
X = Activation('relu')(X)
# Third component of main path (≈2 lines)
X = Conv2D(F3, kernel_size = (1, 1), strides = (1,1), name = conv_name_base + '2c',padding = 'valid', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2c')(X)
##### SHORTCUT PATH #### (≈2 lines)
X_shortcut = Conv2D(F3, kernel_size = (1, 1), strides = (s,s), name = conv_name_base + '1',padding = 'valid', kernel_initializer = glorot_uniform(seed=0))(X_shortcut)
X_shortcut = BatchNormalization(axis = 3, name = bn_name_base + '1')(X_shortcut)
# Final step: Add shortcut value to main path, and pass it through a RELU activation (≈2 lines)
X = Add()([X,X_shortcut])
X = Activation('relu')(X)
### END CODE HERE ###
return X
tf.reset_default_graph()
with tf.Session() as test:
np.random.seed(1)
A_prev = tf.placeholder("float", [3, 4, 4, 6])
X = np.random.randn(3, 4, 4, 6)
A = convolutional_block(A_prev, f = 2, filters = [2, 4, 6], stage = 1, block = 'a')
test.run(tf.global_variables_initializer())
out = test.run([A], feed_dict={A_prev: X, K.learning_phase(): 0})
print("out = " + str(out[0][1][1][0]))
Expected Output:
| out | [ 0.09018463 1.23489773 0.46822017 0.0367176 0. 0.65516603] |
3 - Building your first ResNet model (50 layers)
You now have the necessary blocks to build a very deep ResNet. The following figure describes in detail the architecture of this neural network. "ID BLOCK" in the diagram stands for "Identity block," and "ID BLOCK x3" means you should stack 3 identity blocks together.

The details of this ResNet-50 model are:
- Zero-padding pads the input with a pad of (3,3)
- Stage 1:
- The 2D Convolution has 64 filters of shape (7,7) and uses a stride of (2,2). Its name is "conv1".
- BatchNorm is applied to the channels axis of the input.
- MaxPooling uses a (3,3) window and a (2,2) stride.
- Stage 2:
- The convolutional block uses three set of filters of size [64,64,256], "f" is 3, "s" is 1 and the block is "a".
- The 2 identity blocks use three set of filters of size [64,64,256], "f" is 3 and the blocks are "b" and "c".
- Stage 3:
- The convolutional block uses three set of filters of size [128,128,512], "f" is 3, "s" is 2 and the block is "a".
- The 3 identity blocks use three set of filters of size [128,128,512], "f" is 3 and the blocks are "b", "c" and "d".
- Stage 4:
- The convolutional block uses three set of filters of size [256, 256, 1024], "f" is 3, "s" is 2 and the block is "a".
- The 5 identity blocks use three set of filters of size [256, 256, 1024], "f" is 3 and the blocks are "b", "c", "d", "e" and "f".
- Stage 5:
- The convolutional block uses three set of filters of size [512, 512, 2048], "f" is 3, "s" is 2 and the block is "a".
- The 2 identity blocks use three set of filters of size [512, 512, 2048], "f" is 3 and the blocks are "b" and "c".
- The 2D Average Pooling uses a window of shape (2,2) and its name is "avg_pool".
- The flatten doesn't have any hyperparameters or name.
- The Fully Connected (Dense) layer reduces its input to the number of classes using a softmax activation. Its name should be
'fc' + str(classes).
Exercise: Implement the ResNet with 50 layers described in the figure above. We have implemented Stages 1 and 2. Please implement the rest. (The syntax for implementing Stages 3-5 should be quite similar to that of Stage 2.) Make sure you follow the naming convention in the text above.
You'll need to use this function:
- Average pooling see reference
Here're some other functions we used in the code below:
- Conv2D: See reference
- BatchNorm: See reference (axis: Integer, the axis that should be normalized (typically the features axis))
- Zero padding: See reference
- Max pooling: See reference
- Fully conected layer: See reference
- Addition: See reference
# GRADED FUNCTION: ResNet50
def ResNet50(input_shape = (64, 64, 3), classes = 6):
"""
Implementation of the popular ResNet50 the following architecture:
CONV2D -> BATCHNORM -> RELU -> MAXPOOL -> CONVBLOCK -> IDBLOCK*2 -> CONVBLOCK -> IDBLOCK*3
-> CONVBLOCK -> IDBLOCK*5 -> CONVBLOCK -> IDBLOCK*2 -> AVGPOOL -> TOPLAYER
Arguments:
input_shape -- shape of the images of the dataset
classes -- integer, number of classes
Returns:
model -- a Model() instance in Keras
"""
# Define the input as a tensor with shape input_shape
X_input = Input(input_shape)
# Zero-Padding
X = ZeroPadding2D((3, 3))(X_input)
# Stage 1
X = Conv2D(64, (7, 7), strides = (2, 2), name = 'conv1', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = 'bn_conv1')(X)
X = Activation('relu')(X)
X = MaxPooling2D((3, 3), strides=(2, 2))(X)
# Stage 2
X = convolutional_block(X, f = 3, filters = [64, 64, 256], stage = 2, block='a', s = 1)
X = identity_block(X, 3, [64, 64, 256], stage=2, block='b')
X = identity_block(X, 3, [64, 64, 256], stage=2, block='c')
### START CODE HERE ###
# Stage 3 (≈4 lines)
X = convolutional_block(X, f = 3, filters = [128, 128, 512], stage = 3, block='a', s = 2)
X = identity_block(X, 3, [128, 128, 512], stage=3, block='b')
X = identity_block(X, 3, [128, 128, 512], stage=3, block='c')
X = identity_block(X, 3, [128, 128, 512], stage=3, block='d')
# Stage 4 (≈6 lines)
X = convolutional_block(X, f = 3, filters = [256, 256, 1024], stage = 4, block='a', s = 2)
X = identity_block(X, 3, [256, 256, 1024], stage=4, block='b')
X = identity_block(X, 3, [256, 256, 1024], stage=4, block='c')
X = identity_block(X, 3, [256, 256, 1024], stage=4, block='d')
X = identity_block(X, 3, [256, 256, 1024], stage=4, block='e')
X = identity_block(X, 3, [256, 256, 1024], stage=4, block='f')
# Stage 5 (≈3 lines)
X = convolutional_block(X, f = 3, filters = [512, 512, 2048], stage = 5, block='a', s = 2)
X = identity_block(X, 3, [512, 512, 2048], stage=5, block='b')
X = identity_block(X, 3, [512, 512, 2048], stage=5, block='c')
# AVGPOOL (≈1 line). Use "X = AveragePooling2D(...)(X)"
X = AveragePooling2D(pool_size=(2, 2), padding='same')(X)
### END CODE HERE ###
# output layer
X = Flatten()(X)
X = Dense(classes, activation='softmax', name='fc' + str(classes), kernel_initializer = glorot_uniform(seed=0))(X)
# Create model
model = Model(inputs = X_input, outputs = X, name='ResNet50')
return model
Run the following code to build the model's graph. If your implementation is not correct you will know it by checking your accuracy when running model.fit(...)below.
model = ResNet50(input_shape = (64, 64, 3), classes = 6)
As seen in the Keras Tutorial Notebook, prior training a model, you need to configure the learning process by compiling the model.
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
The model is now ready to be trained. The only thing you need is a dataset.
Let's load the SIGNS Dataset.

X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()
# Normalize image vectors
X_train = X_train_orig/255.
X_test = X_test_orig/255.
# Convert training and test labels to one hot matrices
Y_train = convert_to_one_hot(Y_train_orig, 6).T
Y_test = convert_to_one_hot(Y_test_orig, 6).T
print ("number of training examples = " + str(X_train.shape[0]))
print ("number of test examples = " + str(X_test.shape[0]))
print ("X_train shape: " + str(X_train.shape))
print ("Y_train shape: " + str(Y_train.shape))
print ("X_test shape: " + str(X_test.shape))
print ("Y_test shape: " + str(Y_test.shape))
Run the following cell to train your model on 2 epochs with a batch size of 32. On a CPU it should take you around 5min per epoch.
model.fit(X_train, Y_train, epochs = 40, batch_size = 32)
Expected Output:
| Epoch 1/2 | loss: between 1 and 5, acc: between 0.2 and 0.5, although your results can be different from ours. |
| Epoch 2/2 | loss: between 1 and 5, acc: between 0.2 and 0.5, you should see your loss decreasing and the accuracy increasing. |
Let's see how this model (trained on only two epochs) performs on the test set.
preds = model.evaluate(X_test, Y_test)
print ("Loss = " + str(preds[0]))
print ("Test Accuracy = " + str(preds[1]))
Expected Output:
| Test Accuracy | between 0.16 and 0.25 |
For the purpose of this assignment, we've asked you to train the model only for two epochs. You can see that it achieves poor performances. Please go ahead and submit your assignment; to check correctness, the online grader will run your code only for a small number of epochs as well.
After you have finished this official (graded) part of this assignment, you can also optionally train the ResNet for more iterations, if you want. We get a lot better performance when we train for ~20 epochs, but this will take more than an hour when training on a CPU.
Using a GPU, we've trained our own ResNet50 model's weights on the SIGNS dataset. You can load and run our trained model on the test set in the cells below. It may take ≈1min to load the model.
model = load_model('ResNet50.h5')
preds = model.evaluate(X_test, Y_test)
print ("Loss = " + str(preds[0]))
print ("Test Accuracy = " + str(preds[1]))
ResNet50 is a powerful model for image classification when it is trained for an adequate number of iterations. We hope you can use what you've learnt and apply it to your own classification problem to perform state-of-the-art accuracy.
Congratulations on finishing this assignment! You've now implemented a state-of-the-art image classification system!
4 - Test on your own image (Optional/Ungraded)
If you wish, you can also take a picture of your own hand and see the output of the model. To do this:
1. Click on "File" in the upper bar of this notebook, then click "Open" to go on your Coursera Hub.
2. Add your image to this Jupyter Notebook's directory, in the "images" folder
3. Write your image's name in the following code
4. Run the code and check if the algorithm is right!
img_path = 'images/my_image.jpg'
img = image.load_img(img_path, target_size=(64, 64))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
print('Input image shape:', x.shape)
my_image = scipy.misc.imread(img_path)
imshow(my_image)
print("class prediction vector [p(0), p(1), p(2), p(3), p(4), p(5)] = ")
print(model.predict(x))

You can also print a summary of your model by running the following code.
model.summary()
Finally, run the code below to visualize your ResNet50. You can also download a .png picture of your model by going to "File -> Open...-> model.png".
plot_model(model, to_file='model.png')
SVG(model_to_dot(model).create(prog='dot', format='svg'))
What you should remember:
- Very deep "plain" networks don't work in practice because they are hard to train due to vanishing gradients.
- The skip-connections help to address the Vanishing Gradient problem. They also make it easy for a ResNet block to learn an identity function.
- There are two main type of blocks: The identity block and the convolutional block.
- Very deep Residual Networks are built by stacking these blocks together.
References
This notebook presents the ResNet algorithm due to He et al. (2015). The implementation here also took significant inspiration and follows the structure given in the github repository of Francois Chollet:
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun - Deep Residual Learning for Image Recognition (2015)
- Francois Chollet's github repository: https://github.com/fchollet/deep-learning-models/blob/master/resnet50.py
-------------------------------------------------------------中文版---------------------------------------------------------------------------------------------
中文版摘自:https://blog.csdn.net/u013733326
残差网络的搭建
这里我们将学习怎样使用残差网络构建一个非常深的卷积网络。理论上越深的网络越能够实现越复杂的功能,但是在实际上却非常难以训练。残差网络就是为了解决深网络的难以训练的问题的。
在本文章中,我们将:
- 实现基本的残差块。
- 将这些残差块放在一起,实现并训练用于图像分类的神经网络。
本次实验将使用Keras框架
在解决问题之前,我们先来导入库函数:
import numpy as np
import tensorflow as tf
from keras import layers
from keras.layers import Input, Add, Dense, Activation, ZeroPadding2D, BatchNormalization, Flatten, Conv2D, AveragePooling2D, MaxPooling2D, GlobalMaxPooling2D
from keras.models import Model, load_model
from keras.preprocessing import image
from keras.utils import layer_utils
from keras.utils.data_utils import get_file
from keras.applications.imagenet_utils import preprocess_input
from keras.utils.vis_utils import model_to_dot
from keras.utils import plot_model
from keras.initializers import glorot_uniform
import pydot
from IPython.display import SVG
import scipy.misc
from matplotlib.pyplot import imshow
import keras.backend as K
K.set_image_data_format('channels_last')
K.set_learning_phase(1)
import resnets_utils - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
2.1 - 深层网络的麻烦
上周,我们构建了第一个卷积神经网络。最近几年,卷积神经网络变得越来越深,从只从几层(例如AlexNet)到超过一百层。
使用深层网络最大的好处就是它能够完成很复杂的功能,它能够从边缘(浅层)到非常复杂的特征(深层)中不同的抽象层次的特征中学习。然而,使用比较深的网络通常没有什么好处,一个特别大的麻烦就在于训练的时候会产生梯度消失,非常深的网络通常会有一个梯度信号,该信号会迅速的消退,从而使得梯度下降变得非常缓慢。更具体的说,在梯度下降的过程中,当你从最后一层回到第一层的时候,你在每个步骤上乘以权重矩阵,因此梯度值可以迅速的指数式地减少到0(在极少数的情况下会迅速增长,造成梯度爆炸)。
在训练的过程中,你可能会看到开始几层的梯度的大小(或范数)迅速下降到0,如下图:
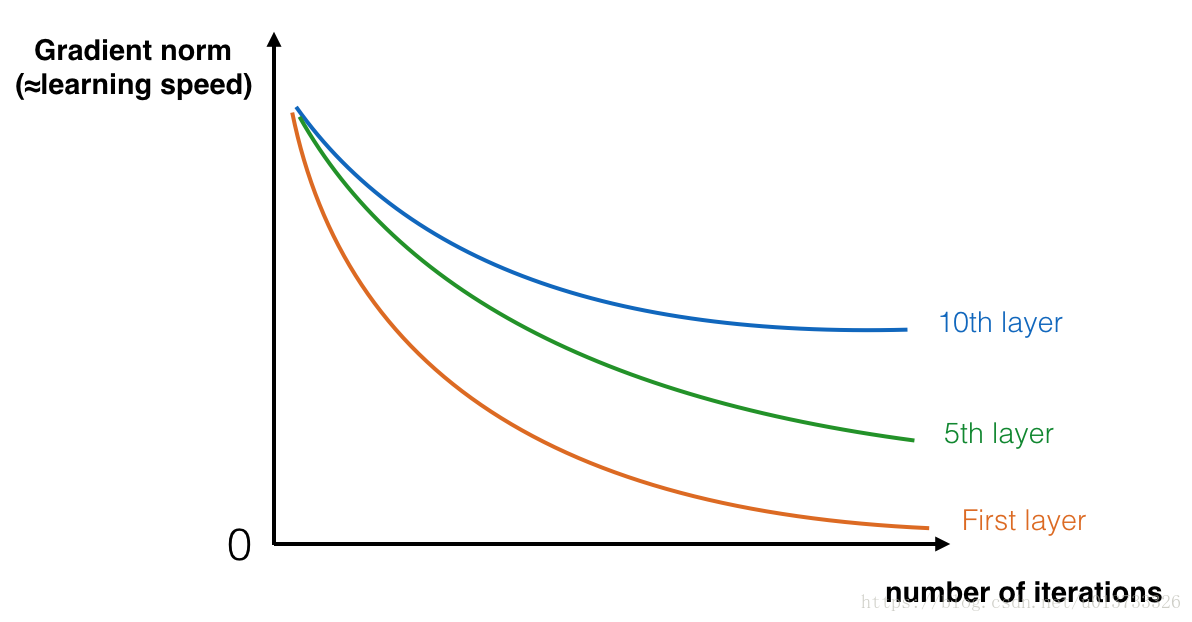
在前几层中随着迭代次数的增加,学习的速度会下降的非常快。
为了解决这个问题,我们将构建残差网络。
2.2 - 构建一个残差网络
在残差网络中,一个“捷径(shortcut)”或者说“跳跃连接(skip connection)”允许梯度直接反向传播到更浅的层,如下图:

图像左边是神经网络的主路,图像右边是添加了一条捷径的主路,通过这些残差块堆叠在一起,可以形成一个非常深的网络。
我们在视频中可以看到使用捷径的方式使得每一个残差块能够很容易学习到恒等式功能,这意味着我们可以添加很多的残差块而不会损害训练集的表现。
残差块有两种类型,主要取决于输入输出的维度是否相同,下面我们来看看吧~
2.2.1 - 恒等块(Identity block)
恒等块是残差网络使用的的标准块,对应于输入的激活值(比如a[l]a[l])与输出激活值(比如a[l+1]a[l+1])具有相同的维度。为了具象化残差块的不同步骤,我们来看看下面的图吧~
上图中,上面的曲线路径是“捷径”,下面的直线路径是主路径。在上图中,我们依旧把CONV2D 与 ReLU包含到了每个步骤中,为了提升训练的速度,我们在每一步也把数据进行了归一化(BatchNorm),不要害怕这些东西,因为Keras框架已经实现了这些东西,调用BatchNorm只需要一行代码。
在实践中,我们要做一个更强大的版本:跳跃连接会跳过3个隐藏层而不是两个,就像下图:
每个步骤如下:
-
主路径的第一部分:
-
第一个CONV2D有F1F1个过滤器,其大小为(11,11),步长为(1,1),使用填充方式为“valid”,命名规则为
conv_name_base + '2a',使用00作为随机种子为其初始化。 -
第一个BatchNorm是通道的轴归一化,其命名规则为
bn_name_base + '2a'。 -
接着使用ReLU激活函数,它没有命名也没有超参数。
-
-
主路径的第二部分:
-
第二个CONV2D有F2F2个过滤器,其大小为(ff,ff),步长为(1,1),使用填充方式为“same”,命名规则为
conv_name_base + '2b',使用00作为随机种子为其初始化。 -
第二个BatchNorm是通道的轴归一化,其命名规则为
bn_name_base + '2b'。 -
接着使用ReLU激活函数,它没有命名也没有超参数。
-
-
主路径的第三部分:
-
第三个CONV2D有F3F3个过滤器,其大小为(11,11),步长为(1,1),使用填充方式为“valid”,命名规则为
conv_name_base + '2c',使用00作为随机种子为其初始化。 -
第三个BatchNorm是通道的轴归一化,其命名规则为
bn_name_base + '2c'。 -
注意这里没有ReLU函数
-
-
最后一步:
-
将捷径与输入加在一起
-
使用ReLU激活函数,它没有命名也没有超参数。
-
接下来我们就要实现残差网络的恒等块了,请务必查看下面的中文手册:
def identity_block(X, f, filters, stage, block):
"""
实现图3的恒等块
参数:
X - 输入的tensor类型的数据,维度为( m, n_H_prev, n_W_prev, n_H_prev )
f - 整数,指定主路径中间的CONV窗口的维度
filters - 整数列表,定义了主路径每层的卷积层的过滤器数量
stage - 整数,根据每层的位置来命名每一层,与block参数一起使用。
block - 字符串,据每层的位置来命名每一层,与stage参数一起使用。
返回:
X - 恒等块的输出,tensor类型,维度为(n_H, n_W, n_C)
"""
#定义命名规则
conv_name_base = "res" + str(stage) + block + "_branch"
bn_name_base = "bn" + str(stage) + block + "_branch"
#获取过滤器
F1, F2, F3 = filters
#保存输入数据,将会用于为主路径添加捷径
X_shortcut = X
#主路径的第一部分
##卷积层
X = Conv2D(filters=F1, kernel_size=(1,1), strides=(1,1) ,padding="valid",
name=conv_name_base+"2a", kernel_initializer=glorot_uniform(seed=0))(X)
##归一化
X = BatchNormalization(axis=3,name=bn_name_base+"2a")(X)
##使用ReLU激活函数
X = Activation("relu")(X)
#主路径的第二部分
##卷积层
X = Conv2D(filters=F2, kernel_size=(f,f),strides=(1,1), padding="same",
name=conv_name_base+"2b", kernel_initializer=glorot_uniform(seed=0))(X)
##归一化
X = BatchNormalization(axis=3,name=bn_name_base+"2b")(X)
##使用ReLU激活函数
X = Activation("relu")(X)
#主路径的第三部分
##卷积层
X = Conv2D(filters=F3, kernel_size=(1,1), strides=(1,1), padding="valid",
name=conv_name_base+"2c", kernel_initializer=glorot_uniform(seed=0))(X)
##归一化
X = BatchNormalization(axis=3,name=bn_name_base+"2c")(X)
##没有ReLU激活函数
#最后一步:
##将捷径与输入加在一起
X = Add()([X,X_shortcut])
##使用ReLU激活函数
X = Activation("relu")(X)
return X- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
我们来测试一下:
tf.reset_default_graph()
with tf.Session() as test:
np.random.seed(1)
A_prev = tf.placeholder("float",[3,4,4,6])
X = np.random.randn(3,4,4,6)
A = identity_block(A_prev,f=2,filters=[2,4,6],stage=1,block="a")
test.run(tf.global_variables_initializer())
out = test.run([A],feed_dict={A_prev:X,K.learning_phase():0})
print("out = " + str(out[0][1][1][0]))
test.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
测试结果:
out = [ 0.19716813 0. 1.35612273 2.17130733 0. 1.33249867]- 1
2.2.2 - 卷积块
我们已经实现了残差网络的恒等块,现在,残差网络的卷积块是另一种类型的残差块,它适用于输入输出的维度不一致的情况,它不同于上面的恒等块,与之区别在于,捷径中有一个CONV2D层,如下图:
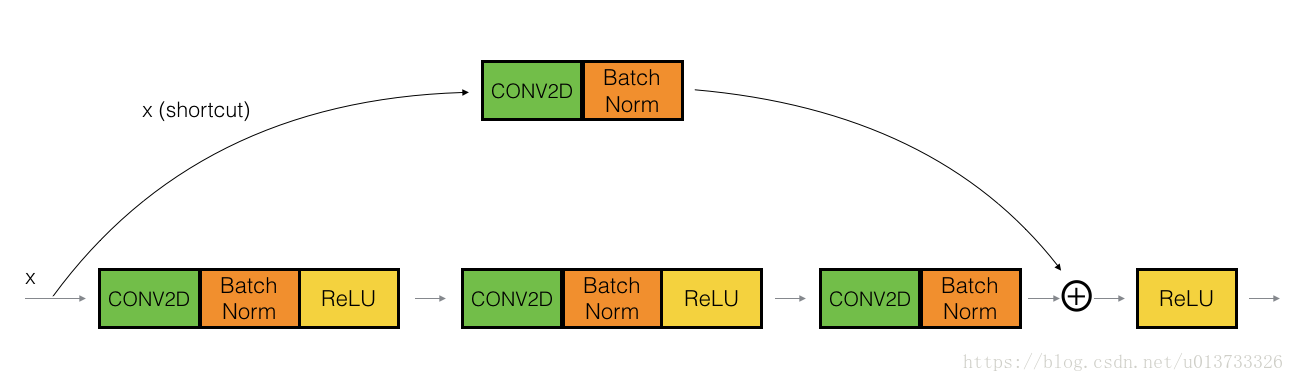
捷径中的卷积层将把输入xx卷积为不同的维度,因此在主路径最后那里需要适配捷径中的维度。比如:把激活值中的宽高减少2倍,我们可以使用1x1的卷积,步伐为2。捷径上的卷积层不使用任何非线性激活函数,它的主要作用是仅仅应用(学习后的)线性函数来减少输入的维度,以便在后面的加法步骤中的维度相匹配。
具体步骤如下:
-
主路径第一部分:
-
第一个卷积层有F1F1个过滤器,其维度为(11,11),步伐为(ss,ss),使用“valid”的填充方式,命名规则为
conv_name_base + '2a' -
第一个规范层是通道的轴归一化,其命名规则为
bn_name_base + '2a' -
使用ReLU激活函数,它没有命名规则也没有超参数。
-
-
主路径第二部分:
-
第二个卷积层有F2F2个过滤器,其维度为(ff,ff),步伐为(11,11),使用“same”的填充方式,命名规则为
conv_name_base + '2b' -
第二个规范层是通道的轴归一化,其命名规则为
bn_name_base + '2b' -
使用ReLU激活函数,它没有命名规则也没有超参数。
-
-
主路径第三部分:
-
第三个卷积层有F3F3个过滤器,其维度为(11,11),步伐为(ss,ss),使用“valid”的填充方式,命名规则为
conv_name_base + '2c' -
第三个规范层是通道的轴归一化,其命名规则为
bn_name_base + '2c' -
没有激活函数
-
-
捷径:
-
此卷积层有F3F3个过滤器,其维度为(11,11),步伐为(ss,ss),使用“valid”的填充方式,命名规则为
conv_name_base + '1' -
此规范层是通道的轴归一化,其命名规则为
bn_name_base + '1'
-
-
最后一步:
-
将捷径与输入加在一起
-
使用ReLU激活函数
-
我们要做的是实现卷积块,请务必查看下面的中文手册:
def convolutional_block(X, f, filters, stage, block, s=2):
"""
实现图5的卷积块
参数:
X - 输入的tensor类型的变量,维度为( m, n_H_prev, n_W_prev, n_C_prev)
f - 整数,指定主路径中间的CONV窗口的维度
filters - 整数列表,定义了主路径每层的卷积层的过滤器数量
stage - 整数,根据每层的位置来命名每一层,与block参数一起使用。
block - 字符串,据每层的位置来命名每一层,与stage参数一起使用。
s - 整数,指定要使用的步幅
返回:
X - 卷积块的输出,tensor类型,维度为(n_H, n_W, n_C)
"""
#定义命名规则
conv_name_base = "res" + str(stage) + block + "_branch"
bn_name_base = "bn" + str(stage) + block + "_branch"
#获取过滤器数量
F1, F2, F3 = filters
#保存输入数据
X_shortcut = X
#主路径
##主路径第一部分
X = Conv2D(filters=F1, kernel_size=(1,1), strides=(s,s), padding="valid",
name=conv_name_base+"2a", kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3,name=bn_name_base+"2a")(X)
X = Activation("relu")(X)
##主路径第二部分
X = Conv2D(filters=F2, kernel_size=(f,f), strides=(1,1), padding="same",
name=conv_name_base+"2b", kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3,name=bn_name_base+"2b")(X)
X = Activation("relu")(X)
##主路径第三部分
X = Conv2D(filters=F3, kernel_size=(1,1), strides=(1,1), padding="valid",
name=conv_name_base+"2c", kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3,name=bn_name_base+"2c")(X)
#捷径
X_shortcut = Conv2D(filters=F3, kernel_size=(1,1), strides=(s,s), padding="valid",
name=conv_name_base+"1", kernel_initializer=glorot_uniform(seed=0))(X_shortcut)
X_shortcut = BatchNormalization(axis=3,name=bn_name_base+"1")(X_shortcut)
#最后一步
X = Add()([X,X_shortcut])
X = Activation("relu")(X)
return X- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
我们来测试一下:
tf.reset_default_graph()
with tf.Session() as test:
np.random.seed(1)
A_prev = tf.placeholder("float",[3,4,4,6])
X = np.random.randn(3,4,4,6)
A = convolutional_block(A_prev,f=2,filters=[2,4,6],stage=1,block="a")
test.run(tf.global_variables_initializer())
out = test.run([A],feed_dict={A_prev:X,K.learning_phase():0})
print("out = " + str(out[0][1][1][0]))
test.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
测试结果:
out = [ 0.09018463 1.23489773 0.46822017 0.0367176 0. 0.65516603]- 1
2.3 - 构建你的第一个残差网络(50层)
我们已经做完所需要的所有残差块了,下面这个图就描述了神经网络的算法细节,图中的”ID BLOCK“是指标准的恒等块,”ID BLOCK X3“是指把三个恒等块放在一起。
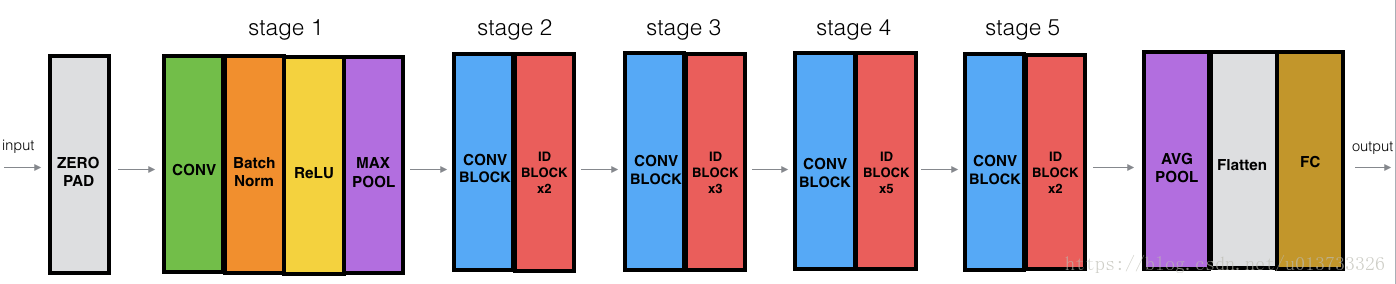
这个50层的网络的细节如下:
1. 对输入数据进行0填充,padding =(3,3)
-
stage1:
-
卷积层有64个过滤器,其维度为(7,7),步伐为(2,2),命名为“conv1”
-
规范层(BatchNorm)对输入数据进行通道轴归一化。
-
最大值池化层使用一个(3,3)的窗口和(2,2)的步伐。
-
-
stage2:
-
卷积块使用f=3个大小为[64,64,256]的过滤器,f=3,s=1,block=”a”
-
2个恒等块使用三个大小为[64,64,256]的过滤器,f=3,block=”b”、”c”
-
-
stage3:
-
卷积块使用f=3个大小为[128,128,512]的过滤器,f=3,s=2,block=”a”
-
3个恒等块使用三个大小为[128,128,512]的过滤器,f=3,block=”b”、”c”、”d”
-
-
stage4:
-
卷积块使用f=3个大小为[256,256,1024]的过滤器,f=3,s=2,block=”a”
-
5个恒等块使用三个大小为[256,256,1024]的过滤器,f=3,block=”b”、”c”、”d”、”e”、”f”
-
-
stage5:
-
卷积块使用f=3个大小为[512,512,2048]的过滤器,f=3,s=2,block=”a”
-
2个恒等块使用三个大小为[256,256,2048]的过滤器,f=3,block=”b”、”c”
-
-
均值池化层使用维度为(2,2)的窗口,命名为“avg_pool”
- 展开操作没有任何超参数以及命名
- 全连接层(密集连接)使用softmax激活函数,命名为
"fc" + str(classes)
为了实现这50层的残差网络,我们需要查看一下手册:
def ResNet50(input_shape=(64,64,3),classes=6):
"""
实现ResNet50
CONV2D -> BATCHNORM -> RELU -> MAXPOOL -> CONVBLOCK -> IDBLOCK*2 -> CONVBLOCK -> IDBLOCK*3
-> CONVBLOCK -> IDBLOCK*5 -> CONVBLOCK -> IDBLOCK*2 -> AVGPOOL -> TOPLAYER
参数:
input_shape - 图像数据集的维度
classes - 整数,分类数
返回:
model - Keras框架的模型
"""
#定义tensor类型的输入数据
X_input = Input(input_shape)
#0填充
X = ZeroPadding2D((3,3))(X_input)
#stage1
X = Conv2D(filters=64, kernel_size=(7,7), strides=(2,2), name="conv1",
kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name="bn_conv1")(X)
X = Activation("relu")(X)
X = MaxPooling2D(pool_size=(3,3), strides=(2,2))(X)
#stage2
X = convolutional_block(X, f=3, filters=[64,64,256], stage=2, block="a", s=1)
X = identity_block(X, f=3, filters=[64,64,256], stage=2, block="b")
X = identity_block(X, f=3, filters=[64,64,256], stage=2, block="c")
#stage3
X = convolutional_block(X, f=3, filters=[128,128,512], stage=3, block="a", s=2)
X = identity_block(X, f=3, filters=[128,128,512], stage=3, block="b")
X = identity_block(X, f=3, filters=[128,128,512], stage=3, block="c")
X = identity_block(X, f=3, filters=[128,128,512], stage=3, block="d")
#stage4
X = convolutional_block(X, f=3, filters=[256,256,1024], stage=4, block="a", s=2)
X = identity_block(X, f=3, filters=[256,256,1024], stage=4, block="b")
X = identity_block(X, f=3, filters=[256,256,1024], stage=4, block="c")
X = identity_block(X, f=3, filters=[256,256,1024], stage=4, block="d")
X = identity_block(X, f=3, filters=[256,256,1024], stage=4, block="e")
X = identity_block(X, f=3, filters=[256,256,1024], stage=4, block="f")
#stage5
X = convolutional_block(X, f=3, filters=[512,512,2048], stage=5, block="a", s=2)
X = identity_block(X, f=3, filters=[512,512,2048], stage=5, block="b")
X = identity_block(X, f=3, filters=[512,512,2048], stage=5, block="c")
#均值池化层
X = AveragePooling2D(pool_size=(2,2),padding="same")(X)
#输出层
X = Flatten()(X)
X = Dense(classes, activation="softmax", name="fc"+str(classes),
kernel_initializer=glorot_uniform(seed=0))(X)
#创建模型
model = Model(inputs=X_input, outputs=X, name="ResNet50")
return model- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
然后我们对模型做实体化和编译工作:
model = ResNet50(input_shape=(64,64,3),classes=6)
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])
- 1
- 2
- 3
现在模型已经准备好了,接下来就是加载训练集进行训练。

X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = resnets_utils.load_dataset()
# Normalize image vectors
X_train = X_train_orig / 255.
X_test = X_test_orig / 255.
# Convert training and test labels to one hot matrices
Y_train = resnets_utils.convert_to_one_hot(Y_train_orig, 6).T
Y_test = resnets_utils.convert_to_one_hot(Y_test_orig, 6).T
print("number of training examples = " + str(X_train.shape[0]))
print("number of test examples = " + str(X_test.shape[0]))
print("X_train shape: " + str(X_train.shape))
print("Y_train shape: " + str(Y_train.shape))
print("X_test shape: " + str(X_test.shape))
print("Y_test shape: " + str(Y_test.shape))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
执行结果:
number of training examples = 1080
number of test examples = 120
X_train shape: (1080, 64, 64, 3)
Y_train shape: (1080, 6)
X_test shape: (120, 64, 64, 3)
Y_test shape: (120, 6)- 1
- 2
- 3
- 4
- 5
- 6
运行模型两代,batch=32,每代大约3分钟左右。
model.fit(X_train,Y_train,epochs=2,batch_size=32)- 1
执行结果:
Epoch 1/2
1080/1080 [==============================] - 200s 185ms/step - loss: 3.0667 - acc: 0.2593
Epoch 2/2
1080/1080 [==============================] - 186s 172ms/step - loss: 1.9755 - acc: 0.4093- 1
- 2
- 3
- 4
- 在1212Epoch中,loss在1~5之间算正常,acc在0.2~0.5之间算正常,你的结果和我的不一样也算正常。
- 在2222Epoch中,loss在1~5之间算正常,acc在0.2~0.5之间算正常,你可以看到损失在下降,准确率在上升。
我们来评估一下模型:
preds = model.evaluate(X_test,Y_test)
print("误差值 = " + str(preds[0]))
print("准确率 = " + str(preds[1]))
- 1
- 2
- 3
- 4
- 5
执行结果:
120/120 [==============================] - 5s 44ms/step
误差值 = 12.3403865178
准确率 = 0.175000000497- 1
- 2
- 3
在完成这个任务之后,如果愿意的话,您还可以选择继续训练RESNET。当我们训练20代时,我们得到了更好的性能,但是在得在CPU上训练需要一个多小时。使用GPU的话,博主已经在手势数据集上训练了自己的RESNET50模型的权重,你可以使用下面的代码载并运行博主的训练模型,加载模型可能需要1min。
#加载模型
model = load_model("ResNet50.h5") - 1
- 2
然后测试一下博主训练出来的权值:
preds = model.evaluate(X_test,Y_test)
print("误差值 = " + str(preds[0]))
print("准确率 = " + str(preds[1]))- 1
- 2
- 3
测试结果:
120/120 [==============================] - 4s 35ms/step
误差值 = 0.108543064694
准确率 = 0.966666662693- 1
- 2
- 3
2.2.4 使用自己的图片做测试
按理来说,训练数据集与自己的数据集是不一样的,但是我们也可以来试试嘛。
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt # plt 用于显示图片
%matplotlib inline
img_path = 'images/fingers_big/2.jpg'
my_image = image.load_img(img_path, target_size=(64, 64))
my_image = image.img_to_array(my_image)
my_image = np.expand_dims(my_image,axis=0)
my_image = preprocess_input(my_image)
print("my_image.shape = " + str(my_image.shape))
print("class prediction vector [p(0), p(1), p(2), p(3), p(4), p(5)] = ")
print(model.predict(my_image))
my_image = scipy.misc.imread(img_path)
plt.imshow(my_image)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
执行结果:
my_image.shape = (1, 64, 64, 3)
class prediction vector [p(0), p(1), p(2), p(3), p(4), p(5)] =
[[ 1. 0. 0. 0. 0. 0.]]- 1
- 2
- 3
请忽略博主这臃肿的手【手动捂脸】 
我们可以看一下网络的节点的大小细节:
model.summary()- 1
执行结果:
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 64, 64, 3) 0
__________________________________________________________________________________________________
zero_padding2d_1 (ZeroPadding2D (None, 70, 70, 3) 0 input_1[0][0]
__________________________________________________________________________________________________
conv1 (Conv2D) (None, 32, 32, 64) 9472 zero_padding2d_1[0][0]
__________________________________________________________________________________________________
bn_conv1 (BatchNormalization) (None, 32, 32, 64) 256 conv1[0][0]
__________________________________________________________________________________________________
activation_1 (Activation) (None, 32, 32, 64) 0 bn_conv1[0][0]
__________________________________________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (None, 15, 15, 64) 0 activation_1[0][0]
__________________________________________________________________________________________________
res2a_branch2a (Conv2D) (None, 15, 15, 64) 4160 max_pooling2d_1[0][0]
__________________________________________________________________________________________________
bn2a_branch2a (BatchNormalizati (None, 15, 15, 64) 256 res2a_branch2a[0][0]
__________________________________________________________________________________________________
activation_2 (Activation) (None, 15, 15, 64) 0 bn2a_branch2a[0][0]
__________________________________________________________________________________________________
res2a_branch2b (Conv2D) (None, 15, 15, 64) 36928 activation_2[0][0]
_________________________________________________________________