Jmeter(一)常用组件说明
1.常用组件说明
1.1HTTP请求默认值
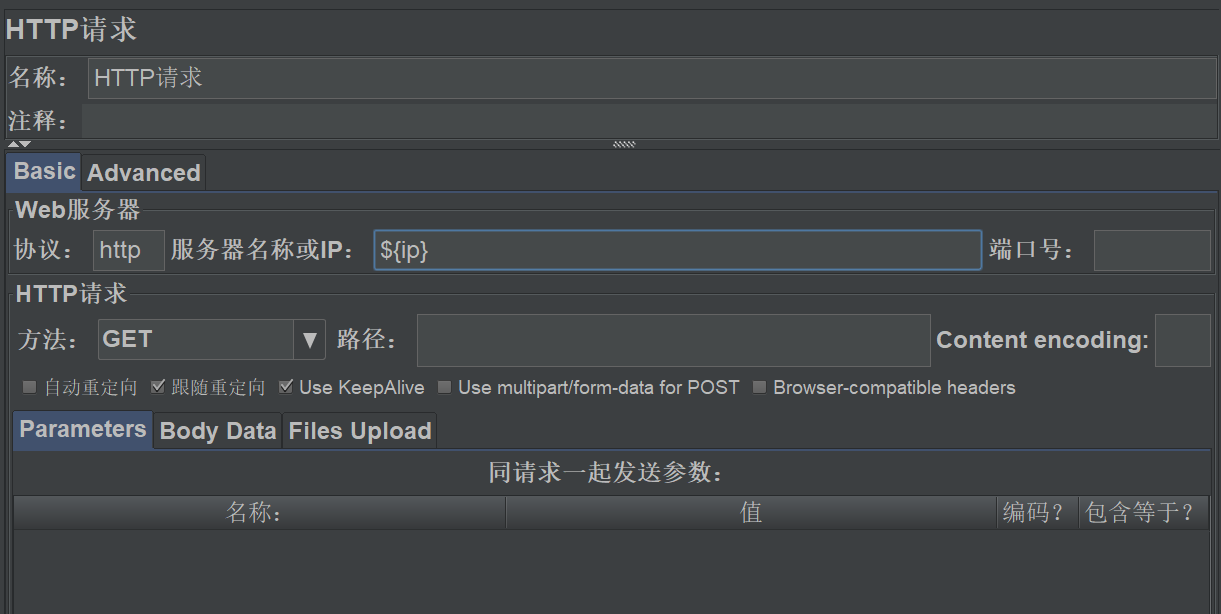
| 服务器名或IP | ${ip}引用自定义变量中用户定义的ip |
| 端口号 | 设置端口号(被测试应用或服务IP的端口号) |
| Connect | 设置连接超时时间(单位毫秒) |
| Respones | 设置响应超时时间(单位毫秒) |
| 协议 | 协议类型,如HTTP |
| Content encoding | 设置HTTP请求编码格式 |
1.2用户定义的变量
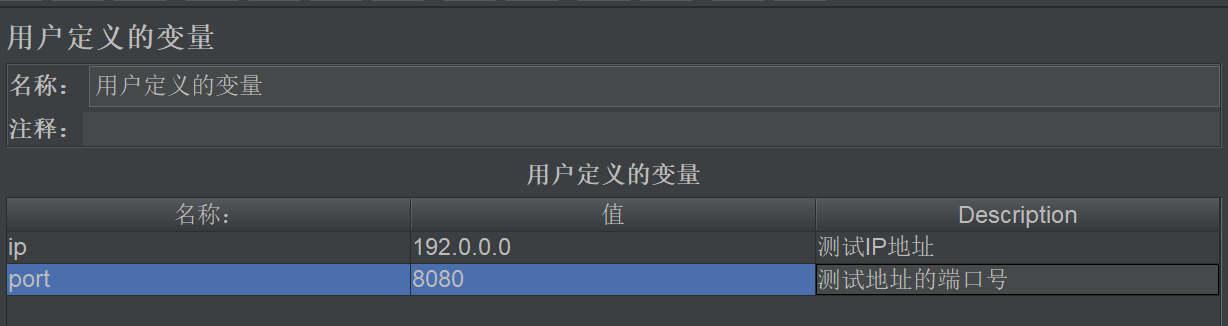
| 名称 | 设置自定义变量的名称。在用例中使用${名称}调用。注意:该组件定义的变量是全局变量 |
| 值 | 变量对应的值 |
| Descriiption | 描述这个变量 |
1.3用户参数
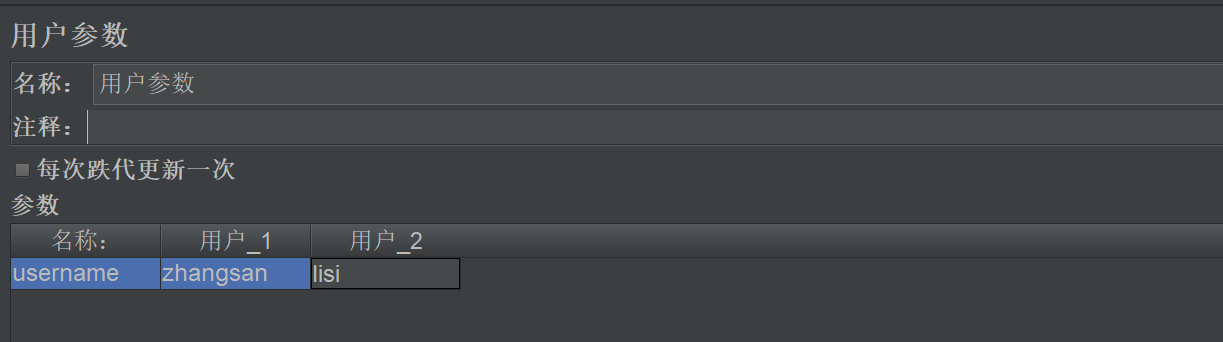
"用户参数"组件,常用于线程组对整个线程租生效,比"用户定义的变量"多一个"每次迭代更新一次"的功能,可以配合线程组做循环取值
1.4固定定时器

主要的作用是设置等待时间和延迟。根据其放置的位置不同而作用也不同,放在全局控制区域对对整个工程生效,放在线程控制区域对个别线程生效
放在用例控制级别对用例生效
1.5HTTP Cookie管理器
| 每次反复清除Cookies | 是否每次迭代清除Cookies |
| Cookies Policy | Cookies实现策略。包含standard、default、compatibility等不同策略 |
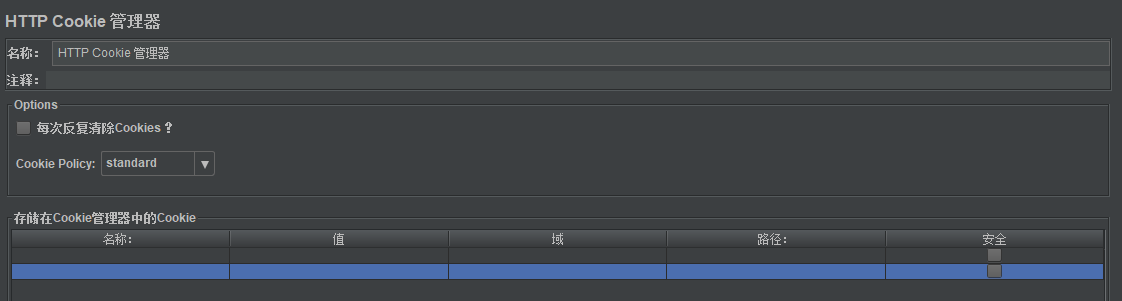
HTTP Cookie管理器自动管理Cookie,像浏览器一样存储发送Cookie.
HTTP Cookie管理器的作用域:放在测试计划下对下面整个测试计划都有效,放在线程组中对特定线程组有效,放在简单控制器或事务控制器中
只对当前简单控制器或者当前事务控制器有效
典型问题:1.如果线程组中设置了Cookie管理器,测试计划中设置的Cookie管理器任会对线程组中有效,这是因该禁用测试计划中的Cookie管理器,线程组中的才会有效
2.每次反复清除Cookies?:选择后,则每次线程组运行时,都会清除 cookie。(若是手动添加的cookie,则不会被清除)
3.Cookie Policy:Cookie的管理策略
compatibility:推荐选择此种策略。这种兼容性设计要求是适应尽可能多的不同的服务器,尽管不是完全按照标准来实现的。如果你遇到了解析 Cookies 的问题,
你就可能要用到这一个规范。有太多的web站点是用CGI脚本去实现的,而导致只有将所有的 Cookies 都放入 Request header 才可以正常的工作。
这种情况下最好设置 http.protocol.single-cookie-header 参数为 true。
rfc2109:是HttpClient使用的默认Cookies协议。
rfc2965:定义了版本2并且尝试去弥补在版本1中 Cookie 的 RFC2109 标准的缺点。规定 RFC2965 最终取代 RFC2109 发送 RFC2965 标准 Cookies 的服务端,
将会使用 Set-Cookie2 header 添加到 Set-Cookie Header 信心中,RFC2965 Cookies 是区分端口的。 ignorecookies:此规格忽略所有 Cookie。被用来防止 HttpClient 接受和发送的 Cookie。
netscape:是最原始的 Cookies 规范,同时也是 RFC2109 的基础。尽管如此,还是在很多重要的方面与 RFC2109 不同,可能需要特定服务器才可以兼容。
default:默认
1.6简单控制器
主要作用是将用例集进行划分。把相同应用的用例放在一起,选择使用简单控制器在运行脚本的时候不会单独生成一条巡行记录,起到了很好的脚本结构划分作用
1.7事务控制器
事务控制器会产生一个额外的取样器(sampler)用来计算衡量它所包含的测试组件(比如一个提交订单的接口会有多个http接口)的总体时间。在查看"查看结果树"
中,事务管理器只有在其子采样器都成功的情况下才会显示成功
1.8HTTP信息头管理器

HTTP消息头管理器。Jmeter中每条用例都是发送请求,需要添加消息头,在这里设置,放在用例内部
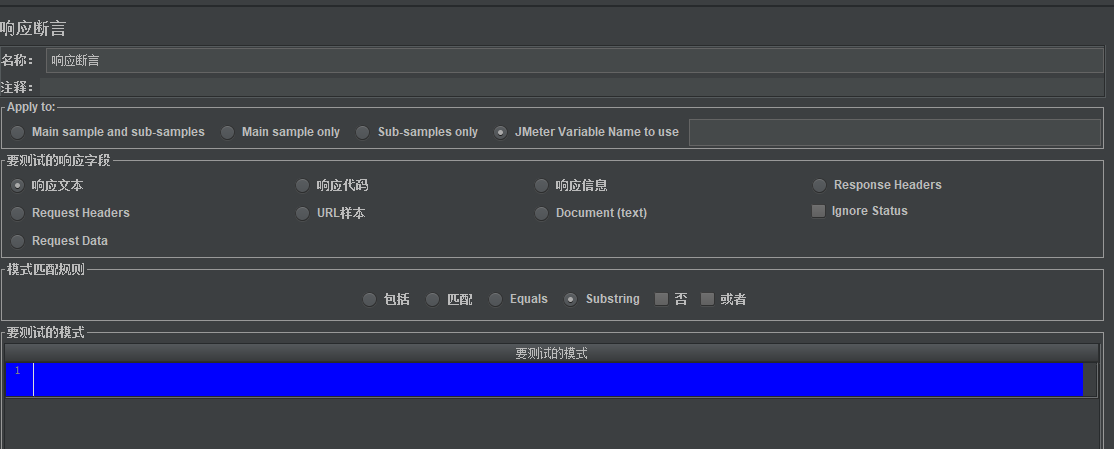
1.9响应断言
| Apply to | 关于应用范围,我们大多数勾选“main sample only” 就足够了,因为我们一个请求,实质上只有一个请求。但是当我们发一个请求时,可以触发多个服务器请求,就有main sample 和 sub-sample之分了。 |
| 要测试的响应字段 | 响应文本、响应代码、响应信息、url样本等 |
| 模式匹配规则 | 包括、匹配、Equals、Substring、否、或者(勾选“包括”,意味着只要相应数据中包含要校验的字段,任务就算成功) |
| 要测试的模式 | 即需要校验的数据值(期望结果) |
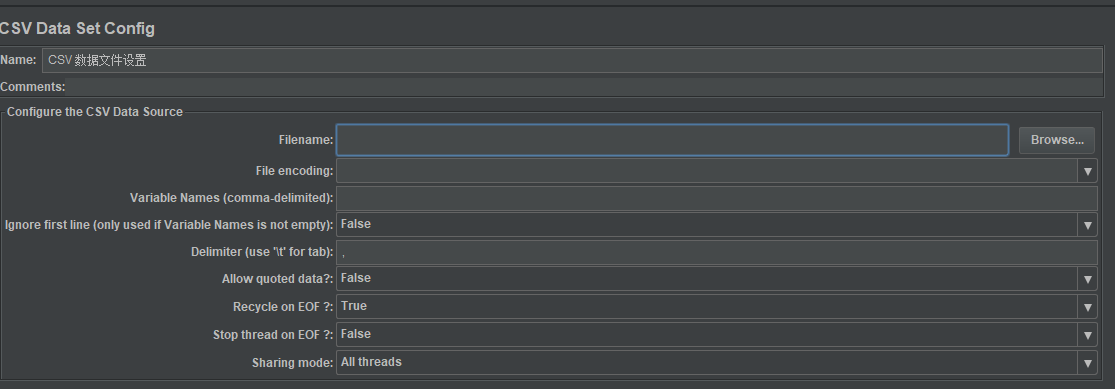
2.0 CSV Data Set Config
| Filename | 外部导入文件地址 |
| File encoding | 文件编码格式 |
| Delimiter | 分隔符 |
| Allow qutoted data | 是否允许引用符。注意:CSV中包括引号,逗号等分隔符,该值应该设置成true |
| Recycle on EOF | 设置为true后,允许循环取 |
| Stop Thread on EOF | 当Recycle on EOF为false 并且Stop Thread on EOF为true,则读完csv文件的记录后,停止运行 |
| Sharing Mode | 设置是否线程共享 |
CSV Data Set Config实现读取外部CSV文件数据,作为参数变量传入。当 Recycle on EOF 选择false时,Stop thread on EOF 选择true,线程4个,参数3个,那么只会请求3次。
当Recycle on EOF选择false时,Stop thread on EOF选择false,线程4个,参数3个,那么请求4次,但是第4次没有参数可取,不让循环,所以第4次请求错误。
2.1聚合报告
Label:请求的名称,就是我们在进行测试的httprequest sampler的名称
Samples:总共发给服务器的请求数量,如果模拟10个用户,每个用户迭代10次,那么总的请求数为:10*10 =100次;
Average:默认情况下是单个 Request 的平均响应时间,当使用了 Transaction Controller 时,以Transaction 为单位显示平均响应时间 ,单位是毫秒
Median: 50%用户的请求的响应时间,中位数
90%Line:90%的请求的响应时间
95%Line:95%的请求的响应时间
99%Line:99%的请求的响应时间
Min:最小的响应时间
Max:最大的响应时间
Error%:错误率=错误的请求的数量/请求的总数
Throughput: 默认情况下表示每秒完成的请求数(Request per Second),当使用了 Transaction Controller 时,也可以表示类似 LoadRunner 的 Transaction per Second 数
KB/sec: 每秒从服务器端接收到的数据量
科普:
90% Line 参数正确的含义:
90% Line - 90% of the samples took no more than this time. The remaining samples at least as long as this.
“ 90% 的样品没有超过这个时间,剩余的样品至少只要这个。”
没太理解是什么意思,于是,点击详细解释。
90% Line (90 th Percentile) is the value below which 90% of the samples fall. The remaining samples too at least as long as the value. This is a standard statistical measure. See, for example: Percentile entry at Wikipedia.
英语太差,还是没理解到底啥意思,不过最后提示我,用维基百科查一下什么是百分位数。
百分位数:
统计学术语,如果将一组数据从大到小排序,并计算相应的累计百分位,则某一百分位所对应数据的值就称为这一百分位的百分位数。可表示为:一组n个观测值按数值大小排列如,处于p%位置的值称第p百分位数。
90% Line
一组数由小到大进行排列,找到他的第90%个数(假如是12),那么这个数组中有90%的数将小于等于12 。
用在性能测试的响应时间也将非常有意义,也就是90%请求响应时间不会超过12 秒。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号