halcon 的深度学习标注训练集hdict格式转YOLO的标注训练集txt格式 halcon深度学习数据集与其他数据集转换
原文作者:aircraft
原文链接:halcon 的深度学习标注训练集hdict格式转YOLO的标注训练集txt格式
有兴趣可以多看其他的halcon教程
今天搜了一下halcon的标注训练集转YOLO的txt格式,搜了一圈发现网上没有,所以就自己写一个分享出来好了
主流数据的格式如下:
YOLO:txt格式
CreateML:json格式
PasclVOC:xml格式
halcon:hdict格式
一.halcon的hdict格式转YOLO的txt格式
首先来看一下YOLO的txt训练集的格式:
第一列:对象类别ID:一个整数,表示对象的类别。类别ID通常从0开始编号。
第二列:中心点坐标X:浮点数,表示对象边界框中心点的X坐标,以图像宽度的比例表示。
第三列:中心点坐标Y:浮点数,表示对象边界框中心点的Y坐标,以图像高度的比例表示。
第四列:边界框宽度:浮点数,表示对象边界框的宽度,以图像宽度的比例表示。
第五列:边界框高度:浮点数,表示对象边界框的高度,以图像高度的比例表示。
然后发现除了ID,其他数据都是小于1的,这是因为YOLO的标注数据集的坐标都除以了图像自身的宽高,将坐标都归一化到0-1之间
5 0.842388 0.746833 0.312116 0.306100
4 0.544041 0.719306 0.257871 0.480070
3 0.175594 0.727013 0.357181 0.354547
2 0.866589 0.249695 0.237008 0.338031
1 0.557394 0.249695 0.358016 0.439331
0 0.182687 0.248044 0.368030 0.398591
然后在来看一下halcon目标检测的数据集hdict里的格式:
class_ids:就是标注的ID编号
class_names:ID编号对应的具体标注名称
image_dir:训练图像存在的根目录
samples:每张图的标注数据,注意看里面还有多少个行列数据,还有每个框得ID,那些就是一张图里的标注框的数据了
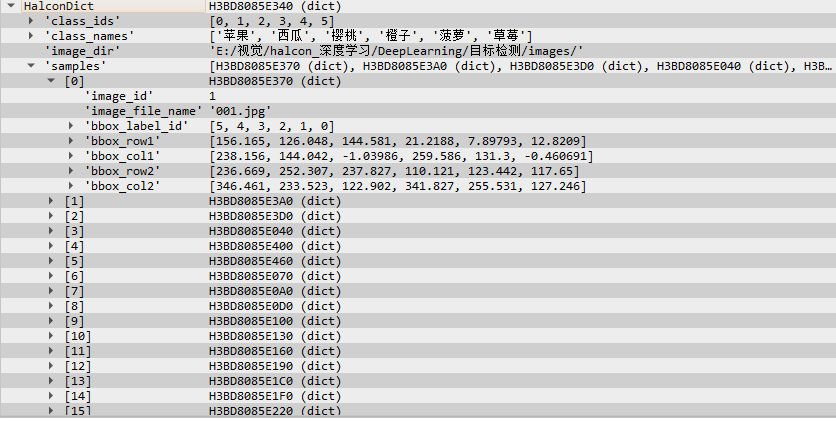
知道了两个数据集的数据区别了,那么我就可以开始转换了,有了每个框的对角点的行列坐标,我们就可以求出框中心坐标,以及框的宽度和高度,这样我们就把YOLO 的TXT数据集里的数据都拿到了,只要整合一下往文件里写就行了
halcon实现代码:
* --------------------------------------------------------------
* Halcon深度学习数据集转YOLO格式转换脚本
* 版本:v1.0(适配Halcon 22)
* 功能:将Halcon的.hdict标注文件转换为YOLO格式的txt标注文件和图像数据集
* --------------------------------------------------------------
* ************ 步骤1:读取Halcon标注数据集 ************
read_dict ('images.hdict', [], [], HalconDict) // 读取Halcon标注文件
get_dict_param (HalconDict, 'keys', [], DatasetKeys) // 获取数据集主键列表
* 解析数据集结构(根据实际结构顺序调整索引)
get_dict_tuple (HalconDict, DatasetKeys[0], class_ids) // 类别ID列表
get_dict_tuple (HalconDict, DatasetKeys[1], class_names) // 类别名称列表
get_dict_tuple (HalconDict, DatasetKeys[2], image_dir) // 原图存储路径
get_dict_tuple (HalconDict, DatasetKeys[3], samples_list) // 样本数据列表
* ************ 路径配置部分 ************
image_dir := 'E:/学习测试/halcon/深度学习格式转换/halcon转YOLO/images/' // 修改为实际路径
* 创建输出目录(如果不存在)
file_exists ('yolo_labels', FileExists)
if(not FileExists)
make_dir ('yolo_labels') // 标签文件目录
make_dir ('yolo_images') // 图像文件目录
endif
* ************ 步骤2:创建类别映射字典 ************
* create_dict (ClassMap) // 初始化字典
* set_dict_tuple (ClassMap, 'defect', 0) // 缺陷类映射为0
* set_dict_tuple (ClassMap, 'scratch', 1) // 划痕类映射为1
* ************ 主处理循环:遍历每个样本 ************
Width := 128
Height := 128
for Index := 0 to |samples_list| - 1 by 1
samples := samples_list[Index] // 当前样本数据
* 解析样本元数据
get_dict_tuple (samples, 'image_file_name', samples_image_file_name) // 图像文件名
get_dict_tuple (samples, 'bbox_label_id', samples_bbox_label_id) // 标签ID列表
* 提取坐标数据
get_dict_tuple (samples, 'bbox_row1', samples_bbox_row1) // 左上角Y坐标
get_dict_tuple (samples, 'bbox_row2', samples_bbox_row2) // 右下角Y坐标
get_dict_tuple (samples, 'bbox_col1', samples_bbox_col1) // 左上角X坐标
get_dict_tuple (samples, 'bbox_col2', samples_bbox_col2) // 右下角X坐标
* ************ 图像处理部分 ************
ImageFileName := image_dir + samples_image_file_name // 拼接完整路径
if (Index == 0)
read_image (Image, ImageFileName) // 加载图像
get_image_size (Image, Width, Height) // 获取宽高尺寸
endif
* ************ 标注转换处理 ************
YoloAnnotations := [] // 初始化标注列表
for Index_label_id := 0 to |samples_bbox_label_id| - 1 by 1
* 提取当前bbox坐标
Row1 := samples_bbox_row1[Index_label_id]
Row2 := samples_bbox_row2[Index_label_id]
Col1 := samples_bbox_col1[Index_label_id]
Col2 := samples_bbox_col2[Index_label_id]
* ************ 坐标归一化计算 ************
XCenter := (real(Col1) + real(Col2)) / (2.0 * real(Width)) // X中心坐标
YCenter := (real(Row1) + real(Row2)) / (2.0 * real(Height)) // Y中心坐标
BoxWidth := (real(Col2) - real(Col1)) / real(Width) // 归一化宽度
BoxHeight := (real(Row2) - real(Row1)) / real(Height) // 归一化高度
ClassID := samples_bbox_label_id[Index_label_id] // 当前类别ID
* ************ 格式转换部分 ************
tuple_string (ClassID, 'd', ClassIDStr) // 整型类别ID
tuple_string (XCenter, '.6f', XCenterStr) // 浮点坐标转换
tuple_string (YCenter, '.6f', YCenterStr)
tuple_string (BoxWidth, '.6f', BoxWidthStr)
tuple_string (BoxHeight, '.6f', BoxHeightStr)
YoloLine := ClassIDStr+' '+XCenterStr+' '+YCenterStr+' '+BoxWidthStr+' '+BoxHeightStr // 拼接标注行
YoloAnnotations := [YoloAnnotations, YoloLine] // 添加到列表
endfor
* ************ 文件保存部分 ************
ImageFileName := regexp_replace(ImageFileName, '\\\\+', '/') // 路径标准化
FileName := regexp_replace(ImageFileName, '^.*/([^/]+)\\..*$', '$1') // 提取基础名
YoloLabelPath := 'yolo_labels/' + FileName + '.txt' // 生成标签路径
open_file (YoloLabelPath, 'append', FileHandle) // 打开文件(追加模式)
for LineIdx := 0 to |YoloAnnotations| - 1 by 1
fwrite_string (FileHandle, YoloAnnotations[LineIdx] + '\n') // 逐行写入
endfor
close_file (FileHandle) // 关闭文件句柄
* ************ 图像复制部分 ************
DestImagePath := 'yolo_images/' + samples_image_file_name // 目标路径
copy_file (ImageFileName, DestImagePath) // 执行文件拷贝
* 进度显示(每50个样本打印一次)
* if (Index % 50 == 0)
*
* endif
endfor
* --------------------------------------------------------------
* 步骤5:生成YOLO配置文件(Halcon 22需要显式编码声明) 下面的代码可以不用运行
* --------------------------------------------------------------
* YamlContent := ['% -*- encoding: utf-8 -*-', \
'path: ../yolo_dataset', \
'train: yolo_images', \
'val: yolo_images # 实际需要划分训练验证集', \
'test: # 可选', \
'', \
'names:', \
' 0: defect', \
' 1: scratch']
* 设置UTF-8编码(全局生效)
* set_system ('file_encoding', 'utf8')
* 打开文件(覆盖模式)
* open_file ('dataset.yaml', 'output', FileHandle)
* 逐行写入
* for LineIdx := 0 to |YamlContent| - 1 by 1
* fwrite_string (FileHandle, YamlContent[LineIdx] + '\n')
* endfor
* 关闭文件
* close_file (FileHandle)
代码如上,用的是halcon22版本的软件跑的,语法应该都差不多,复制应该都可以直接跑,注意在halcon软件跑觉得慢是因为你没有把halcon软件默认开启的图像数据之类的实时显示给关闭掉。单纯的数据运行都是很快的。
我的目录结构如下:
至于其他的格式互转可以看下面的博客:
目标检测中数据集格式之间的相互转换--coco、voc、yolo-------
https://blog.csdn.net/heart_warmonger/article/details/142036018
YOLO 的txt转halcon的hdict格式------
https://blog.csdn.net/weixin_50702038/article/details/141233711
PASCAL VOC 的XML格式 转 halcon的.hdict------
https://blog.csdn.net/songhuangong123/article/details/132541216

 浙公网安备 33010602011771号
浙公网安备 33010602011771号