【人脸伪造检测】Self-Supervised Video Forensics by Audio-Visual Anomaly Detection
一、研究动机
[!note]
原理:经过处理后的视频在视觉和音频信号之间通常会有不一致的现象,提出一种基于异常检测算法实现视频伪造取证。
挑战:不同于简单的检测不同步的例子,因为由于视频采集往往会有“延迟”现象,出现帧偏移现象
创新点:提出在视听特征中实现异常检测,该特征包含了视听特征的一致性
二、检测模型
在大量的真实视频上训练,学习视觉和音频信号是如何同时发生的,在推理阶段可以对音频视觉流不一致时分配低可能性;基于自回归模型拟合真实视频中视听同步特征检测异常,并且在训练过程中不需要任何伪造视频
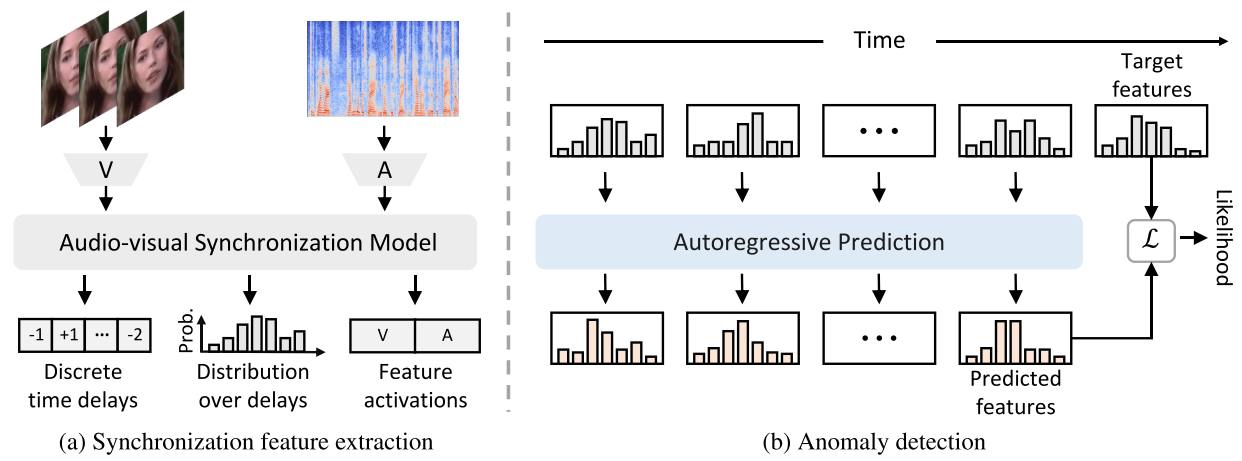
- 视听同步特征获取
从原视频中直接学习视听特征是困难的,为了能够更好的从真实视频中学习到视听特征,文章提出从特征集合中提取视听特征。基于Chen et al. [18].提出的模型计算视觉和听觉同时发生的概率\(\phi(V_i,A_i)\),并且通过一个时序滑动窗口计算同步性得分作为同步性得分概率,其中\(\tau\)表示最大的时间差(即为视频最大可能的帧偏移)

最后通过InfoNCE Loss对模型进行学习:
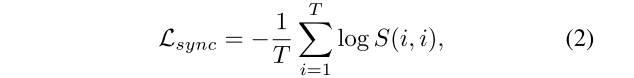
- 异常检测
基于上述模型提取的同步特征,进一步的需要对视频的同步特征异常进行检测。本篇文章学习了提取同步特征的分布,建立自回归模型学习这些分布,通过前\(i-1\)帧的特征预测第\(i\)帧的分布:\(x_{i+1} = p_ \theta(x_{i+1}|x_1,x_2,...,x_i)\),通过最大化对数概率损失学习自回归模型:
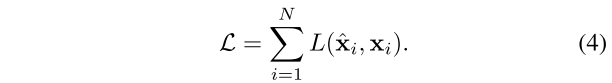
同步特征选取1:Discrete time delays
该特征表示当前帧相对于听觉信号的延迟(提前)的帧数, 特征为\(argmax_j(S(i,j))\)
同步特征选取2:Distributions over delays
虽然离散时间延迟(Discrete time delays)特征很容易表示出来,但是作为特征会损失很多信息,例如当前的延迟信息存在着歧义,因此,文章提出了预测完整的时间延迟分布作为同步特征,即每个帧的延迟时间的概率
三、实验
- 验证数据集:
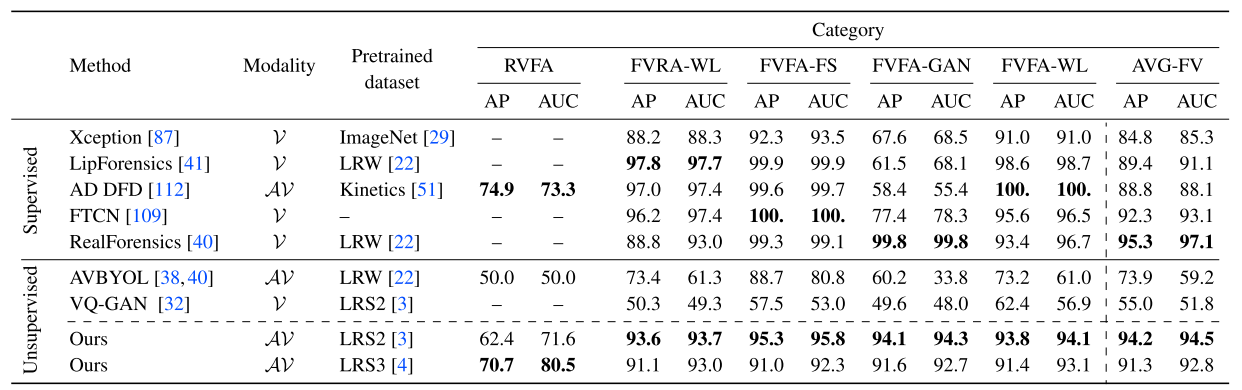
FakeAVCeleb和KoDF - 在
FakeAVCeleb数据集上不同模型的分析结果
- 不同语言
KoDF的数据集验证
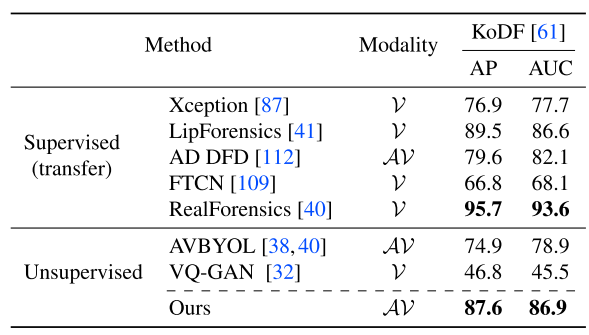
- 同步特征(Distributions over delays)可视化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号