[操作系统]零拷贝
什么是数据复制/数据拷贝(Copy)?
拷贝(Copy)数据,主要包括两种:CPU拷贝/ DMA拷贝。
第一类拷贝:CPU 拷贝(CPU Copy)
在 CPU 拷贝中,数据的传输是由中央处理器(CPU)直接进行的。当数据需要从一个内存区域拷贝到另一个内存区域时,CPU 首先将数据从源内存区域读取到 CPU 寄存器,然后再将数据从寄存器写入到目标内存区域。这个过程需要 CPU 的直接参与,因此称为 CPU 拷贝。CPU 拷贝的过程涉及多次读取和写入操作,较为耗时,特别是在大数据量传输时。
第二类拷贝:DMA 拷贝(Direct Memory Access Copy)
在 DMA 拷贝中,数据的传输是通过 DMA 控制器进行的,而不需要 CPU 的直接参与。
DMA 控制器是一种硬件设备,它能够在 CPU 不直接参与的情况下,将数据从一个内存区域传输到另一个内存区域。
在 DMA 拷贝中,CPU 将传输的任务交给 DMA 控制器,然后 DMA 控制器直接控制数据在内存之间的传输(DMA可以做到把数据从设备直接拷贝到内存缓冲区),减少了 CPU 的负担和参与,提高了数据传输的效率。
DMA 拷贝通常用于大数据量的传输,可以有效减少 CPU 的拷贝操作,提高传输速度。
总结起来,CPU 拷贝是指数据传输需要通过 CPU 进行读取和写入操作,而 DMA 拷贝是指数据传输通过 DMA 控制器直接进行,减少了 CPU 的介入。在性能敏感的场景中,DMA 拷贝通常比 CPU 拷贝更高效。
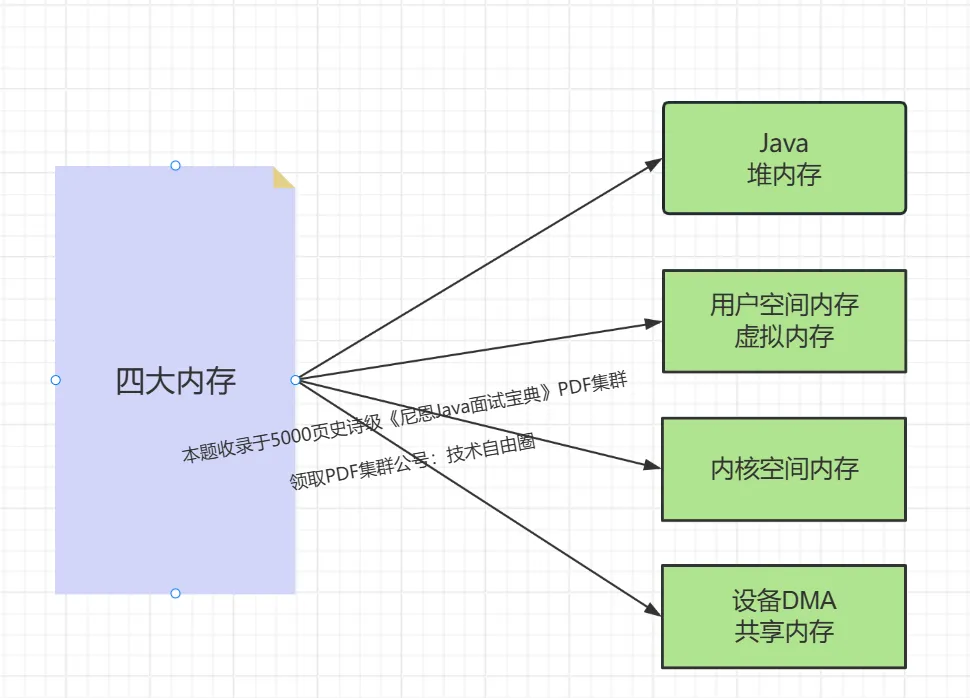
什么是四大内存?
零拷贝是指CPU不需要在用户空间和用户空间、用户空间和内核空间之间、内核空间和设备共享内存之间拷贝数据,消耗资源。(**重点是解放CPU**)
- 用户空间和用户空间
- 用户空间和内核空间
- 内核空间和物理设备共享内存
什么是用户空间,什么是内核空间,两个概念说起来虚头巴脑的。
以 Java SOCKET 的IO为例,主要涉及四大内存:
数据发送到网卡的流程
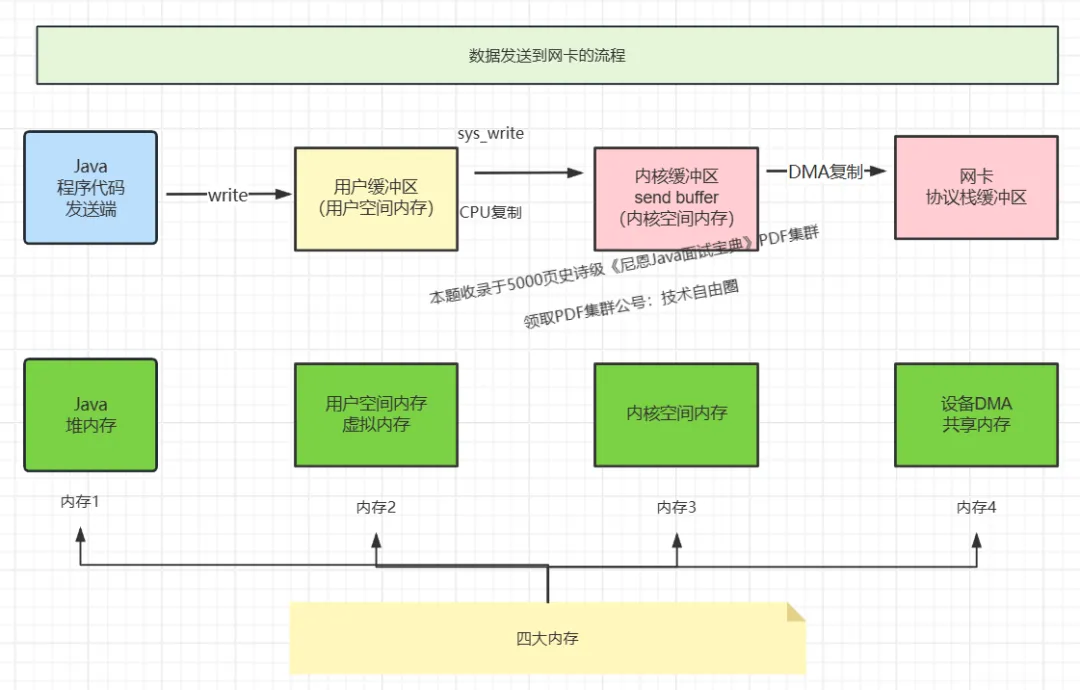
通过到网卡读取数据的流程

接收 SOCKET 数据包的流程
接收SOCKET 数据包是一个复杂的过程,涉及很多底层的技术细节,但大致需要以下几个步骤:
- 网卡收到数据包。
- 将数据包从网卡硬件缓存转移到服务器内存中。
- 通知内核处理。
- 经过TCP/IP协议逐层处理。
应用程序通过read()从socket buffer读取数据。
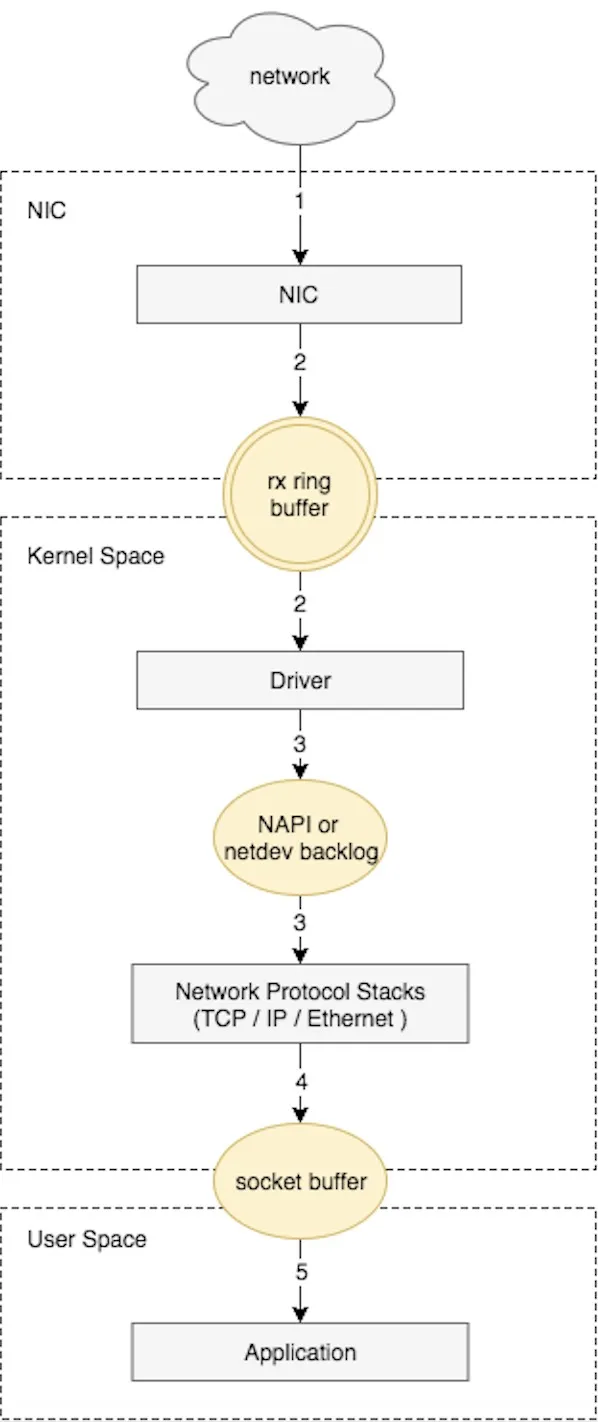
NIC(Network Interface Card ,网络接口卡、网卡)在接收到数据包之后,首先需要将数据同步到内核中,这中间的桥梁是rx ring buffer。
rx ring buffer 是由NIC和驱动程序共享的一片区域,事实上,rx ring buffer存储的并不是实际的packet数据,而是一个描述符,这个描述符指向了它真正的存储地址,具体流程如下:
驱动在内存中分配一片缓冲区用来接收数据包,叫做sk_buffer;
将上述缓冲区的地址和大小(即接收描述符),加入到rx ring buffer。描述符中的缓冲区地址是DMA使用的物理地址;
驱动通知网卡有一个新的描述符;
网卡从rx ring buffer中取出描述符,从而获知缓冲区的地址和大小;
网卡收到新的数据包;
网卡将新数据包通过DMA直接写到sk_buffer中。
图片
这个时候,数据包已经被接受,已经被转移到了sk_buffer中。
sk_buffer 是驱动程序在内存中分配的一片缓冲区,并且sk_buffer 是通过DMA写入的.
由于使用了 DMA, 这里就不依赖CPU直接将数据写到了内存中,对于内核来说, 减轻了负担。
但是, 硬币都有反面。既然DMA 负责写入的操作,这就意味着对内核来说,其实并不知道已经有新数据到了内存中。
那么如何让内核知道有新数据进来了呢?
答案就是中断,NIC 通过中断告诉内核有新数据进来了,并需要进行后续处理。
当NIC把数据包通过DMA复制到内核缓冲区sk_buffer后,NIC立即发起一个硬件中断。
DMA复制完数据后,NIC首先进入第一步 硬中断部分,网卡中断对应的中断处理程序是网卡驱动程序的一部分,CPU执行中断处理程序, 中断处理程序 它发起软中断,进入第3 软中断处理程序部分,开始消费sk_buffer中的数据,交给内核协议栈处理。协议栈处理把数据复制到 SOCKET 的缓存。
图片
这个时候,数据完成了 从网卡的缓冲区进入到了 receive buffer 接受缓冲区, 这就是 内核缓存区,也是内核空间内存。
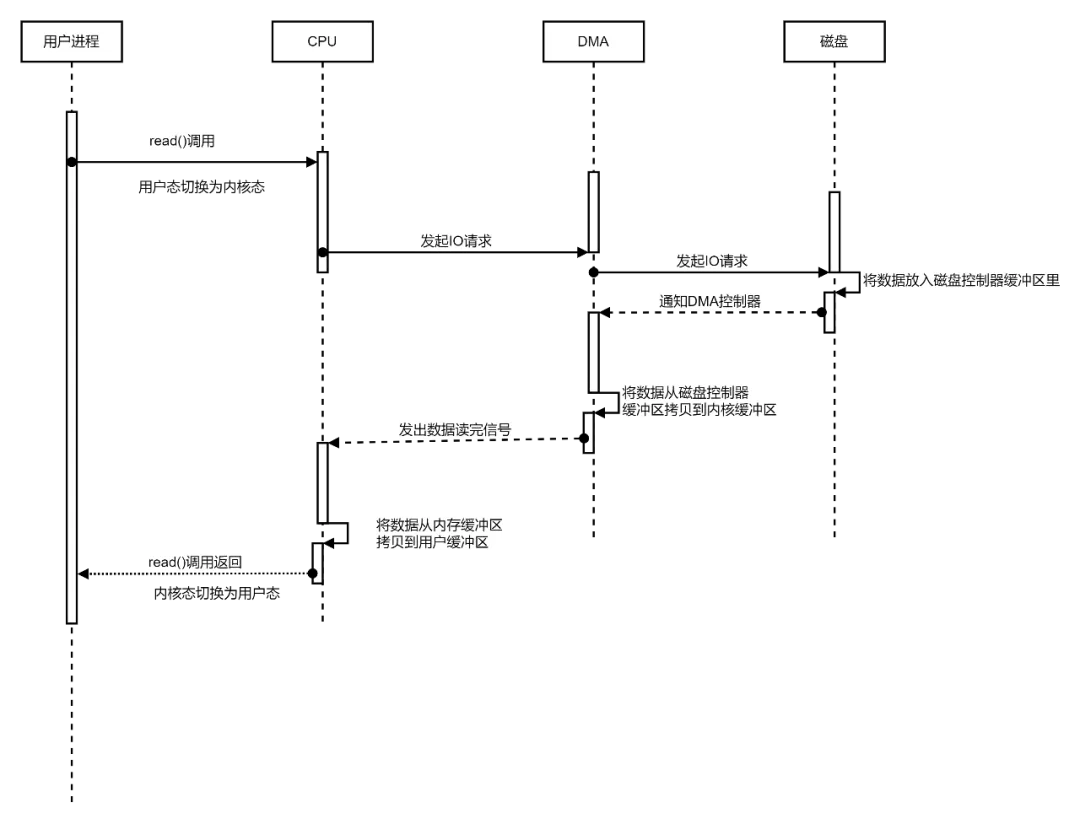
DMA 简介
DMA的全称叫直接内存存取(Direct Memory Access), 是一种允许外围设备(硬件子系统)直接访问系统主内存的机制,也就是,基于DMA访问方式,系统主内存与硬盘或网卡之间的数据传输可以绕开CPU的全程调度。目前大多数的硬件设备,包括磁盘控制器,网卡,显卡以及声卡等支持DMA技术。
整个数据传输操作在一个DMA控制器下进行的。CPU 除了在数据传输开始和结束时做一点处理外(开始和结束时要做中断处理),在传输过程中CPU可以继续进行其他的工作。为了减少CPU对快速设备入出的操作,可以通过把这 批数据的传输过程交由一块专用的接口卡(DMA接口)来控制,让DMA卡代替CPU控制在快速设备与主存储器之间直接传输数据。
在DMA模式下,CPU只须向DMA控制器下达指令,让DMA控制器来处理数据的传送,数据传送完毕再把信息反馈给CPU,这样就很大程度上减轻了 CPU资源占有率。DMA传输的优势:给CPU 带来了解脱 。通过 DMA ,大部分时间里 cpu计算和I/0操作可以处于并行操作,使整个IO的效率大大提升。
基于DMA技术的IO基础流程如下:
什么是零拷贝?零复制的5大类型:
零拷贝(Zero-Copy)是一种数据传输和处理的优化技术,旨在减少数据在系统内部的复制次数,从而提高数据传输的效率和性能。
在传统的数据传输过程中,数据需要在不同的内存区域之间进行多次复制,这会消耗CPU和内存带宽,降低系统性能。
零拷贝技术通过最小化或消除这些复制操作来提升性能。
在零拷贝技术中,主要有以下几种关键思想和机制:
类型1:用户空间和内核空间共享内存:
零拷贝技术允许用户空间和内核空间共享同一块内存区域,这样数据可以直接在内核和用户空间之间传递,避免了复制的开销。
比如,基于mmap的内存映射技术,如下图所示:
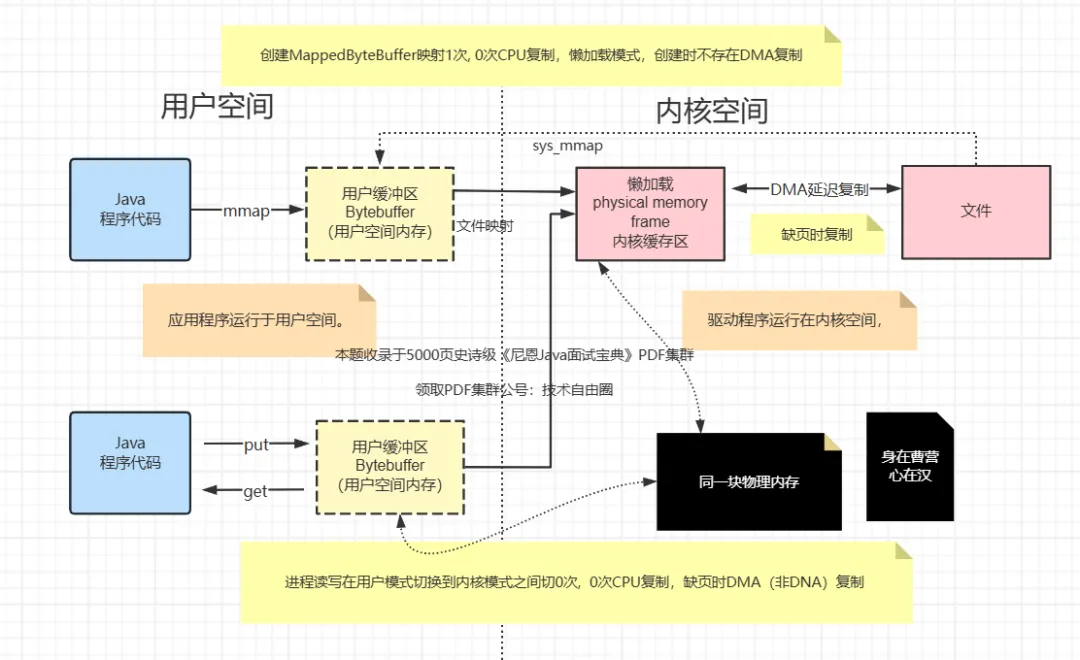
类型2:直接内存访问(DMA):
零拷贝技术使用DMA来实现数据传输,DMA允许外设(如网络适配器、磁盘控制器等)直接访问系统内存,而不需要CPU的干预。
这样数据可以在内存和外设之间直接传递,减少CPU拷贝的步骤。
比如,基于DMA的网卡直接内存复制技术,如下图所示:

类型3:文件描述符传递:
零拷贝技术允许在不同的进程之间传递文件描述符,而不是传递实际的数据。这样可以避免数据的多次复制。
比如,使用sendfile 时,直接传递文件文件描述符和偏移量, 实现全部的DMA 复制。
零拷贝技术允许内核空间进行一些数据的复制操作,但这些复制操作是在内核空间内进行的,不会涉及到用户空间,从而减少了用户空间到内核空间的切换。
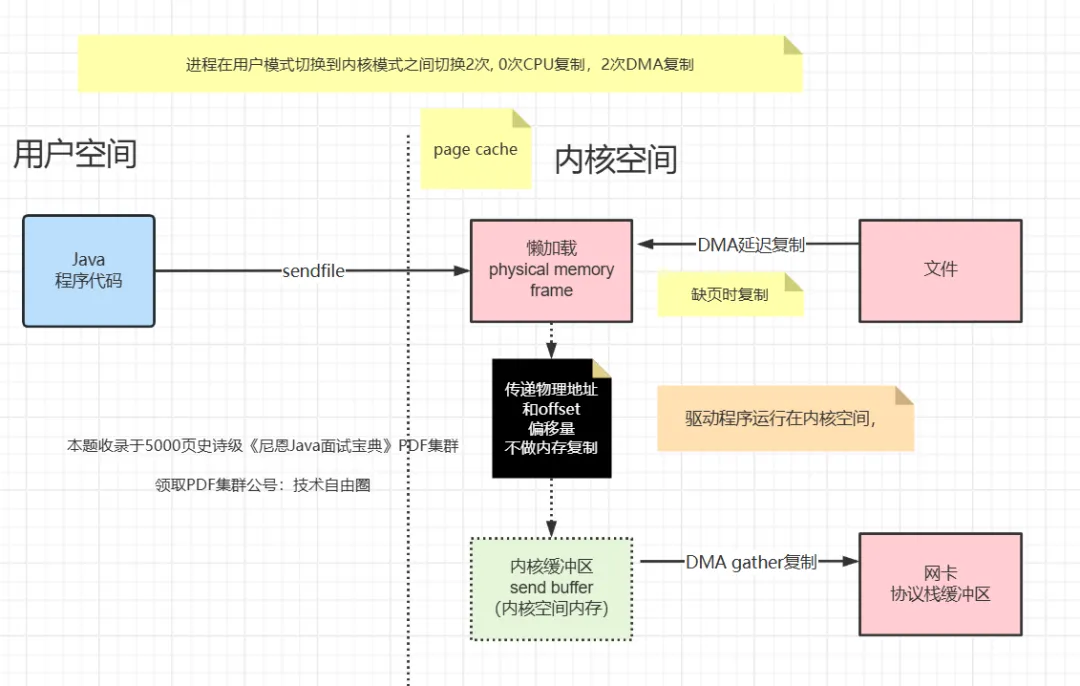
类型4:逻辑内存的数据零复制:
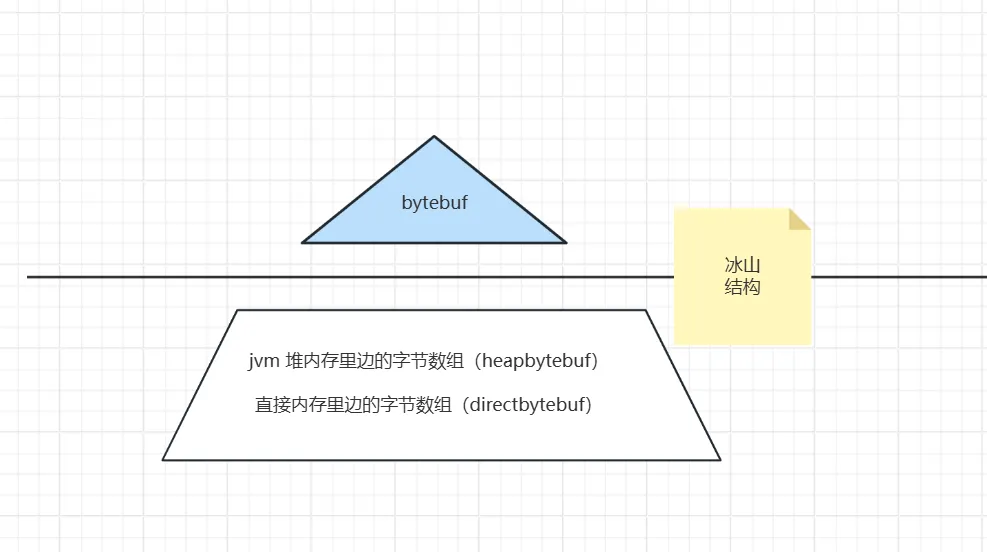
逻辑内存的数据零复制,指的是不复制数据, 不去移动底层的 字节数据。只维护字节数据的 元数据信息。
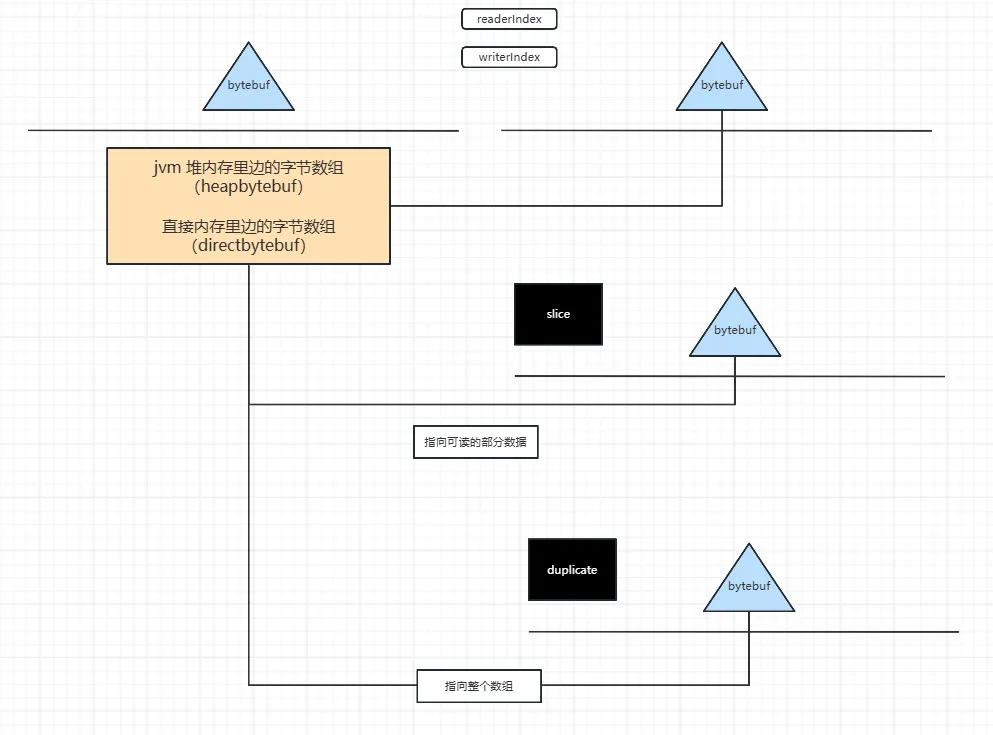
我们知道,Java中的内存,无论是Netty的 ByteBuf ,还是NIO的 bytebuffer,都是冰山结构。

既然是这种二元结构,那么就可以进行逻辑层面的内存的数据复制, 不去动底层的 字节数组。
比如:Netty提供CompositeByteBuf类实现逻辑内存的数据零复制。
使用方式:
CompositeByteBuf compositeByteBuf = Unpooled.compositeBuffer(3);
compositeByteBuf.addComponents(true,ByteBuf1,ByteBuf1);
需要注意的是addComponents第一个参数必须为true, 那么writeIndex 才不为0,才能从compositeByteBuf中读到数据.
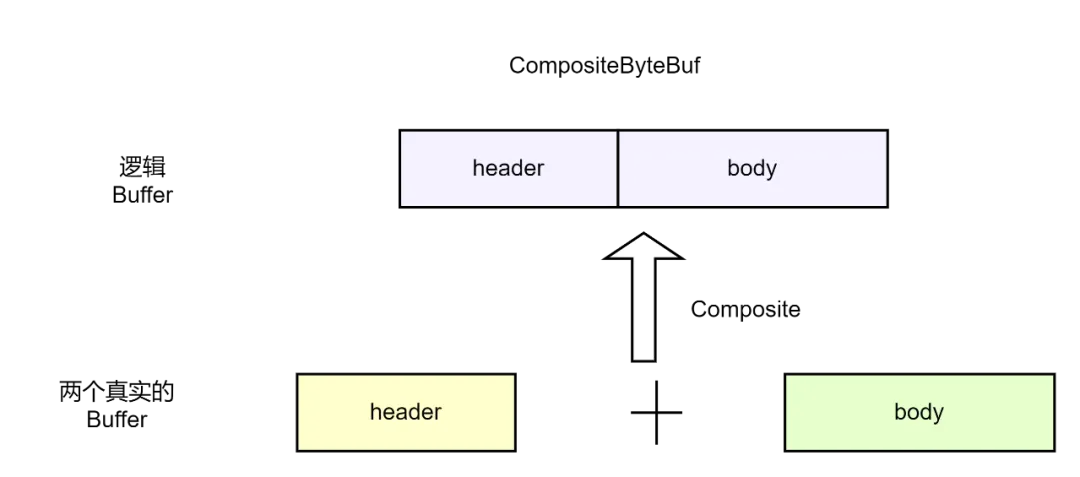
通过 逻辑内存的数据零复制,可以将多个ByteBuf合并为一个逻辑上的ByteBuf,避免了底层数组之间的拷贝.
除此之外, netty的 bytebuf 切片, 也是 逻辑内存的数据零复制 的类型。
类型5:Java通过JNI直接使用本地内存:
Java通过JNI直接使用本地内存,进行本地内存的读写,可以避免本地内存到堆内存直接的一次复制。

在Java中分配直接内存大有如下三种主要方式:
Unsafe.allocateMemory()
ByteBuffer.allocateDirect()
native方法
Unsafe类
Java提供了Unsafe类用来进行直接内存的分配与释放
public native long allocateMemory(long var1);
public native void freeMemory(long var1);
示例
public class DirectMemoryMain {
public static void main(String[] args) throws InterruptedException {
Unsafe unsafe = getUnsafe();
while (true) {
for (int i = 0; i < 10000; i++) {
long address = unsafe.allocateMemory(10000);
// System.out.println(address);
// unsafe.freeMemory(address);
}
Thread.sleep(1);
}
}
// Unsafe无法直接使用,需要通过反射来获取
private static Unsafe getUnsafe() {
try {
Class clazz = Unsafe.class;
Field field = clazz.getDeclaredField("theUnsafe");
field.setAccessible(true);
return (Unsafe) field.get(null);
} catch (IllegalAccessException | NoSuchFieldException e) {
throw new RuntimeException(e);
}
}
}
DirectByteBuffer 直接内存
虽然Unsafe可以通过反射调用来进行内存分配,但是按照其设计方式,它并不是给开发者来使用的,而且Unsafe里面的方法也十分原始,更像是一个底层设施。
而其上层的封装则是DirectByteBuffer,这个才是最终留给开发者使用的。
DirectByteBuffer的分配是通过ByteBuffer.allocateDirect(int capacity)方法来实现的。
DirectByteBuffer申请内存的源码如下:
DirectByteBuffer(int cap) {
super(-1, 0, cap, cap);
// 计算需要分配的内存大小
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
// 告诉内存管理器要分配内存
Bits.reserveMemory(size, cap);
// 分配直接内存
long base = 0;
try {
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
// 计算内存的地址
if (pa && (base % ps != 0)) {
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
// 创建Cleaner
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}
整个DirectByteBuffer分配过程中,比较需要关注的Bits.reserveMemory()和Cleaner,Deallocator,其中Bits.reserveMemory()与分配相关,Cleaner、Deallocator则与内存释放相关。
零拷贝的三大优势
零拷贝的三大优势:
(1)尽可能避免不必要的CPU拷贝,让CPU解脱出来去执行其他的任务;(2)减少内存带宽的占用;(3)减少用户空间和操作系统内核空间之间的上下文切换;
零拷贝技术在各种场景中都有应用,特别是在高性能网络传输、文件系统操作和数据库访问等方面。
它可以显著提升数据传输的效率,降低系统的资源消耗,从而改善系统的性能。
一些常见的应用包括网络数据传输、文件的读写和数据库查询等。
零拷贝技术的目标是尽可能减少数据在系统内部的复制次数,从而提高数据传输的效率和性能。虽然零拷贝可以减少或避免某些复制操作,但并不是绝对不需要拷贝过程。
什么是CPU上下文切换/ 用户态与内核态切换?
在操作系统中,从用户态切换到内核态(核心态)以及从内核态切换回用户态是操作系统进行上下文切换的过程,涉及到处理器的特权级变更和寄存器保存与恢复。
这些切换是为了保护操作系统和应用程序的稳定性和安全性,同时允许内核执行特权指令。
从用户态切换到内核态: 当应用程序执行特权级操作(例如系统调用、硬件中断处理、异常处理等)时,需要从用户态切换到内核态。以下是从用户态切换到内核态的基本步骤:
触发切换请求: 应用程序通过系统调用或其他方式触发特权级操作的请求。
硬件响应: 处理器检测到特权级操作的请求,触发硬件中断或异常。
保存用户态上下文: 处理器将应用程序的用户态上下文(寄存器值、程序计数器等)保存到内核态的堆栈或内存区域。
切换到内核态: 处理器切换到内核态,将特权级提升为内核态,并跳转到内核态的处理程序(例如中断处理程序)。
执行内核态操作: 内核态的处理程序执行相应的操作,可能包括对资源的访问、状态更新等。
恢复用户态上下文: 处理器从内核态返回时,将之前保存的用户态上下文从堆栈或内存中恢复,使应用程序继续执行。
从内核态切换回用户态: 当内核态的操作完成后,需要将处理器从内核态切换回用户态,使应用程序继续执行。以下是从内核态切换回用户态的基本步骤:
保存内核态上下文: 内核态处理程序将内核态的上下文(寄存器值、状态等)保存到内核堆栈或内存中。
切换到用户态: 处理器切换回用户态,将特权级降低为用户态,并跳转到之前用户态的执行位置。
恢复用户态上下文: 处理器从用户态返回时,将之前保存的用户态上下文从堆栈或内存中恢复,使应用程序继续执行。
需要注意的是,上下文切换是一种开销较大的操作,因为涉及到寄存器值的保存和恢复,以及特权级的变更。在多任务操作系统中,频繁的上下文切换可能会影响系统性能。
而在每个任务运行前,CPU 都需要知道任务从哪里加载、又从哪里开始运行,也就是说,需要系统事先帮它设置好 CPU 寄存器和程序计数器(Program Counter,PC)。
CPU 寄存器,是 CPU 内置的容量小、但速度极快的内存。而程序计数器,则是用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置。它们都是 CPU 在运行任何任务前,必须的依赖环境,因此也被叫做 CPU 上下文。
图片
知道了什么是 CPU 上下文,我想你也很容易理解 CPU 上下文切换。
CPU 上下文切换,就是先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
而这些保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来。这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
我猜肯定会有人说,CPU 上下文切换无非就是更新了 CPU 寄存器的值嘛,但这些寄存器,本身就是为了快速运行任务而设计的,为什么会影响系统的 CPU 性能呢?
所以,根据任务的不同,CPU 的上下文切换就可以分为几个不同的场景,也就是进程上下文切换、线程上下文切换以及中断上下文切换。
进程上下文切换
Linux 按照特权等级,把进程的运行空间分为内核空间和用户空间,分别对应着下图中, CPU 特权等级的 Ring 0 和 Ring 3。
内核空间(Ring 0)具有最高权限,可以直接访问所有资源;
用户空间(Ring 3)只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问这些特权资源。
图片
换个角度看,也就是说,进程既可以在用户空间运行,又可以在内核空间中运行。进程在用户空间运行时,被称为进程的用户态,而陷入内核空间的时候,被称为进程的内核态。
从用户态到内核态的转变,需要通过系统调用来完成。比如,当我们查看文件内容时,就需要多次系统调用来完成:首先调用 open() 打开文件,然后调用 read() 读取文件内容,并调用 write() 将内容写到标准输出,最后再调用 close() 关闭文件。
那么,系统调用的过程有没有发生 CPU 上下文的切换呢?答案自然是肯定的。
CPU 寄存器里原来用户态的指令位置,需要先保存起来。接着,为了执行内核态代码,CPU 寄存器需要更新为内核态指令的新位置。最后才是跳转到内核态运行内核任务。
而系统调用结束后,CPU寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行进程。所以,一次系统调用的过程,其实是发生了两次 CPU 上下文切换。
不过,需要注意的是,系统调用过程中,并不会涉及到虚拟内存等进程用户态的资源,也不会切换进程。这跟我们通常所说的进程上下文切换是不一样的:
进程上下文切换,是指从一个进程切换到另一个进程运行。
而系统调用过程中一直是同一个进程在运行。
所以,系统调用过程通常称为特权模式切换,而不是上下文切换。但实际上,系统调用过程中,CPU 的上下文切换还是无法避免的。
那么,进程上下文切换跟系统调用又有什么区别呢?
首先,你需要知道,进程是由内核来管理和调度的,进程的切换只能发生在内核态。所以,进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。
因此,进程的上下文切换就比系统调用时多了一步:在保存当前进程的内核状态和CPU寄存器之前,需要先把该进程的虚拟内存、栈等保存下来;而加载了下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈。
如下图所示,保存上下文和恢复上下文的过程并不是“免费”的,需要内核在 CPU 上运行才能完成。
图片
根据 Tsuna 的测试报告,每次上下文切换都需要几十纳秒到数微秒的 CPU 时间。这个时间还是相当可观的,特别是在进程上下文切换次数较多的情况下,很容易导致 CPU 将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了真正运行进程的时间。这也正是上一节中我们所讲的,导致平均负载升高的一个重要因素。
另外,我们知道, Linux 通过 TLB(Translation Lookaside Buffer)来管理虚拟内存到物理内存的映射关系。当虚拟内存更新后,TLB 也需要刷新,内存的访问也会随之变慢。特别是在多处理器系统上,缓存是被多个处理器共享的,刷新缓存不仅会影响当前处理器的进程,还会影响共享缓存的其他处理器的进程。
知道了进程上下文切换潜在的性能问题后,我们再来看,究竟什么时候会切换进程上下文。
显然,进程切换时才需要切换上下文,换句话说,只有在进程调度的时候,才需要切换上下文。Linux 为每个 CPU 都维护了一个就绪队列,将活跃进程(即正在运行和正在等待CPU的进程)按照优先级和等待 CPU 的时间排序,然后选择最需要 CPU 的进程,也就是优先级最高和等待CPU时间最长的进程来运行。
那么,进程在什么时候才会被调度到 CPU 上运行呢?
最容易想到的一个时机,就是进程执行完终止了,它之前使用的CPU会释放出来,这个时候再从就绪队列里,拿一个新的进程过来运行。其实还有很多其他场景,也会触发进程调度,在这里我给你逐个梳理下。
其一,为了保证所有进程可以得到公平调度,CPU时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样,当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运行。
其二,进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行。
其三,当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度。
其四,当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。
最后一个,发生硬件中断时,CPU上的进程会被中断挂起,转而执行内核中的中断服务程序。
了解这几个场景是非常有必要的,因为一旦出现上下文切换的性能问题,它们就是幕后凶手。
线程上下文切换
说完了进程的上下文切换,我们再来看看线程相关的问题。
线程与进程最大的区别在于,线程是调度的基本单位,而进程则是资源拥有的基本单位。说白了,所谓内核中的任务调度,实际上的调度对象是线程;而进程只是给线程提供了虚拟内存、全局变量等资源。所以,对于线程和进程,我们可以这么理解:
当进程只有一个线程时,可以认为进程就等于线程。
当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。
另外,线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
这么一来,线程的上下文切换其实就可以分为两种情况:
第一种, 前后两个线程属于不同进程。此时,因为资源不共享,所以切换过程就跟进程上下文切换是一样。
第二种,前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据。
到这里你应该也发现了,虽然同为上下文切换,但同进程内的线程切换,要比多进程间的切换消耗更少的资源,而这,也正是多线程代替多进程的一个优势。
中断上下文切换
除了前面两种上下文切换,还有一个场景也会切换 CPU 上下文,那就是中断。
为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
跟进程上下文不同,中断上下文切换并不涉及到进程的用户态。所以,即便中断过程打断了一个正处在用户态的进程,也不需要保存和恢复这个进程的虚拟内存、全局变量等用户态资源。中断上下文,其实只包括内核态中断服务程序执行所必需的状态,包括CPU 寄存器、内核堆栈、硬件中断参数等。
对同一个 CPU 来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。同样道理,由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束。
另外,跟进程上下文切换一样,中断上下文切换也需要消耗CPU,切换次数过多也会耗费大量的 CPU,甚至严重降低系统的整体性能。所以,当你发现中断次数过多时,就需要注意去排查它是否会给你的系统带来严重的性能问题。
传统IO中的数据拷贝
传统C程序IO流程中数据拷贝
传统的JAVA程序IO流程中数据拷贝
C传统程序IO过程中数据拷贝
图片
详解C传统程序典型的IO系统调用流程: 写入流程
用户程序通过write 写系统调用,启动io操作。
step 1: write 写系统调用导致进程从用户态切换到内核态。
step 2: sys_write 内核函数,将用户空间内存数据放入内核地址空间缓冲区。
这是一次CPU负责的内存复制。
但是,这次将数据放入另一个与文件或者设备相关的缓冲区.
如果该内核地址缓冲区与套接字相关,叫做socket send buffer,如果与文件系统相关,叫做filesystem cache,
step 3: 当DMA引擎将数据从内核缓冲区传递到协议栈引擎时。
这是一次DMA负责的内存复制,CPU不用参与其中。
step 4: write系统调用返回,进程从内核模式切换到用户模式。
详解C传统程序典型的IO系统调用流程: 读取流程
step 1: read系统调用, 首先导致进程从用户模式切换到内核模式。
在阻塞式的IO模式下, 用户进程等待系统调用返回。系统会等待内核缓存中的数据。
step 2: 数据的最初的副本,由DMA引擎执行复制,复制到内核缓存。
这是一次DMA负责的内存复制,CPU不用参与其中。
DMA引擎读取文件内容(或者网卡协议栈缓存内容),并将其存储到内核地址空间缓冲区中。
step 3: sys_read 内核函数,将数据从内核缓冲区复制到用户缓冲区,然后读取的系统调用返回。
这是一次CPU负责的内存复制。
step 4: read调用返回,导致进程从内核切换回用户模式。
现在,数据存储在用户地址空间缓冲区中,并且进程可以重新开始。
内核空间和用户空间为什么要发生拷贝?
用户程序是绝对无法直接访问内核空间的,无法直接访问任意一块物理内存。
这块其实很复杂,和安全性有关,但主要的原因应该是:
用户空间的内存可能并不指向物理内存,直接访问时可能产生缺页异常。
但是Linux内核禁止在中断时产生缺页异常,否则会产生打印oops错误。
这就要求我们用户的缓冲区数据必须要存在内存中,而这个实际上很难控制,所以就会直接把数据复制到内核缓冲区中。
//缺页异常处理函数
asmlinkage void
do_page_fault(unsigned long address, unsigned long mmcsr,
long cause, struct pt_regs regs)
{
//省略一堆。。
//这里注释已经说的很清楚了,不允许在内核中执行缺页中断
/ If we're in an interrupt context, or have no user context,
we must not take the fault. /
if (!mm || faulthandler_disabled())
goto no_context;
}
//打印oops
no_context:
/ Oops. The kernel tried to access some bad page. We'll have to
terminate things with extreme prejudice. /
printk(KERN_ALERT "Unable to handle kernel paging request at "
"virtual address %016lx\n", address);
die_if_kernel("Oops", regs, cause, (unsigned long)regs - 16);
do_exit(SIGKILL);
Java传统程序IO流程中数据拷贝
图片
传统I/O操作的数据读写流程, 触发
4次上下文切换
4次CPU拷贝
2次DMA拷贝
图片
如果使用直接内存的一次传统网络send操作,则需要2次内存复制,如下图所示:
图片
使用java的堆内存地址值,与JNI堆外内存的地址值不一致的原因是:
由于JVM 的有自己的内存模型,JVM缓冲区起始地址和长度,与JNI堆外内存的值不一致,
所以,不能直接传递给JNI函数去调用底层的C语言内存操作函数.
为什么会在JVM堆内外之间发生数据拷贝
回顾:Linux进程内存布局
JVM虚拟机,对操作系统来说只是一个普通的Linux程序,所以除了Java的内存模型外,JVM整体使用的内存也符合Linux的堆栈区分配。
看下面这张经典的Linux进程内存布局图:
图片
不要把JVM的堆栈和C语言的堆栈弄混了,因为JVM属于C++程序,而我们所谓的Java堆实际上是一个C++对象,所以属于C语言的堆之内。至于Java线程的栈分配在C语言的堆还是栈上就看具体的虚拟机实现了,这个其实区别不大。
对于JVM的堆我们暂且叫做:Java Heap,之外的堆叫做C Heap。
对应的,ByteBuffer有allocate方法用来申请堆内和堆外缓冲区。
Java Heap和C Heap哪个效率更高?
其实差别不大,两个都是由malloc申请来的内存,可以理解为Java Heap属于C Heap的一部分,所以两者的读写效率肯定没什么差别。
但Java Heap有一个很重要的特性就是GC,在堆内GC的时候可能会移动其中的对象。这点很关键,因为这意味着我们的Java对象的内存地址并不是固定的。
这也解释了一个常见的疑问:‘Java的hashcode是否是内存地址?’,答案是否定的。因为Java规范要求应用运行其间hashcode值不能变,但Java对象的内存地址是会变化的。
JVM GC其间会移动对象的地址
由于JVM GC其间会移动对象的地址,包括byte[],而内核无法感知到内存的移动,很可能会导致数据错误。
这是因为JNI方法访问的内存区域是一个已经确定了的内存区域地质,那么该内存地址指向的是Java堆内内存的话,那么如果在操作系统正在访问这个内存地址的时候,Java在这个时候进行了GC操作,而GC操作会涉及到数据的移动操作
GC经常会进行先标志再压缩的操作。即,将可回收的空间做标志,然后清空标志位置的内存,然后会进行一个压缩,压缩就会涉及到对象的移动,移动的目的是为了腾出一块更加完整、连续的内存空间,以容纳更大的新对象,数据的移动会使对象的地址发生变化。
为什么会在堆内外之间发生数据拷贝
由于JVM只是一个普通的用户程序,所以涉及到系统功能时JVM必须把功能委托给操作系统提供的系统调用执行,这里我们研究一下IO操作中的write和read函数。
由于JVM GC其间会移动对象的地址,包括byte[],而内核无法感知到内存的移动,很可能会导致数据错误。
所以我们在以byte[]的形式写入数据时必须先把数据拷贝到不受JVM堆控制的堆外内存中,这部分就是我们说的C heap,而DirectByteBuffer正处于这片区域。
同样的,read的时候,我们也要保证在系统往缓冲区写入的时候我们不能gc移动内存,否则数据不知道写到了哪里,所以也会导致拷贝发生。
堆内外之间发生数据拷贝的必然性
所以我们在以byte[]的形式写入数据时必须先把数据拷贝到不受JVM堆控制的堆外内存中,这部分就是我们说的C heap,而DirectByteBuffer正处于这片区域。
同样的,read的时候,我们也要保证在系统往缓冲区写入的时候我们不能gc移动内存,否则数据不知道写到了哪里,所以也会导致拷贝发生。
堆内外之间发生数据拷贝减少的解决方案
直接使用堆外内存,如DirectByteBuffer。
这种方式是直接在堆外分配一个内存(即,native memory)来存储数据,程序通过JNI直接将数据读/写到堆外内存中。
因为数据直接写入到了堆外内存中,所以这种方式就不会再在JVM管控的堆内再分配内存来存储数据了,也就不存在堆内内存和堆外内存数据拷贝的操作了。
这样在进行I/O操作时,只需要将这个堆外内存地址传给JNI的I/O的函数就好了。
零复制的三大常见的实现技术
- DirectBuffer
- mmap+write
- sendfile
用户空间和内核空间共享内存 mmap
mmap+write零复制 就是其中的一种
mmap+write的代码
buf = mmap(file, len);
write(sockfd, buf, len);
用 mmap() 替换 read() 系统调用函数。
mmap() 系统调用函数会直接把内核缓冲区里的数据「映射」到用户空间,这样,操作系统内核与用户空间就不需要再进行任何的数据拷贝操作。
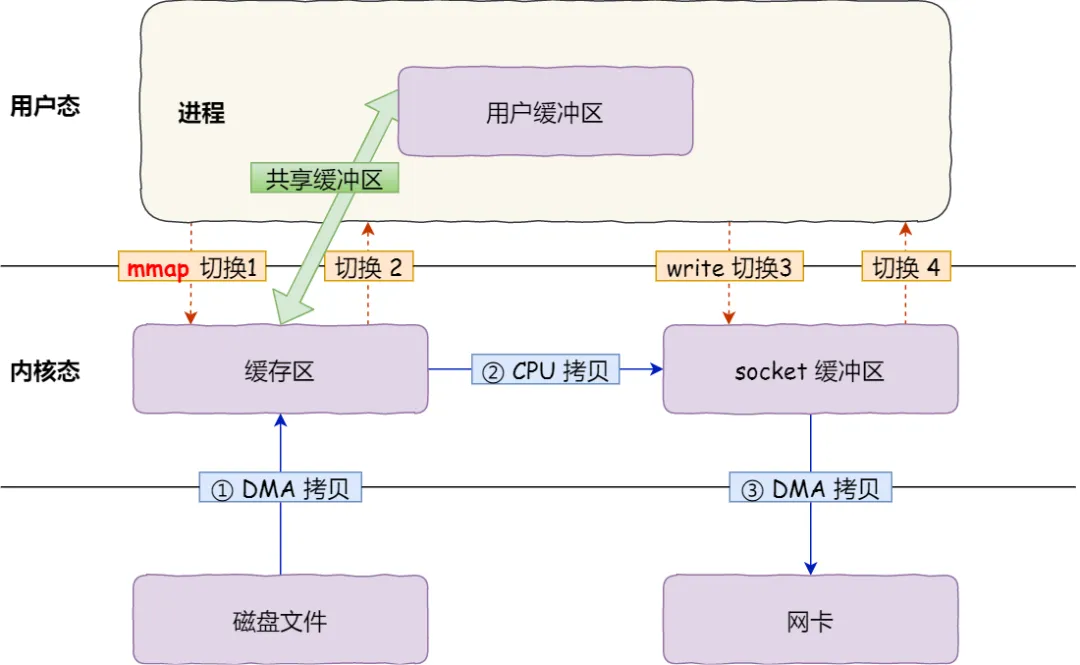
mmap用户可以直接操作内核缓冲区内的数据,减少了一次数据CPU拷贝,不影响上下文切换
mmap进行文件IO(读写)
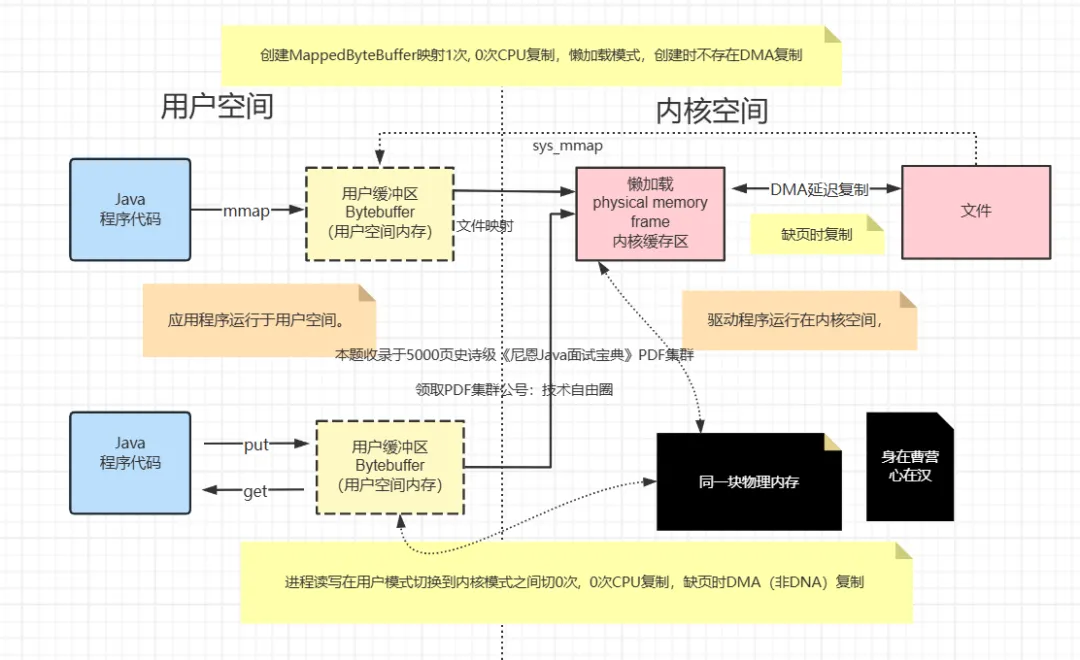
mmap+write零复制进行文件读+Socket写
参考的c代码:
tmp_buf = mmap(file, len);
write(socket, tmp_buf, len);
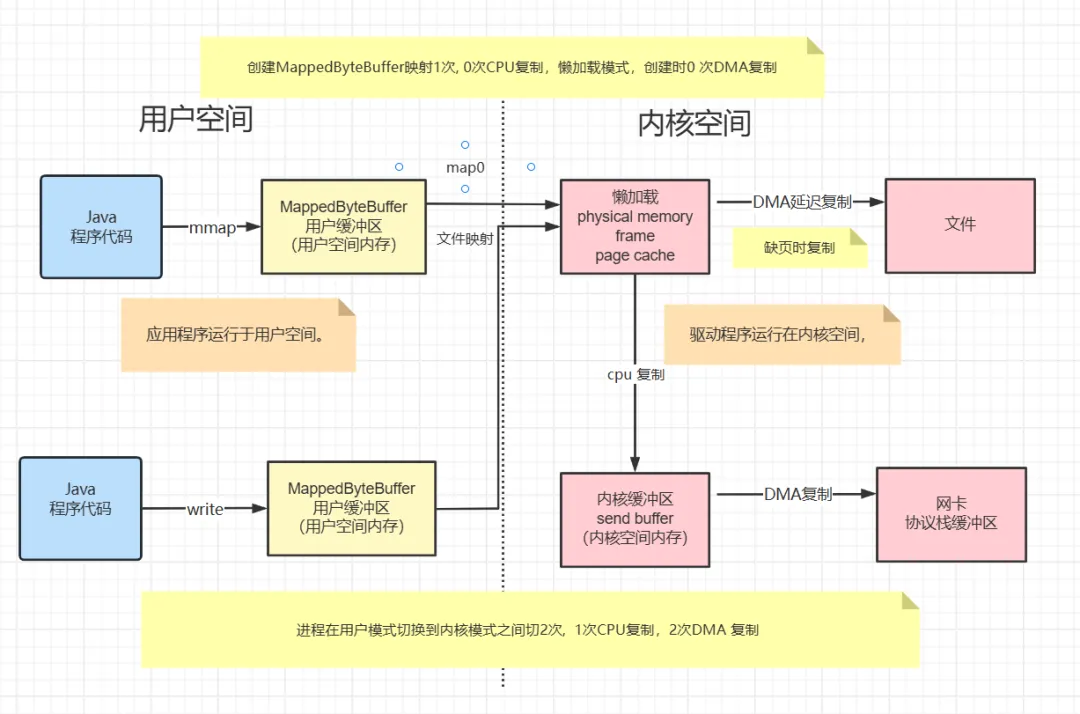
经典使用场景:
rocketmq 使用 mmap+write 发送文件里边的消息。
到这里就只有3次复制,其中只有1次CPU 复制,2次DMA 复制,4次上下文切换。
那能不能把CPU 复制减少到没有呢?
文件描述符传递零复制, sendfile
sendfile 零复制就是其中的一种
Linux Kernel 2.1 引进了 sendfile(),只需要一个系统调用来实现文件发送。
sendfile 函数
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
它的前两个参数分别是目的端和源端的文件描述符,后面两个参数是源端的偏移量和复制数据的长度,返回值是实际复制数据的长度。
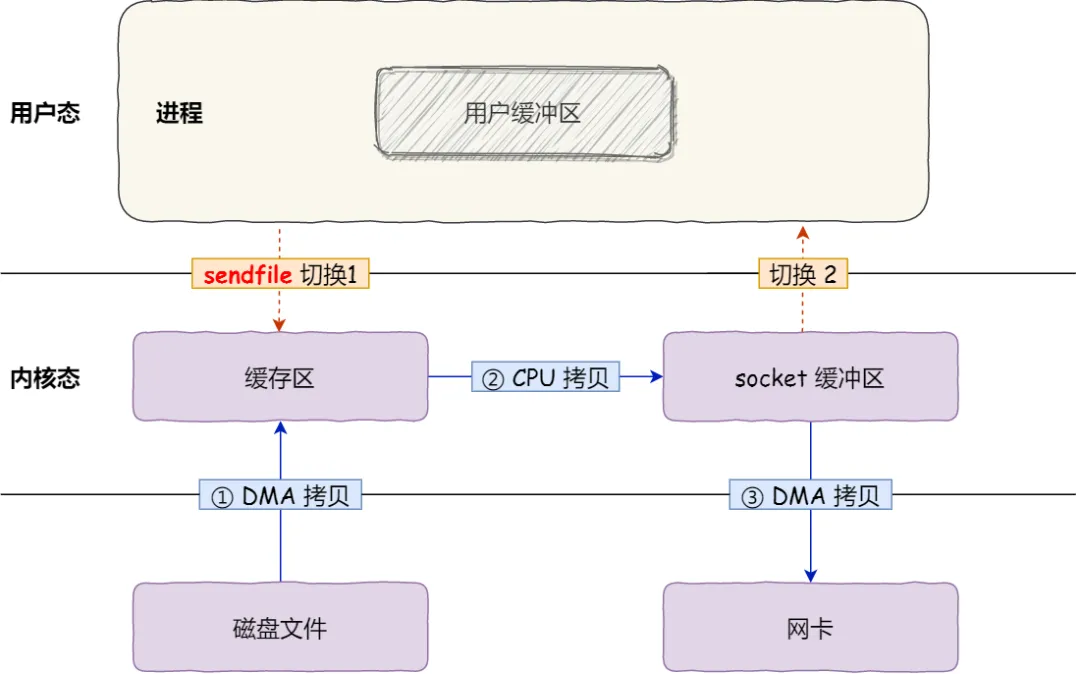
2次DMA 来实现数据传输,DMA允许外设(如网络适配器、磁盘控制器等)直接访问系统内存,而不需要CPU的干预。
一次CPU复制在内核空间完成。这样数据可以在内核空间和外设之间直接传递,减少CPU拷贝的步骤,不需要用户空间参与。
sendfile的使用
这种方式可以替换上面的mmap+write方式,如:
mmap();
write();
首先,sendfile可以替代前面的 read() 和 write() 这两个系统调用,这样就可以减少一次系统调用,也就减少了 2 次上下文切换的开销。
替换为
sendfile();
这样就减少了2次上下文切换,因为少了一个应用程序发起mmap操作,直接发起sendfile操作。
老版本sendfile减少了上下文切换

- sendfile系统调用使DMA引擎将文件内容复制到内核缓冲区中。
- 然后,数据被内核复制到与套接字关联的内核缓冲区中。
- 第三次复制发生在DMA引擎将数据从内核套接字缓冲区传递到协议引擎时。
到目前为止,我们已经能够避免让内核创建多个副本,但是我们仍然只剩下一个副本。也可以避免吗?
在内核版本2.4中,修改了套接字缓冲区描述符以适应这些要求-在Linux中称为零拷贝。
DMA Gather
Linux2.4内核进行了优化,提供了gather操作,这个操作可以把最后一次CPU Copy去除
于是,从 Linux 内核 2.4 版本开始起,对于支持网卡支持 SG-DMA 技术的情况下, sendfile() 系统调用的过程发生了点变化,具体过程如下:
第一步,通过 DMA 将磁盘上的数据拷贝到内核缓冲区里;
第二步,缓冲区描述符和数据长度传到 socket 缓冲区,这样网卡的 SG-DMA 控制器就可以直接将内核缓存中的数据拷贝到网卡的缓冲区里,此过程不需要将数据从操作系统内核缓冲区拷贝到 socket 缓冲区中,这样就减少了一次数据拷贝;
Linux Kernel 2.4 改进了 sendfile(),调用接口没有变化:
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
什么原理呢?
就是在内核空间Read Buffer和Socket Buffer不做数据复制,而是将Read Buffer的内存地址、偏移量记录到相应的Socket Buffer中,这样就不需要复制(其实本质就是和虚拟内存的解决方法思路一样,就是内存地址的记录)
(1)sendfile系统调用导致DMA引擎将文件内容复制到内核缓冲区中。
(2)没有数据被复制到套接字缓冲区中。相反,只有包含数据位置和长度信息的描述符才会附加到套接字缓冲区。DMA引擎将数据直接从内核缓冲区传递到协议引擎,从而消除剩余的最终副本。
DMA Gather零拷贝,数据不会在内核缓冲区之间重复。
新版本sendfile减少了最后一次cpu复制
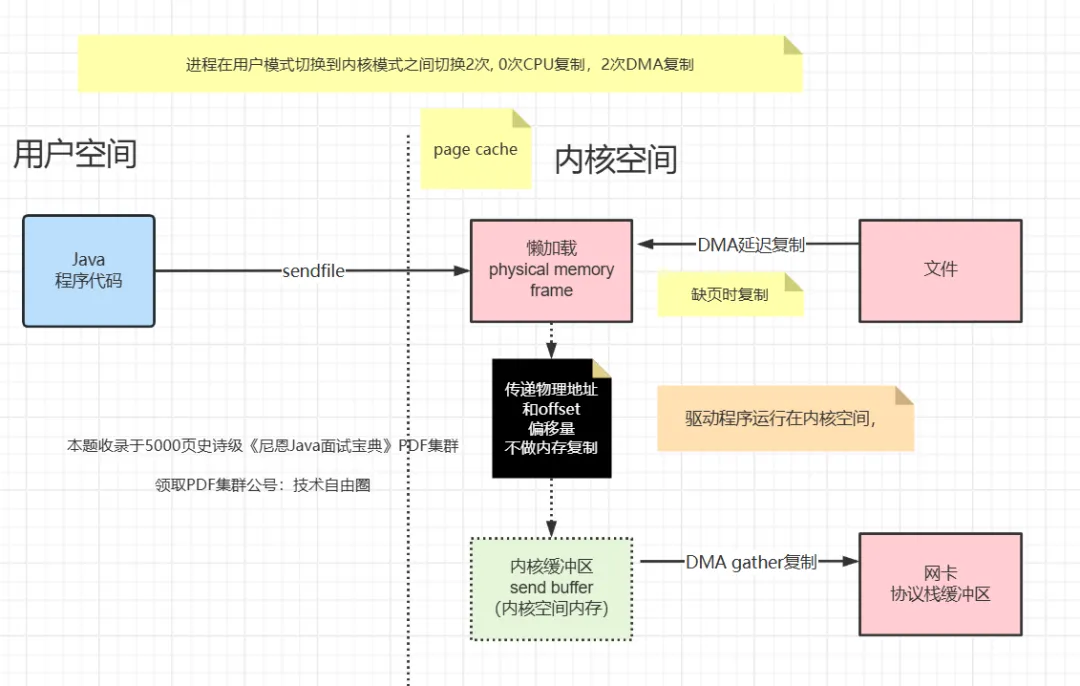
再来一副来自互联网的图:
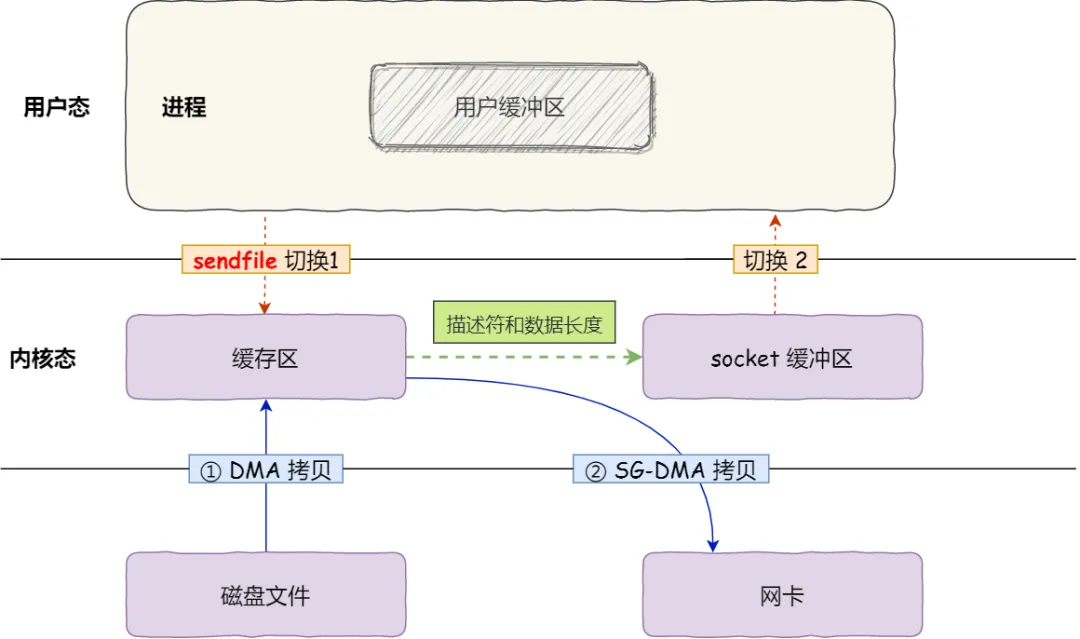
内核缓冲区直接拷贝到网卡,一次系统调用,两次上下文切换,两次拷贝,没有cpu拷贝,也就是真正意义上的零拷贝
来自互联网小伙伴的测试数据,在同样的硬件条件下,传统文件传输和零拷拷贝文件传输的性能差异,你可以看到下面这张测试数据图,使用了零拷贝能够缩短 65% 的时间,大幅度提升了机器传输数据的吞吐量。
sendfile这种方法不仅减少了多个上下文切换,而且还消除了处理器进行的数据重复。
到这里就只有2次复制,其中只有0次CPU 复制,2次DMA 复制,两次内核态和用户态切换。
在许多 http server 中,都引入了 sendfile 的机制,如 nginx、lighttpd 等,它们正是利用 sendfile() 这个特性来实现高性能的文件发送的。
kafka 使用 sendfile() 发送文件。
rocketmq 有类似的api。
Java通过JNI直接使用本地内存零复制
DirectBuffer 就是其中的一种,具体的图解如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号