2024数据采集与融合技术实践-作业2
作业①:
1)在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
1.核心代码描述
# 定义一个WeatherForecast类,用于获取和处理天气数据
class WeatherForecast:
def __init__(self):
# 设置HTTP请求头部,模拟浏览器访问
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
# 定义城市代码映射字典
self.cityCode = {"北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601"}
def forecastCity(self, city):
# 根据城市名称获取天气数据
if city not in self.cityCode.keys():
print(city + " code cannot be found")
return
# 构造访问天气数据的URL
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
# 发送HTTP请求并获取响应数据
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
# 解码响应数据,处理可能的编码问题
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
# 使用BeautifulSoup解析HTML数据
soup = BeautifulSoup(data, "lxml")
# 选择包含天气数据的HTML元素
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
# 提取日期、天气和温度信息
date=li.select('h1')[0].text
weather=li.select('p[class="wea"]')[0].text
temp=li.select('p[class="tem"] span')[0].text+"/"+li.select('p[class="tem"] i')[0].text
# 打印提取的天气数据
print(city,date,weather,temp)
# 将天气数据插入数据库
self.db.insert(city,date,weather,temp)
except Exception as err:
# 如果提取数据失败,打印错误信息
print(err)
except Exception as err:
# 同上
print(err)
def process(self, cities):
# 初始化数据库操作对象
self.db = WeatherDB()
self.db.openDB()
# 遍历城市列表,获取每个城市的天气数据
for city in cities:
self.forecastCity(city)
# 关闭数据库连接
self.db.closeDB()
2.输出信息

3.Gitee文件夹链接
作业2/1 · 舒锦城/2022级数据采集与融合技术 - 码云 - 开源中国
2)心得体会
通过该题目复习了数据库的相关操作,对数据库的使用更加熟练了,同时也复习了如何编写类和使用类,最主要的是能够规范的编写爬虫程序爬取想要的数据并存储,受益良多。
作业②:
1)用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
1.核心代码描述
try:
# 请求的URL,用于获取股票数据
url = 'https://push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409840494931556277_1633338445629&pn=1&pz=10&po=1&np=1&fltt=2&invt=2&fid=f3&fs=b:MK0021&fields=f12,f14,f2,f3,f4,f5,f6,f7,f8,f9,f10,f11,f18,f15,f16,f17,f23'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre'
} # 设置HTTP请求头部,模拟浏览器访问
response = requests.get(url, headers=headers) # 发送GET请求
# 处理响应文本,提取JSON数据
response_text = response.text.split('(', 1)[1].rsplit(')', 1)[0]
stock_data = json.loads(response_text)['data']['diff'] # 解析JSON数据
c = conn.cursor() # 获取数据库游标对象
for stock in stock_data: # 遍历股票数据
# 提取每只股票的详细信息
stock_code = stock['f12']
stock_name = stock['f14']
latest_price = stock['f2']
change_percent = stock['f3']
change_amount = stock['f4']
volume = stock['f5']
turnover = stock['f6']
amplitude = stock['f7']
high = stock['f15']
low = stock['f16']
open_price = stock['f17']
yesterday_close = stock['f18']
# 插入每行数据到stock_info表
c.execute('''
INSERT INTO stock_info
(stock_code, stock_name, latest_price, change_percent, change_amount, volume, turnover, amplitude, high, low, open_price, yesterday_close)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', (
stock_code, stock_name, latest_price, change_percent, change_amount, volume, turnover, amplitude, high,
low,
open_price, yesterday_close))
conn.commit() # 提交数据库操作
2.输出信息
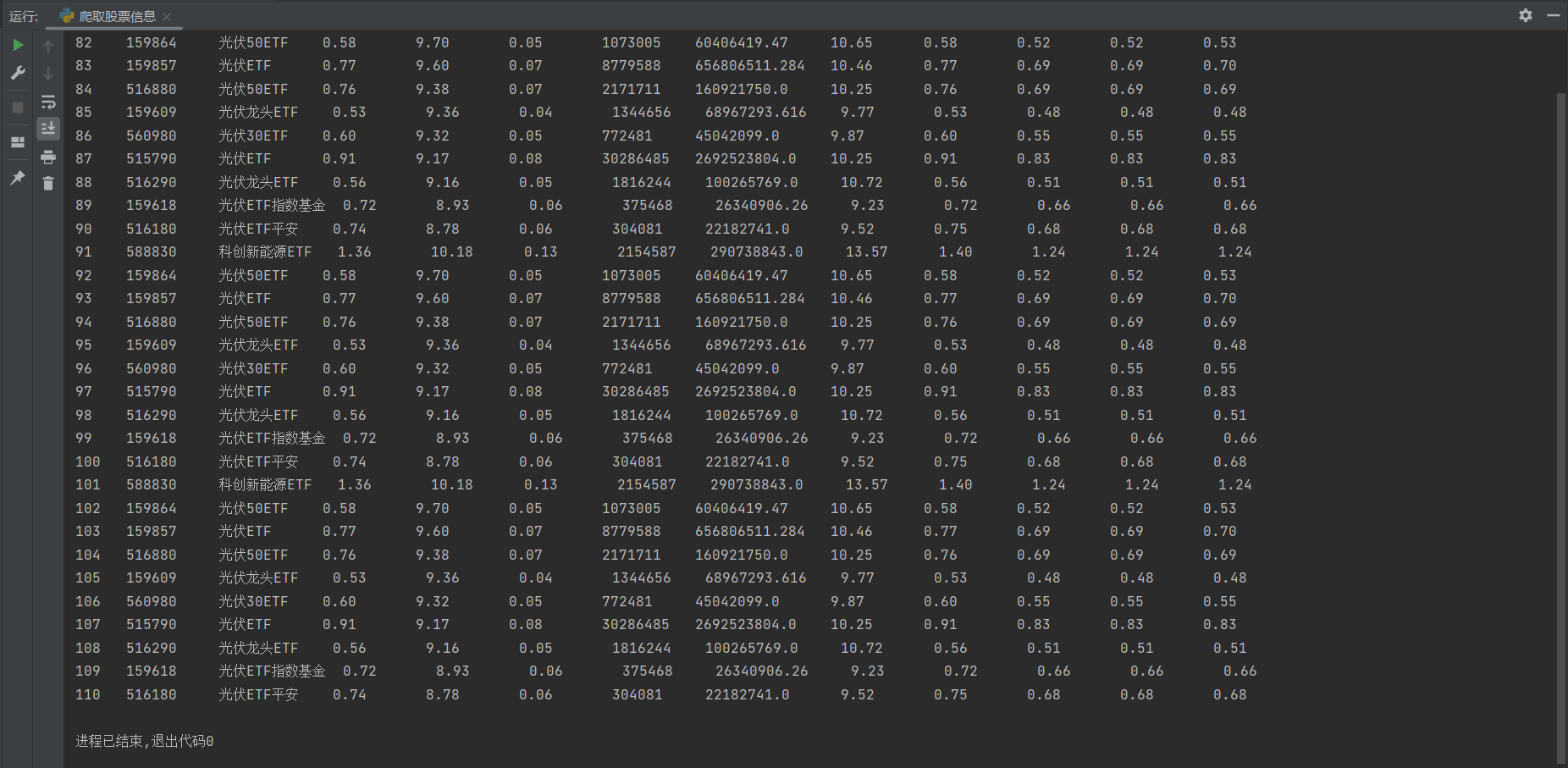
3.Gitee文件夹链接
作业2/2 · 舒锦城/2022级数据采集与融合技术 - 码云 - 开源中国
2)心得体会
通过该题目以及老师给的股票爬取教程学到了如何从网页中抓包获取想要的信息字段,能够精准的从网页中获取想要的数据,同时对数据量相对较大的网站能较为准确快速的获取自己的想要的数据了。
作业③:
1)爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
1.核心代码描述
url = 'https://www.shanghairanking.cn/rankings/bcur/2021' # 要抓取的网页URL
header = {
'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre'
}
html = url_text_get(url, header)
if html is None: # 如果获取页面失败,则退出程序
return
soup = BeautifulSoup(html, 'html.parser') # 使用BeautifulSoup解析HTML
rows = soup.find_all('tr') # 查找所有的表格行
print("排名\t学校名称\t\t省市\t学校类型\t总分") # 打印表头
init_db() # 初始化数据库和表结构
# 遍历每一行,提取并保存数据
for row in rows:
rank = row.find('td').text.strip() if row.find('td') else ""
name = row.find('span', class_="name-cn")
university_name = name.text.strip() if name else ""
province = row.find_all('td')[2].text.strip() if len(row.find_all('td')) > 2 else ""
type_of_university = row.find_all('td')[3].text.strip() if len(row.find_all('td')) > 3 else ""
total_score = row.find_all('td')[4].text.strip() if len(row.find_all('td')) > 4 else ""
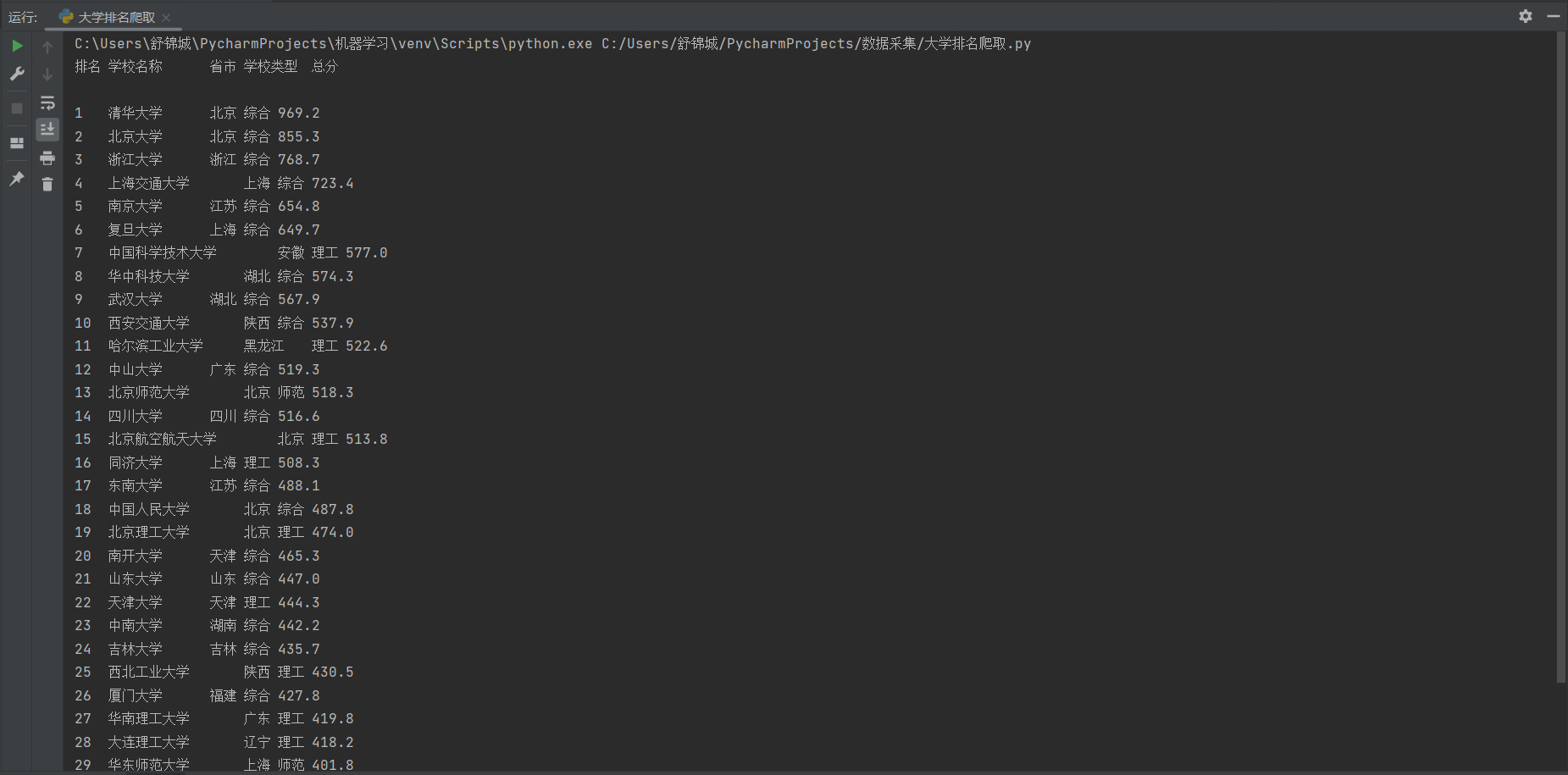
print(f"{rank}\t{university_name}\t\t{province}\t{type_of_university}\t{total_score}")
save_to_db(rank, university_name, province, type_of_university, total_score)
2.输出信息
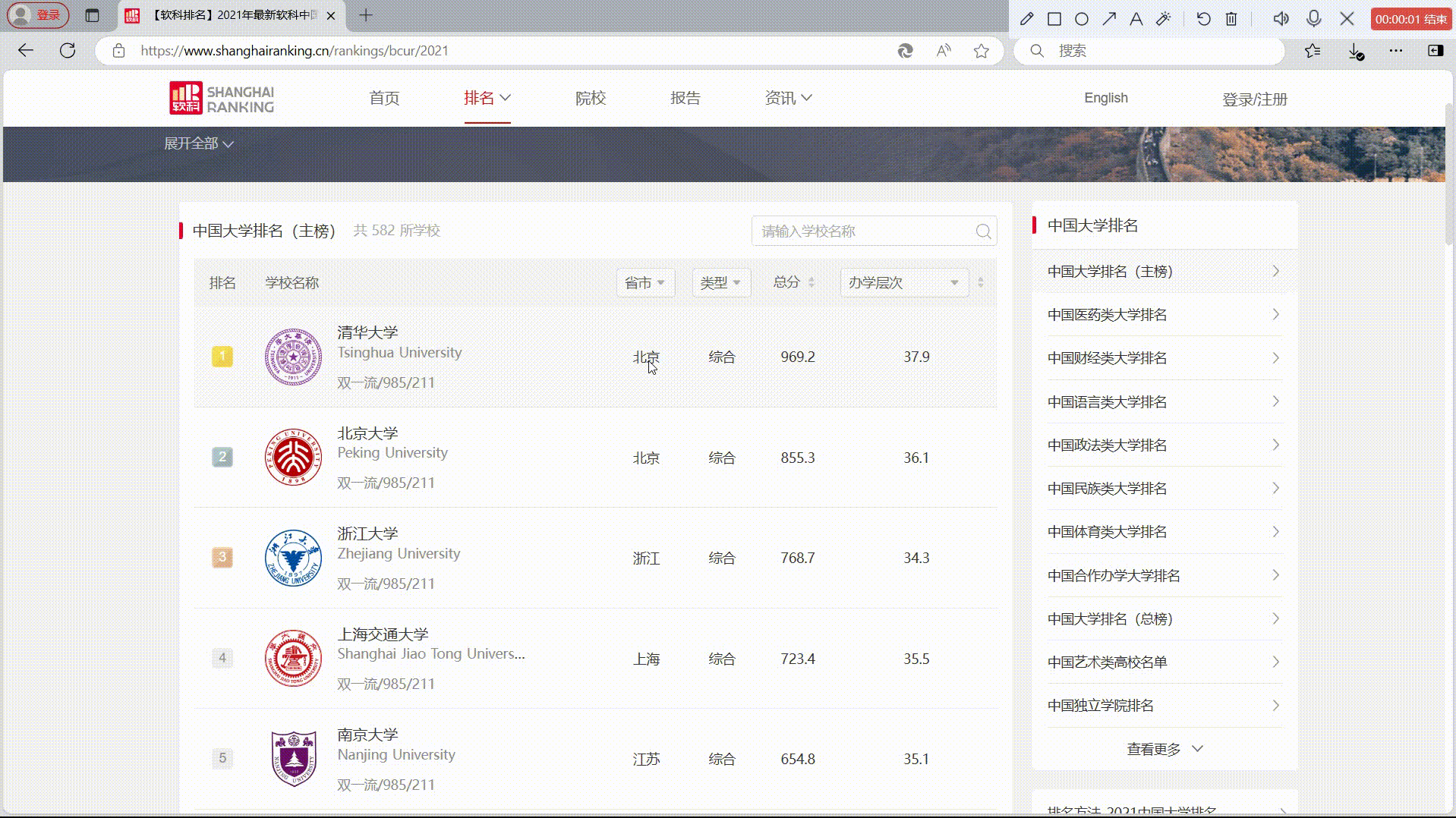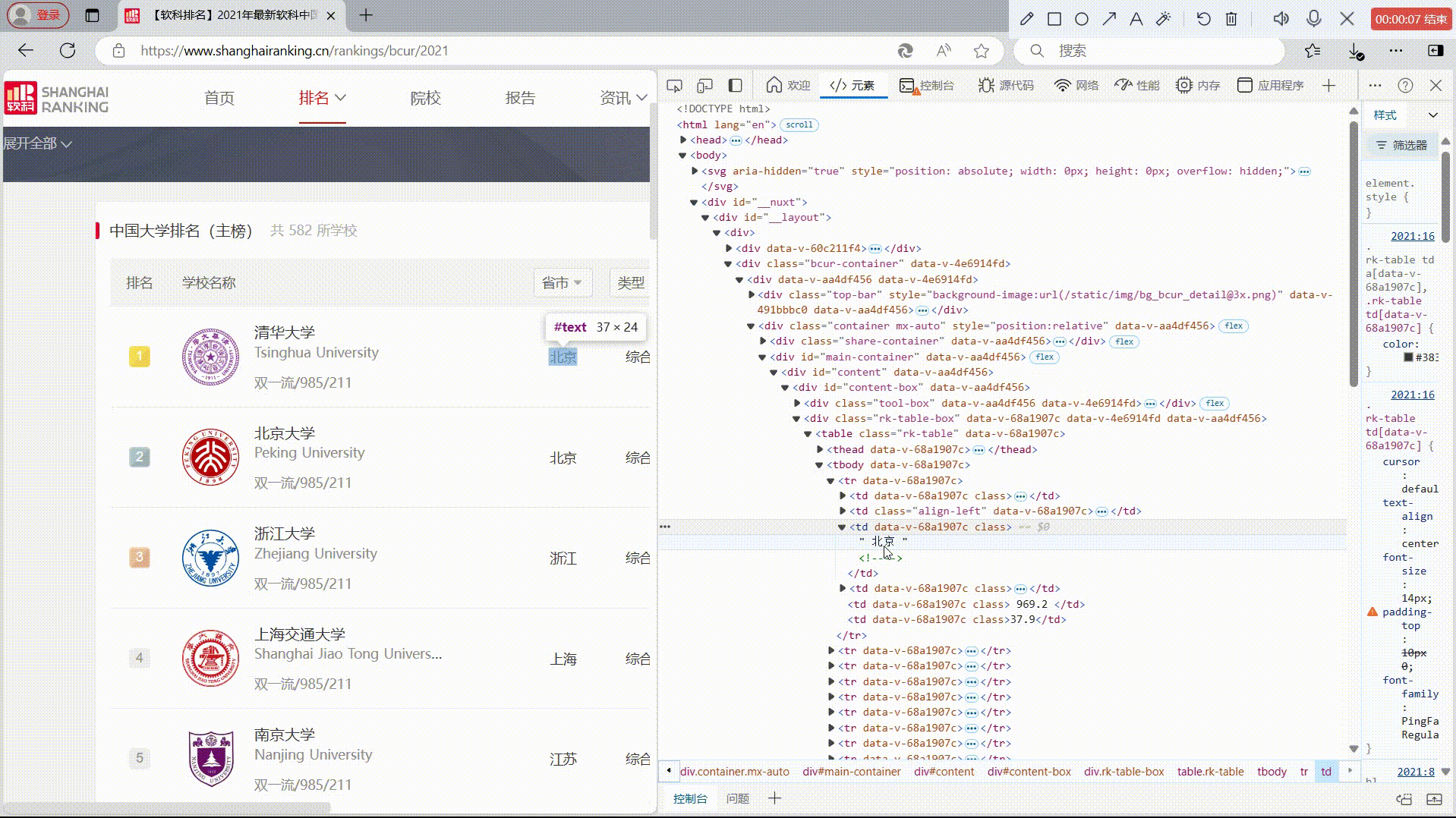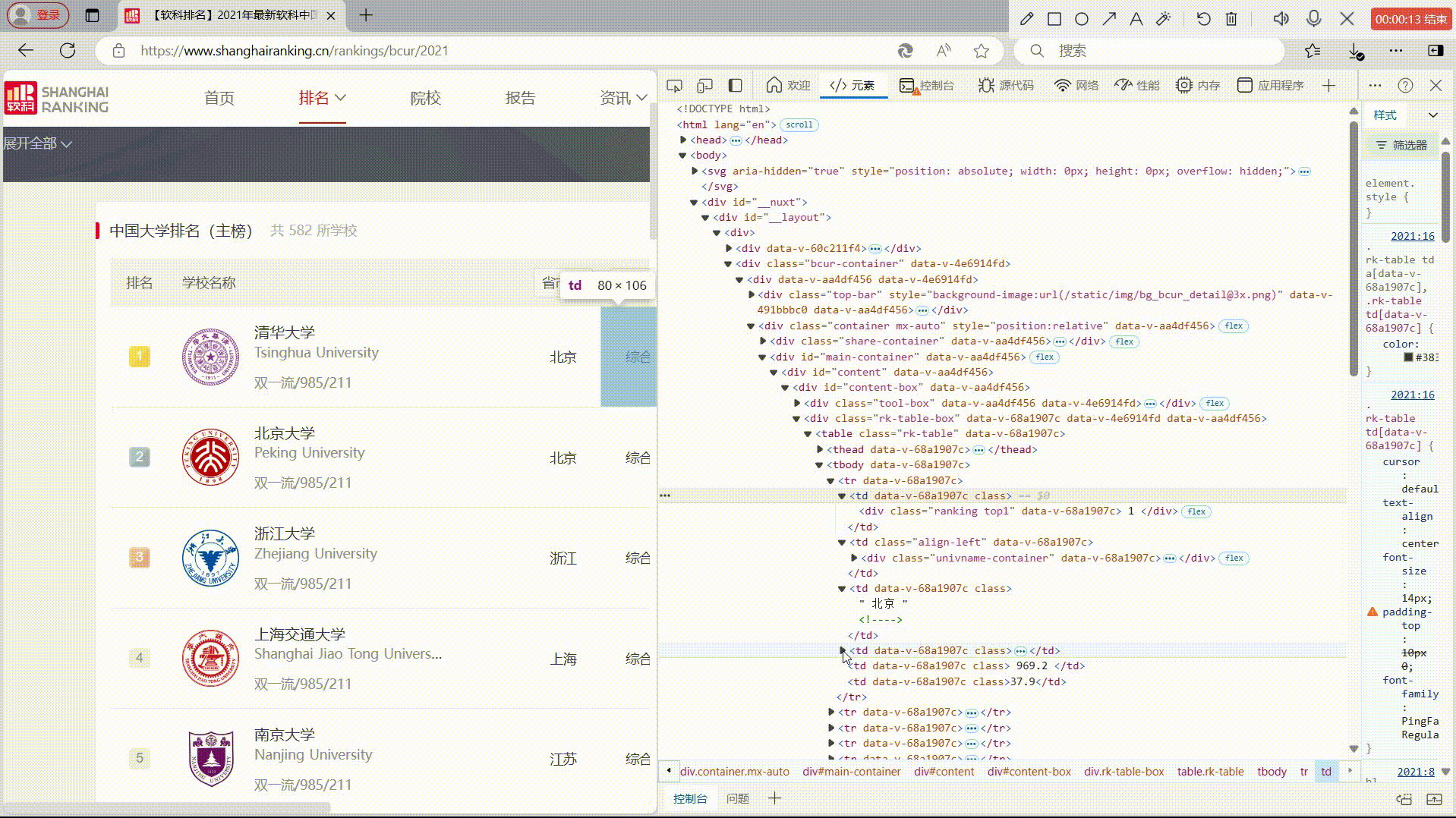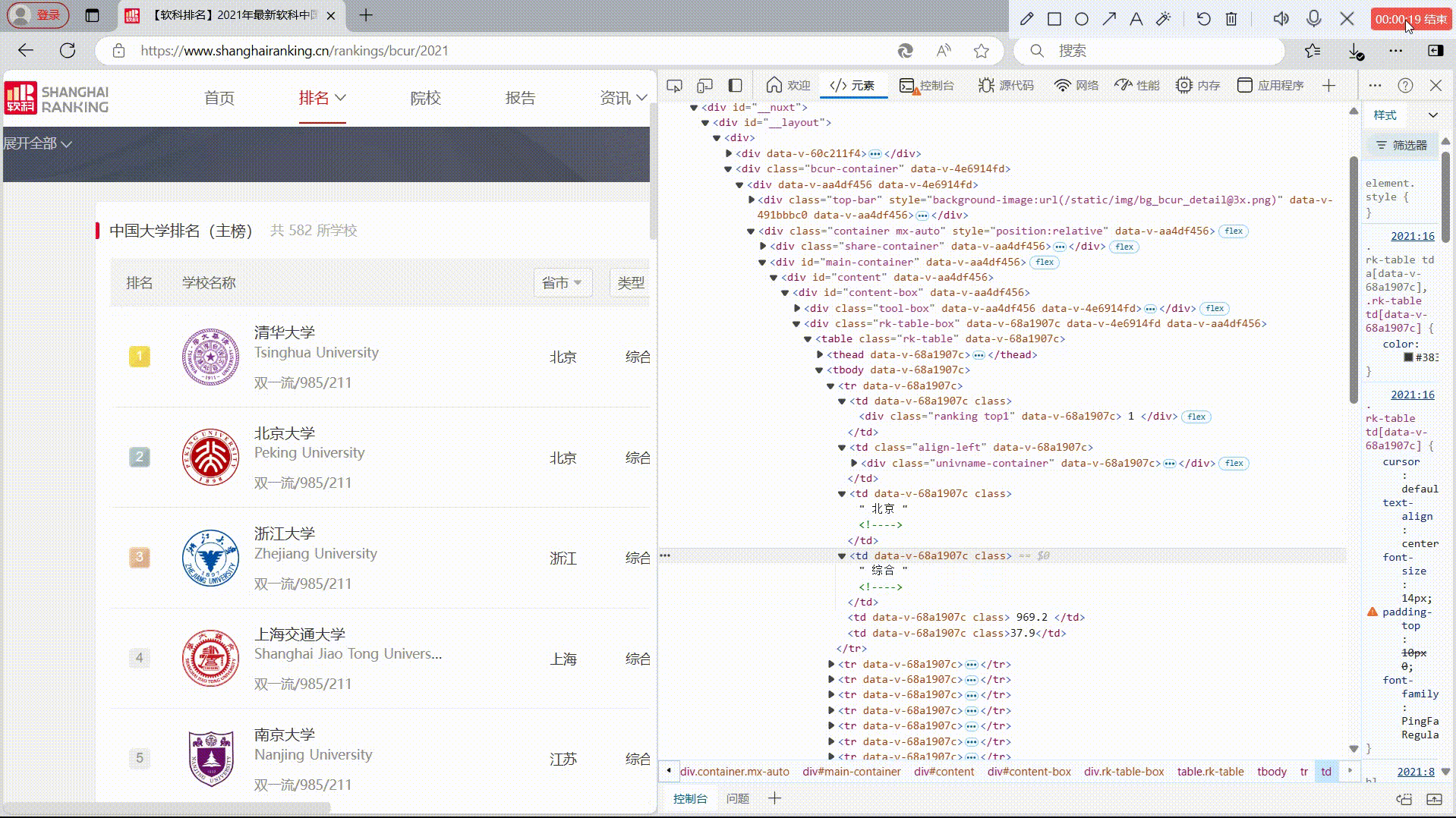
3.Gitee文件夹链接
2022级数据采集与融合技术: 2022级数据采集与融合技术用仓库 - Gitee.com
2)心得体会
同样通过该题目复习了数据库的相关操作,将之前做过的代码进行了修改,添加了存储到数据库的部分,使数据能够很好的保存到本地。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号