数据采集第四次作业
l 作业①:
1. 要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;
i. Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
2. 候选网站:http://www.dangdang.com/
3. 关键词:学生自由选择
4. 输出信息:
MySQL数据库存储和输出格式如下:

步骤如下:
① 编写item.py
class DangdangItem(scrapy.Item):
id = scrapy.Field()
title = scrapy.Field()
price = scrapy.Field()
author = scrapy.Field()
publisher = scrapy.Field()
date = scrapy.Field()
detail = scrapy.Field()
②编写spider
1)观察用于翻页的参数,发现是page_index
link = selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next'] / a / @ href").extract_first()
if link:
url = response.urljoin(link)
yield scrapy.Request(url=url, callback=self.parse)
2)同理通过F12检查页面,可获取想要爬取的标签信息
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
lis = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]")
for li in lis:
title = li.xpath("./a[position()=1]/@title").extract_first()
price =li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
date =li.xpath("./p[@class='search_book_author']/span[position()=last()- 1]/text()").extract_first()
publisher = li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title ").extract_first()
detail = li.xpath("./p[@class='detail']/text()").extract_first()
# detail有时没有,结果是None
③创建数据库及表用于存储数据
class DangDB:
# 在数据库中创建表
db = pymysql.connect(host='localhost', port=3306, user='root', password='******', charset='utf8')
cursor = db.cursor()
cursor.execute('CREATE DATABASE IF NOT EXISTS DANGDANG')
sql = '''create table if not exists dangdang.Crawl(
id int primary key auto_increment comment '序号',
title varchar(256) comment '名称',
price varchar(256) comment '价格',
author varchar(256) comment '作者',
publisher varchar(256) comment '出版社',
date varchar(256) comment '日期',
detail varchar(256) default null comment '介绍'
)'''
cursor.execute(sql)
db.close()
④将爬取到的数据存储到数据库
class DangdangPipeline:
def __init__(self):
# 连接数据库
self.conn = pymysql.connect(host='localhost', port=3306, user='root', password='******', db='DANGDANG',
charset='utf8')
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
try:
self.cursor.execute("insert into Crawl(id,title,price,author,publisher,date,detail) \
values (%s,%s,%s,%s,%s,%s,%s)", (
item['id'], item['title'], item['price'], item['author'], item['publisher'],
item['date'], item['detail']
))
self.conn.commit()
except Exception as e:
print("error:", e)
return item
⑤结果展示:
l 作业②
-
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
-
候选网站:招商银行网:http://fx.cmbchina.com/hq/
3.输出信息:MYSQL数据库存储和输出格式
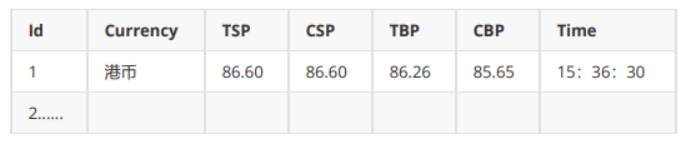
步骤如下:
1)检查页面可以发现想要爬取的数据在tbody中,一个tr是一行数据,一个td是一格数据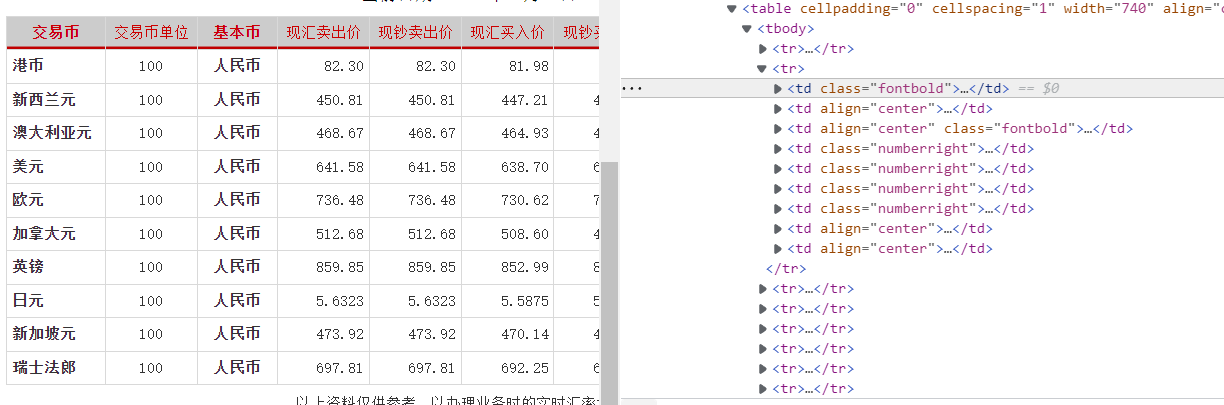
2)数据爬取(编写item.py与第一题类似,略)
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"]) data = dammit.unicode_markup selector = scrapy.Selector(text=data) trs = selector.xpath("//tr") for tr in trs: if self.flag == 0: self.flag += 1 continue currency = tr.xpath("./td[1]/text()").extract_first() tsp = tr.xpath("./td[4]/text()").extract_first() csp = tr.xpath("./td[5]/text()").extract_first() tbp = tr.xpath("./td[6]/text() ").extract_first() cbp = tr.xpath("./td[7]/text()").extract_first() time = tr.xpath("./td[8]/text()").extract_first()
3)创建数据库(与第一题类似,略)并将数据插入数据库
class BankPipeline: def __init__(self): # 连接数据库 self.conn = pymysql.connect(host='localhost', port=3306, user='root', password='cyz2952178079', db='BANK', charset='utf8') self.cursor = self.conn.cursor() def process_item(self, item, spider): try: self.cursor.execute("insert into Fx(id,currency,tsp,csp,tbp,cbp,time) \ values (%s,%s,%s,%s,%s,%s,%s)", ( item['id'], item['currency'], item['tsp'], item['csp'], item['tbp'], item['cbp'], item['time'] )) self.conn.commit() except Exception as e: print("error:", e) return item
4)查看结果

l 作业③:
1.要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
2.候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
3.输出信息:
MySQL数据库存储和输出格式如下,
表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
|
序号 |
股票代 码 |
股 票 名 称 |
最新 报价 |
涨跌幅 |
涨跌 额 |
成交 量 |
成 交 额 |
振幅 |
最高 |
最低 |
今开 |
昨收 |
|
1 |
688093 |
N 世 华 |
28.47 |
62.22% |
10.92 |
26.13 万 |
7.6 亿 |
22.34 |
32.0 |
28.08 |
30.2 |
17.55 |
|
2...... |
|
|
|
|
|
|
|
|
|
|
|
|
步骤如下:
1)检查页面,发现每行数据放在tr中(奇偶行数据的class分别为odd、even)

2)设置浏览器驱动与板块信息
# 使用谷歌驱动器,并设置不加载图片以加快访问速度 options = webdriver.ChromeOptions() options.add_experimental_option('prefs', {'profile.managed_default_content_settings.images': 2}) browser = webdriver.Chrome(options=options) # 三个板块 plates = ["hs_a_board", "sh_a_board", "sz_a_board"] names = ["沪深A股", "上证A股", "深证A股"] data_list = []
3)编写spider
def start_spider(url): browser.get(url) page = 5 count = 0 while True: try: count += 1 # 留时间给页面加载 time.sleep(random.randint(3, 5)) odds = browser.find_elements_by_class_name('odd') evens = browser.find_elements_by_class_name('even') for i in range(10): data_list.append([odds[i].text, evens[i].text]) except Exception as e: print("error:", e) continue # 5页时停止 if count == page: break # 找到下一页的元素并点击 next = browser.find_element_by_css_selector('a.next.paginate_button') next.click()
4)创建数据库
def createDatabase(): db = pymysql.connect(host='localhost', port=3306, user='root', password='cyz2952178079', charset='utf8') cursor = db.cursor() cursor.execute('CREATE DATABASE IF NOT EXISTS STOCK') sql = '''create table if not exists STOCK.Gp( id int primary key auto_increment comment '序号', part varchar(256) comment '板块', node varchar(256) comment '股票代码', name varchar(256) comment '股票名称', newprice varchar(256) comment '最新报价', riserange varchar(256) comment '涨跌幅', riseprice varchar(256) comment '涨跌额', change varchar(256) comment '成交量', changeprice varchar(256) comment '成交额', rise varchar(256) comment '振幅', highest varchar(256) comment '最高', lowest varchar(256) comment '最低', today varchar(256) comment '今开', yestertoday varchar(256) comment '昨收' )''' cursor.execute(sql) db.close()
5)编写主函数
createDatabase() url = 'http://quote.eastmoney.com/center/gridlist.html#' conn = pymysql.connect(host='localhost', port=3306, user='root', password='cyz2952178079', db='STOCK', charset='utf8') cursor = conn.cursor() for k in range(3): url = url + plates[k] print(names[k]) start_spider(url) id = 0 for i in data_list: for item in i: datas = item.split(" ") print(datas) id += 1 try: cursor.execute("insert into Gp(id,part,node,name,newprice,riserange,riseprice,changenum,changeprice,rise," "highest,lowest,today,yestertoday) \ values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)", ( k*100+datas[0], names[k], datas[1], datas[2], datas[6], datas[7], datas[8], datas[9], datas[10], datas[11], datas[12], datas[13], datas[14], datas[15])) print("插入成功") conn.commit() except Exception as e: print("error:", e) browser.quit()
6)结果展示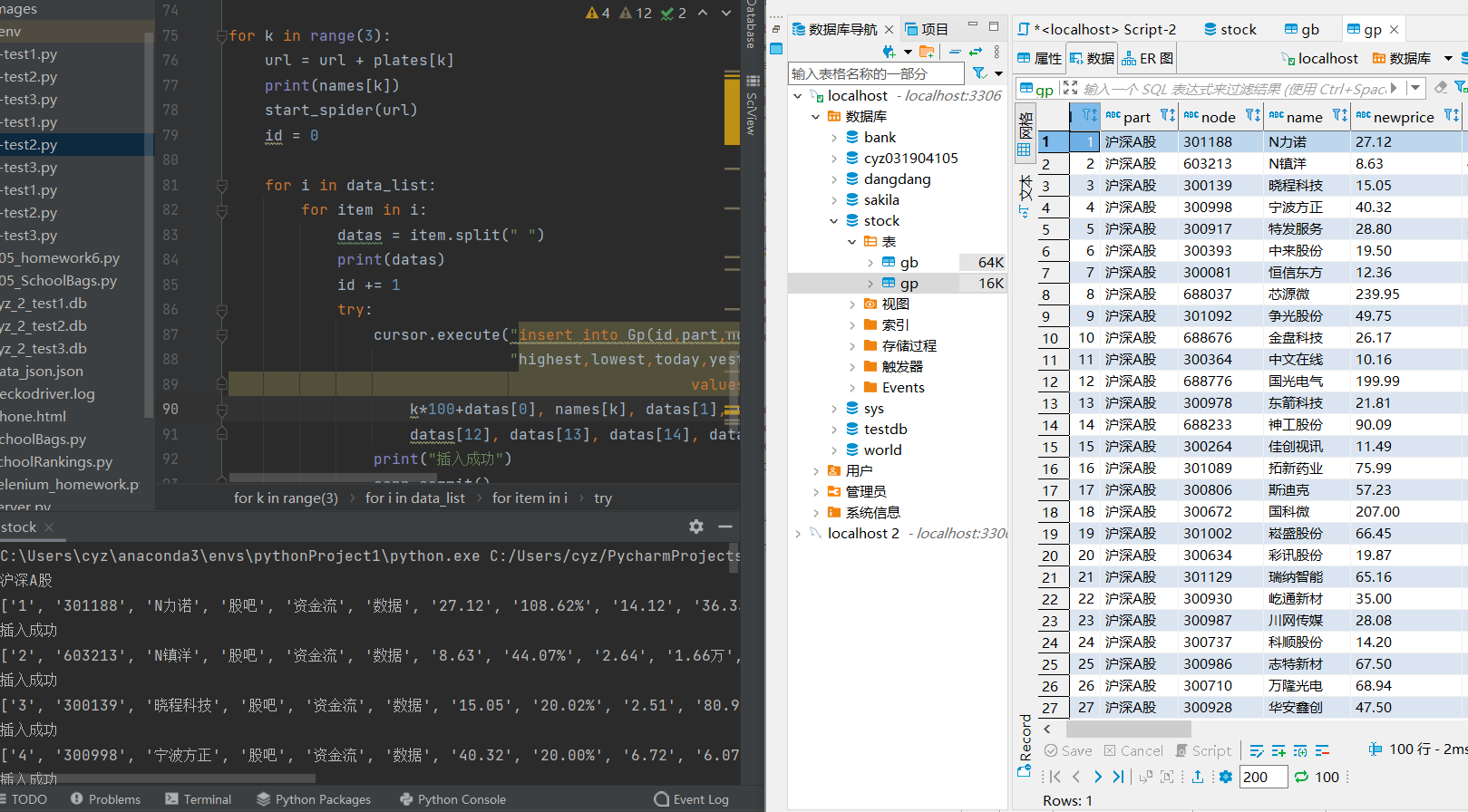
完整代码:陈杨泽/D_BeiMing - Gitee.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号