数据采集第三次作业
作业①:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.we
ather.com.cn)。分别使用单线程和多线程的方式爬取。(限定爬取图片数量为学号后3位)
输出信息:
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
步骤如下:
1)检查网页,可以发现a标签下有新的url,可以根据a标签的href属性访问新网页

2)获取a标签下的url
def getUrls(startUrl): urls = ['http://www.weather.com.cn/'] html = getHtml(startUrl) soup = BeautifulSoup(html, 'html.parser') for li in soup.find_all('a'): newUrl = li if 'http' in str(newUrl): reg = r'http.*?html' ls = re.findall(reg, str(newUrl)) if len(ls)==1: urls.append(ls[0]) return urls
3)获取图片
def getImg(url,page): global x # x = 1 if x< 106: html = getHtml(url) soup = BeautifulSoup(html, 'html.parser') # 获取所有的img标签 global imgs for li in soup.find('body').children: if isinstance(li, bs4.element.Tag): Img = li('img') for i in Img: reg = r'//.*?jpg' ls = re.findall(reg, str(i)) filename = 'Images/%s.jpg' % str(x) # filename = 'Images/%s.jpg' % str(x+(page-1)*5) # 将URL表示的网络对象复制到本地文件 if len(ls) != 0: URL = 'http:' + ls[0] if URL not in imgs: if x >= 106: # if x>=6 break imgs.add(URL) urllib.request.urlretrieve(URL, filename) print(" 图片URL为:" + URL) x += 1
4)单线程/多线程爬取
def main(): threads = [] #线程列表 #五线程 urls = getUrls('http://www.weather.com.cn/') page = 1 for i in range(len(urls)): # range(21) t = threading.Thread(target=getImg, args=(urls[i], page, )) threads.append(t) page+=1 for t in threads: t.start() t.join() # for t in threads: # t.join() #注释代码部分为多线程代码
5)结果如下(共105张)
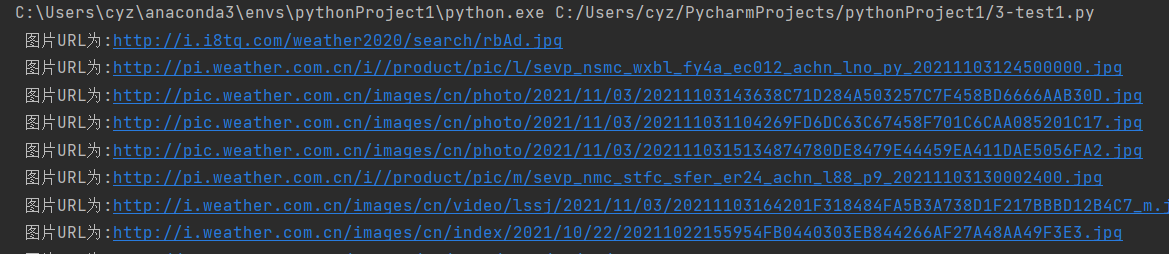
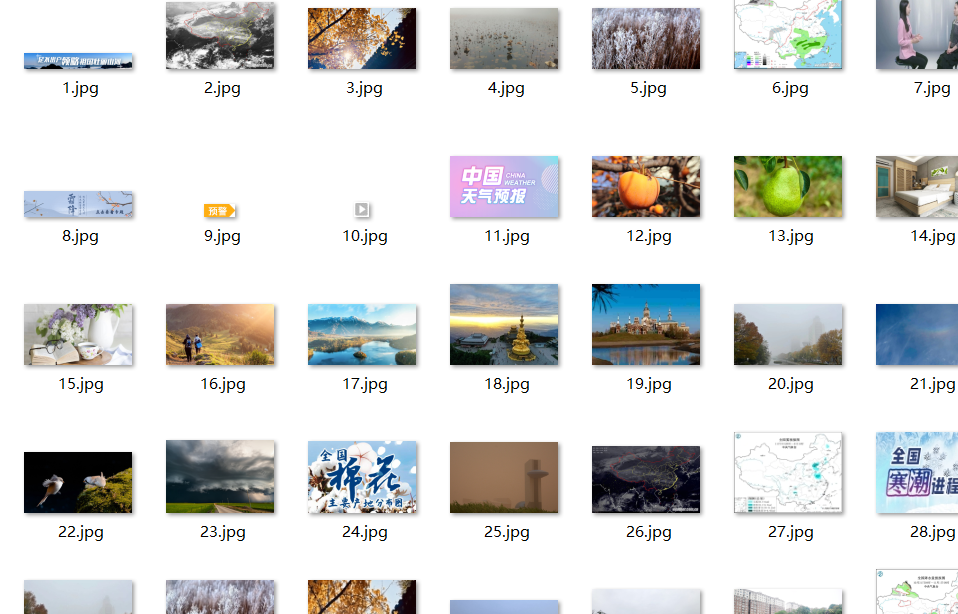
作业②
要求:使用scrapy框架复现作业①。
输出信息:
同作业①
步骤如下:
1)编写spider
class Myspider(scrapy.Spider): id = 1 name = 'weather' start_url = "http://www.weather.com.cn/" def start_requests(self): yield scrapy.Request(self.start_url, callback=self.parse) def parse(self, response): urls = response.xpath('//a/@href').extract() for url in urls: yield scrapy.Request(url=url, callback=self.img_parse) def img_parse(self, response): pics = response.xpath('//img/@src').extract() imgs = [] for k in pics: if k not in imgs and k!='': print("图片url为:", k) imgs.append(k) item = WeatherItem() item["pic_url"] = k item["id"] = self.id if self.id ==105: break self.id += 1 yield item
2)编写pipeline.py
from scrapy import Request from scrapy.utils.project import get_project_settings from scrapy.pipelines.images import ImagesPipeline settings = get_project_settings() class WeatherPipeline(ImagesPipeline): def get_media_requests(self, item, info): image_url = item["pic_url"] yield Request(image_url)
3)运行并查看结果

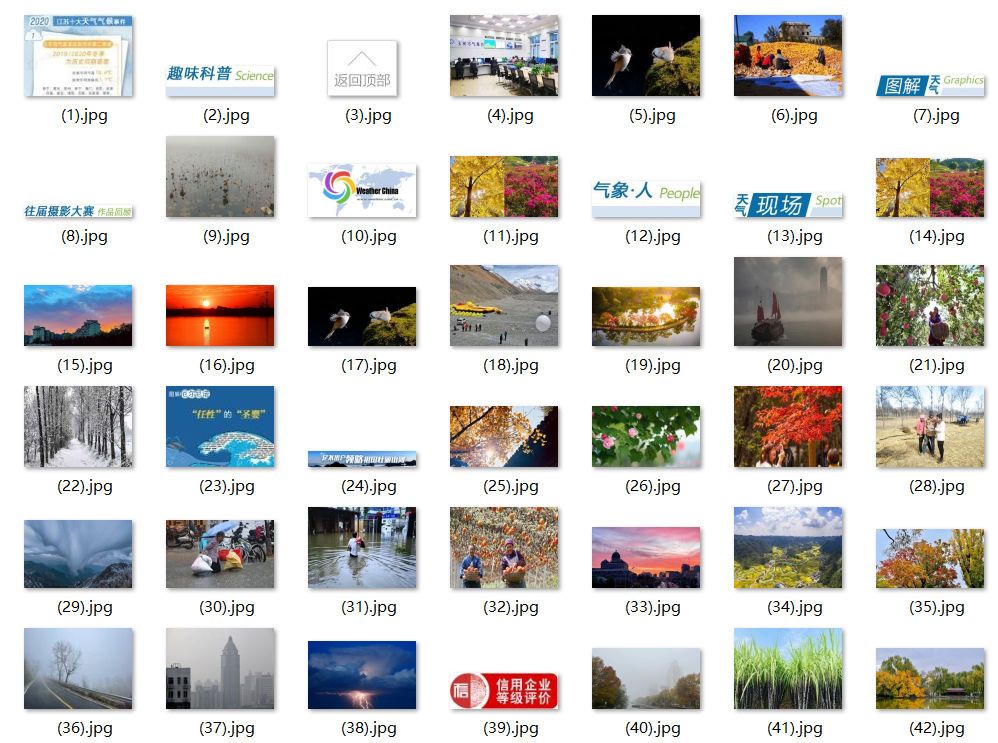 (ctrl+a+f2快速命名)
(ctrl+a+f2快速命名)
作业③:
要求:爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在
imgs路径下。
候选网站: https://movie.douban.com/top250
步骤如下:
1)通过F12查找元素,并复制Xpath路径
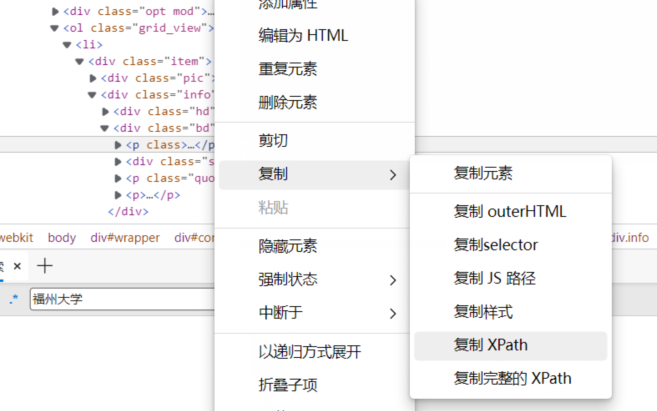
2)编写spider(翻页规律较为简单,看代码即可)
class Myspider(scrapy.Spider): name = 'movie' start_urls = [] def start_requests(self): # 实现翻页爬取 for i in range(1, 10): s = i * 25 self.url = 'https://movie.douban.com/top250?start=' + str(s) + '&filter='
yield scrapy.Request(self.url, callback=self.parse) def parse(self, response): item = MovieItem() item["id"] = response.xpath("//ol/li/div/div/em/text()").extract() item["name"] = response.xpath("//ol/li/div/div/a/img/@alt").extract() roles = response.xpath('//div[@class="bd"]/p[1]/text()').extract_first() item["directors"] = roles.split('主')[0] item["actors"] = '主' + roles.split('主')[1] item["introduce"] = response.xpath("//ol/li/div/div/div/p/span/text()").extract() item["score"] = response.xpath('//ol/li/div/div/div/div/span[@class="rating_num"]/text()').extract() item["pic"] = response.xpath("//ol/li/div/div/a/img/@src").extract()
yield item
3)创建数据库
class MovieDB: # 在数据库中创建表 db = pymysql.connect(host='localhost', port=3306, user='root', password='******', charset='utf8') cursor = db.cursor() cursor.execute('CREATE DATABASE IF NOT EXISTS DOUBAN')
sql = '''create table if not exists douban.Movie( id int primary key auto_increment comment '序号', moviename varchar(256) comment '电影名称', director varchar(256) comment '导演', actor varchar(256) comment '主演', introduce varchar(256) default null comment '简介', score varchar(256) comment '电影评分', pic varchar(256) comment '电影封面' )''' cursor.execute(sql) db.close()
4)编写pipeline完成插入数据与保存图片
class MoviePipeline:
def __init__(self):
# 连接数据库
self.conn = pymysql.connect(host='localhost', port=3306, user='root', password='******', db='DOUBAN',
charset='utf8')
self.cursor = self.conn.cursor()
self.cursor.execute('truncate table Movie')
self.conn.commit()
def process_item(self, item, spider):
# 插入数据
for i in range(len(item['id'])):
#提取导演与主演信息
d = re.findall(r'导演: (.*?)&', item["roles"][i])
a = re.findall(r'主演: (.*?)...', item["roles"][i])
try:
item['directors'] = d[0]
item['actors'] = a[0]
except :
item['directors'] = ''
item['actors'] = ''
self.cursor.execute("insert into Movie(id,moviename,director,actor,introduce,score,pic) \
values (%s,%s,%s,%s,%s,%s,%s)", (
item['id'][i], item['name'][i], item['directors'][0], item['actors'][0], item['introduce'][i], item['score'][i],
item['pic'][i]))
self.conn.commit()
return item
class PicPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for i in range(len(item["pic"])):
image_url = item["pic"]
yield Request(image_url)
5)部分结果展示
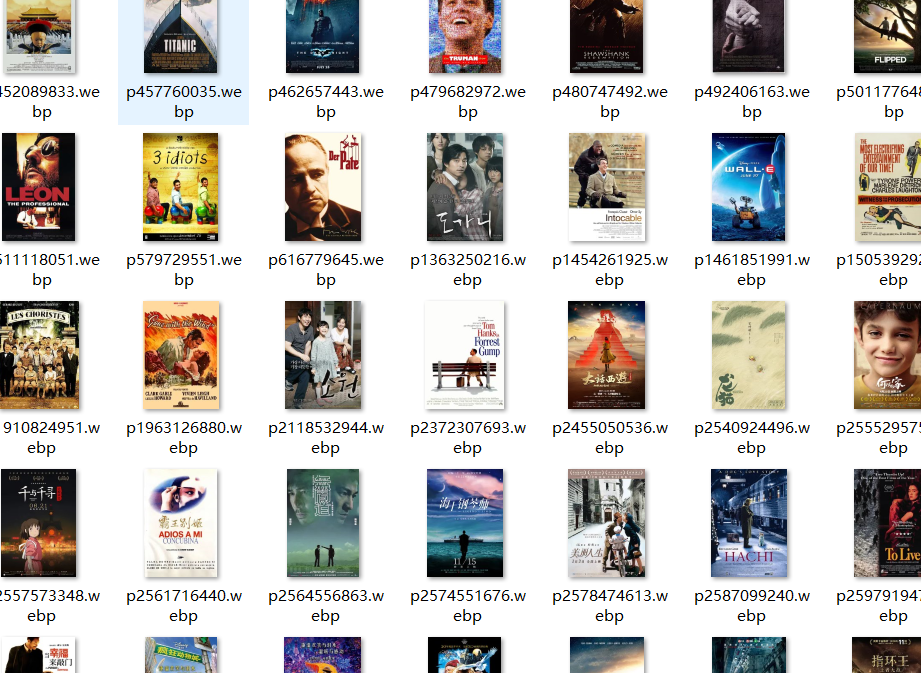
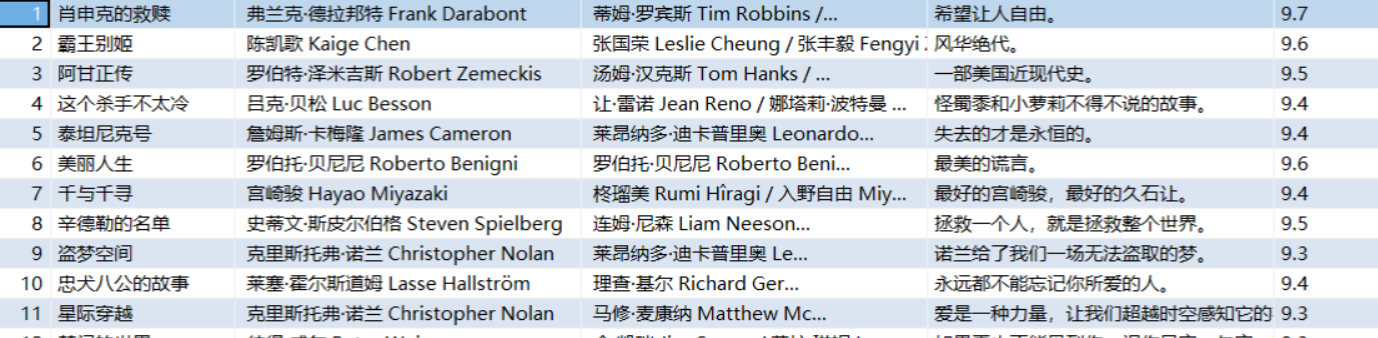
三题完整代码:陈杨泽/D_BeiMing - Gitee.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号