数据采集第一次作业
-
作业①:
1)大学排名爬取实验
要求:用urllib和re库方法定向爬取给定网址(https://www.shanghairanking.cn/rankings/bcsr/2020/0812 )的数据。
输出信息:
| 2020排名 | 全部层次 | 学校类型 | 总分 |
|---|---|---|---|
| 1 | 前2% | 中国人民大学 | 1069.0 |
| 2...... |
步骤:
1.获取网页源码
def getHtml(url): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'} try: req = urllib.request.Request(url, headers=headers) resp = urllib.request.urlopen(req) data = resp.read() data = data.decode() dammit = UnicodeDammit(data, ["utf-8", "gbk"]) unicodeData = dammit.unicode_markup return unicodeData except: return ""
2.通过正则匹配找到所要的信息
rank = re.findall(r'<div class="ranking" data-v-68e330ae>.*\n.*\n.*</div>', html)
name = re.findall(r'cn" data-v-b80b4d60>.*?</a>', html)
level = re.findall(r'<td data-v-68e330ae>\n.*?%', html)
score = re.findall(r'<td data-v-68e330ae>\n.*?\n </td>', html)
3.对匹配到的信息进行一定的处理(部分处理见全代码)
def dealWithInfo(List): for i in range(len(List)): List[i] = List[i].replace(" ", "") List1 = re.findall(r'\n.*?\n', List[i]) for j in List1: List[i] = j.replace("\n", "") return List
4.输出
print("{:^10}\t{:^10}\t{:^10}\t{:^16}".format("2020排名", "全部层次", "学校名称", "总分"))
for i in range(30):
print("{:^10}\t{:^10}\t{:^18}\t{:^10}".format(rank[i], level[i], name[i], score[i]))
结果如下:
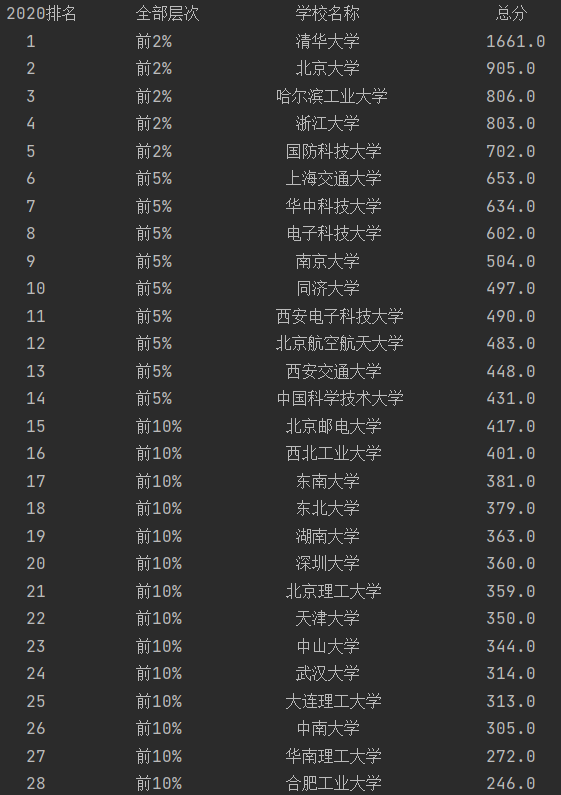
2)心得体会:
1.为了不给对方的服务器造成困扰,可以将爬取到的html先保存下来
2.在正则匹配中常有一些干扰字符如\n之类的,可以用replace处理
3.输出时可借助制表符\t进行对齐
-
作业②:
2)AQI时报爬取实验
要求:用requests和Beautiful Soup库方法设计爬取https://datacenter.mee.gov.cn/aqiweb2/ AQI实时报。
输出信息:
| 序号 | 城市 | AQI | PM2.5 | SO2 | No2 | Co | 首要污染物 |
|---|---|---|---|---|---|---|---|
| 1 | 北京 | 55 | 6 | 5 | 1.0 | 225 | — |
| 2...... |
步骤:
1.获取网页源码
def getHtml(url): try: r = requests.get(url, timeout=25,headers=headers) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return ""
2.用BeautifulSoup打包,获取所要的信息
def fillList(ulist, html): soup = BeautifulSoup(html, "html.parser") for tr in soup.find('tbody').children: if isinstance(tr, bs4.element.Tag): tds = tr('td') ulist.append([tds[0].text.strip(), tds[1].text, tds[2].text.strip(), tds[4].text.strip(), tds[5].text.strip(), tds[6].text.strip(), tds[8].text.strip()])
3.输出列表里的内容
def printList(ulist): print("{:^10}\t{:^10}\t{:^20}{:^1}\t{:^10}\t{:^10}\t{:^10}\t{:^10}".format("序号", "城市", "AQI", "PM2.5", "SO2", "NO2", "CO", "首要污染物")) for i in range(len(ulist)): u = ulist[i] print("{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}".format(i+1, u[0], u[1], u[2], u[3], u[4], u[5], u[6]))
结果如下:
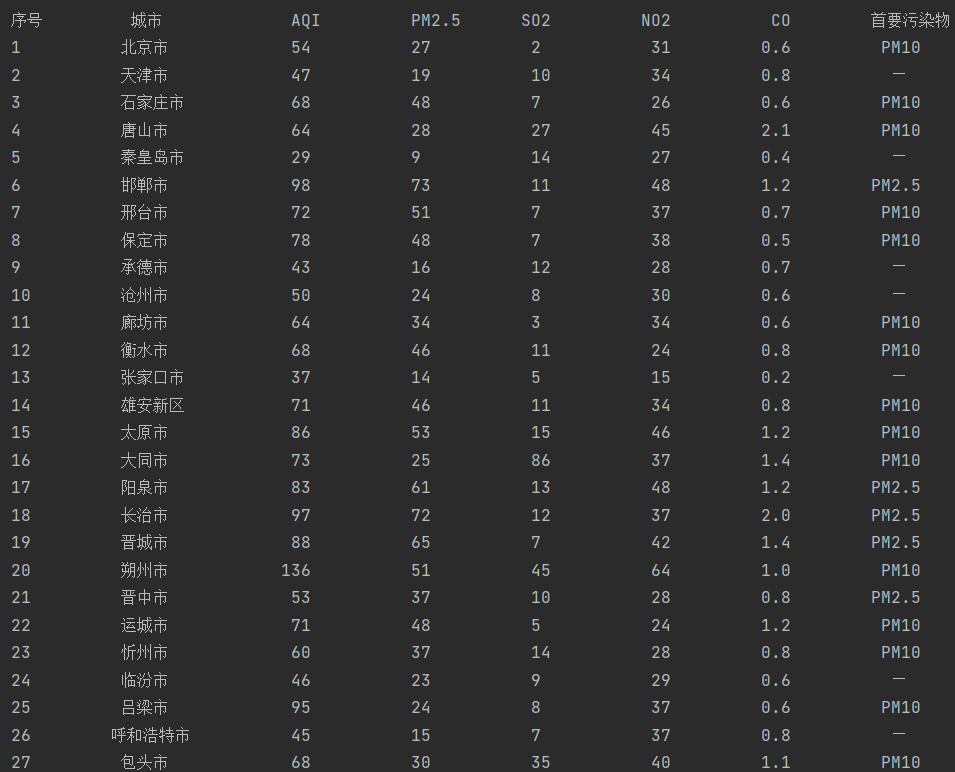
2)心得体会:
1.相比于re正则爬取,本题采用BeautifulSoup显然更为容易,因为所要爬取的内容都在同一个目录下。
2.能够熟练地提取标签的特征显然对爬虫的信息提取有很大的帮助。
3.如果不限制使用方法,也可以采用以下更短的代码
import requests import pandas as pd from lxml import etree url = "http://datacenter.mee.gov.cn/aqiweb2/" html = getHtml(url) #与之前的getHtml相同 parsed_text = etree.HTML(html) # 解析字符串格式的HTML文档对象 data_res = pd.read_html(url, encoding="gb2312") # pd.read_html:快速获取在html中页面中table格式的数据,返回的是一个list # gb2312采用中文编码 data = data_res[0] header = ['城市', 'AQI', 'PM2.5', 'PM10', 'SO2', 'NO2', 'CO', 'O3', '首要污染物'] data.columns = header # 修改列名 print(data)
-
作业③:
3)爬取福大新闻网图片实验
要求:使用urllib和requests爬取(http://news.fzu.edu.cn/),并爬取该网站下的所有图片
输出信息:将网页内的所有图片文件保存在一个文件夹中
步骤:
1.获取网页源码(流程与作业②相同)
2.获取所有图片
def getImg(): url = 'http://news.fzu.edu.cn/' html = getHtml(url) soup = BeautifulSoup(html,'html.parser') #获取所有的img标签 Img = soup.find_all('img') x = 1 for i in Img: # 获取src路径 imgsrc = i.get('src') # 本地路径 filename = 'C:/Users/cyz/Desktop/imgsrc/%s.jpg' % x # 将URL表示的网络对象复制到本地文件 urllib.request.urlretrieve(url+imgsrc, filename) print('下载第%d张' % x) x += 1 print('**下载完成!**')
结果如下:
2)心得体会
1.爬取所有图片时应提取对应标签的同有特征,即img标签下均有src属性
2.掌握urllib.request.urlretrieve()对网页爬取结果的保存有很大帮助。
三题作业的完整代码:陈杨泽/D_BeiMing - Gitee.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号