QOJ 板刷记录2
2025.8.21 开始第二篇刷题记录
考虑到把所有记录全放在一篇文章太长了,所以准备一篇文章只记录 \(5\) 道题。
感觉清华集训题很多太偏了,然后还有一些题找不到题解,我决定选择跳着做题,随缘补题了。
最近太累了,比较需要肝代码量的跳过了,啥时候补吧,而且一道一道做题这辈子QOJ 第一页都做不完我感觉。,。
#6. 玛里苟斯
题意简述
给你 \(n\) 个数,求从这几个数中任意选几个数的异或和(空集就是 \(0\))的 \(k\) 次方的期望。
完全不会做,润去看题解。
比较难绷猜了个结论竟然对了(就是概率均等的性质),这启示我们没有头绪就手玩几组样例然后猜结论。
但这不影响我做不出来,用到了一个比较有意思的 \(\text{trick}\) ,还是很有启发价值的。
题解
首先你需要观察到一个性质,就是所有的能取到的异或和的概率均等。
考虑证明:
一定可以把这些数最大的线性无关组挑出来也就是线性基,这些数一定会把所有能取到的异或和都只取一次,取到的概率是均等的。考虑再往里加入剩下的线性相关的数,假设在加入前所有数取到的概率是均等的,因为线性相关,所以不会异或出在这些异或和之外的数,而这个数和每个不同的数异或都有一个不同的异或结果,所以加入后取到的概率还是均等的。
既然概率均等,所以我们完全可以对这些数的线性基求异或和 \(k\) 次方的期望。我们考虑拆位。
能异或的到的数一定可以表示成 \(\sum_{i=0}^{logV} b_j2^i\) 其中 \(b_j\in\{0,1\}\)。根据组合意义,若干个数的和的 \(k\) 次方可以理解为:在这些数中可重复选取 \(k\) 次数,并且将这 \(k\) 次选择的数乘起来作为这次取数方案的权值,并且对所有的取数方案权值加起来就是这些数的和的 \(k\) 次方。其实就是二项式定理扩展到多项的形式。
所以答案其实就是 \(\sum_n \sum_\sigma\prod_{i=1}^k\sigma(i)\) 其中 \(n\) 是枚举线性基能取到的数,\(\sigma(i)\) 枚举的是第 \(i\) 次取的二进制数位,其中 \(n\) 包含 \(\sigma(i)\) 对应的这个二进制位即 \(\sigma(i) \mathbin{\&} n=\sigma(i)\)。我们考虑交换求和顺序即:
我们枚举 \(\sigma(i)\) 时间复杂度是可以接受的,因为总的二进制数位个数不会太多,因为答案小于 \(2^{63}\) 所以进制位数量等于 \(\frac{64}{k}\),枚举这 \(k\) 次取哪个的时间复杂度是\((\frac{64}{k})^k\) 可以接受。现在我们需要求出来有多少个线性基能异或出来的数包含所有 \(\sigma(i)\) 对应的数位。对于这一部分我们发现,除了 \(\sigma(i)\) 对应的数位都没有用,我们把线性基所有数全都把除了 \(\sigma(i)\) 对应的数位都置为 \(0\),然后把这些数全都在放到一个新的线性基中,检测 \(\sigma(i)\) 对应的数位全是 \(1\) 的数是否和那些新的数线性相关(即把它插入新线性基判断是否能够成功插入。)如果线性无关的说明包含 \(\sigma(i)\) 所有数位的数不可能会被异或出来,所以贡献是 \(0\),否则在新线性基之外的数无论取哪些数都可以通过再异或新线性基里面的若干个数最后变成一个包含 \(\sigma(i)\) 所有数位的数,即最后包含所有 \(\sigma(i)\) 对应的数位能被异或出来的数一共有 \(2^{u-v}\) 中方案,其中 \(u\) 为第一个线性基的秩,\(v\) 为新线性基的秩。然后就做完了。时间复杂度 \(O(k(\log V)^{k+1})\)
#7. 主旋律
题意简述
给你一个有向图,求有多少种强联通子图的。
做过了,补个题解。
已经忘了。。难过了。。。再也不相信自己的记忆力了。
题解
发现强联通很难求,我们考虑转化成总数减去非强联通子图。
非强连通子图一定看可以缩点缩成一个点数大于 \(1\) 的 \(\text{DAG}\)。你发现把所有度数为 \(0\) 的点删了还是一个 \(\text{DAG}\),所以我们就可以枚举作为度数为\(0\) 的点集,然后做 \(\text{dp}\) 了
\(n\) 的大小很小,我们直接考虑状压,设 \(dp[S]\) 表示 \(s\) 这些点的非强联通子图数量,\(g[S]\) 表示把 \(s\) 这些点缩点后只存在度数为 \(0\) 的点的方案数,\(E[S][T]\) 表示 \(S\) 点集到 \(E\) 点集的边数。那么就有:
先不考虑那个 \((-1)^?\) ,为什么这个式子是对的,你考虑枚举 \(T\) 作为缩点完度数为 \(0\) 的点,\(g[T]\) 就是其方案数,剩下的点 \(S-T\) 中,$T $ 可以向 \(S-T\) 任意连边,\(S-T\) 内部也可以随意连边。
再考虑这个 \((-1)^?\) 到底是什么,你发现 \(S-T\) 里面可能仍然有缩完点之后度数为 \(0\) 的点,所以直接累和会有重叠部分,所以我们需要加一些容斥系数,你发现容斥系数和 \(T\) 里面度数为 \(0\) 的点的个数有关,假设 \(x\) 是 \(T\) 里度数为 \(0\) 的点,那么容斥系数就是 \((-1)^{x+1}\),但是我们不太能表述出来,因为根据 \(g\) 的定义,\(g\) 里面的点数是不确定的,所以我们改变一下 \(g\) 的定义,改成 \(g[S]\) 表示把 \(s\) 这些点缩点后只存在奇数个度数为 \(0\) 的点的方案数减去偶数个度数为 \(0\) 的点的方案数,假如说 \(g[T]\) 和 \(E\) 数组能求出来,我们就可以 \(o(3^n)\) 时间复杂度求出来 \(\text{dp}\) 了。
先考虑 \(g\) 怎么求,我们可以枚举 \(\text{SCC}\), 然后做 \(\text{dp}\),根据经典 \(\text{DAG}\) 容斥办法,直接枚举子集会导致方案重复,我们可以钦定一个点,要求在这个点一定被缩到我们枚举的 \(\text{SCC}\),这样就不会重了,所以有:
所以 \(g\) 跟着 \(dp\) 一起转移就好了。
现在我们只需要考虑 \(E\) 数组就好了,你发现对于 \(T\) 我们需要求的 \(E\) 只有两种即 \(E[T][T]\) 和 \(E[T][S-T]\),前者我们枚举边再枚举所有状态 \(S\) 是否包含边的左右端点,如果包含,就 \(E[S]\)++,然后就统计完了。对于后者,对于由于没有重边。每个点我们预处理 \(out[i]\) 表示 \(i\) 能到达的所有点的二进制状态。我们在 \(\text{DP}\) 过程中枚举 \(S\) 以及子集 \(T\) 时,枚举 \(T\) 包含的所有点 \(i\),那么就有 \(E[T][S-T]+=\operatorname{popcount}(out[i]\operatorname{and}(S-T))\) 。然后这道题就做完了。
#11. 矩阵变换
题意简述
给定一个 \(N\) 行 \(M\) 列(\(M>N\))的矩阵,保证矩阵上的所有数的值域是 \([0,N]\),保证每一行中 \([1,N]\) 范围内的数字全都出现并只出现了一次,保证每一列不会有两个相同的数,现在希望你每一行选择一个数,将其后缀全改成这个数,需要你构造方案使得操作完每一列仍然不存在两个相同的数。
稳定婚姻问题,红日讲过,可惜忘了。
题解
观察性质,发现每一行最后一个数一定会被改成这一行选的数,而每一列的数都不能相同,所以每一行选的数也各不相同。这就形成了一个二分图匹配的形式,\(n\) 行和 \(n\) 个数做匹配,并要求匹配方案合法。
我们手玩发现,不合法情况只有这样的:
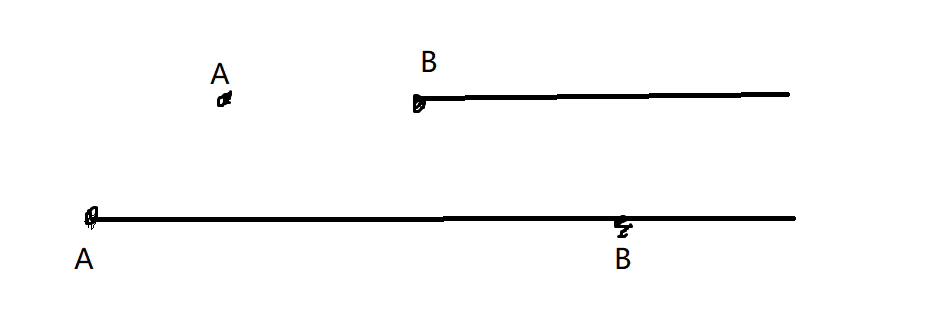
下面的 \(A\) 覆盖住了上面的 \(A\),因此有一列有两个 \(A\) 而不合法。
而不存在有一列存在两个 \(B\),因为下面的行的 \(B\) 被 \(A\) 覆盖了。
这启示我们,对于一行我们更倾向于匹配这一行最靠左的元素,这样就可以覆盖住别的点使得别的点合法;对于一个点我们更倾向于选择这个点在最右面的行,因为这样就不容易覆盖后面的点的时候和的行的这个数出现在同一列。
那如果出现 \(A\)(数) 和 \(b\) (行)匹配,\(B\) 和 \(a\) 匹配,但是 \(A\) 更希望和 \(a\) 匹配(即 \(A\) 在 \(a\) 行比 \(b\) 行更靠右), \(a\) 也更希望和 \(A\) 匹配(即 \(a\) 行 \(A\) 比 \(B\) 更靠左)那么就会出现如图所示的情况,就不合法。
这显然就是完美婚姻匹配问题了。
我们回顾一下怎么做,每一个左部点从上到下按照顺序和右部点匹配,如果重了就看对于右部点哪个左部点排名更靠前,然后和更靠前的左部点作为新的和那个右部点匹配的点,另一个继续按照排名找到下一个不重合法的右部点,直到所有左部点匹配完为止。
这个构造显然是对的,根据构造过程,对于每一个左部点 \(a\),排名比他匹配的点靠前的右部点的匹配对象一定比 \(a\) 更心仪的,所以是稳定的,而对于所有右部点,比她匹配的左部点排名更靠前的左部点显然也找到了比她更心仪的(因为是从排名靠前到排名靠后的选取对象)。而我们也构造出来方案了,所以不存在无解情况,(不可能会出现一个左部点所有匹配的右部点都都被别的左部点匹配过了,因为一共就 \(n\) 个点)
然后按照这个方法,对数和行做一下婚姻匹配这道题就做完了。
时间复杂度 \(O(TN^2)\)
#12. Sum
题意简述
给定正整数 \(n,\,r\) ,求:
完全不需要简化题意,数学推式子题。
类欧几里得题,补一下,这辈子是记不住怎么推的了。
比较恶心的是这个东西,得提前取整还有记着约分,否则会爆精度。。。
题解
先把 \(\sqrt r\) 是整数的特判掉,这个很显然了。
如果 \(\sqrt r\)是偶数,答案就是 \(n\)。
否则,答案就是 \(-(n \operatorname{mod}2)\)。
考虑到 \((-1)^x\) 这种东西非常难以刻画,我们根据经典结论:
这样就好办多了,看到这个向下取整也能很自然想到类欧几里得算法。
我们把这个东西带入到原式子:
我们考虑令 \(x=\sqrt r\),\(f(a,b,c,n)=\sum_{i=1}^{n}\lfloor\frac{ax+b}{c}i\rfloor\),\(t=\frac{ax+b}{c}\)(就是 \(f\) 函数里面的 \(a\),\(b\),\(c\))。
那么我们要求的答案就是:
怎么求 \(f\) 函数呢?我们考虑递归,并且分讨一下 \(t\),这种带向下取整的我们拆开看看总没错。
考虑当 \(t>1\) 的情况,令 \(k=\lfloor t \rfloor\):
我们再来考虑 \(t<1\) 的情况:
这一步是经典类欧套路了,将向下取整转化为一条直线的线下整点数由于 \(x\) 是根号下的东西,整数的情况已经被判掉了,所以 \(ti\) 一定不会不会是整点,我们枚举整点,大胆通过判断是否比 \(ti\) 小,来判断是否是线下的就好了。
继续按照类欧几里得套路推式子:
我们分析这一坨东西的时间复杂度,\(t>1\)时一定会递归到\(t<1\) 的情况,而 \(t<1\) 一定会递归使 \(n\) 乘上一个 \(t\) 并且向下取整,然而 \(t\) 的取值比较诡异不太能说清楚,总之期望上来讲 \(t\) 大概等于 \(0.5\),即使更大,这个东西的一个渐进时间复杂度也是一个 \(\log n\) 这样的东西,显然不会递归太多次,所以时间复杂度是 \(O(T\log n)\),随便通过此题。
#15. 虫逢
题意简述
给你一个词库包含若干个单词(你只知道大小为 \(M\),但不知道包含什么单词),一个单词由四个字母组成(字符集是 \(\text{ASCII}33-126\))。
现在有 \(2N\) 个词组,每个词组由 \(l\) 个词库里的词组成。定义两个词组是同源的,那么就有这两个词组有正好一半个词是一样的。
现在你需要找到哪些词组是同源的,保证 \(A\) 若和 \(B\) 同源,那么 \(A\) 和 \(C\) 一定不同源,保证所有词组都有另一个词组和这个词组同源,保证任意非同源词组的交小于一半。
完全没思路。这个套题几乎全不会没救了。
乱搞题,感觉有点幽默。
题解
考虑哈希,给每个词随机一个权值,对于每一个词组的权值取其包含的所有词的权值最大值,这样同源词组的交集在两边的取到最大值的概率各为 \(\frac{1}{2}\),总共就有 \(\frac{1}{4}\) 概率最大值一样,而非同源词组因为数据随机,所以几乎没有交集,只有 \(\frac{1}{L^2}\) 的概率才有可能取到的最大值一样(以上算的都很粗略,但级别差不多),所以我们把最大值相同的词组都暴力尝试是否能够配对。当然有可能没匹配完,我们只需要重复上述过程然后多做几次就好了。根据我们前面的理论一组最大值相同的词组大概只有 \(\frac{n}{L^2}\) 个,暴力匹配一共要匹配 \(\frac{n^2}{L^4}\) 次,一次匹配时间复杂度是 \(O(L)\),而组数一共就有 \(L^2\) 组,做一次随机化的时间复杂度就是 \(O(\frac{n^2}{L})\),而做一次随机化 \(\frac{1}{4}\) 的概率会有一对数分到一个组,而我们可以把一个组的数的匹配关系全都确定,所以期望很少次就可以把所有匹配关系确定完,实际上需要小卡常,加上快读,匹配过的数跳过以及一些若干常数优化就可以通过此题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号