【学习笔记】由《查找》说起
由查找说起
查找是一种太为常见的操作,关于查找诞生了很多数据结构。 其中最简单的当属于数组
数组的一个特点就是可以直接寻址,能够在O(1)时间内访问任意元素。
1.顺序查找
顺序查找是一种最简单直接暴力的查找了,也就是从头到尾进行遍历,找到了就停止,所以其时间复杂度为0(n)。
2.二分查找
二分查找就是经典的使用了分治的思想,将全部数据逐渐减小规模,最终就能够找到了。
2.1 前提
数据必须是有序的
2.2 过程
1.定位有序数组中间值;比较目标值和中间值大小;
2.如果目标值=中间值,找到结束;
3.如果目标值<中间值,将左边数组作为新数组,从头执行;
4.如果目标值>中间值,将右边数组作为新数组,从头指向;
2.3 本质
其本质就是每次比较都会减少一半的数据,省去了很多不必要的操作,时间复杂度为0(logN);
2.4 缺点
在大多数应用中,要能够实现快速的查找并且插入,但是这种查找并不适合,一想到插入,其实就应该想到链式结构,因为这是其优势,插入时间复杂度低。但是单链表是不能使用二分查找的,因为二分查找之所以高效,是因为它能够快速的定位到中间元素,这种快速索引链表做不到。所以就需要更复杂的数据结构。
3.二叉查找树
二叉查找树(BST):任意一个节点值都大于其左子树的任意节点,小于右子树的任意节点。
如果把这个二叉树投影到一条直线上,那就是一个有序数组:
3.1 查找
1.if树是空的,未找到;
2.if当前节点值=目标值,找到;
3.if当前节点值<目标值,到左子树上找;
4.if当前节点值>目标值,到右子树上找;
这就是一个递归的过程,从上到下查找,要查找的树的规模也在减小。
- 理想情况下,如果二叉树分布较为平衡,每次都可减小一半的节点,时间复杂度O(logN);
- 极端情况下,如果二叉树只有一边子树,则需要将所有节点遍历一遍,时间复杂度O(N);
3.2 插入
插入和查找基本上是一样的。
- 查找:比较元素值是否相等,相等则返回,不相等就判断大小,递归查询左子树、右子树,直到找到相等元素,或者子节点为空,返回节点不存在;
- 插入:比较元素值是否相等,相等则返回,表示已存在,不相等就判断大小,递归查询左子树、右子树,直到找到相等的元素,或子节点为空,将其插入该节点位置;
其实这和快排基本上是一样的,树的根节点就是快速排序里面的哨兵,左边都比它大,右边都比它小。
现在看来,时间复杂度的高低取决于这个树的平衡性,如果树能够更平衡一些,每个树枝上都有分叉,别太直了,也就是避免树向线性结构靠近,那时间复杂度就是O(logN);
4.平衡二叉树
平衡二叉树(AVL树):左右两棵树的高度差不超过1,并且左右两棵树也是平衡二叉树。
这样就能解决二叉树退化成链表的问题了,把时间复杂度维持在O(logN);
缺点:在一棵树中动态插入和删除的操作中,每次进行基本都会破坏这种平衡性,所以每次都需要大规模调整,这代价太高了。
5.红黑树
红黑树就是用来保证树的平衡性,使其不至于退化为链表,能够降低树的高度,要知道,查找,插入或删除可都是取决于树的高度,高度越低效率越高。
在看红黑树之前,先来了解一下2-3树;
5.1 2-3树
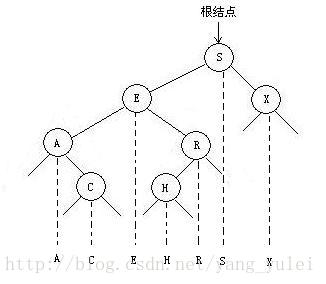
- 2节点:能保存1个值,所以能分出来2个叉,左边都比节点小,右边都比节点大;
- 3节点:能保存2个值,所以能分出来3个叉,左边都比节点里小的还小,中间的在这两个值中间,右边都比节点里大的还大;
一颗完美的平衡2-3树所有空节点到根节点距离都一样。
5.1.1 查找
根据目标值和当前节点的值的比较,如果有相等的,那就找到了,如果不相等,根据比较的结果指向响应区间的链接,再去相应的子树中递归的去查找,直到为空,表示未找到。
5.1.2 插入
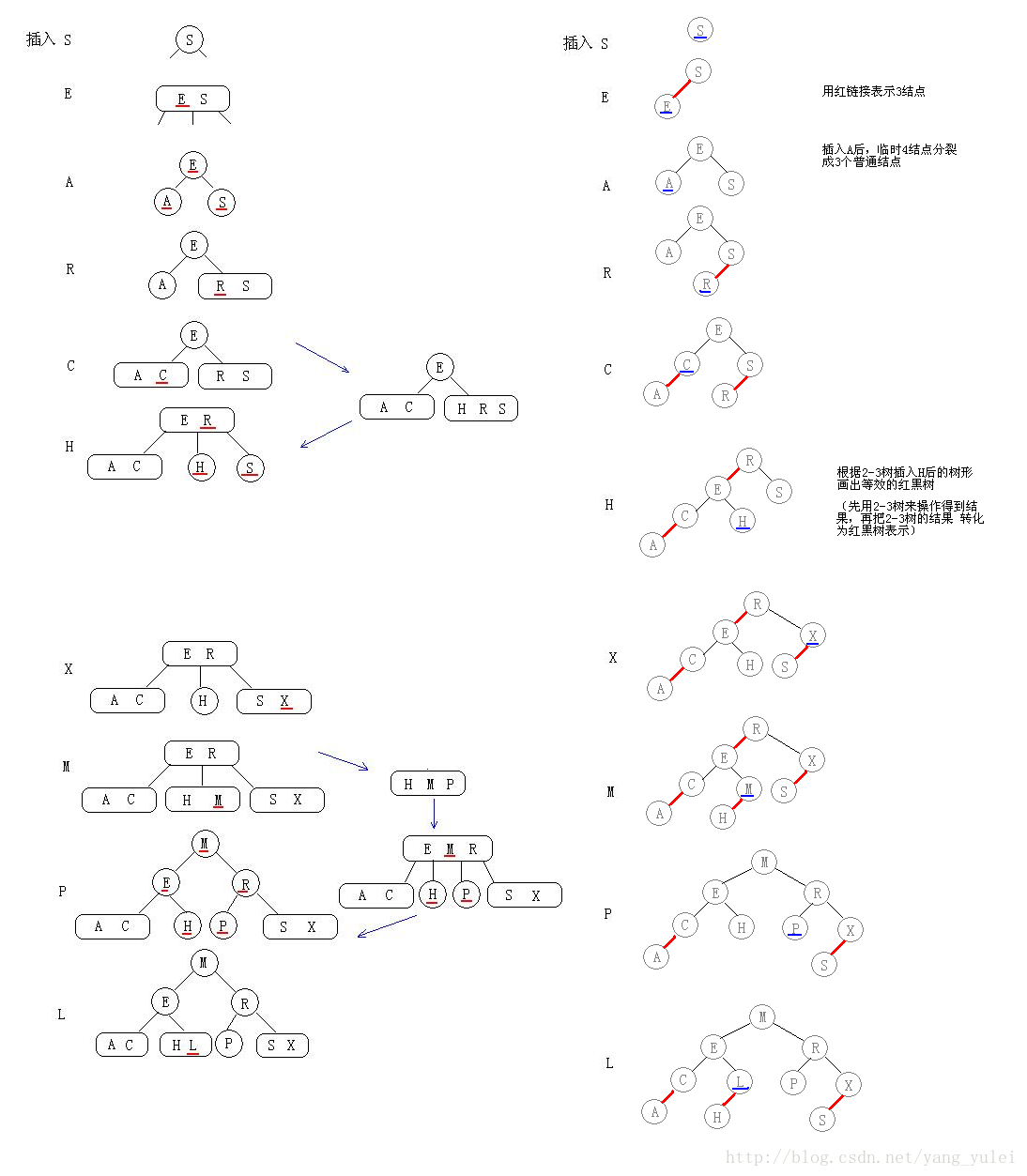
我们使用2-3树的原因就是要使插入新值后树仍然能够保持平衡;
原则:先找插入节点,if节点有空(2节点),那就直接插入;if节点没空(3节点),那就先临时插入(成为了4节点),然后再分裂该节点,中间元素上移;
一句话:有空则插,没空硬插,插完分裂
具体实现可见下面图
根本:2-3树插入算法的根本在于这些变换都是局部的,除了相应的节点和链接外不必修改或者检查树的其他部分,这种局部变换不会影响整棵树的有序性和平衡性;
优点:任何查找或者插入的成本都不会超过对数级别,其他,完美平衡的2-3查找树很平展,例如,10亿个节点的2-3树的高度仅在19-30之间,所以最多其实只需要访问30个节点就可以在10个节点中任意查找;
缺点:需要维护两种不一样的节点,查找和插入需要大量的程序;
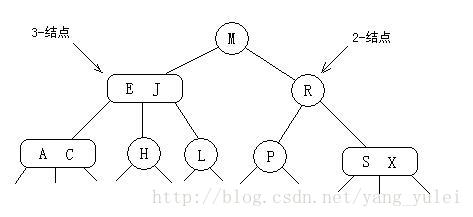
5.2 红黑树
如果理解了上面2-3树的过程,那红黑树就是一句话:用红色链接表示3节点,
红黑树的思想就是用标准的二叉查找树(完全由2节点组成)和一些额外的信息(替换3节点)来表示2-3树;
具体的:我们将3节点表示成为一条由左斜的红链接相连的2节点;
注意
1.红链接均为左链接;
2.没有任何一个节点同时和两条红链接相连;
3.这个树是黑色完美平衡的,即任意空连接到根节点的路径经过的黑连接数量相同
如果我们把红链接全都画平,那所有空连接到根节点的距离都是相同的;如果将红链接链接的节点合并,那就得到一颗2-3树;
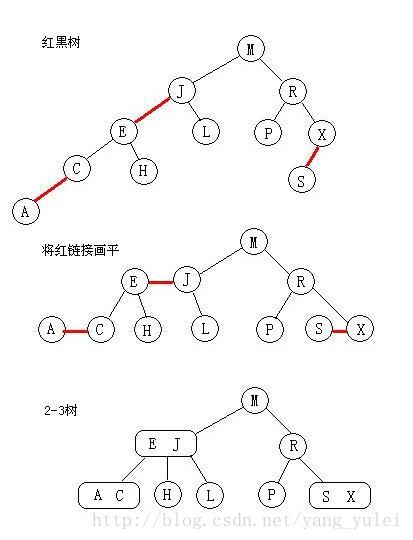
无论我们用何种方式去定义它们,红黑树都既是二叉查找树,也是2-3树。
(2-3树的深度很小,平衡性好,效率高,但是其有两种不同的结点,实际代码实现比较复杂。而红黑树用红链接表示2-3树中另类的3-结点,统一了树中的结点类型,使代码实现简单化,又不破坏其高效性。)
如果是比较大众的红黑树,那里的红节点指的是红链接指向的节点;
2-3树和红黑树构造的全过程
红黑树的特性
1.每个节点或黑或红;
2.根节点是黑;
3.所有的叶子节点(null)是黑;
4.红节点不能相邻(红节点不能有红父节点或红子节点)
5.从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点;
包含N个内部节点的红黑树的高度是O(logN);

6. B树(B-tree)
如果节点存储的数据非常有限,那么就需要查找很多次,但是磁盘的操作费时费资源,所以就想着能不能避免磁盘过于频繁的多次查找呢? --> 减少树的高度 --> 多路平衡查找树
在大规模数据存储方面,大量数据存储在外存储器,而在外存中读/写 块中某数据时,首先需要定位到磁盘中的某块 -- B树
概念:B树是一颗多路平衡查找树,其主要能够使树维持一个较低的高度,从而能够有效避免磁盘过于频繁的查找和存取,提高查找效率;
B树主要是用于存储海量数据的,一般一个节点就占用磁盘一个块的大小;
B树与红黑树最大的不同在于:B树的节点可以有许多子女,从几个到几千个,但是它们又很像,因为其都是平衡查找树,但是B树的高度要小许多。
特点
1.节点的关键字按照递增排序,依然遵循左小右大原则;
2.子节点数:非叶子节点的子节点数>1,且<=M(M是代表M叉树);
3.关键字数:枝节点的关键字数量>=ceil(M/2)-1且<=M-1;
4.所有叶子节点均在同一层;
B树如图所示:
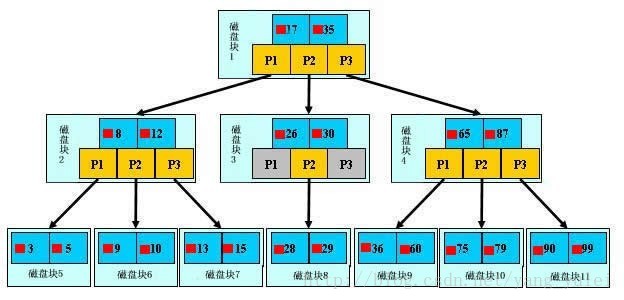
- 图中的小方块表示关键字所代表的文件的存储位置,实际上可以看做是一个地址,比如根节点中17旁边的小红块表表示的就是关键字17对应的文件在硬盘中的位置;
- P是指针,指针、关键字、关键字所代表的的文件地址三样东西构成了B树的一个节点,这个节点存储在一个磁盘块上;
6.1 查找
因为都是排序好的,就和二叉查找树一样,比较然后确定到对应子树上;
B树中的每个节点可以包含大量的关键字信息和分支,根据磁盘驱动的不同,一般块的大小在1K-4K左右,这样树的深度降低了,意味着查找一个元素只要很少节点从外存磁盘中读入内存,很快访问到要查找的数据。
例如要查找上图的29文件:
-
根据根结点指针找到文件目录的根磁盘块1,将其中的信息导入内存。【磁盘IO操作1次】
-
此时内存中有两个文件名17、35和三个存储其他磁盘页面地址的数据。根据算法我们发现:17<29<35,因此我们找到指针p2。
-
根据p2指针,我们定位到磁盘块3,并将其中的信息导入内存。【磁盘IO操作 2次】
-
此时内存中有两个文件名26,30和三个存储其他磁盘页面地址的数据。根据算法我们发现:26<29<30,因此我们找到指针p2。
-
根据p2指针,我们定位到磁盘块8,并将其中的信息导入内存。【磁盘IO操作 3次】
-
此时内存中有两个文件名28,29。根据算法我们查找到文件名29,并定位了该文件内存的磁盘地址。
分析上面的操作,需要3次磁盘IO操作和3次内存查找操作;
6.2 插入
只要会了2-3树其他其实都一样,就一个要领:有空则插,没空硬插,插完分裂
插完之后就成M个元素了,变成M+1阶了,所以要分裂,将中间元素移动到父节点,然后左右各一般元素;
具体可参考此博客B树的查找
特点
B树相对于平衡二叉树的不同是,每个节点包含的关键字增多了,特别是在B树应用到数据库中的时候,数据库充分利用了磁盘块的原理(磁盘数据存储是采用块的形式存储的,)
7.B+树
B+树是B树的一个升级版,更充分的利用了节点的空间,让查询速度更加稳定
特点
1.和B树最大的不同是非叶子节点不保存关键字记录的指针,只进行数据索引,所以每个非叶子节点能保存的关键字大大增加;
2.叶子节点保存了父节点的所有关键字记录的指针,数据地址必须要到叶子节点才能获取到,所以每次查询的次数是一样的。 (叶子节点包含了所有的索引字段)
3.B+树的叶子节点关键字从小到大有序排列,而且左边结尾数据都会保存右边节点开始数据的指针;

问:B+树与B树比的优势?
1.B+树的层级更少:每个内节点存储的关键子树更多,树的层级更少所以查询数据更快;
举个例子,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信
息指针2bytes。一棵9阶B-tree(一个结点最多8个关键字)的内部结点需要2个盘快。而B+
树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B 树就比B+
树多一次盘块查找时间(在磁盘中就是盘片旋转的时间)。
2.B+树查询速度更稳定:B+所有关键字数据地址都在叶子节点上,所以每次查找次数是一样的。
3.B+树天然具有排序功能:B+树所有的叶子节点数据构成了一个有序链表。
4.B+树全节点遍历更快:遍历整颗树只需要遍历所有的叶子节点就可以。
B树相较于B+树:如果要访问的数据离根节点很近,因为其内节点存储数据地址,所以就更快访问到。
本质上,B+树把所有的数据都放到了叶子节点上,而关键字和子女指针放到内节点上,内节点完全是索引的功能。
8. 散列表
普通数组可以直接寻址,能够在0(1)时间内访问数组的任意位置,但是在散列表中,不是直接拿关键字下标作为索引,而是根据关键字计算得到相对应的下标;
使用散列表有两个步骤:
- 1.用散列函数将查找的关键字转为数组的一个索引;
- 2.当多个键散列到相同的索引值时,处理碰撞。
散列表是经典的在时间和空间上做权衡的例子
if没有内存限制,那可以直接将键作为数组索引;
if没有时间限制,那可以用无序的数组顺序查找;
而散列表就是在两者之间找平衡;
为什么不用散列表去做数据库索引?因为哈希表虽然能很快找到一个值,但是在数据库中有很多大于小于等操作,因为散列表不是排序的,那就做不到了。
8.1 散列函数
第一步就是用散列函数将其转换为数组的索引,评价一个散列函数的好坏就是应该易于计算并且能够将所有的键值计算后均匀分布;常见的散列函数有很多种;
8.2 处理碰撞
第二步就是处理碰撞,因为可能有两个以上的键散列到相同的索引,一般有两种方法:
拉链法
将散列到相同的索引上的键按照链表串起来,那么在查找的时候,就先找到键,然后再沿着链表顺序找到对应的键;
线性探测法
当发生碰撞时,直接检查散列表中的下一个位置(索引值+1),如果不同那就继续查找,直到找到该键或遇到一个空元素;
二次探测法
当发生碰撞时,不再按照当前的索引值+1来处理,而是按照平方进行处理,依次是+1,-1,+4,-4,+9,-9来看是否有空位置;
9 数据库索引
再来回顾一下这个过程,我们的目的是在大量的数据里能够快速定位到一个数据或者是一段数据(比如大于或者等于之类的),那采用哪种数据结构呢?
- 哈希表?这个确实能够快速定位,但是那要是大于或者小于咋办,也就是说模糊查询或者范围查询,哈希表没辙了,哈希表都不是按序排列的。
- 二叉查找树?排序嘛,好说,二叉排序树,这能定位到值,也能定位到一段,大于小于等于都能处理,但是,那要是数据库里的索引比如主键都按递增顺序,那这弄成二叉树那不成了一棵歪树了?退化成链表了,那这样查找的话复杂度变成线性了。
- 红黑树?那就把二叉树弄成平衡的,左右子树尽量一样,这次总不能长成歪树了吧,这就是红黑树,但是,问题又来了,动辄几百上千万的数据要是按二叉树去存,那岂不是要几十层,那这几十层每一次读取可都是涉及到磁盘IO的操作,很耗时的,几十次代价太大了;
- B树?既然我们要降低树的高度,那是不是可以让每一层存多点数据,也就是每个节点不是存一个数,存多个,那这样树的高度就降低了,尽量让几千万的数据最后存起来都是3-5层,这样IO操作就比较少了; 但是人总是贪心的,这样感觉还是没充分利用好节点信息,树的高度还是高,能不能更低点。而且如果我要范围查找,也就是查找大于等于这样子的,比如上面的 图里,如果我想找>20的,那我定位到20以后,我还得往上走,也就是去找父节点甚至祖父节点,最终才能把>20的找出来;
- B+树:经过前面的进化,这就是最终形态了,B+树在B树的基础上又进行了升级:除了叶子节点外,所有的节点都只有索引,不再跟着索引的数据地址了,这样就又在每个节点上省了很多空间,每个节点就能存更多的索引了,树的高度就又降低了;其次,所有的数据地址都存储到了叶子节点,所以其实每次查找都会到叶子节点,查找的稳定性也提高了;再其次,对于范围查找,因为每个叶子结点也都是连接着的,而且从小到大排序着,所以很容易进行范围查找,不用往上旋转了;
过程
这个过程是这样的,数据库的值都是保存在磁盘上的,其索引构成了一棵B+树,每次都先把根节点load进内存,然后比如要查找某值,那就在内存中进行比较,找到该去哪里找,然后根据其指针也就是上面的p去把磁盘里的下一节点load到内存里,就这样找,直到找到叶子节点,找到值了,叶子节点里根据不同的索引方式要么放着其索引的数据地址,根据这个地址找到数据,要么就已经存放着数据表的记录了。 (想一下这个过程,我们IO操作其实是十分少的,也就是load很少的次数就可以)
问:什么是索引,索引的分类?
数据库的索引就像是字典里的音序表,if没有音序表,需要去查找某个汉字,那可能需要翻遍几百页;有了索引之后,就可以快速的进行一个查找,尤其是当数据量变大的时候,索引就更重要了。主要的目的就是为了提高查询效率;其实我理解的索引就是把无序的数据变成有序的查询;
- 普通索引:没有多余的限制;
- 唯一索引:索引列的值必须唯一,但是可以是空;
- 主键索引:一个表只能有一个主键,而且不允许有空值;
或者 - 聚集索引(主键索引);
- 非聚集索引:给普通字段加上索引;
- 联合索引:就是好几个字段组成的索引;联合索引遵循最左匹配原则;
哪些数据不走索引?
- Like这种%在前面的不走索引,在后面的走索引:
- 索引进行计算的,不走索引;
- 对索引用函数的,不走索引;
- 索引用了!=的,不走索引;
Like '王%' :走索引;
Like '%王' :不走索引;
where age = 10+8; 走索引;
where age+8 = 10; 不走索引;
where concat('name','哈') ='王哈哈'; 不走索引;
where name = concat('王哈','哈'); 走索引;
select * from student where age != 18 不走索引;
索引其实也可以分为密集索引和稀疏索引两大类:
- 对于MyISAM引擎,不论是主键索引、唯一索引或普通索引,都属于稀疏索引;
- 对于InnoDB引擎,if一个主键被定义,那该主键是密集索引,if没有主键被定义,那该表的第一个唯一非空索引作为密集索引;if都不满足,InnoDB内部会生成一个隐藏主键;
9.1 数据引擎
首先数据引擎是对表来讲的,不是库;
MyISAM存储引擎(非聚集)
非聚集:索引和数据分开存储;(在真实的文件夹下是存在两个文件的:MYI文件和MYD文件),在MyISAM中默认的是表级锁,不支持行级锁;

假设的这样一个三列的表,这就是一个MyISAM的存储引擎,索引的数据文件里保存的是数据记录的地址,这里是把col1作为了了主索引,其实主索引和辅助索引没有太大区别,只不过主索引的key必须唯一,辅助索引的key可以重复;
首先按照B+树的查找规则找到索引,然后取出指定key中data域的值,以data域的值作为地址,读取出数据表中相应的数据记录;
InnoDB存储引擎(聚集)
索引和数据存在一起(只有一个文件:ibd文件)
叶节点包含了完整的数据记录; 在InnoDB中默认的是行级锁,也支持表级锁;

问:为什么InnoDB表必须有主键,并且推荐使用整形的自增长键?
InnoDB的数据文件本身就要按照主键聚集,所以要求必须有主键,如果没有的显式的指定,那就会自动选择一个唯一的数据作为主键,如果没有这种数据列,那就会自动生成这样的一个隐含字段作为主键。
另外,辅助索引的data域存储的是相对应的主键而不是地址,例如下图,也就是说InnoDB的所有辅助索引都引用主键作为data域。这样其实如果按照辅助索引需要两遍索引,首先按照辅助索引获得相对应的主键,然后按照主键到主索引中去获取数据记录;所以如果主键过长会使辅助索引变的过大;
自增长能够节约对整个树的平衡开销,可以直接在后面跟进插入;如果使用非单调的主键,那在插入新记录时会为了维持B+树然后频繁的分裂调整;
问:Mysql中的锁机制?
锁的话就是计算机协调多个进程或者线程并发访问某一资源的机制。在数据库中,数据是需要很多用户共享的资源,所以要保证数据在并发访问的一致性,所以在mysql中需要用到锁;
MyISAM引擎是使用的表级锁,不支持行级锁,InnoDB是默认行级锁,也支持表级锁;
- 全局锁:也就是对整个数据库进行加锁,比如说需要对整个数据库备份的时候;
- 表级锁:开销小,加锁比较快,不会出现死锁的问题,锁定的是整个表,粒度大,发生锁冲突的概率最高,并发度最低;比如MyISAM就是支持表级锁,在Mysql里有两种:一种是表锁,一种是元数据锁(meta data lock,MDL);
表锁:lock tables … read/write;
例如lock tables t1 read, t2 write; 命令,则其他线程写 t1、读写 t2
的语句都会被阻塞。同时,线程 A 在执行 unlock tables 之前,也只能执行读 t1、读写 t2
的操作。连写 t1 都不允许,自然也不能在unlock tables之前访问其他表。
元数据锁:MDL 不需要显式使用,在访问一个表的时候会被自动加上,
在 MySQL 5.5 版本中引入了 MDL,当对一个表做增删改查操作的时候,
加 MDL读锁;当要对表做结构变更操作的时候,加 MDL 写锁。
- 行级锁:开销大,加锁比较慢,会出现死锁的问题,锁定的是单行,粒度小,发生锁冲突的概率最低,并发度也最高;只有InnoDB支持行级锁;
行级锁不是直接锁的数据,而是锁的索引,
if是主键索引,则直接锁定这条主键索引,
if是非主键索引,那就先锁定非主键索引,然后再锁住主键索引;
- 页面锁:开销和加锁时间介于表锁和行锁之间,会出现死锁,锁定粒度在表锁和行锁之间,并发度一般;

问:两个引擎的锁机制?
MyISAM引擎
MyISAM默认的是用表级锁,不支持行级锁;
当有某个表中有数据正在被读取的时候,MyISAM会自动给整个表加上一个读锁,当有数据在被增删改的时候,MyISAM会自动给整个表加上一个写锁。当读锁未被释放的时候,写锁会被阻塞,无法对该表进行增删改,直到所有的读锁释放。同理,写锁未被释放时,读取数据的操作会被阻塞,不仅如此,一个写锁未释放,其他写锁也会被阻塞。因此,读锁也被称为共享锁,写锁也称为排他锁/互斥锁。
MyISAM适合场景:频繁的执行全表的count命令,增删改的要求不高,查询频繁的时候,没有事务的时候;
InnoDB引擎
InnoDB支持事务和行级锁
开销大,加锁比较慢,会出现死锁的问题,锁定的是单行,粒度小,发生锁冲突的概率最低,并发度也最高
InnoDB适合场景:数据增删改查都比较频繁的时候,可靠性要求比较高支持事务的场景;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号