【知识详解】JAVA基础(秋招总结)
JAVA基础
问:面向过程(POP)和面向对象(OOP)?
- 面向过程主要是指从前到后的执行,强调的是一种功能行为,是以函数为最小单位的,主要考虑从前到后该怎么做;
- 面向对象指的是把一些属性和方法给提取出来组合成一个类,主要强调的是具有功能的对象,是以类/或者说对象为最小单位的,考虑的是谁来做;
问:Python和Java的区别?
对象:首先两者都是面向对象的语言,但是侧重点我感觉不一样,java语言的设计集中在对象和接口,提供了类和接口的实现,在对象中封装变量和对应的方法,实现信息的封装和隐藏,类提供了对象的原型,并且通过继承的机制,子类可以使用父类提供的方法,实现代码复用; python的话是既支持面向对象的函数编程,也支持面向对象的抽象编程;
语言:java是强类型语言,数据类型定了以后就不能改变,同时也是一种静态语言,在变量声明的时候就要声明变量类型,这样的话编译器在程序运行的时候就知道变量的类型,提前按数据类型规划好了内存区域,找起来范围就变小了,所以更快一些; 而python是弱类型语言,同时是一种动态语言,在程序运行时解释器只知道变量是一个对象,具体是什么类型根本不知道;所以速度相对较慢,比如list,变量任意类型;
在python中一切皆对象,a=1背后是a=int(1),1在java里是基本数据类型,但在python里是对象,所以也是在堆里分配空间的;
应用:java主要用于商业上,比如各种web端等,但是python用途最多的是脚本,像数据分析或者深度学习算法上;
库:实际使用的python入门很简单,有很多很强大的库,python的库可以用python、c语言等设计,所以无论是深度学习,智能算法、数据分析,图像处理都有各种各样的库,java的话库没有那么多,很多库都是商业公司内部使用的,或者发布出来的一个jar包,看不到源代码;
问:java的八大基本数据类型?
| 数据类型 | 内存大小 |
|---|---|
| byte | 1kb |
| short | 2kb |
| int | 4kb |
| long | 8kb |
| float | 4kb |
| double | 8kb |
| char | 英文1kb,中文utf-8 3kb |
| boolean | 4kb |
问:封装继承多态说一下?
封装:封装有很多体现,比如有一些事物拥有共同的属性和方法,所以就可以把这些属性和方法放到一起,这就是封装的一种体现;再比如,把一些属性和方法声明为私有的,也就是private的,外部不能对其直接进行访问和修改,只对外暴露一些接口,能够解耦合,无需知道具体实现细节,做到一个信息的隐藏,这也是封装的一种体现;
继承:有一些类都有相同的属性和方法,所以就可以把这些属性和方法提出来放到一个公共的基类里,也就是父类,然后这些类就可以继承这个父类,获得父类里非私有化的属性,能够提高程序的复用性,同时这也是多态的前提;
多态:多态是指父类的引用能够指向子类的对象。引用变量在调用方法时,并不能够确定是哪个方法,只有在运行的时候才知道,其实这也是一种向上转型。创建的是一个父类的引用,实际指向的是子类的对象。另外也体现在方法的重写上,子类可以直接继承父类的方法,如果想修改也可以对该方法进行重写,这也是多态的体现。能够提高程序的可扩展性;
问:方法和函数的区别?
方法可以说是函数的一种
- 函数是一段代码,可以通过名字调用,把一些数据传进去处理,然后返回一些数据,或者没有返回值也行;
- 方法也是一段代码,也是通过名字来调用的,但是它跟一个对象关联,可以操作类内部的数据;
问:抽象类和接口的区别?
- 一提抽象类,就是指不能被实例化,要被继承,但是有构造器,构造器是供子类使用的,抽象类中有抽象方法,只有声明,没有方法体,if子类继承了抽象类,那一定要重写抽象方法;
- 接口更多的是一种“能不能”的关系,本质上是一种标准和规范,其中的方法都是public abstract, 属性都是public static final,也就是说只有抽象方法和常量,没有构造器;主要用来被实现类实现,一个类可以实现多个接口;
- 抽象类的成员变量可以是各种类型,但是接口是public static final类型,也就是常量;一个类可以继承一个抽象类,但是可以实现多个接口;抽象类是对事物进行的一种抽象,包括属性和行为,是一种“是不是”的关系,但是接口更多的是对一些行为进行抽象,主要是“能不能”的关系.
问:==和equals区别?
- ==:它的作用是判断两个对象地址是否相同,判断两个对象是不是同一个(具体对于基本数据类型就是值相不相等,引用数据类型就是比较地址);
- equals:也是判断两个对象是否相等;但是很多时候都会重写equals方法,重写以后就是比较的内容是不是相等;
问:final,finally和finalize的区别?
- final是一个关键字,可以用来修饰属性、方法和类,final修饰的属性不能被修改,方法不能被重写,类不能被继承;
- finally是异常处理的里面的语句,往往和try-catch一起使用,能够保证在finally的程序一定会被执行;
- finalize是Object类的一个方法,所以每个类都有这个方法,这个方法在在垃圾回收的时候被调用;
问:重写和重载的区别?
- 重写:重写指的是子类重写了父类的方法;要求是同名同参数,即两者的方法名相同,参数列表也相同;除此之外,子类方法的返回值类型应该小于等于父类方法的返回值类型,重写的方法访问权限要大于等于被重写的;
- 重载:重载指的是同样的方法根据输入的不同,做出的反应也不同,是同一个类中同名的参数,但是参数列表不同;
问:static关键字说一下?
static是一个关键字,能够把属性和方法声明为静态的,意思就是说这些是随着类的加载而加载的,静态变量只加载一次,存在方法区中,静态方法只能调用静态的属性和方法,都可以直接用类来调用;之所以要用这个就是因为 有些数据在内存空间里只要有一份就行,不用每个对象都单独再分配,是成员共享的;比如最常见的单例模式,就是只能创建一个实例对象;
问:Java的值传递?
java是采用的值传递,是将实参的副本传入方法,参数本身不受影响;
- 基本类型的变量,将变量进行了拷贝,所以方法无论怎么修改都不会影响原变量;
- 引用类型的变量,将变量所指向的对象地址进行了拷贝,所以会修改到原对象;
问:深拷贝和浅拷贝?
这是经常会碰到的一种情况,因为经常会用到复制还有赋值操作,其实也是因为java的值传递机制;
- 浅拷贝:拷贝后有和原始对象一样的值,比如如果是基本数据类型,就拷贝这个类型的值,如果是引用数据类型,就拷贝内存中的地址,所以如果任何一个进行了修改的话,这个值都是要变化的;
- 深拷贝:在拷贝引用数据类型的变量时,为这个成员开辟了一个独立的内存空间,是内容上的拷贝,两者指向的是不同的内存空间,两者修改不再相互影响;
问:String、StringBuffer和StringBuilder区别?
- String是字符串常量,是不可变的对象,每次对String拼接的时候,都是新创建了一个String对象,然后指向了新的String对象;
- StringBuffer是字符串变量,初始化长度为16的数组,装不下就扩容,扩容为原来的2倍+2,同时将原数组复制到新数组中; 是线程安全的,所以当多线程的时候用stringBuffer;
- StringBuilder是字符串变量,是线程不安全的,但是其效率比StringBuffer要高,String的效率最低;
问:new一个字符串和直接定义个一个字符串?
- 通过new来创建字符串:首先在编译期间先去字符串常量池中检查是否存在该字符串,不存在就开辟空间新建一个,存在的话就不键了,常量池中始终就存在一个这样的字符串;然后在堆里开辟出一块空间存刚在的字符串(姑且理解为存着方法区里的字符串地址),栈里开辟出空间存放创建的引用变量,引用变量指向堆里面那块地址;
- 通过字面量创建的话,也是在常量池中检查是否有当前字符串,没有的话就新建一个,然后栈中的引用变量指向方法区的字符串;
问:cookie和session的区别?
http是无状态的协议,服务器不能够从网络连接上知道客户端的身份;所以才有了cookie和session;
- cookie是浏览器保存少量数据的一种技术,每次访问服务器的时候都会带着,比如用户的登录信息等;
- session是服务器保存当前会话数据的一种技术,主要是在服务端记录用户的状态;session放在服务端安全性要高一些;
- 在实际应用中,是将两者结合使用,如果所有信息都保存在cookie里太占用空间了,每次访问都得带着,所以就会用到session;浏览器第一次访问服务器的时候,服务器会创建一个session和sessionID,然后设置cookie将sessionID发给浏览器,浏览器以后每次访问服务器都要带着,这样服务器就能根据sessionID来判断是哪个用户了;
问:说一下java的异常(throw和throws)?
Java的异常都继承自Java.lang.throwable类,主要分为两大类:一个是error,一个是exception,error一般不需要编写针对性代码进行处理,exception又分为编译时异常和运行时异常;
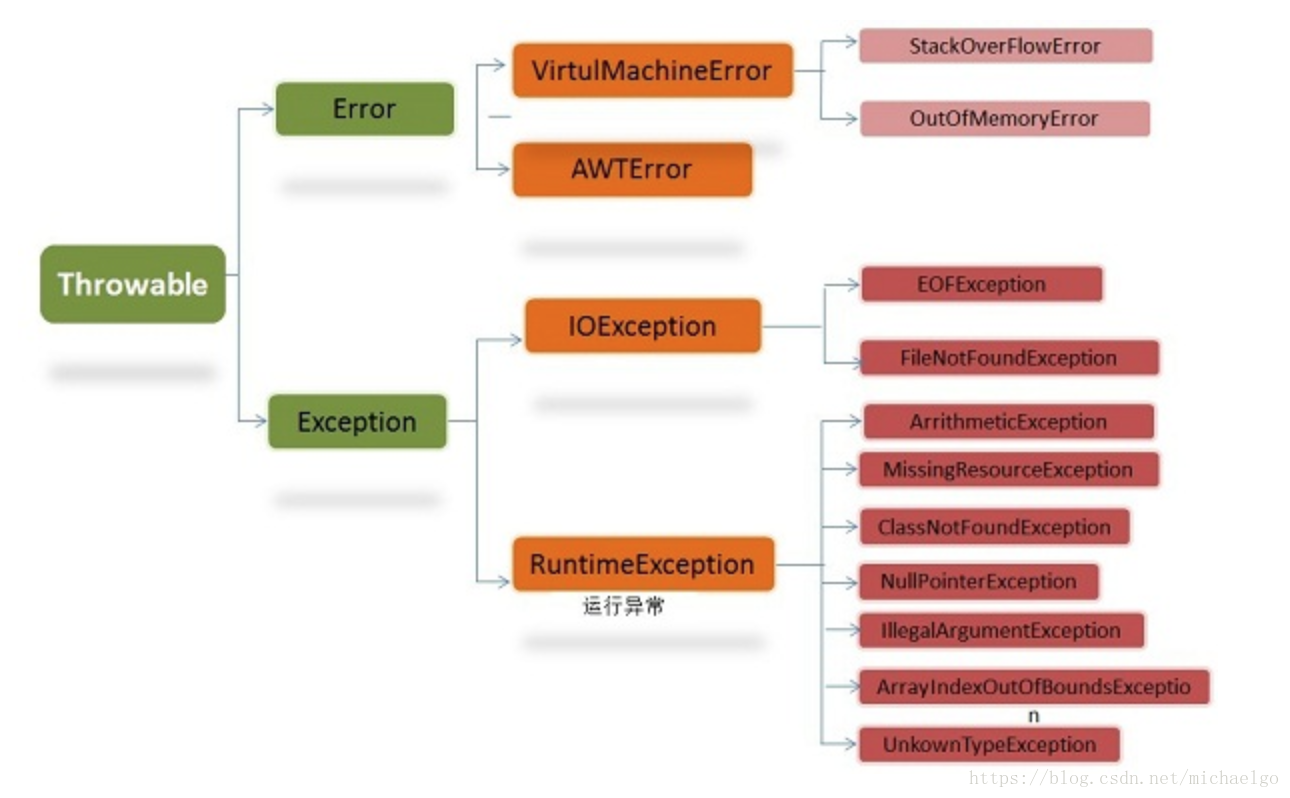
对于异常的处理,主要是用到抓抛模型,也就是说java在运行的时候if产生异常,会生成一个异常类对象,然后抛出,当捕获到对应的异常后,进行相应的处理,然后异常类对象的抛出,可以有两种实现方法,一是系统自动生成,一是手动生成并抛出(throw);
异常处理有两种机制:
-
try-catch-finally:产生异常后通过catch进行捕获并处理;
-
throws:声明抛出异常,意思就是不处理,往上抛,由该方法的调用者去处理;
-
throw是在异常的生成阶段,指的是手动抛出异常对象;
-
throws是在异常的处理阶段,它是一种异常的处理方式;
问:什么是序列化?
Java 对象在 JVM退出时会全部销毁,如果需要将对象持久化就要通过序列化实现,将内存中的对象保存在二进制流中,需要时再将二进制流反序列化为对象。对象序列化保存的是对象的状态,属于类属性的静态变量不会被序列化。
常见的序列化有三种:
① Java 原生序列化,实现 Serializabale标记接口,兼容性最好,但不支持跨语言,性能一般。序列化和反序列化必须保持序列化 ID 的一致,一般使用 private static final long serialVersionUID 定义序列化 ID,如果不设置编译器会根据类的内部实现自动生成该值。
② Hessian 序列化,支持动态类型、跨语言。
③ JSON 序列化,将数据对象转换为 JSON 字符串,抛弃了类型信息,反序列化时只有提供类型信息才能准确进行。相比前两种方式可读性更好。
序列化通常使用网络传输对象,容易遭受攻击,因此不需要进行序列化的敏感属性应加上 transient 关键字,把变量生命周期仅限于内存,不会写到磁盘
集合
问:List、Set、Map区别?
- List是存储有序、可重复的数据;类似于一种“动态”数组;建立时不用指定长度;
- Set是存储无序、不可重复的数据,类似于数学上“集合”的概念;
- Map是存储的键值对;Key-Value的形式;是一对的数据;
问:ArrayList、LinkedList、Vertor区别?
- ArrayList是List的主要实现类,底层创建了长度为10的object数组,在jdk7的时候是初始化的时候就创建,然后如果不够了就扩容为原来的1.5倍,然后把原来数组复制到新数组中;jdk8以后在初始化的时候不创建了,延迟创建,第一次调用add的时候创建;
- LinkedList是维持了一个类似双向链表,内部是Node类型,有first和last属性,指向前一个元素和后一个元素;
- Vector和ArrayList一样,只不过是同步的,访问慢点,无论是jdk7还是8,都是创建长度为10的数组,不够了扩容为原来2倍;
- ArrayList是基于动态数组,所以其获取和修改比较快,而LinkedList是基于链表的,所以其插入和删除有优势;两者都不是同步的, Vector就是同步的ArrayList,所以其访问要比ArrayList慢,同时每次扩容为原来2倍,而ArrayList是1.5倍;
问:HashMap底层实现原理?
在jdk1.8以前,哈希表底层是采用数组+链表来实现的:
- 1.当创建一个哈希表时,底层创建了一个长度为16的一维数组Entry[];
- 2.然后向里面添加元素时,首先调用key所在类的hashcode计算出来它的哈希值,然后将哈希值通过某种散列函数得到在数组中的位置;
- 3.if当前位置上没有元素,那就直接添加成功;if当前位置上有元素,那就比较当前key的哈希值和已经存在元素的哈希值,if都不一样,那就添加成功;如果有元素哈希值也一样,那就调用equals方法,if都为false,那就添加,如果和谁比价是true,那就这个key的值做更新;
在jdk1.8里,哈希表底层采用的是数组+链表+红黑树的结构,和之前的区别主要有3个
- 1.初始化的时候没有创建数组,而是在第一个put的时候创建;
- 2.底层数组不再是entry,变成了node;
- 3.当数组某一索引处的元素个数>8但是< 64的时候,采用红黑树存储;
问:为什么重写equals必须重写hashcode方法?
因为在进行哈希表的put或者其他操作时,if两个对象相等,那两个对象的hashcode也一定是相等的;if两个对象相等,那去调用equals方法时返回true,但是反过来就不成立了,if两个对象具有相等的hashcode,不一定相等,也就是说,当equals方法被覆盖过后,hashcode也必须得覆盖;
问:HashMap如何扩容?
哈希表有负载因子的概念,一般取0.75,当数组长度大于默认容量*负载因子的时候,就扩容,默认扩容为原来的2倍,然后重新计算元素在新数组中的位置(rehash),然后复制进去;
这个负载因子其实控制着哈希表中的数据密度。if过大,那就会增加碰撞的几率,链表就会长;if过小,就很容易引发扩容,造成内存浪费;
问:HashMap的长度为什么是2的n次方?
HashMap是为了存取高效,要求是尽量减少碰撞,也就是尽可能把数据分配均匀;这个算法实际上就是在取模,hash%length;但是在计算机中求余运算不如位运算,所以在源码中是使用位运算进行计算的:hash&(length-1);
但是hash%length == hash&(length-1)的前提是length是2的n次方;
为什么这样能均匀分布减少碰撞呢?因为2的n次方实际上就是1后面n个0,2的n次方-1实际上就是n个1;这样进行与的时候就会减少碰撞;
例如长度为9的时候:3&(9-1)=0, 2&(9-1)=0,都在0上,发生碰撞;
例如长度为8的时候:3&(8-1)=0, 2&(8-1)=0,不同位置上,不发生碰撞;
问:hashmap和hashtable的区别?
- 首先最重要的区别是hashmap是线程不安全的,而hashtable是线程安全的;
- 其次hashmap是允许存放空置null的,而hashtable不允许存放空值,if为null会抛异常;
- hashmap在底层实现上初始化容量为16,之后每次扩容为原来的2倍,而hashtable初始容量为11,之后每次扩容为原来的2倍+1;
问:Hashmap为什么线程不安全?
hashmap不安全其实主要体现在需要扩容的时候,比如如果在原数组里,有这几个数据:[3,A],[7,B],[5,C],而且都在一个桶上,也就是entry数组,然后执行扩容,假如线程1执行完:Entry next = e.next,时间片切到了线程2,这时候e是[3,A],而next是[7.B],然后线程2 resize完了之后,假如[7.B]的next后成了[3,a],又回到线程1,线程1先处理自己当时的e,[3,a],然后next,[7,B],但是,这时候因为[7,B]的next变成了[3,a],所以就变成了一个循环链表,陷入死循环;
所以一般在多线程的时候不会用hashmap,hashtable是线程安全的,但是它是把所有需要多线程的操作都加上了synchronized关键字,所有线程都在竞争一把锁,效率太低;
所以现在涉及到线程安全的时候一般采用concurrenthashmap;
问:HashMap实现线程安全的方法有哪些?
主要有两个方法:
- 使用concurrentHashMap[首选],因为下面两个都会给整个集合进行加锁,导致其他操作阻塞,性能低下;
- 使用hashtable;
- 使用线程安全下的hashmap,使用collections下的线程安全的容器;比如Collections.synchronizedMap(new HashMap());
问:说一下concurrenthashmap?
JDK1.7
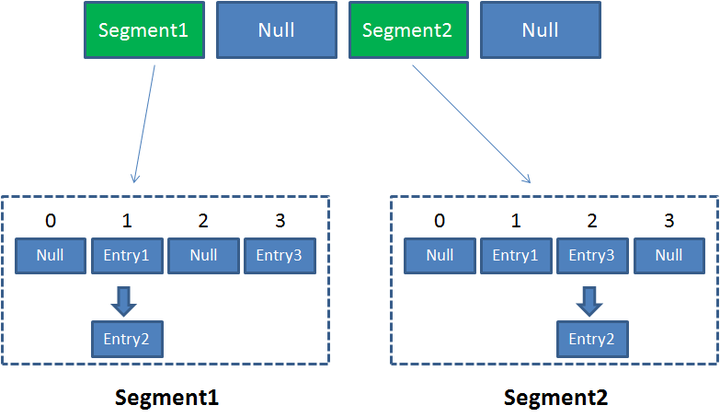
底层是由segment数组、hashentry数组和链表组成;segment本身相当于一个hashmap对象,然后里面包含一个hashentry数组,数组中的每个hashentry既是一个键值对,也是一个链表的头节点;
可以说concurrenthashmap是一个二级哈希表,在总哈希表下又若干个子哈希表;主要是通过分段锁来实现的,每一个segment都是一个独立的锁,内部是hashmap 。整体的结构如下图类似:
- put操作:
1.进行第一次key的hash来定位Segment的位置(其实还会进行一次hash以减少冲突);
2.if Segment还没有初始化,那就进行赋值;segment初始化主要是hashentry数组初始大小(cap,默认为1),负载因子;
3.进行第三次hash操作,找到相应的HashEntry的位置;
4.在将数据插入指定的HashEntry位置时,会通过继承ReentrantLock的tryLock()方法尝试去获取锁,如果获取成功就直接插入相应的位置;
5.如果已经有线程获取该Segment的锁,那当前线程会以自旋的方式去继续的调用tryLock()方法去获取锁,超过指定次数就挂起,等待唤醒;
- get操作:
第一次需要经过一次hash定位到Segment的位置,再hash定位到指定的HashEntry,遍历该HashEntry下的链表进行对比,成功就返回,不成功就返回null;
- size操作:类似于乐观锁和悲观锁
1.第一种方案以不加锁的模式去尝试多次计算ConcurrentHashMap的size,最多三次,比较前后两次计算的结果,结果一致就认为当前没有元素加入,计算的结果是准确的;乐观锁
2.第二种方案是如果第一种方案不符合,他就会给每个Segment加上锁,然后计算ConcurrentHashMap的size返回;悲观锁
JDK1.8
在JDK1.8中和hashmap一样,为了防止查询链表的复杂度变为O(N), 底层采用了Node数组+链表+红黑树组成;
node节点都采用volatile来修饰,保证并发的可见性;内部大量采用syschronized和cas来操作,每次只锁定当前链表或者红黑树的根节点,保证效率;
concurrentmap和hashtable区别?
hashtable是一种类似于全表锁,使用synchronized来保证线程安全,效率很低,当一个线程访问同步方法时,其他线程就不能访问了,会进入阻塞状态,效率太低;
而concurrentmap是使用了分段锁的思想,效率就要高很多了。
泛型
问:说一下泛型?
泛型就是我们在定义类或方法的时候,可以不用确定好参数,而是使用一种类似标签的想法,等编译的时候才去确定好具体的类型,这个确定类型的工作推迟到了创建对象或者方法调用的时候。
采用泛型能够解决一些问题,比如说集合里可以存储object类型,所以各种类都能放到集合里,一方面这样不安全,另一方面在使用集合里的元素时,需要进行强制类型转换,麻烦而且容易出错;使用了泛型,那就不需要了,而且这种可读性和稳定性也提高了,在写程序的时候就能够限定类型;
反射
问:说一下反射?
我理解的反射,可以说是正常创建new对象的反过程,正常情况下,是引入需要的类,然后通过new来实例化,然后再得到实例化后的对象,反射的话是实例化对象,然后调用getClass方法能够得到整个类的结构。这样的话就能够动态的获取类的信息,或者动态的调用类对象的方法和属性。这就是反射。
所写的程序经过javac.exe命令以后,会生成一个或多个字节码文件(以.class结尾),然后使用java.exe命令对字节码文件进行解释运行,相当于将某个字节码文件加载到内存中,这就是类的加载,这时加载到内存中的类称为运行时类,这个运行时类就作为整个Class类的一个实例;这个Class类是java反射的源头;可以通过Class类来获取Class类实例
Person p1 = new Person();
Class clazz = p1.getClass(); //获取Class类实例,也就是运行时类;
//Class<Person> clazz = Person.class(); //得到运行时类的另一种方法;
Person obj = (Person)clazz.newInstance(); //得到运行时类的实例对象;需要有运行时类的空参构造器;
框架
问:说一下IOC的原理?
IoC 是控制反转的意思,也就是把对象创建和对象之间的调用过程都交给Spring来进行管理,主要目的是为了降低程序之间的耦合度,IOC是基于IOC容器来完成的,底层就是对象工厂。主要有两种创建方式,一种是基于xml配置文件,一种是基于注解方式。
问:说一下AOP?
AOP 是面向切面编程,将代码中重复的部分抽取出来,使用动态代理技术,在不修改源码的基础上对方法进行增强。
如果目标对象实现了接口,默认采用 JDK 动态代理,也可以强制使用 CGLib;如果目标对象没有实现接口,采用 CGLib 的方式。
常用场景包括权限认证、自动缓存、错误处理、日志、调试和事务等。
相关术语
Aspect:切面,一个关注点的模块化,这个关注点可能会横切多个对象。
Joinpoint:连接点,程序执行过程中的某一行为,即业务层中的所有方法。(类里面哪些方法可以被增强,这些方法称为连接点);
Advice:通知,指切面对于某个连接点所产生的动作,包括前置通知、后置通知、返回后通知、异常通知和环绕通知。(实际增强的逻辑部分,称为通知或者说增强)
Pointcut:切入点,指被拦截的连接点,切入点一定是连接点,但连接点不一定是切入点。(实际被真正增强的方法,称为切入点);
Proxy:代理,Spring AOP 中有 JDK 动态代理和 CGLib 代理,目标对象实现了接口时采用 JDK 动态代理,反之采用 CGLib 代理。
Target:代理的目标对象,指一个或多个切面所通知的对象。
Weaving :织入,指把增强应用到目标对象来创建代理对象的过程。
相关注解
@Aspect:声明被注解的类是一个切面 Bean。
@Before:前置通知,指在某个连接点之前执行的通知。
@After:后置通知,指某个连接点退出时执行的通知(不论正常返回还是异常退出)。
@AfterReturning:返回后通知,指某连接点正常完成之后执行的通知,返回值使用 returning 属性接收。
@AfterThrowing:异常通知,指方法异常退出时执行的通知,和 @AfterReturning 只会有一个执行,异常使用 throwing 属性接收
问:Spring中有哪些设计模式?
简单工厂模式:Spring 中的 BeanFactory,根据传入一个唯一的标识来获得 Bean 实例。
工厂方法模式:Spring 的 FactoryBean 接口的 getObject 方法。
单例模式:Spring 的 ApplicationContext 创建的 Bean 实例都是单例对象。
代理模式:Spring 的 AOP。
适配器模式:Spring MVC 中的 HandlerAdapter,由于 handler 有很多种形式,包括 Controller、HttpRequestHandler、Servlet 等,但调用方式又是确定的,因此需要适配器来进行处理,根据适配规则调用 handle 方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号