20244211 2024-2025-2 《Python程序设计》实验四报告
20244211 2024-2025-2 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 2442
姓名: 朱睿颖
学号:20244211
实验教师:王志强
实验日期:2025年5月13日
必修/选修: 专选课
1.实验内容
- Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
例如:编写从社交网络爬取数据,实现可视化舆情监控或者情感分析。
例如:利用公开数据集,开展图像分类、恶意软件检测等。
例如:利用Python库,基于OCR技术实现自动化提取图片中数据,并填入excel中。
例如:爬取天气数据,实现自动化微信提醒。
例如:利用爬虫,实现自动化下载网站视频、文件等。
例如:编写小游戏:坦克大战、贪吃蛇、扫雷等等。
注:在Windows/Linux系统上使用VIM、PDB、IDLE、Pycharm等工具编程实现。
其中,我选择了编写爬虫,用python程序实现从豆瓣电影网上爬取电影排行前100电影。
2. 实验过程及结果
- 编写对应爬虫程序。
(1)用import导入对应模块。比如说用于解析网页的解析库BeautifulSoup。
![]()
(2)进行必要的定义与赋值。main标志着程序的开始,给save_path赋值,其实就明确了它的保存路径,save_data(datalist, save_path),意思是要把爬取的数据保存到excel文件中.
![]()
(3)先创建一个空列表,用来存储所有电影的数据。用循环结构来操作,然后通过改变start的值,生成每一页。接着,ask_url函数是用来获取页面的HTML内容,再用BeautifulSoup解析库。
找到页面中所有div标签,从而找寻对应电影。将item转换为字符串,方便用正则表达式处理。接着,用正则表达式从item中提取电影的链接,标题,评分,评价人数,并将提取到的电影链接、标题、评分和评价人数依次添加到data列表中。最后,将当前电影的数据添加到datalist中。
def get_data(base_url):
datalist = []
for i in range(0, 10): # 爬取10页数据
url = base_url + str(i * 25)
html = ask_url(url)
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('div', class_="item"):
data = []
item = str(item)
# 使用正则表达式提取数据
link = re.findall(r'<a href="(.*?)">', item)[0]
title = re.findall(r'<span class="title">(.*?)</span>', item)
rating = re.findall(r'<span class="rating_num".*?>(.*?)</span>', item)[0]
judge = re.findall(r'<span>(\d*)人评价</span>', item)[0]
data.append(link)
data.append(title[0])
data.append(rating)
data.append(judge)
datalist.append(data)
return datalist
(4)正式开始爬取网页内容:先模拟浏览器访问网页。User-Agent可以告诉我是用什么浏览器访问的网站,然后获取网页的HTML内容。
def ask_url(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
}
response = requests.get(url, headers=headers)
return response.text
(5)保存爬取的数据:创建一个Excel工作簿,添加一个名为“豆瓣电影Top250”的工作表。用循环结构,将列名写入表格的第一行。遍历每一部电影数据,并取出电影的数据,用循环结构,将电影的链接、名称、评分和评价人数依次写入表格的对应列,保存Excel文件到之前定义过的指定路径。
def save_data(datalist, savepath):
book = xlwt.Workbook(encoding="utf-8")
sheet = book.add_sheet('豆瓣电影Top250')
col = ("电影链接", "电影名称", "评分", "评价人数")
for i in range(0, 4):
sheet.write(0, i, col[i])
for i in range(0, len(datalist)):
data = datalist[i]
for j in range(0, 4):
sheet.write(i + 1, j, data[j])
book.save(savepath)
- 完整程序源代码、视频运行过程如下:
import requests
from bs4 import BeautifulSoup
import re
import xlwt
import sqlite3
def main():
base_url = "https://movie.douban.com/top250?start="
datalist = get_data(base_url)
save_path = "豆瓣电影Top250.xls"
save_data(datalist, save_path)
def get_data(base_url):
datalist = []
for i in range(0, 10): # 爬取10页数据
url = base_url + str(i * 25)
html = ask_url(url)
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('div', class_="item"):
data = []
item = str(item)
# 使用正则表达式提取数据
link = re.findall(r'<a href="(.*?)">', item)[0]
title = re.findall(r'<span class="title">(.*?)</span>', item)
rating = re.findall(r'<span class="rating_num".*?>(.*?)</span>', item)[0]
judge = re.findall(r'<span>(\d*)人评价</span>', item)[0]
data.append(link)
data.append(title[0])
data.append(rating)
data.append(judge)
datalist.append(data)
return datalist
def ask_url(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
}
response = requests.get(url, headers=headers)
return response.text
def save_data(datalist, savepath):
book = xlwt.Workbook(encoding="utf-8")
sheet = book.add_sheet('豆瓣电影Top250')
col = ("电影链接", "电影名称", "评分", "评价人数")
for i in range(0, 4):
sheet.write(0, i, col[i])
for i in range(0, len(datalist)):
data = datalist[i]
for j in range(0, 4):
sheet.write(i + 1, j, data[j])
book.save(savepath)
if __name__ == "__main__":
main()
3. 实验过程中遇到的问题和解决过程
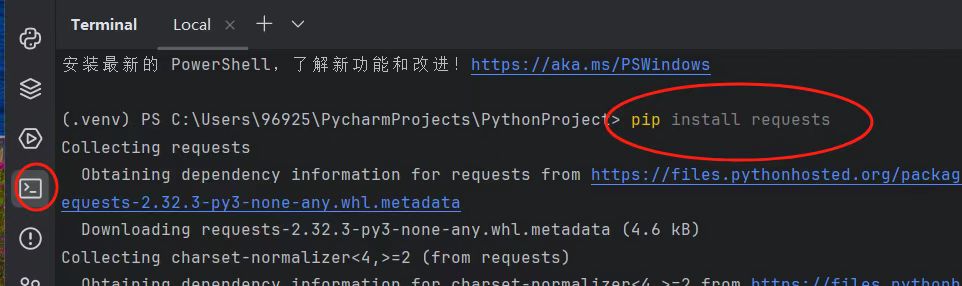
- 问题1:没有安装对应的解析库,导致程序报错。
![]()
- 问题1解决方案:输入pip install 加对应解析库名称,安装解析库。
![]()
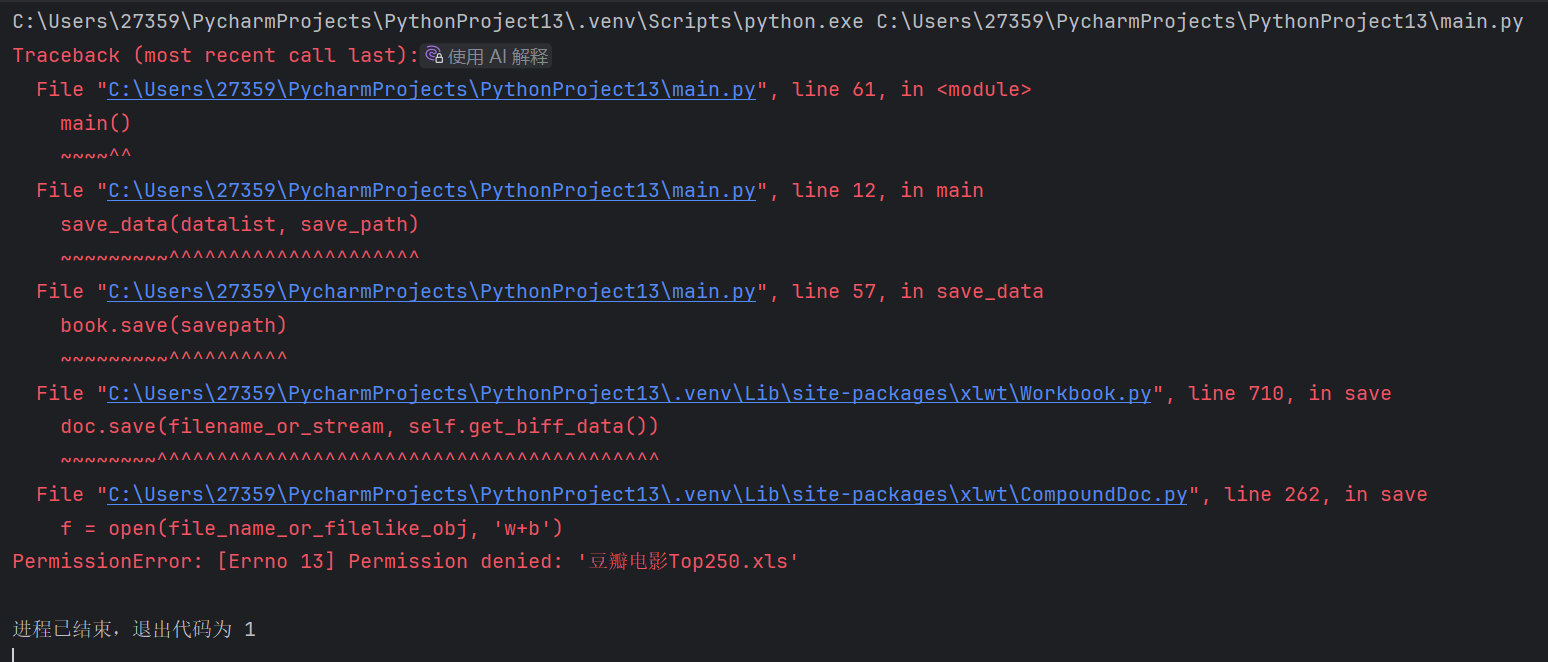
- 问题2:代码无法将数据保存到文件中。
![]()
- 问题2解决方案:因为程序运行过,已经保存过一遍了,要将生成的文件删除后,才能运行。

其他(感悟、思考等)
- 本次课程的感悟:
(1)学到的知识:我学会了如何使用网络爬虫,并深入理解了其背后的工作原理和应用场景。它是一种强大的自动化工具,能够高效地从互联网上抓取结构化或非结构化数据。首先。我学会了很多模块的作用。比如:requests用于获取网页内容,BeautifulSoup可以提取数据,xlwt生成了存储我爬取的数据的Excel文件。而且,当我发现通过使用pip命令,我成功安装了requests、BeautifulSoup、re和xlwt等库。本次课程还让我巩固了之前所学的列表和遍历知识。在爬虫程序中,列表被广泛用于存储和处理数据。例如,在提取电影信息时,我使用了列表data来存储每部电影的链接、标题、评分和评价人数。随后,我将data列表添加到更大的列表datalist中,从而实现了对多部电影数据的存储和管理。而且,在我运行程序的时候,我发现,当我成功新运行程序时,程序报错,因为我已经生成了需要爬取的数据表格,这让我对于程序的运行有了更深的理解。
(2)经验教训:在实验过程中,我遇到很多问题,遇到没有安装对应类库时,我意识到开发环境的准备是编程实践的重要组成部分。通过学习如何使用pip安装所需的库,我不仅解决了当前的问题,还掌握了在今后开发中可能用到的技能。当解决了发现代码无法将数据保存到文件中,这同样让我明白了在处理文件时需要注意的细节。文件路径、文件名都是需要仔细检查的地方。通过这些问题,我对Python爬虫有了更丰富、全面的了解。同时,还磨炼了我的心性。现在的我,面对复杂需求时不再畏惧,而是能够冷静分析、拆解问题,逐步实现目标。
(3)感想体会:“人在事上练,刀在石上磨。”编写这个程序充满了困难和挑战。从翻阅相关书籍,查阅爬虫基本用法和编写方法,到运行频繁报错,我一步步走来,一个个攻克问题。当很多模块我都不理解含义,我一个个查询网上资料,调试代码。第一次插入链接,我仔细阅读插入链接的方法,并且请教同学,终于成功在B站上发布了视频。正是这些困难和挑战,赋予爬虫程序编写以非凡意义,在钻研过程中,我对Python有了更深的了解和热爱。 - Python课程的感悟:
(1)知识的掌握:通过本次课程的学习,我在Python编程方面取得了显著的进步。目前,我已经掌握了Python编程的入门知识和基本原理,从最基础的变量定义、数据类型(如整型、字符串、列表、字典等)和运算符使用开始,逐步深入到条件判断、循环控制等流程控制语句的灵活运用,同时,进一步的学习让我理解了参数传递、返回值、作用域等概念。后来,我能够通过编写简单的代码。比如,我会制作各种有趣的小游戏,例如石头剪刀布和猜数字。此外,我还学会了如何通过文件操作来编辑日记,这让我能够将Python应用于实际的文本处理任务中。通过学习函数定义和循环语句,我能够编写简单的应用程序,进一步提升了我对编程的理解和应用能力。同时,我还积累了一些常用的函数的表达方式。这些工具让我在编写代码时更加得心应手,能够快速实现各种功能。此外,我还学习了服务端和客户端的程序开发,这些知识体系相互关联、层层递进,使我对Python从入门到应用形成了完整的认知框架,为后续更深入的学习打下了坚实基础。虽然在这个过程中遇到了不少困难,但这些经历也让我对网络编程有了更深入的理解。
(2)能力的锻炼:逻辑思维的培养是本次课程的一大亮点。我学会了如何分析问题,并将其转化为代码。这个过程极大地锻炼了我的逻辑思维能力此外,我在面对困难时的毅力也得到了提升。在开发服务端和客户端程序时,我遇到了多次报错的情况。这些错误让我感到困惑和沮丧,但我没有放弃。通过向老师请教和查阅资料,我逐步解决了这些问题。这个过程不仅让我学会了如何调试程序,还让我明白了在遇到困难时要坚持不懈,在和朋友的合作中积极寻找解决办法。同时,我还学会利用问题导向提升编程技术,通过一次次调试,我得以发现我的知识体系中存在的缺陷,记得有一次,在开发服务器和客户端程序时,两台电脑始终无法正常连接。我反复检查代码,却始终找不到问题所在。那几天,我和搭档反复讨论,却始终找不到问题所在。我没有选择逃避,而是主动向老师请教。老师耐心地帮我分析,指出是IP地址找错的缘故。同时,我还查阅了大量的资料,学习IP地址相关的知识。这个过程不仅让我学会了如何调试程序,更让我明白了每一个问题都是学会新知识的“锚点”。每一次克服困难,都是一次成长的机会。
(3)个人体会:学习Python,首先感受到的是其语言的简洁性,其他语言,需要有冗长的代码,如C语言往往需要定义变量类型,Python无需如此,而且可以调用函数轻松表达所需内容。而且,最让我着迷的是它的逻辑性。通过if-else分支结构,我学会了如何将题目中的选择判断转化为清晰的程序流程;使用for和while循环时,我理解了如何处理重复性的操作。Python让我理解到算法背后的数学之美,以及如何用计算思维解决实际问题。而且,我还理解了科学常识,比如网络端口,这让我的科普知识得以丰富。而且,Python赋予我一种科学的、严谨的世界观,以一种科学、理性的逻辑对待我们的生活,进而保持对知识纯粹的热爱,保持对这个世界、对编程世界的探索欲。
(3)意见和建议:王老师的教学展现了卓越的教育能力。理论讲解时,您能用生活化的类比阐释抽象概念,让我理解了很多知识比如类库。案例设计独具匠心,从游戏开发到服务端和客户端的对话,每个项目都既有趣味性又有实用价值。特别欣赏您采用的"提问式教学法",比如在讲解列表时,先用例题告诉我们其中的规律性,再提问同学来检测我们对于规律的掌握程度,这种主动学习、随时反馈的学习机制极大地提升了学习效果。对于课程改进,我有几点建议:可以增加更多的编程环节,让我们在自己调试代码的过程中感受Python的乐趣;同时,建议提供一些扩展阅读资料,满足不同层次学生的学习需求;最后,建议王老师在讲解难度较大的知识时,多做一些简单类比或者例题的铺垫,便于同学们理解。总之,这门课程不仅传授了技术知识,更点燃了我对编程的热情。感谢王老师富有感染力的教学,您生动的教学案例、耐心的答疑解惑、以及您向我们呈现的富有逻辑的Python之美,都让我受益匪浅。我期待在未来能保持对Python的热爱,对世界前沿科技有更多的了解。
参考资料
- 《零基础学Python》
- 《Python网络爬虫从入门到实践》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号