CopyOnWriteArrayList源码分析到面试题
前言
我们学过ArrayList之后都知道,它是一个线程不安全的集合。在多线程情况下,会出现许许多多的问题,如果别人问你,那么该如何解决?你可能会想到vector,但是其实vector也只能保证一个相对线程安全,不能保证绝对线程安全(在多线程下,我们的一个线程恰好在错误的时间里面删除了一个元素,位置为i,那么另一个线程就有可能访问到这个i的时候发生数组越界异常。)。而且vector其实也只是在ArrayList上加了Synchronized修饰,并发度大大降低。
所以我们需要去认识一下关于ArrayList的另一个线程安全的集合——CopyOnWriteArrayList。(为方便,后面统称COWArrayList)
写时复制机制
关于这部分来自参考资料第一篇,需要深入的可以去了解。
在正式分析COWArrayList源码之前,我们先来了解一下CpoyOnWrite机制,也就是写时复制机制。所谓写时复制机制就是在我们在对数组进行修改的时候对其修改操作和增加操作等操作的时候都是在底层创建一个拷贝数组(快照)进行的,所以被称为写时复制机制或写时拷贝机制。(如果不想了解COW在其他方面的应用可以跳过下面部分直接到源码分析。)
这里我们以Linux下的COW实际运用再加深一下对这个机制的印象。
在说明Linux下的copy-on-write机制前,我们首先要知道两个函数:fork()和exec()。需要注意的是exec()并不是一个特定的函数, 它是一组函数的统称, 它包括了execl()、execlp()、execv()、execle()、execve()、execvp()。
fork函数
所谓fork是类Unix操作系统上创建线程的主要方法。fork用于创建子进程(等同于当前进程的副本),也就是说新的进程都是通过老的进程自身得到到。例如在我们的Linux中,init进程就是所有进程的父进程,这些进程都是通过init进程或者init子进程fork出来。
关于fork函数这里需要注意几个点:
(1)fork作为一个函数被调用。这个函数会有两次返回,将子进程的PID返回给父进程,0返回给子进程。(如果小于0,则说明创建子进程失败)。
(2)当前进程调用fork(),会创建一个跟当前进程完全相同的子进程(除了pid),所以子进程同样是会执行fork()之后的代码。
(3)父进程在执行if代码块的时候,fpid变量的值是子进程的pid,子进程在执行if代码块的时候,fpid变量的值是0。
exec函数
fork会创建一个父进程的副本子进程,而exec函数的作用就是装载一个新的程序,也就是在执行的时候会直接替换当前进程的地址空间。举个例子也就是我们父进程fork一个子进程,子进程会继续执行父进程之后的代码,但是我们fork出来就是让你干别的事,所以需要覆盖掉当前的进程,给它别的任务。
比如:
(1)原本父进程A是用来打印Hello World,fork出的子进程默认也是打印Hello World;
(2)子进程调用了exec()函数之后,就会替换打印Hello World的功能,变成自己自定义的代码了。
Linux下的COW
按照我们上面介绍的,父进程的数据拷贝到子进程之后,父进程和子进程的数据段和堆栈是相互独立的。而我们的子进程往往都要执行exec()来做自己想要的功能,但是这样又会清空我们复制过去的数据,所以就有了COW。
COW原理还是比较容易理解的:
- fork创建出的子进程,与父进程共享内存空间。也就是说,如果子进程不对内存空间进行写入操作的话,内存空间中的数据并不会复制给子进程,这样创建子进程的速度就很快了!(不用复制,直接引用父进程的物理空间)。
- 并且如果在fork函数返回之后,子进程第一时间exec一个新的可执行映像,那么也不会浪费时间和内存空间了。
这里父子进程虽然逻辑空间是不同,但是物理空间是同一个。如果只读取内存的话,父子进程这样是最好的选择。但是如果父子进程中有更改相应段的行为发生时候,会再为子进程相应的段分配物理空间(至此两者有各自的进程空间,互不影响),而代码段继续共享父进程的物理空间(两者的代码完全相同)。
具体技术实现原理如下:
fork()之后,kernel把父进程中所有的内存页的权限都设为read-only,然后子进程的地址空间指向父进程。当父子进程都只读内存时,相安无事。当其中某个进程写内存时,CPU硬件检测到内存页是read-only的,于是触发页异常中断(page-fault),陷入kernel的一个中断例程。中断例程中,kernel就会把触发的异常的页复制一份,于是父子进程各自持有独立的一份。
COW技术优缺点
优点
- COW技术可减少分配和复制大量资源时带来的瞬间延时。
- COW技术可减少不必要的资源分配。比如fork进程时,并不是所有的页面都需要复制,父进程的代码段和只读数据段都不被允许修改,所以无需复制。
缺点
如果在fork()之后,父子进程都还需要继续读写操作,那么会产生大量的分页错误(页异常中断page-fault),得不偿失。
COW源码分析
关于COW源码大概有1600多行,这里我觉得把基本重要成员属性,构造方法以及重要方法讲讲便可。
成员属性分析
/** The lock protecting all mutators */
final transient ReentrantLock lock = new ReentrantLock();
/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;
这里用到一个可重入锁和volatile修饰的数组。
(1)这里我们因为在写时复制的获取-拷贝-写入三步并不是原子性,所以需要一个独占锁来保证同时只有一个线程才能对list数组进行修改。
(2)这里我们用volatile修饰我们的数组是也是因为volatile保证内存的可见性,可以在我们的新数组替换旧数组之后,能够第一时间读取到新数据。
构造方法分析
构造方法有三个,都是比较好分析的。
(1)空构造方法。
/**
* Creates an empty list.
*/
public CopyOnWriteArrayList() {
setArray(new Object[0]);
}
创建一个空数组,没有默认容量,不像我们的ArrayList有默认容量10。
(2)传入Collections下的集合。
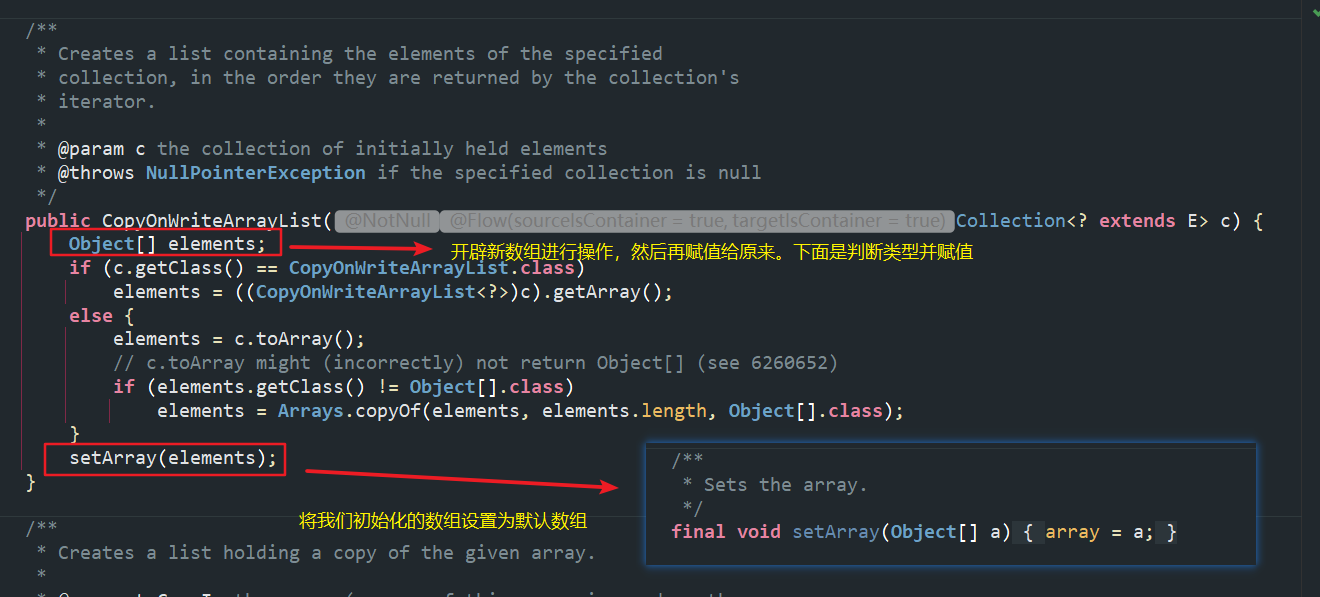
使用时需要传入一个集合,例如:
CopyOnWriteArrayList<Integer> cow = new CopyOnWriteArrayList<>(new ArrayList<>());
(3)传入我们封箱后的数组。

使用时需要传入一个封装数组,例如:
CopyOnWriteArrayList<Integer> cow = new CopyOnWriteArrayList<>(new Integer[]{});
重要方法分析
好了,下面开始一些我们比较重要的方法。
(1)add(E) 方法分析
我们都说COW是写入时复制,来看看源码人家是怎么实现的。
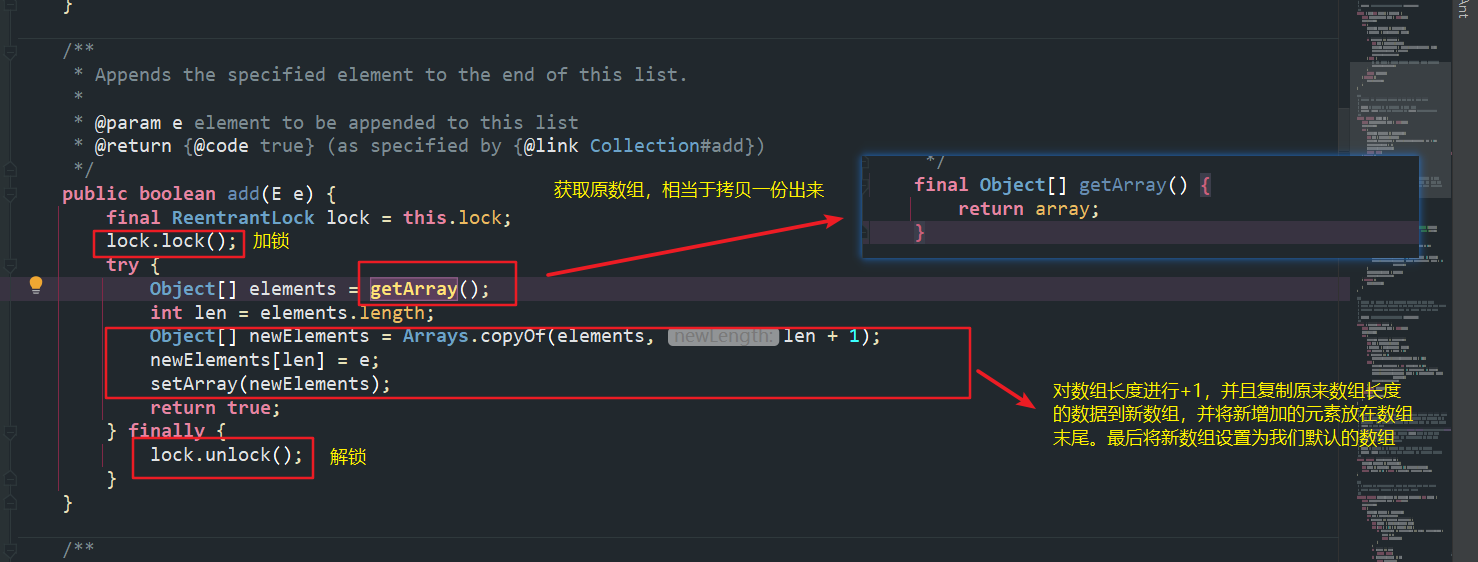
简单分析一下增加步骤:
-
加锁。原因也说过了,因为我们的获取-拷贝-写入不是原子性的,这是为了保证线程安全。
-
拷贝数组到一个新的数组(长度+1)。
-
给数组最后一个位置复制为当前添加的对象。
-
给数组引用复制,设置为我们原来的数组。原来的数组在一段时间后就会被gc。
-
解锁。lock类需要自己手动释放锁。
思考?💡
这里同样需要我们去思考一些问题,为什么这里每一次添加都要进行一次复制呢?而不是像ArrayList那样去扩容?
答:其实这里我们要从COWArrayList设计去分析,我们的COW就是写时复制,适用与读多写少的场景,所以虽然每一次写的时候都需要进行一次复制,但是写的机会少,而且每次只增加一个容量,非常的节约空间。
(2)remove(int index)方法分析
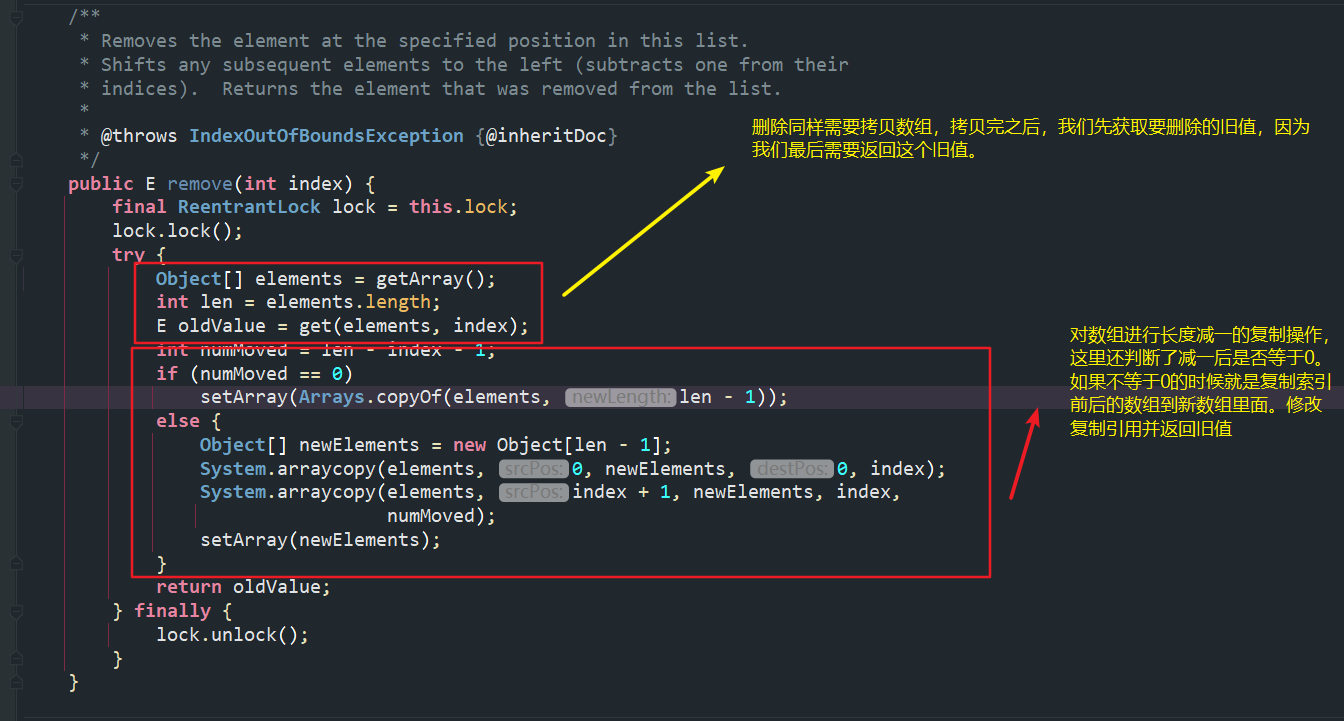
同样的,我们总结分析一下,删除的步骤:
- 加锁。
- 先获取我们的旧数组的副本,毕竟是写时复制。然后存取我们的要删除的值,等到最后返回。
- 如果删除的是最后一个元素,直接复制前面所有的元素到新数组即可。
- 如果删除的不是最后一个元素,分两次复制,复制删除位置前后的数据到新数组里面。
- 修改复制引用,让新数组代替老的数组。
- 释放锁。
(3)remove(Object o)方法分析
上面的删除方法是直接删除索引的,这里的删除方法是删除具体元素的。
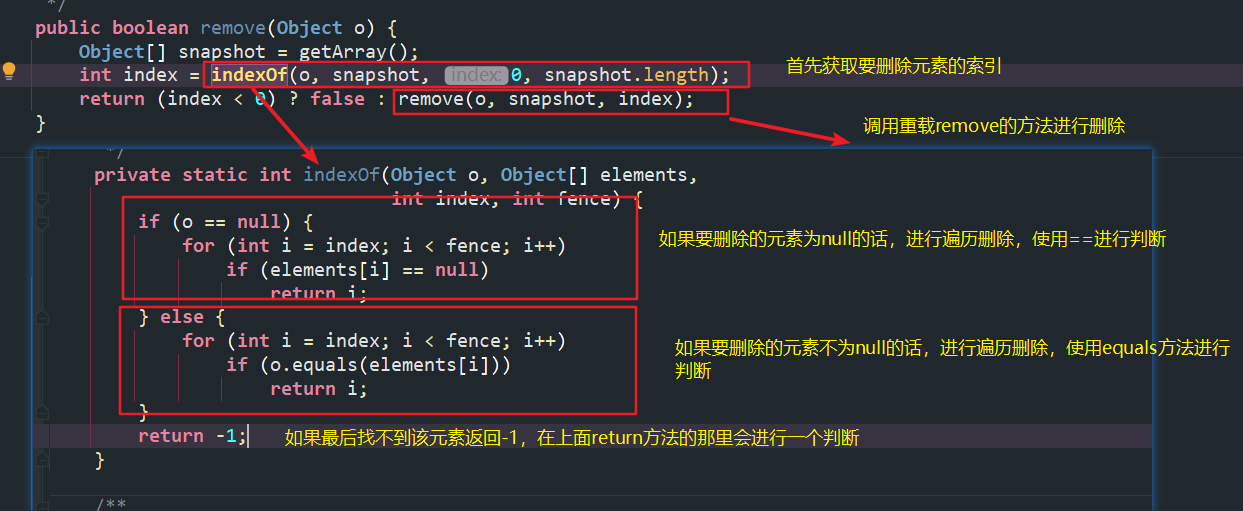
我们继续看重载的方法,真正涉及到删除的操作。

(4)set(int index, E element)方法分析
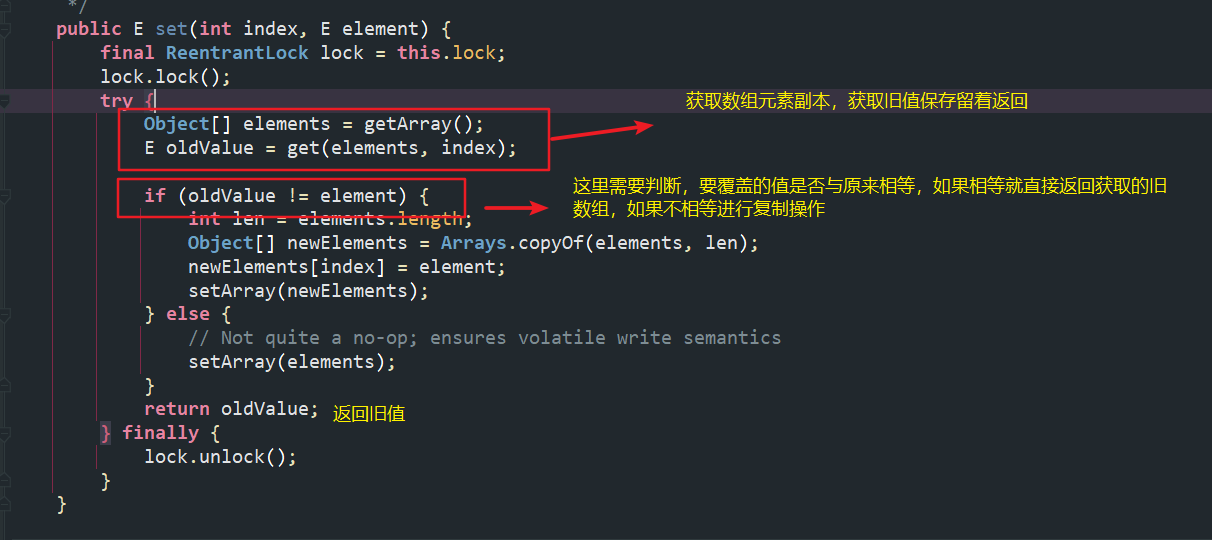
(5)迭代器Iterator
本来想分析一下COW下的迭代器,不过看了一下源码也没什么好分析。我们所有的迭代都是拿出了一个旧的数组在那进行迭代。所以写时复制的读也叫做快照读,而我们这个迭代器也被称为弱一致性迭代器。
关于弱一致性迭代器举一个例子再说明,比如我们现在COW里面已经有了5个数据。然后我们获取了它的迭代器,但是我们不着急进行迭代。我们再开一个线程往里面添加5个元素,如果可以发现我们的迭代器里面还是5个元素,而不是10个元素,没有保持一致性,所谓弱一致性迭代器。
总结
其实简单阅读一下源码,就可以对COW的使用和特性有了一个比较透彻的了解。
(1)COW是写时复制,所以是适用与读多写少的场景,原因在上面也分析过了,贴合设计保证线程安全并且节约空间。不过需要注意的是,因为用到了写时复制,所以内存里面可能会存在两个array数组,如果内存占用的太大,那么就会造成频繁GC,所以COW并不适合大数据量的场景。
(2)读是可以并发的,但是我们的读因为是获取的旧数组在那读取,所以也可以说是快照读。
(3)写的时候需要加锁,因为我们的获取-拷贝-写入不是原子性的,所以需要加锁,这里我们用的是Lock下的可重入锁。
(4)我们的最底层的数组是没有容量的Volatile修饰的Object数组,主要为了修改我们的复制引用的使用保证内存可见性,可以第一时间被其他线程所知道。
(5)面试题基本就是上面这些总结了,具体能讲讲我觉得就OK了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号