SpringCloud-Eureka(3)集群配置和了解CAP原则
集群配置
我们在之前的博客演示了如何配置一个注册中心,在微服务崩了的时候,注册中心有自我保护模式来处理,那么注册中心崩了怎么办呢?实际上,就是运用集群的方法来解决的。我们按之前配置一个注册中心一样再配置两个。
导入相同的依赖
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka-server</artifactId>
<version>1.4.6.RELEASE</version>
</dependency>
</dependencies>
创建配置application.yml
server:
port: 7001
#Eureka配置
eureka:
instance:
hostname: localhost #服务端的实例名称
client:
register-with-eureka: false #表示是否向服务中心注册自己
fetch-registry: false #为false的话,表示自己为注册中心
service-url: #与服务中心进行交互的一个地址
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
我们将三个注册中心的端口分别设置7001,7002,7003。为了能够分辨三个注册中心的主机名,我们去C:\Windows\System32\drivers\etc\hosts配置三个映射域名。(不配置的话,都是localhost,在注册中心集群那里不能明确显示属于哪个集群)
我们在下面添加
127.0.0.1 eureka_7001
127.0.0.1 eureka_7002
127.0.0.1 eureka_7003
可能会出现没有权限的问题,这里有解决方案。关于hosts文件无权限
添加成功之后,我们修改yml文件里面的主机名和注册地址
这是7001注册端口的yml文件
server:
port: 7001
#Eureka配置
eureka:
instance:
hostname: eureka-7001 #服务端的实例名称
client:
register-with-eureka: false #表示是否向服务中心注册自己
fetch-registry: false #为false的话,表示自己为注册中心
service-url: #与服务中心进行交互的一个地址
defaultZone: http://eureka-7002:7002/eureka/ ,http://eureka-7003:7003/eureka/
7002,7003注册端口的同样只需要改一下我们映射的主机名,和添加其他两个的注册地址。
然后我们配置好了三个服务注册中心,接下来只需要把我们三个注册中心的地址给我们的服务提供者就行,在yml里面配置地址
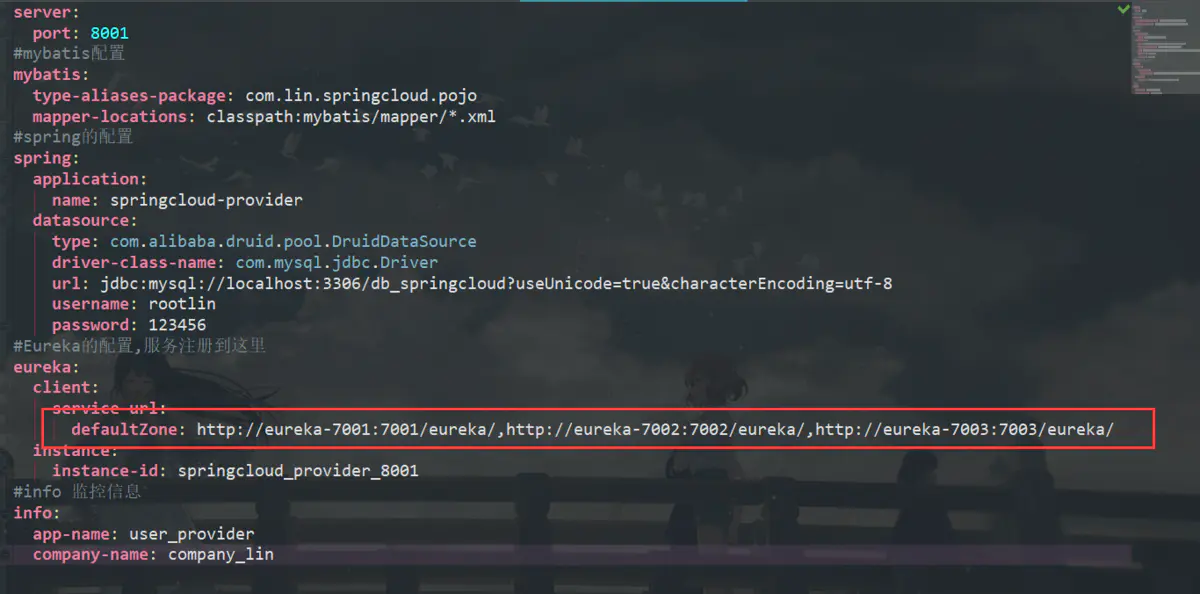
接下来就是按照顺序打开我们的注册中心的服务器,最后打开服务提供者的服务器。
我们随便访问eureka-7001:7001,eureka-7002:7002,eureka-7003:7003,都可以看到其他两个注册中心,这就是集群。
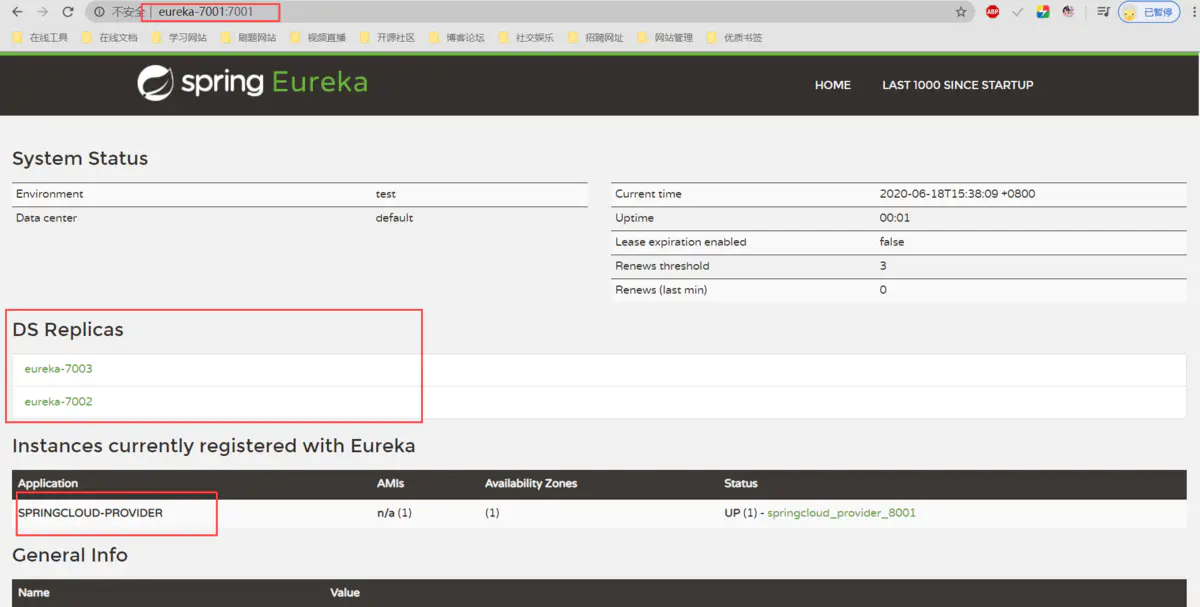
而且每个注册中心都有我们注册进来的服务,这个时候哪怕有一个服务中心崩了,我们的服务也还是可以提供的,这就是集群的好处。
CAP原则
CAP原则又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。

CAP理论的核心
- 一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求
- 根据CAP原理,将NOSQL数据库分成了满足CA原则,CP原则,AP原则三大类:
- CA:单点集群,满足一致性,可用性的系统,通常可扩展性较差
- CP:满足一致性,分区容错性的系统,通常性能不是特别高
- AP:满足可用性,分区容错性的系统,通常可能对一致性要求低一些
Zookeeper保证CP
当向注册中心查询服务列表时,我们可以容忍注册中心返回的是几分钟以前的注册信息,但不能接受服务直接down掉不可用。也就是说,服务注册功能对可用性的要求要高于一致性。但是zk会出现这样一种情况,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30 ~ 120s, 且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪。在云部署的环境下,因网络问题使得zk集群失去master节点是较大概率会发生的事,虽然服务能够最终恢复,但是漫长的选举时间导致的注册长期不可用是不能容忍的。
Eureka保证AP
Eureka看明白了这一点,因此在设计时就优先保证可用性。Eureka各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而Eureka的客户端在向某个Eureka注册或时如果发现连接失败,则会自动切换至其它节点,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性)。除此之外,Eureka还有一种自我保护机制,如果在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,此时会出现以下几种情况:
- Eureka不再从注册列表中移除因为长时间没收到心跳而应该过期的服务
- Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上(即保证当前节点依然可用)
- 当网络稳定时,当前实例新的注册信息会被同步到其它节点中
因此, Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像zookeeper那样使整个注册服务瘫痪。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号