支持向量机算法(Support Vector Machine Alg)的介绍及数学推导
本文章的大致内容包括 SVM 的介绍、推导过程中的基本概念介绍、数学推导。我会把问题描述到最容易理解。参考资料主要有李航老师的《统计学习方法》、吴恩达老师的机器学习课程、python scikit learn的官方文档和上个学期的课件。
支持向量机介绍
支持向量机(support vector machines,
SVM)是一种二分类模型。它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机,支持向量机还包括核技巧,这使它成为实质上的非线性分类器。(关于“间隔”、“核技巧”的介绍在下文中会讲)
支持向量机的应用
Support vector machines (SVMs) are a set of supervised learning methods used for classification, regression and outliers detection.
译:支持向量机是一种监督学习算法,可以用于分类问题、回归问题和异常点识别问题。
直观理解支持向量机
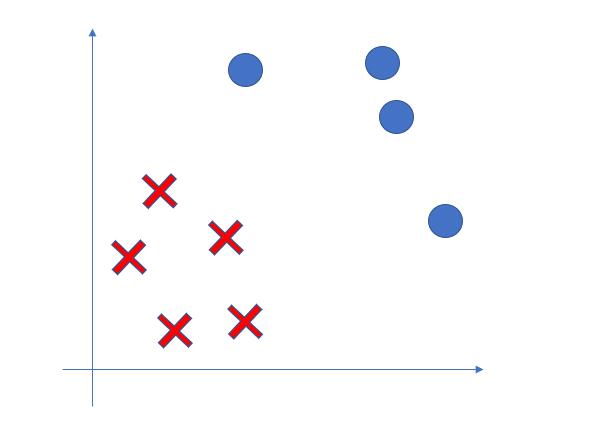
假设在一个二分类问题中,我们的样例中有四个正例和五个反例(其中正例由圆形表示,反例由叉表示),如 pic0 所示。
现在我们想通过一条直线将正例和反例区分开。显而易见,能够实现分类的有无数条直线,图中我们给出了三条分类直线:l1、l2、l3,如 pic1 所示。
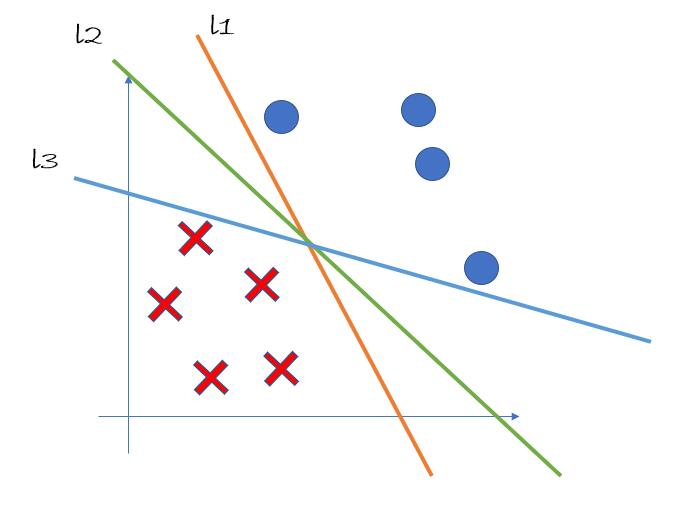
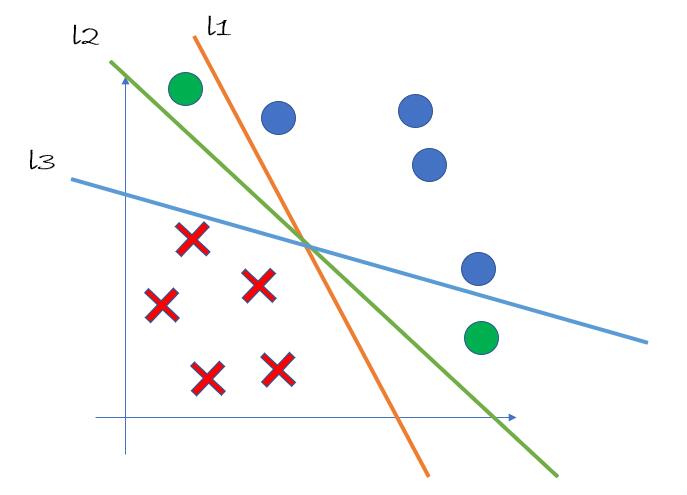
然而,这三条直线的分类能力并不相同。假设我们再向训练样例中添加两个正样例(在 pic2 中用绿色的圆点表示),此时我们可以发现,直线 l1 和直线 l3 失去了完美的分类能力,因为它们没法将新加入的样例成功分类。
由此我们可以看出,l2 的分类能力比 l1 和 l3 的分类能力更强。而支持向量机算法就是去寻找所有直线中分类最强的那一条直线。在后面的推导过程中,我们也会证明:在这样的线性可分问题中,分类能力最强的直线(也就是“超平面”,后面会介绍)有且仅有一条。
支持向量机的优势和劣势
了解 SVM 的优势能够帮助我们在合适的问题中选择合适的算法。
在看过后面算法的推导过程之后,会对支持向量机的优势和劣势有更深刻的了解。
支持向量机的优势
- Effective in high dimensional spaces.在高维空间中比较容易使用。
- Still effective in cases where number of dimensions is greater than the number of samples. 当样本特征数比样本数更多的时候,支持向量机仍然可以用。
- Uses a subset of training points in the decision function (called support vectors), so it is also memory efficient.仅仅用到了训练集中的部分样例(即支持向量),所以会节省内存空间。
- Versatile: different Kernel functions can be specified for the decision function. Common kernels are provided, but it is also possible to specify custom kernels.不同的核函数决定不同的决策函数。在python的scikit learn库中提供了普遍使用的核函数,当然我们也可以自定义核函数。
支持向量机的劣势
- If the number of features is much greater than the number of samples, avoid over-fitting in choosing Kernel functions and regularization term is crucial.当样本特征数比样本数多的时候要注意防止过拟合,这个时候核函数的选择至关重要。
- SVMs do not directly provide probability estimates, these are calculated using an expensive five-fold cross-validation (see Scores and probabilities, below).sklearn包并不直接提供概率评估,是通过代价很大的五折交叉运算来实现的。
支持向量机的分类
-
线性可分支持向量机(linear support vector machine in linearly separable case)
通过硬间隔最大化(hard margin maximization)学习一个线性的分类器,又称为硬间隔支持向量机。 -
线性支持向量机(linear support vector machine)
当训练数据近似可分时,通过软间隔最大化(soft margin maximization)形成线性不可分支持向量机,简称为线性支持向量机 -
非线性支持向量机(non-linear support vector machine)
当训练数据集线性不可分时,通过使用核技巧以及软间隔最大化来学习非线性支持向量机。
相关定义和方法介绍
L0, L1, L2范数
直观地说,
L0范数:\(||x||_0 := \sum_{i = 1}^n x^0\) 即向量中所有非零元素的个数;L1范数:\(||x||_1 := \sum_{i = 1}^n |x|\) 即向量中所有元素绝对值的和;L2范数:\(||x||_2 := \sqrt{\sum_{i = 1}^n x^2}\) 即欧几里得(Euclidean)范数;
范数是一个函数,其赋予某个向量空间(或矩阵)中的每个向量以长度或大小。对于零向量,另其长度为零。
直观的说,向量或矩阵的范数越大,则我们可以说这个向量或矩阵也就越大。有时范数有很多更为常见的叫法,如绝对值其实便是一维向量空间中实数或复数的范数,而Euclidean距离也是一种范数。
p范数(p-norm)的表达公式:
函数间隔和几何间隔
首先在这里补充超平面的概念,超平面即分离不同类样本的分界面,在二维空间中的超平面就是线。
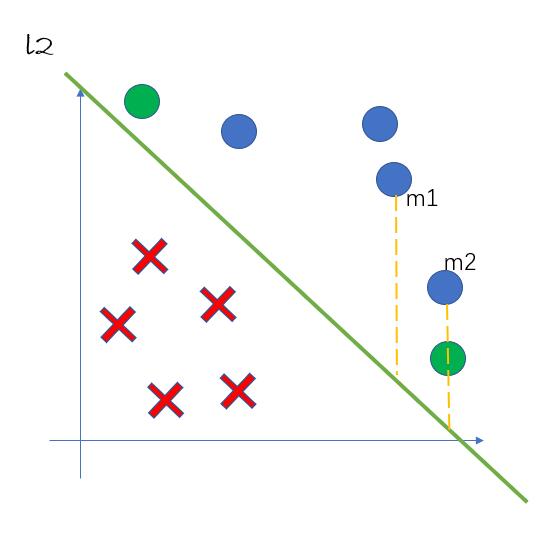
我们回到最开始的二分类问题,如pic3所示。
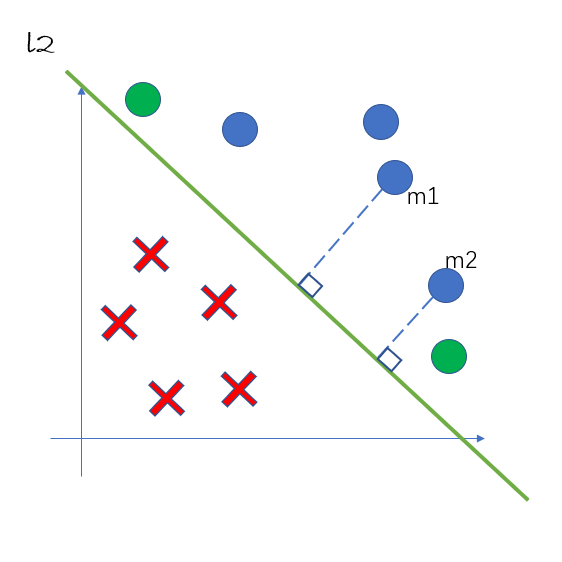
假设我们用直线 \(l_2\) 对样例进行划分,图中的横轴表示样例的第一个属性\(x^{(1)}\) ,纵轴表示样例的第二个属性 \(x^{(2)}\)。图中的点 \(m_1(x_1^{(1)}, x_1^{(2)})\) 和 \(m_2(x_2^{(1)}, x_2^{(2)})\) 都被划分为正类。一般来说,一个点距离超平面的远近可以表示分类预测确信程度,距离超平面越远的点确信程度越高,这个从直观上也比较容易理解。
假设图中 \(l_2\) 的方程确定为 \(w_1x^{(1)} + w_2x^{(2)} + b = 0\) ,通过点到直线的距离公式\(d = \frac{|w_1x^{(1)} + w_2x^{(2)} + b|}{\sqrt{w_1^2 + w_2^2}}\) 我们可以求得 \(m_1\) 和 \(m_2\) 到超平面的距离,以此来评判这些点分类的确信程度。这里的 \(d\) 就被我们称为几何间隔。
但如果我们仅仅想比较点 \(m_1\) 和 \(m_2\) 确信程度的大小,我们可以仅用距离公式的分子:\(d' = |w_1x^{(1)} + w_2x^{(2)} + b|\) 进行比较,因为同一条直线分类的点的分母都是相同的。这里的 \(d'\) 我们称为函数间隔。 \(d'\) 在图中的几何意义表示如下图所示:
一般来说,在超平面 \(w·x+b=0\) 确定的情况下,\(|w·x+b|\) 能够相对地表示点\(x\)距离超平面的远近,而 \(w·x+b\) 的符号与类标记 \(y\) 的符号是否一致能够表示分类是否正确。(在这里 \(y\) 表示样本的标签)所以可以用\(\widehat{\gamma_i} = y_i(w·x_i+b)\) 来表示点 \(m_i\) 分类的正确性及确信度,这就是样本的函数间隔的概念。
定义超平面 \((w, b)\) 关于训练数据集 \(T\) 的函数间隔为超平面\((w, b)\) 关于 \(T\) 中所有样本点\((x_i, y_i)\) 的函数间隔的最小值,即:
函数间隔可以表示分类预测的正确性和及确信度。但是选择分离超平面时,只有函数间隔还不够。因为只要成比例地改变\(w\)和\(b\),例如将它们改为\(2w\)和\(2b\),超平面并没有改变,但函数的间隔却变为原来的两倍。这一事实启示我们,可以对分离超平面的法向量\(w\)加某些约束,如规范化,\(||w||=1\),使得间隔是确定的。这是函数间隔成为几何间隔(geometric margin)。
定义(几何间隔)
对于给定的训练数据集\(T\)和超平面\((w, b)\) ,定义超平面\((w,b)\) 关于样本点\((x_i, y_i)\) 的几何间隔为
定义超平面\((w,b)\) 关于训练数据集\(T\) 的几何间隔为超平面\((w, b)\) 关于 \(T\) 中所有样本点\((x_i, y_i)\)的几何间隔最小值,即:
拉格朗日对偶性
首先举例直观理解,求解 \(min_xmax_{\alpha, \beta} L(x, \alpha, \beta)\) 和求解 \(max_{\alpha, \beta}min_x L(x, \alpha, \beta)\) 是对偶问题。前者是极小极大问题,后者是极大极小问题。
在约束优化问题中,常常利用拉格朗日对偶性(Lagrange duality)将原始问题转换为对偶问题,通过对偶问题而得到原始问题的解。该方法应用在许多统计学习方法中,例如,最大熵模型与支持向量机。这里简要叙述拉格朗日对偶性的主要概念和结果。
原始问题
假设\(f(x)\), \(c_i(x)\), \(h_j(x)\) 是定义在 \(R^n\) 的连续可微函数。考虑约束最优化问题:
称此最优化问题为原始最优化问题或原始问题。
首先引进广义拉格朗日函数(generalized Lagrange function)
这里,\(x=(x^{(1)}, x^{(2)}, ..., x^{(3)})^T \in R^n\) ,\(\alpha_i, \beta_j\) 是拉格朗日乘子,\(\alpha \geq 0\)。考虑 \(x\) 的函数:
这里,下标 \(P\) 表示原始问题。
假设给定某个\(x\)。如果 \(x\) 违反原始问题的约束条件,即存在某个 \(i\) 使得 \(c_i(x) > 0\) 或者存在某个 \(j\) 使得 \(h_j(x) \neq 0\),那么就有
因为若某个 \(i\) 使约束 \(c_i(x) > 0\) ,则可令 $\alpha_i \rightarrow + \infty $ ,若某个 \(j\) 使 \(h_j(x) \neq 0\),则可令 \(\beta_j\) 使 \(\beta_jh_j(x) \rightarrow + \infty\) ,而将其余各 \(\alpha_i\), \(\beta_j\) 均取为0.
相反地,如果 \(x\) 满足约束条件\((C.2)\) 和\((C.3)\) ,此时 \(\theta_P(x)=f(x)\).
所以,如果考虑极小化问题
\(min_x max_{\alpha, \beta:\alpha_i \geq 0} L(x, \alpha, \beta)\) 称为广义拉格朗日函数的极小极大问题。
为了方便,定义原始问题的最优值
对偶问题
再考虑极大化 \(\theta_D(x) = min_{x} L(x, \alpha, \beta)\) ,即
问题 \(max_{\alpha, \beta:\alpha_i \geq 0}min_{x} L(x, \alpha, \beta)\) 称为广义拉格朗日函数的极大极小问题。
可以将广义拉格朗日定理函数的极大极小问题表示为约束最优化问题:
称为原始问题的对偶问题,定义对偶问题的最优值:
原始问题和对偶问题的关系
这里只给出了定理,证明略去。
定理C.1
若原始问题和对偶问题都有最优值,则
推论C.1
设 \(x^*\) 和 \(\alpha^*\) , \(\beta^*\) 分别是原始问题和对偶问题的可行解,并且 \(d^* = p^*\) ,则 \(x^*\) 和 \(\alpha^*, \beta^*\) 分别是原始问题和对偶问题的最优解。
定理C.2
假设函数 \(f(x)\) 和 \(c_i(x)\) 是凸函数,\(h_j(x)\) 是仿射函数;并且假设不等式约束\(c_i(x)\) 是严格可行的,即存在 \(x\) ,对所有\(i\)有\(c_i(x) <0\),则存在 $x^\ast , \alpha^\ast , \beta^\ast $ ,使 \(x^\ast\) 是原始问题的解,\(\alpha^\ast\) , \(\beta^\ast\) 是对偶问题的解,并且
定理C.3
假设函数 \(f(x)\) 和 \(c_i(x)\) 是凸函数,\(h_j(x)\) 是仿射函数;并且假设不等式约束\(c_i(x)\) 是严格可行的,则 $ x^\ast $ 和 \(\alpha^\ast, \beta^\ast\) 分别是原始问题和对偶问题的解的充分必要条件是 \(x^\ast, \alpha^\ast, \beta^\ast\) 满足下面的 Karush-Kuhn-Trucker(KKT) 条件:
特别指出,式\((C.24)\) 称为 KKT 的对偶互补条件。由此条件可知:若 \(\alpha_i^* >0\) , 则 \(c_i(x^*)=0\)。
简单的总结一下这一小节:在某些条件下,原始问题和对偶问题的解相同,我们可以通过求解对偶问题的解来解决原问题。
核技巧
核技巧我们可以通过一张图来理解:
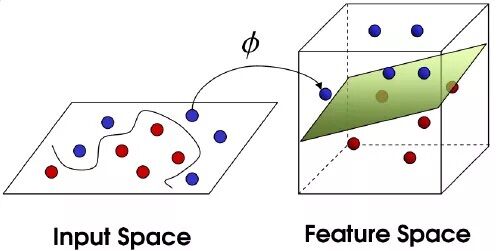
核函数是二元函数,输入是映射之前的两个向量,其输出等价于两个向量映射之后的内积。
下面这个链接里有关于核函数更详细的描述:
支持向量机数学推导
关于支持向量机的推导,重点还是在线性可分支持向量机这里。在明白了线性可分支持向量机的推导之后,线性支持向量机仅仅是在此基础上加了一个软间隔,非线性支持向量机是加上了核技巧。
线性可分支持向量机
支持向量机学习的基本想法是求解能够正确划分数据集并且几何间隔最大的分离超平面。这里的间隔最大化又称硬间隔最大化(与后面讨论的软间隔最大化相对应)。
对训练数据集找到几何间隔最大的超平面意味着以充分大的确信度对训练数据进行分类。也就是说,不仅将正负实例点分开,而且对最难分的实例点(离超平面最近的点)也有足够大的确信度将它们分开。这样的超平面应该对未知的新实例有很好的分类预测能力。
最大间隔算法
我们的目标是求解一个几何间隔最大的分离超平面,可以表示为下面的约束最优化问题:
考虑到几何间隔和函数间隔的关系(\(\gamma\) 表示几何间隔,\(\widehat{\gamma}\) 表示函数间隔),可以将这个问题改写为:
函数间隔\(\widehat{\gamma}\) 的取值并不影响最优化问题的解。事实上,假设将\(w\) 和 \(b\) 按比例改编为 \(\lambda w\) 和 \(\lambda b\) ,这时函数间隔成为 \(\lambda \widehat{\gamma}\) ,函数间隔的这一改变对等式约束没有影响,对目标函数的优化也没有影响。
这样,我们可以取\(\widehat{\gamma} =1\) ,带入到上面的式子,同时我们注意到最大化\(\frac{1}{||w||}\) 和最小化 \(\frac{1}{2}||w||^2\) 是等价的,于是约束规划问题可以转换成如下的形式:
\(min_{w,b} \frac{1}{2}||w||^2 \tag {1.3}\)
综上,我们得到了线性可分的支持向量机算法——最大间隔法,在后文中我们会对这个算法进行求解。
算法(线性可分支持向量机学习算法):
- 输入:线性可分训练数据集 \(T=\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\}\),其中,\(x_i \in X =R^n,y_i \in Y ={-1, +1},i=1,2,...,N\);
- 输出:最大间隔分离超平面和分类决策函数
(1) 构造并求解约束最优化问题:
求得最优解\(w^*,b^*\)。
(2) 由此得到分类超平面啊:
分类决策函数


 浙公网安备 33010602011771号
浙公网安备 33010602011771号