何为内存重排序?
前言
对于我们所编写的源代码最终以指令形式而顺序执行,程序只是处理器自上而下执行的文本文件中列出的操作列表,其实这是错误的理解,计算机能够根据需要更改某些低级操作的顺序,尤其是在读取和写入内存时,出于性能原因,会进行内存重排序,内存重排序是一种利用指令来进行对应操作,通过这种操作极大地提高了程序的速度,但是,另一方面,它可能对无锁多线程造成严重破坏性,本节我们来分析何为重排序。
何为重排序
程序被加载到主内存中以便执行,CPU的任务是运行存储在其中的指令,并在必要时读取和写入数据,那么具体CPU具体是如何操作的呢?获取指令、解码从主存储器中加载所有所需数据的指令、执行指令、将生成的结果写回并存储到主内存中。现代CPU能够每纳秒执行十条指令,但是需要数十纳秒才能从主内存中获取一些数据,与处理器相比,这种类型的内存变得非常慢,为了减少加载和存储操作中的延迟,因此操作系统为CPU配备了一个很小但又非常快的特殊内存块,称为缓存,所以CPU将使用寄存器-缓存,高速缓存是处理器存储其最常使用的数据的地方,以避免与主内存的缓慢交互,当处理器需要读取或写入主内存时,它首先检查该数据的副本在其自己的缓存中是否可用,如果是这样,则处理器直接读取或写入高速缓存,而不必等待较慢的主内存响应,现代的CPU由多个内核组成—执行实际计算的组件,每个内核都有自己的缓存块,该缓存块又连接到主内存,如下图所示:
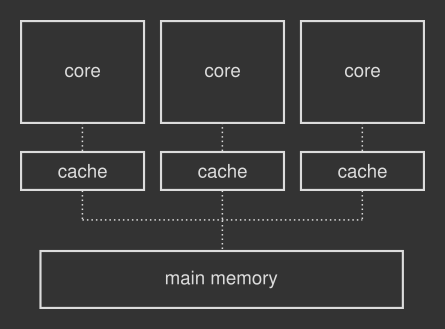
具体地说,解码模块可以具有一个派遣队列,在该队列中,提取的指令将保留,直到其请求的数据从主内存加载到缓存中或它们的从属指令完成为止,当一些指令正在等待(或停顿)时,就绪的指令会同时解码并下推到管道中,如果旧数据尚未在高速缓存中,则回写模块会将存储请求放入存储缓冲区中(高速缓存控制器按高速缓存行存储和加载数据,每条高速缓存行通常大于单个内存访问),并开始处理下一条独立指令。在将旧数据放入缓存后,或者如果它已经在缓存中,指令将使用新结果覆盖缓存,最终,新数据将最终根据不同的策略异步刷新到主内存(例如,当必须从高速缓存中为新的高速缓存行或与其他数据一起以批处理方式处理数据时),总而言之,通过加入缓存使计算机运行速度更快, 或者说它可以使处理器始终保持忙碌和高效的状态,从而帮助处理器因等待主内存响应避免浪费不必要的时间。
class ReadWriteDemo { int A = 0; boolean B = false; //CPU1 (thread1) runs this method void writer() { A = 10; B = true; } //CPU2 (thread2) runs this method void reader() { while (!B) continue; System.out.println(A == 10); } }
编写上述代码后,我们会假设write方法将在reader方法执行之前完成,在理想情况下这种假设正确无疑,但是,如果使用CPU寄存器的缓存和缓冲,这种假设将可能是错误的,例如,如果字段B已经在高速缓存中,而A不在,则B可以早于A存入主内存,即使A和B都在高速缓存中,B仍有可能早于A存入主内存或者A从主内存中先加载到B之前或者A在B存储前加载之前等类似多种可能性结果,简而言之,将语句在原始代码中的排序方式称为程序顺序,单个内存引用(加载或存储)完成的顺序称为执行顺序,由于CPU高速缓存,缓冲区和推测性执行在指令完成时间上增加了太多的异步性,因此执行顺序不一定与其程序顺序相同,这就是CPU中执行重排序的方式。如果程序是单线程或者方法writer中的字段A和B仅由一个线程访问,我们实际上并不用关心重排序,因为方法writer中的两个存储区是独立的,即使两个存储被重排序。但是,如果程序为多线程,那么可能需要考虑执行顺序,例如,CPU1执行方法writer,而CPU2执行方法reader,由于线程使用共享的主内存进行通信,并且由于CPU缓存一致性协议,缓存对访问是透明的,因此当从内存中加载数据时,如果从未从任何CPU加载过数据,则从主内存中获取,如果该CPU拥有数据,则为来自另一个CPU的高速缓存,如果拥有数据,则为来自其自身的高速缓存,如果CPU1无序执行方法writer,则上述打印出false,即使CPU1按照程序顺序执行了方法writer,打印结果仍有可能为false,因为CPU2可以在执行while语句时之前执行打印结果,因为从逻辑上讲,在完成while语句之后才应该打印结果(这称为控制依赖),但是,CPU2可以自由地先推测性地执行打印结果,一般来讲,当CPU看到诸如if或while语句之类的分支时,直到该分支指令完成之前,它才知道在哪里获取下一条指令,但是,如果它等待分支指令而又找不到足够的独立指令,则会降低CPU性能,因此,CPU1可以根据其预测推测性地执行打印结果,稍后可以批准其预测路径正确时,它将提交执行,在reader方法情况下,这意味着在打印结果之后,CPU1在while语句中找到了B == true,由于CPU并不知道我们关心A和B的执行顺序,因此必须使用所谓的内存屏障来告知它们顺序必须使用同步构造以强制执行的排序语义。如果两个CPU都引用相同的内存位置,说明它们具有数据依赖性,则没有一个CPU将对存储的给定操作进行重排序,否则将违反程序语义,基于以上分析,我们得出结论:单线程程序在顺序化语义as-if-serial下运行,重排序的效果仅对多线程程序可见(或者一个线程中的重新排序仅对其他线程可见/对其他线程很重要),当CPU本质上执行给不了我们实际想要的排序语义时,程序必须使用同步机制。
指令调度说明
只要编译器不违反程序语义(这里的编译指代的是JIT编译器)就可以自由地根据其优化对代码进行物理或逻辑重排序,现代编译器具有许多强大的代码转换,如下:
public class Main { public static void main(String[] args) { int A = 10; int B = A + 10; int C = 20; } }
假设编译器通过复杂的分析发现A不在缓存中,而C在缓存中,因此,A=10将触发多周期的数据加载,而C=20则可以在单个周期内完成,编译器可以直接跳过对A=10和B=A+10进行赋值操作而执行C=20,以将停顿减少1,如果编译器可以找到更多独立的指令,则可以通过减少更多的停顿来进行相同的重排序。由上述我们知道在单核计算机上,硬件内存的重排序并不是问题,线程是操作系统控制的软件结构,CPU仅接收连续的存储指令流,它们仍然可以重排序,但是要遵循一个基本规则:给定内核的内存访问在该内核中似乎是在程序中编写的,因此,可能会发生内存重排序,但前提是它不会破坏最终结果。接下来我们再来看一个例子(源于java并发实战)
public class UnsafeLazyInitialization { private static Resource resource; public static Resource getInstance() { if (resource == null) resource = new Resource(); return resource; } }
如上使用先检查后操作模式实例化Resource,不用多讲,很有可能两个线程可以在该方法中同时抵达,都将resource视为null并初始化变量。这里还涉及到我们上一节所讲解的部分初始化对象问题,导致对象无法正确安全发布,当我们初始化一个对象具体会进行5步操作:分配内存、创建对象、使用默认值初始化字段(比如int、boolean等)、运行构造函数、将对象的引用分配给变量,但是这里在进行第4步操作之前就运行第5步操作,所以getInstance方法将返回一个非空但不一致的对象(具有未初始化字段)的引用。但是上述方法也很有可能返回null,因为JMM对此允许, 要了解为什么这样做是可行的,我们需要详细分析读写,并评估它们之间是否存在事先发生联系(happens-before),我们将上述代码进行如下重写,以清楚地显示读取和写入:

public class UnsafeLazyInitialization { private static Resource resource; public static Resource getInstance() { Resource temp = resource; if (resource == null) resource = temp = new Resource(); return temp; } }
通过声明一个Resource的临时变量temp,此时在线程1和线程2都为null,接下来将在线程1中为null,而在线程2中不为null,因为它已由线程1初始化,最终线程1返回实例,而线程2返回null。
总结
本节我们详细讲解了重排序的概念以及引入重排序的原因,下一节我们进入到内存模型,感谢您的阅读,我们下节见。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号