

第一次个人编程作业
| 这个作业属于哪个课程 | 课程网站 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 设计论文查重算法、学习使用PSP表格、学习单元测试、尝试JProfiler性能分析、尝试Git管理 |
1.Github
https://github.com/Jaywilde/3119005474
仓库截图
由于git的push大文件出错,现将文件保存在百度网盘
hi,这是我用百度网盘分享的文件~复制这段内容打开「百度网盘」APP即可获取。
链接:https://pan.baidu.com/s/1Y6LSrsisjqtEpBGuXyB82w
提取码:Dzcy
2.PSP表格
PSP是卡耐基梅隆大学(CMU)的专家们针对软件工程师所提出的一套模型:Personal Software Process (PSP, 个人开发流程,或称个体软件过程)。
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 60 |
| Estimate | 估计这个任务需要多少时间 | 20 | 17 |
| Development | 开发 | 90 | 110 |
| Analysis | 需求分析(包括学习新技术) | 60 | 67 |
| Design Spec | 生成设计文档 | 40 | 45 |
| Design Review | 设计复审 | 20 | 23 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 15 | 13 |
| Design | 具体设计 | 90 | 75 |
| Coding | 具体代码 | 600 | 756 |
| Code Review | 代码复审 | 25 | 20 |
| Test | 测试(自我测试,修改代码,提交修改) | 20 | 20 |
| Reporting | 报告 | 15 | 15 |
| Test Repor | 测试报告 | 25 | 25 |
| Size Measurement | 计算工作量 | 20 | 20 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 60 | 45 |
| 合计 | 1140 | 1311 |
3.需求分析
3.1 需求
题目:论文查重
描述如下:
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
原文示例:今天是星期天,天气晴,今天晚上我要去看电影。
抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。
要求输入输出采用文件输入输出,规范如下:
从命令行参数给出:论文原文的文件的绝对路径。
从命令行参数给出:抄袭版论文的文件的绝对路径。
从命令行参数给出:输出的答案文件的绝对路径。
我们提供一份样例,课堂上下发,上传到班级群,使用方法是:orig.txt是原文,其他orig_add.txt等均为抄袭版论文。
注意:答案文件中输出的答案为浮点型,精确到小数点后两位
3.2 流程思路
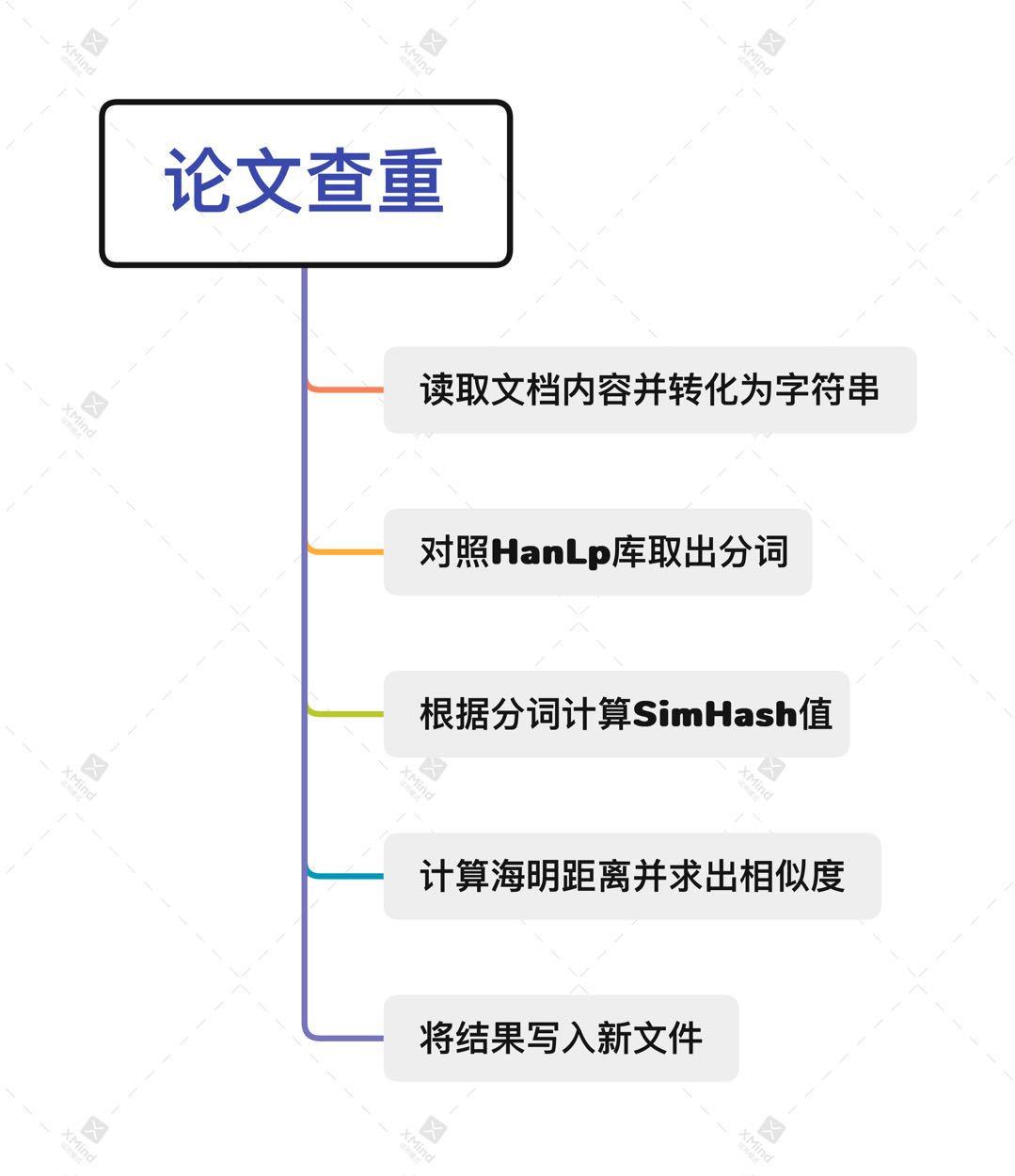
3.3 类说明
- thesis_main: 主函数,写入文件存储路径和工具类的调用
- Hamming:计算海明距离
- ShortStringException:处理文件文字内容过短
- SimHash:计算哈希值
- TxtIO:写入文本内容并转换为字符串
4.模块接口的设计
4.1 Hamming模块
文本相似度比较有很多方法,如余弦夹角算法、欧式距离、Jaccard相似度、最长公共子串、编辑距离等,海明距离是其中之一。
在信息编码中,两个合法代码对应位上编码不同的位数称为码距,又称海明距离。
n位的码字可以用n维空间的超立方体的一个顶点来表示。两个码字之间的海明距离就是超立方体两个顶点之间的一条边,而且是这两个顶点之间的最短距离。
对海明距离的应用,最多的是在海量短文本去重上,性能优,主要方法就是对文本进行向量化,或者说把文本的特征抽取出来映射成编码,然后再对编码进行异或计算出海明距离。
4.2 SimHash模块
-
分词,把需要判断文本分词形成这个文章的特征单词。最后形成去掉噪音词的单词序列并为每个词加上权重,我们假设权重分为5个级别(1~5)。比如:“ 美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人 ” ==> 分词后为 “ 美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)”,括号里是代表单词在整个句子里重要程度,数字越大越重要。
-
hash,通过hash算法把每个词变成hash值,比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。这样我们的字符串就变成了一串串数字,还记得文章开头说过的吗,要把文章变为数字计算才能提高相似度计算性能,现在是降维过程进行时。
-
加权,通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
-
合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。比如 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”, 把每一位进行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”。这里作为示例只算了两个单词的,真实计算需要把所有单词的序列串累加。
-
降维,把4步算出来的 “9 -9 1 -1 1 9” 变成 0 1 串,形成我们最终的simhash签名。 如果每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 0 1 0 1 1”。
4.3 TxtIO模块
调用 Java.io 包提供的接口读文件和写文件
4.4 thesis_main模块
- 从命令行输入的路径名读取对应的文件,将文件的内容转化为对应的字符串
- 由字符串得出对应的 simHash值
- 由 simHash值求出相似度
- 把相似度写入最后的结果文件中
- 退出程序
5.测试
5.1 test类的实现
@Test
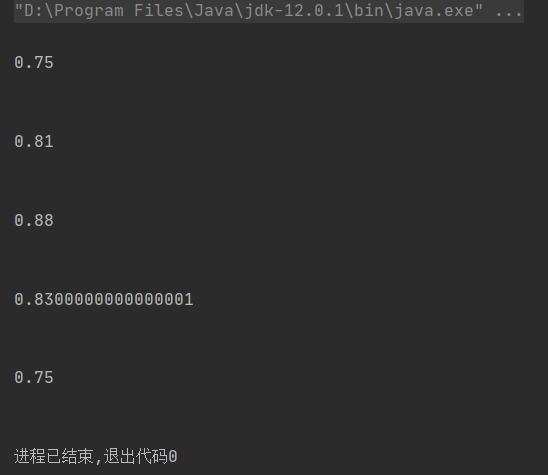
public void Main_test1() {
String str0 = TxtIO.readTxt("E:\\测试文本\\orig.txt");
String str1 = TxtIO.readTxt("E:\\测试文本\\orig_0.8_add.txt");
String simHash0 = SimHash.getSimHash(str0);
String simHash1 = SimHash.getSimHash(str1);
double similarity = Hamming.getSimilarity(simHash0, simHash1);
System.out.println(similarity);
}
@Test
public void Main_test2() {
String str0 = TxtIO.readTxt("E:\\测试文本\\orig.txt");
String str1 = TxtIO.readTxt("E:\\测试文本\\orig_0.8_del.txt");
String simHash0 = SimHash.getSimHash(str0);
String simHash1 = SimHash.getSimHash(str1);
double similarity = Hamming.getSimilarity(simHash0, simHash1);
System.out.println(similarity);
}
@Test
public void Main_test3() {
String str0 = TxtIO.readTxt("E:\\测试文本\\orig.txt");
String str1 = TxtIO.readTxt("E:\\测试文本\\orig_0.8_dis_1.txt");
String simHash0 = SimHash.getSimHash(str0);
String simHash1 = SimHash.getSimHash(str1);
double similarity = Hamming.getSimilarity(simHash0, simHash1);
System.out.println(similarity);
}
@Test
public void Main_test4() {
String str0 = TxtIO.readTxt("E:\\测试文本\\orig.txt");
String str1 = TxtIO.readTxt("E:\\测试文本\\orig_0.8_dis_10.txt");
String simHash0 = SimHash.getSimHash(str0);
String simHash1 = SimHash.getSimHash(str1);
double similarity = Hamming.getSimilarity(simHash0, simHash1);
System.out.println(similarity);
}
@Test
public void Main_test5() {
String str0 = TxtIO.readTxt("E:\\测试文本\\orig.txt");
String str1 = TxtIO.readTxt("E:\\测试文本\\orig_0.8_dis_15.txt");
String simHash0 = SimHash.getSimHash(str0);
String simHash1 = SimHash.getSimHash(str1);
double similarity = Hamming.getSimilarity(simHash0, simHash1);
System.out.println(similarity);
}
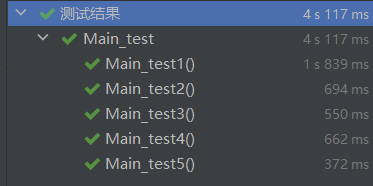
5.2 测试结果
5.3 命令行输入
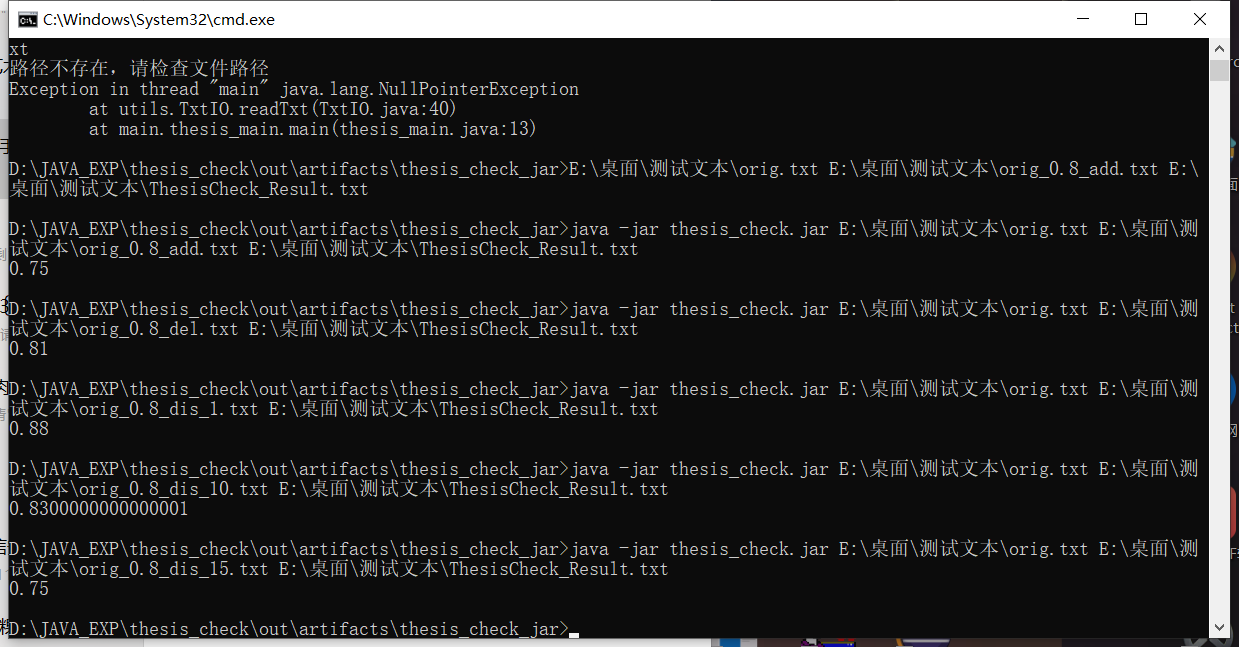
5.4 代码覆盖率
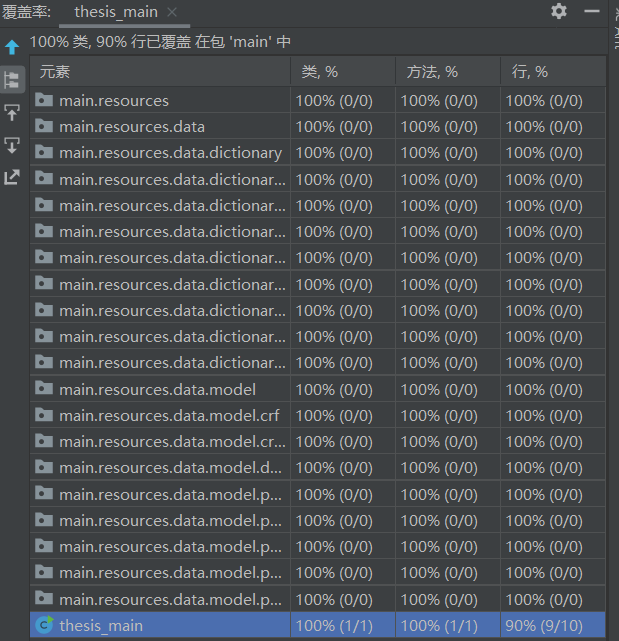
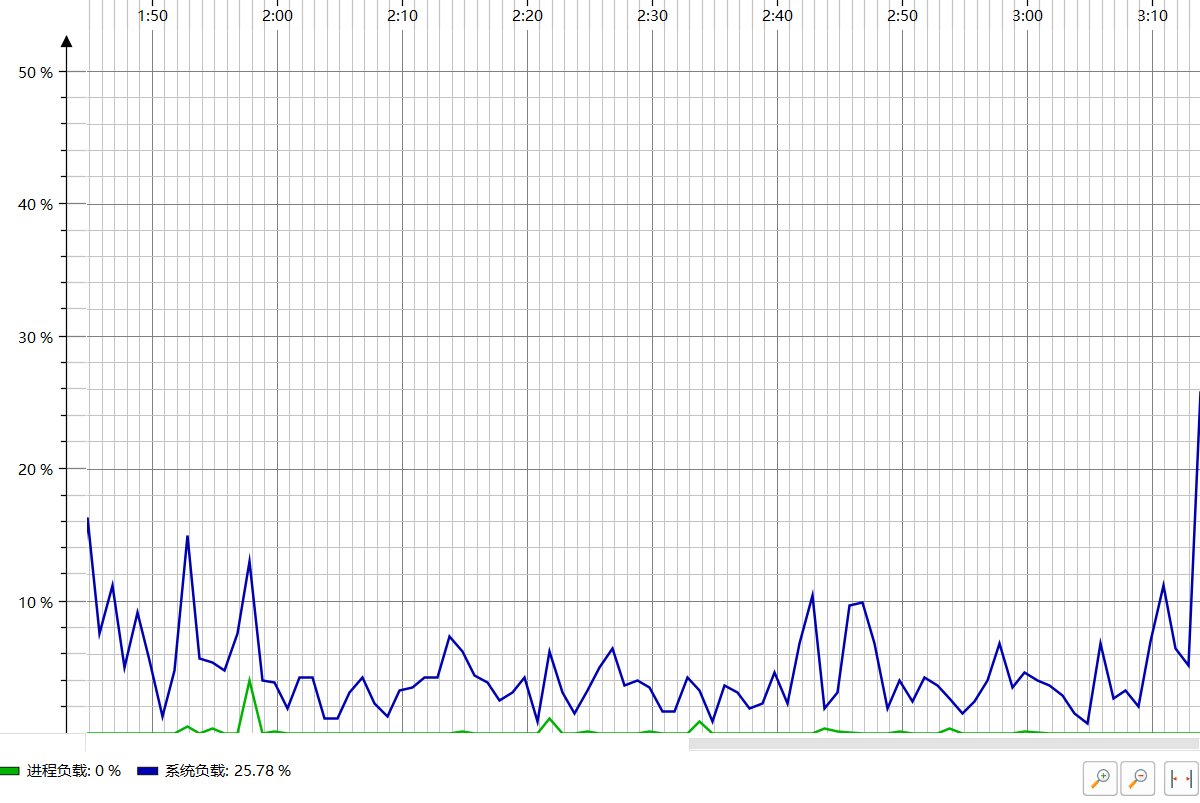
6.计算模块接口部分的性能改进
6.1 CPU
6.2 堆内存
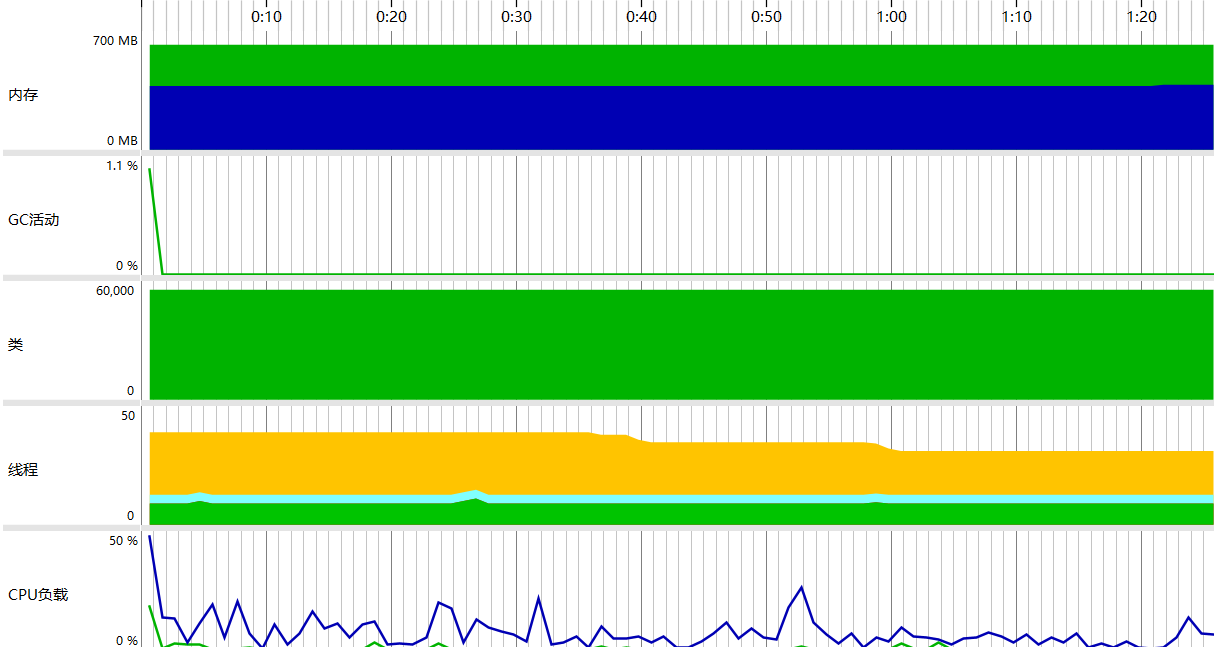
6.3 类占用
7.总结
在本次编程作业中,我发现了我存在有许多问题,导致我在完成作业的过程中十分坎坷。
- 对编程语言的掌握度不够,像是JAVA中的许多函数的用法尚不清晰
- 对软件工程课程中,开发软件所需要的工具,例如Github、Git的使用十分生疏
- IDEA编译器库的配置等操作十分混乱,并且对文件存在的位置、用途十分不明确,思路十分混乱
- 逻辑思维能力较弱,对陌生算法的理解花费了较长时间
- 时间分配不够合理,以导致在最后几天加班加点才能够完成作业
接下来提出几点对未来的展望
- 尽快熟悉与掌握JAVA语言
- 平时锻炼逻辑思维,自行寻找算法书籍阅读思考
- 多尝试使用开发工具,熟悉开发工具的使用方式
- 锻炼时间分配能力,每次作业都要尽早开始
8.文章参考
- https://blog.csdn.net/fjssharpsword/article/details/54600902?utm_medium=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~default-1.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~default-1.no_search_link
- https://blog.csdn.net/weixin_44911685/article/details/108785424
- https://www.cnblogs.com/jiyuqi/p/4845969.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号