python抓取中文网页乱码通用解决方法
注:转载自http://www.cnpythoner.com/
我们经常通过python做采集网页数据的时候,会碰到一些乱码问题,今天给大家分享一个解决网页乱码,尤其是中文网页的通用方法。
首页我们需要安装chardet模块,这个可以通过easy_install 或者pip来安装。
安装完以后我们在控制台上导入模块,如果正常就可以。
比如我们遇到的一些ISO-8859-2也是可以通过下面的方法解决的。
直接上代码吧:
import sys
import chardet
req = urllib2.Request("http://www.163.com/")##这里可以换成http://www.baidu.com,http://www.sohu.com
content = urllib2.urlopen(req).read()
typeEncode = sys.getfilesystemencoding()##系统默认编码
infoencode = chardet.detect(content).get('encoding','utf-8')##通过第3方模块来自动提取网页的编码
html = content.decode(infoencode,'ignore').encode(typeEncode)##先转换成unicode编码,然后转换系统编码输出
print html
通过上面的代码,相信能够解决你采集乱码的问题。
接着开始学习网络爬虫的深入点儿的东东:
以抓取韩寒博客文章目录来加以说明:http://blog.sina.com.cn/s/articlelist_1191258123_0_1.html,下面是截图
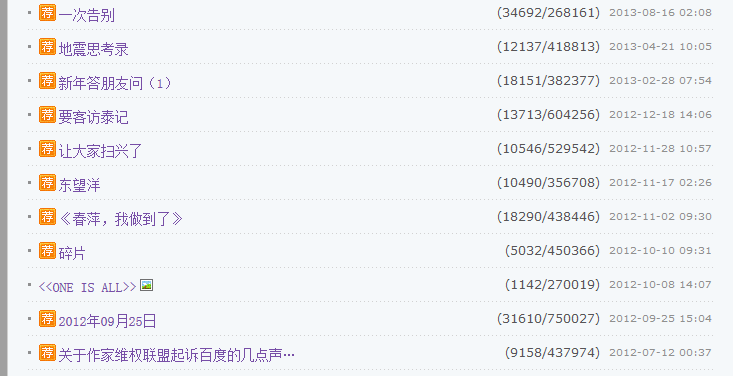
我用的是Chrome浏览器(firefox也行),打开上述网页,鼠标右击,选择审查元素,就会出现下面所示
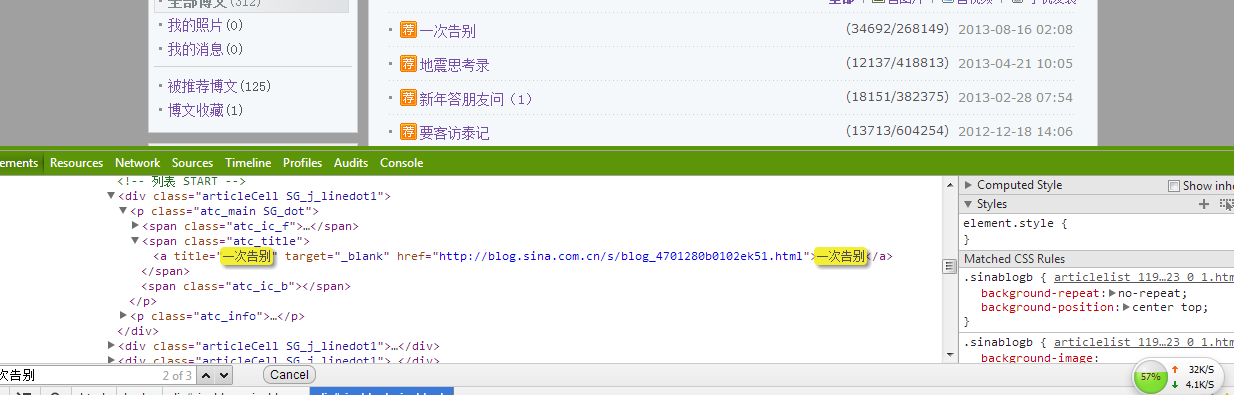
首先我们来实现抓取第一篇文章“一次告别”的page的url
按住ctrl+f就会在上图左下角打开搜索栏,输入”一次告别“,就会自动定位到html源码所在位置,如上高亮显示的地方
接下来我们就是要把对应的url:http://blog.sina.com.cn/s/blog_4701280b0102ek51.html提取出来
详细实现代码如下:


1 #coding:utf-8 2 import urllib 3 str0 = '<a title="一次告别" target="_blank" href="http://blog.sina.com.cn/s/blog_4701280b0102ek51.html">一次告别</a>' 4 title = str0.find(r'<a title') 5 print title 6 href = str0.find(r'href=') 7 print href 8 html = str0.find(r'.html') 9 print html 10 url = str0[href + 6:html + 5] 11 print url 12 content = urllib.urlopen(url).read() 13 #print content 14 filename = url[-26:] 15 print filename 16 open(filename, 'w').write(content)
下面对代码进行解释:
首先利用find函数开始依次匹配查找'<a title','href=','.html',这样就可以找到关键字符所在的索引位置,然后就可以定位到http://blog.sina.com.cn/s/blog_4701280b0102ek51.html的位置[href+6:html+5]
最后利用urllib的相关函数打开并读取网页内容,写到content中
运行程序:
0
40
93
http://blog.sina.com.cn/s/blog_4701280b0102ek51.html
blog_4701280b0102ek51.html
于是在代码所在目录生成html文件blog_4701280b0102ek51.html
至此便抓取到第一篇文章的url及网页内容;上述操作主要学习了以下几个内容:1.分析博客文章列表特征2.提取字符串中的网络连接地址3.下载博文到本地
接下来继续深入:获取博文目录第一页所有文章的链接并将所有文章下载下来
1 #coding:utf-8 2 import urllib 3 import time 4 url = ['']*50 5 con = urllib.urlopen('http://blog.sina.com.cn/s/articlelist_1191258123_0_1.html').read() 6 i = 0 7 title = con.find(r'<a title=') 8 href = con.find(r'href=', title) 9 html = con.find(r'.html', href) 10 11 while title != -1 and href != -1 and html != -1 and i < 50: 12 url[i] = con[href+6:html+5] 13 print url[i] 14 title = con.find(r'<a title=', html) 15 href = con.find(r'href=', title) 16 html = con.find(r'.html', href) 17 i = i + 1 18 else: 19 print "Find end!" 20 j = 0 21 while j < 50: 22 content = urllib.urlopen(url[j]).read() 23 open(r'hanhan/' + url[j][-26:], 'w+').write(content) 24 j = j + 1 25 print 'downloading', url[j] 26 time.sleep(15) 27 else: 28 print 'Download article finish!' 29 #print 'con', con

 浙公网安备 33010602011771号
浙公网安备 33010602011771号