关于Set-List-Map的比较学习
在介绍之前,先来看一下:The Interface and Class Hierarchy Diagram of Java Collections
1. Collection vs Collections
First of all, “Collection” and “Collections” are two different concepts. As you will see from the hierarchy diagram below, “Collection” is a root interface in the Collection hierarchy but “Collections” is a class which provide static methods to manipulate on some Collection types.

2. Class hierarchy of Collection
The following diagram demonstrates class hierarchy of Collection.

3. Class hierarchy of Map
Here is class hierarchy of Map.

4. Summary of classes

1、Set
The HashSet stores elements using a rather complex approach that will be explored in the Containers in Depth chapter—all you need to know at this point is that this technique is the fastest way to retrieve elements, and as a result the storage order can seem nonsensical (often, you only care whether something is a member of the Set, not the order in which it appears). If storage order is important, you can use a TreeSet, which keeps the objects in ascending comparison order, or a LinkedHashSet, which keeps the objects in the order in which they were added.
HashSet is Implemented using a hash table. Elements are not ordered. The add, remove, and containsmethods have constant time complexity O(1).
TreeSet is implemented using a tree structure(red-black tree in algorithm book). The elements in a set are sorted, but the add, remove, and contains methods has time complexity of O(log (n)). It offers several methods to deal with the ordered set like first(), last(), headSet(), tailSet(), etc.
LinkedHashSet is between HashSet and TreeSet. It is implemented as a hash table with a linked list running through it, so it provides the order of insertion. The time complexity of basic methods is O(1).
In brief, if you need a fast set, you should use HashSet; if you need a sorted set, then TreeSet should be used; if you need a set that can be store the insertion order, LinkedHashSet should be used.
(1)、HashSet:HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个对象的HashCode()方法返回值也相等——也就是说HashSet会在两个条件都满足的情况下才会判断两个元素相等
但在实际实现时应该注意:如果需要某个类的对象保存到HashSet集合中,重写这个类的equals()方法和HashCode()方法时,应该尽量保证两个对象通过equals()方法比较返回true时,他们的HashCode方法返回值也相等
根据《Effective Java》第九条所说:“Always override hashCodewhen you override equals(覆盖equals总要覆盖hashCode)”;equal objects must have equal hash codes
Set的三个实现类HashSet、TreeSet和EnumSet都是线程不安全的
HashSet Example:
HashSet<Dog> dset = new HashSet<Dog>(); dset.add(new Dog(2)); dset.add(new Dog(1)); dset.add(new Dog(3)); dset.add(new Dog(5)); dset.add(new Dog(4)); Iterator<Dog> iterator = dset.iterator(); while (iterator.hasNext()) { System.out.print(iterator.next() + " "); }
TreeSet Example:
LinkedHashSet Example:
LinkedHashSet<Dog> dset = new LinkedHashSet<Dog>(); dset.add(new Dog(2)); dset.add(new Dog(1)); dset.add(new Dog(3)); dset.add(new Dog(5)); dset.add(new Dog(4)); Iterator<Dog> iterator = dset.iterator(); while (iterator.hasNext()) { System.out.print(iterator.next() + " "); }
Performance Testing:
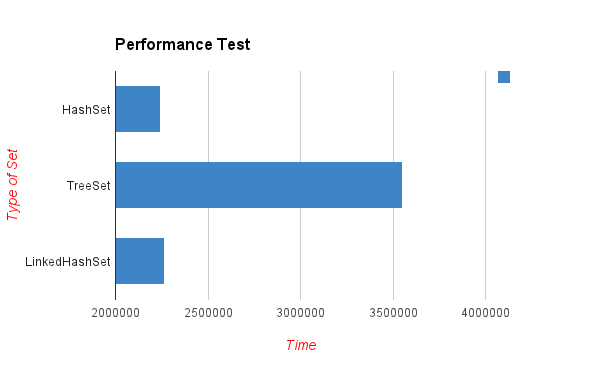
The following method tests the performance of the three class on add() method.
From the output below, we can clearly wee that HashSet is the fastest one.
HashSet: 2244768 TreeSet: 3549314 LinkedHashSet: 2263320
* The test is not precise, but can reflect the basic idea that TreeSet is much slower because it is sorted.
2、List
主要掌握ArrayList和LinkedList:两者的区别不妨引用 http://www.importnew.com/6629.html所述:
LinkedeList和ArrayList都实现了List接口,但是它们的工作原理却不一样。它们之间最主要的区别在于ArrayList是可改变大小的数组,而LinkedList是双向链接串列(doubly LinkedList)。ArrayList更受欢迎,很多场景下ArrayList比LinkedList更为适用。这篇文章中我们将会看看LinkedeList和ArrayList的不同,而且我们试图来看看什么场景下更适宜使用LinkedList,而不用ArrayList。

LinkedList和ArrayList的区别
The real difference is their underlying implementation and their operation complexity.
LinkedList和ArrayList的差别主要来自于Array和LinkedList数据结构的不同。如果你很熟悉Array和LinkedList,你很容易得出下面的结论:
1) 因为Array是基于索引(index)的数据结构,它使用索引在数组中搜索和读取数据是很快的。Array获取数据的时间复杂度是O(1),但是要删除数据却是开销很大的,因为这需要重排数组中的所有数据。
2) 相对于ArrayList,LinkedList插入是更快的。因为LinkedList不像ArrayList一样,不需要改变数组的大小,也不需要在数组装满的时候要将所有的数据重新装入一个新的数组,这是ArrayList最坏的一种情况,时间复杂度是O(n),而LinkedList中插入或删除的时间复杂度仅为O(1)。ArrayList在插入数据时还需要更新索引(除了插入数组的尾部)。
3) 类似于插入数据,删除数据时,LinkedList也优于ArrayList。
4) LinkedList需要更多的内存,因为ArrayList的每个索引的位置是实际的数据,而LinkedList中的每个节点中存储的是实际的数据和前后节点的位置。
什么场景下更适宜使用LinkedList,而不用ArrayList
我前面已经提到,很多场景下ArrayList更受欢迎,但是还有些情况下LinkedList更为合适。譬如:
1) 你的应用不会随机访问数据。因为如果你需要LinkedList中的第n个元素的时候,你需要从第一个元素顺序数到第n个数据,然后读取数据。
2) 你的应用更多的插入和删除元素,更少的读取数据。因为插入和删除元素不涉及重排数据,所以它要比ArrayList要快。
以上就是关于ArrayList和LinkedList的差别。你需要一个不同步的基于索引的数据访问时,请尽量使用ArrayList。ArrayList很快,也很容易使用。但是要记得要给定一个合适的初始大小,尽可能的减少更改数组的大小。
Note: The default initial capacity of an ArrayList is pretty small. It is a good habit to construct the ArrayList with a higher initial capacity. This can avoid the resizing cost.


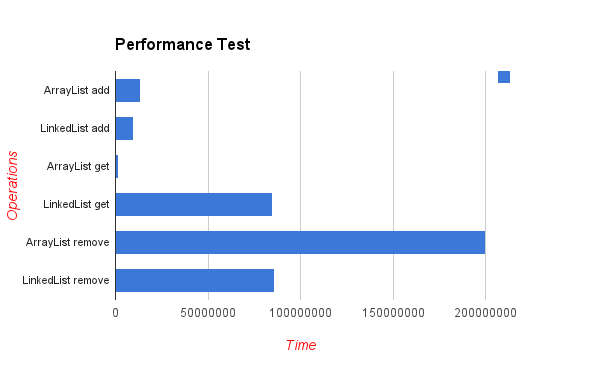
1 ArrayList<Integer> arrayList = new ArrayList<Integer>(); 2 LinkedList<Integer> linkedList = new LinkedList<Integer>(); 3 4 // ArrayList add 5 long startTime = System.nanoTime(); 6 7 for (int i = 0; i < 100000; i++) { 8 arrayList.add(i); 9 } 10 long endTime = System.nanoTime(); 11 long duration = endTime - startTime; 12 System.out.println("ArrayList add: " + duration); 13 14 // LinkedList add 15 startTime = System.nanoTime(); 16 17 for (int i = 0; i < 100000; i++) { 18 linkedList.add(i); 19 } 20 endTime = System.nanoTime(); 21 duration = endTime - startTime; 22 System.out.println("LinkedList add: " + duration); 23 24 // ArrayList get 25 startTime = System.nanoTime(); 26 27 for (int i = 0; i < 10000; i++) { 28 arrayList.get(i); 29 } 30 endTime = System.nanoTime(); 31 duration = endTime - startTime; 32 System.out.println("ArrayList get: " + duration); 33 34 // LinkedList get 35 startTime = System.nanoTime(); 36 37 for (int i = 0; i < 10000; i++) { 38 linkedList.get(i); 39 } 40 endTime = System.nanoTime(); 41 duration = endTime - startTime; 42 System.out.println("LinkedList get: " + duration); 43 44 45 46 // ArrayList remove 47 startTime = System.nanoTime(); 48 49 for (int i = 9999; i >=0; i--) { 50 arrayList.remove(i); 51 } 52 endTime = System.nanoTime(); 53 duration = endTime - startTime; 54 System.out.println("ArrayList remove: " + duration); 55 56 57 58 // LinkedList remove 59 startTime = System.nanoTime(); 60 61 for (int i = 9999; i >=0; i--) { 62 linkedList.remove(i); 63 } 64 endTime = System.nanoTime(); 65 duration = endTime - startTime; 66 System.out.println("LinkedList remove: " + duration);
ArrayList add: 13265642 LinkedList add: 9550057 ArrayList get: 1543352 LinkedList get: 85085551 ArrayList remove: 199961301 LinkedList remove: 85768810
In brief, LinkedList should be preferred if:
- there are no large number of random access of element
- there are a large number of add/remove operations
Vector is almost identical to ArrayList, and the difference is that Vector is synchronized. Because of this, it has an overhead than ArrayList. Normally, most Java programmers use ArrayList instead of Vector because they can synchronize explicitly by themselves.
3、Map
所有的Map实现类都实现了toString()方法
(1)、关于HashMap和Hashtable实现类
Hashtable是一个线程安全的实现类,而HashMap是一个线程不安全的实现类,故而性能要好一些;如果有多条线程访问同一个Map对象时,则采用Hashtable实现类会较好
Hashtable使不允许用NULL作为key或者value;HashMap可以
注:和vector类似尽量少用Hashtable
重难点理解:HashMap的实现原理(转载自:http://www.cnblogs.com/ktgu/p/3529137.html)
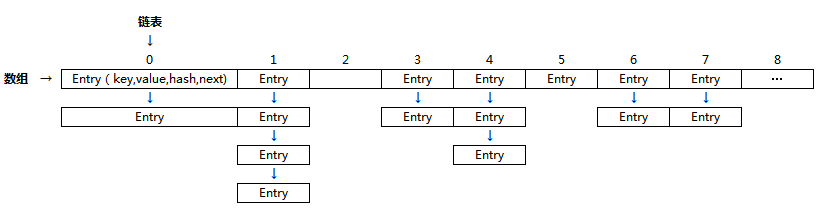
HashMap内部数据结构:
面试的时候经常会遇见诸如:“java中的HashMap是怎么工作的”,“HashMap的get和put内部的工作原理”这样的问题。本文将用一个简单的例子来解释下HashMap内部的工作原理。首先我们从一个例子开始,而不仅仅是从理论上,这样,有助于更好地理解,然后,我们来看下get和put到底是怎样工作的。
我们来看个非常简单的例子。有一个”国家”(Country)类,我们将要用Country对象作为key,它的首都的名字(String类型)作为value。下面的例子有助于我们理解key-value对在HashMap中是如何存储的。

/**
* Applies a supplemental hash function to a given hashCode, which
* defends against poor quality hash functions. This is critical
* because HashMap uses power-of-two length hash tables, that
* otherwise encounter collisions for hashCodes that do not differ
* in lower bits. Note: Null keys always map to hash 0, thus index 0.
*/
static int hash( int h ) {// This function ensures that hashCodes that differ only by // constant multiples at each bit position have a bounded // number of collisions (approximately 8 at default load factor). h ^= (h >>> 20) ^ ( h >>> 12) ; return h ^ (h >>> 7 ) ^ (h >>> 4); }
说明:该hash算法的内部实现乍一看的确很晦涩难懂。参数值h是key.hashCode(),很明显,该方法的意图就是根据key.hasCode()的值进行重新计算。为什么要这么做呢?因为HashMap要求key的hashCode值分布越均匀性能就越好(见上图,若hash函数计算出的hash值越均匀,链表的长度也就越均衡,就不会造成有的链表长度很短,而有的链表长度特别长的情况,我们知道,链表长度越长,检索效率就越慢)。而put到HashMap作为key的对象的hashCode可能五花八门,有的对象的hashCode可能还进行过重写,这可能导致put到HashMap中的key的hashCode值分布可能会不均衡,所以HashMap就利用这样一个算法对hashCode进行重新计算,以期望得到更加分布均衡的hashCode值。
为什么这个算法能够提供更加均衡的hashCode值?
对于下面这两行代码执行的结果可以采用更为直观的代码分离开来观察:
h ^= (h >>> 20) ^ ( h >>> 12) ;
return h ^ (h >>> 7 ) ^ (h >>> 4);
public static void main (String[] args )
{
int h =0xffffffff;
int h1 = h >>>20;
int h2 = h >>>12;
int h3 = h1 ^ h2;
int h4 = h ^ h3;
int h5 = h4 >>>7;
int h6 = h4 >>>4;
int h7 = h5 ^ h6;
int h8 = h4 ^ h7;
printBin ( h );
printBin ( h1 );
printBin ( h2 );
printBin ( h3 );
printBin ( h4 );
printBin ( h5 );
printBin ( h6 );
printBin ( h7 );
printBin ( h8 );
}
static void printBin (int h )
{
System.out.println (String.format ("%32s",Integer.toBinaryString ( h )).replace (' ','0'));
}Which prints:
11111111111111111111111111111111
00000000000000000000111111111111
00000000000011111111111111111111
00000000000011111111000000000000
11111111111100000000111111111111
00000001111111111110000000011111
00001111111111110000000011111111
00001110000000001110000011100000
11110001111100001110111100011111
经过上述算法实现后从最后得到的二进制01分布可以很明显的看到很均衡 The end result is a smoother distribution of bits through the hash value.1. Country.java
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
package org.arpit.javapostsforlearning;public class Country { String name; long population; public Country(String name, long population) { super(); this.name = name; this.population = population; } public String getName() { return name; } public void setName(String name) { this.name = name; } public long getPopulation() { return population; } public void setPopulation(long population) { this.population = population; } // If length of name in country object is even then return 31(any random number) and if odd then return 95(any random number). // This is not a good practice to generate hashcode as below method but I am doing so to give better and easy understanding of hashmap. @Override public int hashCode() { if(this.name.length()%2==0) return 31; else return 95; } @Override public boolean equals(Object obj) { Country other = (Country) obj; if (name.equalsIgnoreCase((other.name))) return true; return false; }} |
如果想了解更多关于Object对象的hashcode和equals方法的东西,可以参考:http://www.importnew.com/8701.html
2. HashMapStructure.java(main class)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
import java.util.HashMap;import java.util.Iterator; public class HashMapStructure { /** * @author Arpit Mandliya */ public static void main(String[] args) { Country india=new Country("India",1000); Country japan=new Country("Japan",10000); Country france=new Country("France",2000); Country russia=new Country("Russia",20000); HashMap<country,string> countryCapitalMap=new HashMap<country,string>(); countryCapitalMap.put(india,"Delhi"); countryCapitalMap.put(japan,"Tokyo"); countryCapitalMap.put(france,"Paris"); countryCapitalMap.put(russia,"Moscow"); Iterator<country> countryCapitalIter=countryCapitalMap.keySet().iterator();//put debug point at this line while(countryCapitalIter.hasNext()) { Country countryObj=countryCapitalIter.next(); String capital=countryCapitalMap.get(countryObj); System.out.println(countryObj.getName()+"----"+capital); } } } |
现在,在第23行设置一个断点,在项目上右击->调试运行(debug as)->java应用(java application)。程序会停在23行,然后在countryCapitalMap上右击,选择“查看”(watch)。将会看到如下的结构:

从上图可以观察到以下几点:
-
有一个叫做table大小是16的Entry数组。
-
这个table数组存储了Entry类的对象。HashMap类有一个叫做Entry的内部类。这个Entry类包含了key-value作为实例变量。我们来看下Entry类的结构。Entry类的结构:
|
1
2
3
4
5
6
7
8
|
static class Entry implements Map.Entry{ final K key; V value; Entry next; final int hash; ...//More code goes here} ` |
-
每当往hashmap里面存放key-value对的时候,都会为它们实例化一个Entry对象,这个Entry对象就会存储在前面提到的Entry数组table中。现在你一定很想知道,上面创建的Entry对象将会存放在具体哪个位置(在table中的精确位置)。答案就是,根据key的hashcode()方法计算出来的hash值(来决定)。hash值用来计算key在Entry数组的索引。
-
现在,如果你看下上图中数组的索引10,它有一个叫做HashMap$Entry的Entry对象。
-
我们往hashmap放了4个key-value对,但是看上去好像只有2个元素!!!这是因为,如果两个元素有相同的hashcode,它们会被放在同一个索引上。问题出现了,该怎么放呢?原来它是以链表(LinkedList)的形式来存储的(逻辑上)。
上面的country对象的key-value的hash值是如何计算出来的。
`
<code>Japan的Hash值是95,它的长度是奇数。 India的Hash值是95,它的长度是奇数。 Russia的Hash值是31,它的长度是偶数。 France,它的长度是偶数。 </code>
`
下图会清晰的从概念上解释下链表。

所以,现在假如你已经很好地了解了hashmap的结构,让我们看下put和get方法。
Put :
让我们看下put方法的实现:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
/** * Associates the specified value with the specified key in this map. If the * map previously contained a mapping for the key, the old value is * replaced. * * @param key * key with which the specified value is to be associated * @param value * value to be associated with the specified key * @return the previous value associated with <tt>key</tt>, or <tt>null</tt> * if there was no mapping for <tt>key</tt>. (A <tt>null</tt> return * can also indicate that the map previously associated * <tt>null</tt> with <tt>key</tt>.) */ public V put(K key, V value) { if (key == null) return putForNullKey(value); int hash = hash(key.hashCode()); int i = indexFor(hash, table.length); for (Entry<k , V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(hash, key, value, i); return null; } |
现在我们一步一步来看下上面的代码。
-
对key做null检查。如果key是null,会被存储到table[0],因为null的hash值总是0。
-
key的hashcode()方法会被调用,然后计算hash值。hash值用来找到存储Entry对象的数组的索引。有时候hash函数可能写的很不好,所以JDK的设计者添加了另一个叫做hash()的方法,它接收刚才计算的hash值作为参数。如果你想了解更多关于hash()函数的东西,可以参考:http://www.iteye.com/topic/709945 以及http://www.cnblogs.com/ktgu/p/3529137.html
-
indexFor(hash,table.length)用来计算在table数组中存储Entry对象的精确的索引。
-
在我们的例子中已经看到,如果两个key有相同的hash值(也叫冲突),他们会以链表的形式来存储。所以,这里我们就迭代链表。
- 如果在刚才计算出来的索引位置没有元素,直接把Entry对象放在那个索引上。
- 如果索引上有元素,然后会进行迭代,一直到Entry->next是null。当前的Entry对象变成链表的下一个节点。
- 如果我们再次放入同样的key会怎样呢?逻辑上,它应该替换老的value。事实上,它确实是这么做的。在迭代的过程中,会调用equals()方法来检查key的相等性(key.equals(k)),如果这个方法返回true,它就会用当前Entry的value来替换之前的value。
Get:
现在我们来看下get方法的实现:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
/** * Returns the value to which the specified key is mapped, or {@code null} * if this map contains no mapping for the key. * * <p> * More formally, if this map contains a mapping from a key {@code k} to a * value {@code v} such that {@code (key==null ? k==null : * key.equals(k))}, then this method returns {@code v}; otherwise it returns * {@code null}. (There can be at most one such mapping.) * * </p><p> * A return value of {@code null} does not <i>necessarily</i> indicate that * the map contains no mapping for the key; it's also possible that the map * explicitly maps the key to {@code null}. The {@link #containsKey * containsKey} operation may be used to distinguish these two cases. * * @see #put(Object, Object) */ public V get(Object key) { if (key == null) return getForNullKey(); int hash = hash(key.hashCode()); for (Entry<k , V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) return e.value; } return null; } |
当你理解了hashmap的put的工作原理,理解get的工作原理就非常简单了。当你传递一个key从hashmap总获取value的时候:
-
对key进行null检查。如果key是null,table[0]这个位置的元素将被返回。
-
key的hashcode()方法被调用,然后计算hash值。
-
indexFor(hash,table.length)用来计算要获取的Entry对象在table数组中的精确的位置,使用刚才计算的hash值。
-
在获取了table数组的索引之后,会迭代链表,调用equals()方法检查key的相等性,如果equals()方法返回true,get方法返回Entry对象的value,否则,返回null。
要牢记以下关键点:
- HashMap有一个叫做Entry的内部类,它用来存储key-value对。
- 上面的Entry对象是存储在一个叫做table的Entry数组中。
- table的索引在逻辑上叫做“桶”(bucket),它存储了链表的第一个元素。
- key的hashcode()方法用来找到Entry对象所在的桶。
- 如果两个key有相同的hash值,他们会被放在table数组的同一个桶里面,这样也就造成了冲突,于是采用链表的形式解决。
- key的equals()方法用来确保key的唯一性。
- value对象的equals()和hashcode()方法根本一点用也没有。
0. Convert a Map to List
// key list List keyList = new ArrayList(map.keySet()); // value list List valueList = new ArrayList(map.valueSet()); // key-value list List entryList = new ArrayList(map.entrySet()); |
for(Entry entry: map.entrySet()) { // get key K key = entry.getKey(); // get value V value = entry.getValue(); }
Iterator can also be used, especially before JDK 1.5
2. Sort a Map on the keys
List list = new ArrayList(map.entrySet()); Collections.sort(list, new Comparator() { @Override public int compare(Entry e1, Entry e2) { return e1.getKey().compareTo(e2.getKey()); } }); |
One implementing class of SortedMap is TreeMap. Its constructor can accept a comparator. The following code shows how to transform a general map to a sorted map.
3. Sort a Map on the values
Putting the map into a list and sorting it works on this case too, but we need to compare Entry.getValue()this time. The code below is almost same as before.
We can still use a sorted map for this question, but only if the values are unique too. Under such condition, you can reverse the key=value pair to value=key. This solution has very strong limitation therefore is not really recommended by me.
4. Initialize a static/immutable Map
When you expect a map to remain constant, it’s a good practice to copy it into an immutable map. Such defensive programming techniques will help you create not only safe for use but also safe for thread maps.
To initialize a static/immutable map, we can use a static initializer (like below). The problem of this code is that, although map is declared as static final, we can still operate it after initialization, likeTest.map.put(3,"three");. Therefore it is not really immutable. To create an immutable map using a static initializer, we need an extra anonymous class and copy it into a unmodifiable map at the last step of initialization. Please see the second piece of code. Then, anUnsupportedOperationException will be thrown if you run Test.map.put(3,"three");.
Guava libraries also support different ways of intilizaing a static and immutable collection. To learn more about the benefits of Guava’s immutable collection utilities, see Immutable Collections Explained in Guava User Guide.
5. Difference between HashMap, TreeMap, and Hashtable
There are three main implementations of Map interface in Java: HashMap, TreeMap, and Hashtable. The most important differences include:
- The order of iteration. HashMap and HashTable make no guarantees as to the order of the map; in particular, they do not guarantee that the order will remain constant over time. But TreeMapwill iterate the whole entries according the “natural ordering” of the keys or by a comparator.
- key-value permission. HashMap allows null key and null values. HashTable does not allow nullkey or null values. If TreeMap uses natural ordering or its comparator does not allow null keys, an exception will be thrown.
- Synchronized. Only HashTable is synchronized, others are not. Therefore, “if a thread-safe implementation is not needed, it is recommended to use HashMap in place of HashTable.”
A more complete comparison is
| HashMap | HashTable | TreeMap ------------------------------------------------------- iteration order | no | no | yes null key-value | yes-yes | yes-yes | no-yes synchronized | no | yes | no time performance | O(1) | O(1) | O(log n) implementation | buckets | buckets | red-black tree
Read more about HashMap vs. TreeMap vs. Hashtable vs. LinkedHashMap.
6. A Map with reverse view/lookup
Sometimes, we need a set of key-key pairs, which means the map’s values are unique as well as keys (one-to-one map). This constraint enables to create an “inverse lookup/view” of a map. So we can lookup a key by its value. Such data structure is called bidirectional map, which unfortunetely is not supported by JDK.
Both Apache Common Collections and Guava provide implementation of bidirectional map, calledBidiMap and BiMap, respectively. Both enforce the restriction that there is a 1:1 relation between keys and values.
7. Shallow copy of a Map
Most implementation of a map in java, if not all, provides a constructor of copy of another map. But the copy procedure is not synchronized. That means when one thread copies a map, another one may modify it structurally. To [prevent accidental unsynchronized copy, one should useCollections.synchronizedMap() in advance.
Another interesting way of shallow copy is by using clone() method. However it is NOT even recommended by the designer of Java collection framework, Josh Bloch. In a conversation about “Copy constructor versus cloning“, he said
I often provide a public clone method on concrete classes because people expect it. … It’s a shame that Cloneable is broken, but it happens. … Cloneable is a weak spot, and I think people should be aware of its limitations.
For this reason, I will not even tell you how to use clone() method to copy a map.
8. Create an empty Map
If the map is immutable, use
Otherwise, use whichever implementation. For example
原文链接: javacodegeeks 翻译: ImportNew.com - miracle1919
译文链接: http://www.importnew.com/10620.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号