基于AI的 OCR - 智能分析24+文档结构元素
随着技术的快速发展和业务需求的不断变化,自动化重复任务已成为现代企业提高效率的关键因素和实现数字化转型的基石。RPA(机器人流程自动化)是应对这一挑战的有效技术。越来越多的公司采用RPA技术来实现内部工作流程的现代化。

客户背景和挑战
某专注于办公软件开发的科技公司,计划打造一款RPA产品和一款智能问答产品,帮助企业实现工作流和业务流程的自动化,满足企业高效、低成本、合规运营的需求,同时提升客户体验。
然而,该公司在RPA和AI问答产品的研发过程中,遇到了非结构化文档处理的难题:人工标注海量文档效率低、容易出错,导致成本增加、开发进度缓慢。他们了解到,ComIDP智能文档处理解决方案曾帮助某数据提供商在5天内处理了300多万份非结构化文档,促使该数据提供商要求实现自动化数据标注,实现智能版式识别和数据解析。
ComIDP为其定制了版式识别参数,并通过AI模型升级OCR技术,使用超过24种标签还原文档的版式和逻辑,确保文档版式的完整性和一致性。该公司在集群环境中部署了ComIDP智能文档解决方案,开发RPA和智能问答产品,大大缩短了开发周期,降低了成本,并实现了产品的快速上市。
客户痛点
非结构化文档内容复杂,格式不一致,数据解析和提取难度极大。版面识别是非结构化文档解析的一大难点,因为每个版面的页面元素繁多,版式和样式各异,内容之间的逻辑关系也各有不同,再加上噪声、倾斜、透视等问题,进一步增加了识别的难度。这就需要具有高度自适应性和智能化的解析技术。然而,由于缺乏先进技术的支撑,该企业只能依靠人工处理,效率低下且不准确,直接影响了RPA和问答系统的有效性。
手动数据标记
该科技企业此前采用人工方式对非结构化数据进行标注,进行文档版式识别,耗时耗力且容易出错。当不同的人处理同一数据集时,标注结果会有所不同,导致数据质量不一致。这不仅增加了后续数据验证的成本和时间,也增加了开发工作的复杂性并延长了项目工期。
海量文档输入
该公司每天处理的文件数量达数十万个,需要高效率、高负荷的处理能力的服务器,但传统的服务器架构无法处理如此大规模的数据输入,导致系统性能缓慢。
自我发展挑战
在竞争激烈的市场中,自主开发虽然可以带来个性化的解决方案,但成本高、耗时长,较长的开发周期使企业难以快速响应市场变化,容易错失市场机会。
客户要求
该公司向我们ComIDP团队详细介绍了其产品的应用场景,并提出了对版面分析智能数据标注的具体要求,旨在实现AI数据自动化的同时,优化数据解析效果。
AI 数据标记的类型
他们需要对文档中的标题、段落、代码块、表格、公式、列表和非文本内容进行注释,以确保非结构化文档的完整性。其中,自然段落的分离和版面的分割尤为重要。

除了这些基本需求之外,每种数据标签类型都有特定的限制,例如独立标题标签、不重叠的段落和块、没有多列块以及没有包含混合数据类型的块。
输出标签
该公司在对非结构化文档进行解析后,要求输出文件为JSON 格式,输出标签有限,包括标题、段落、区块、代码区块、图片区块、表格区块、科学区块、列表区块,以支持后续的关键信息提取和语义分析,提升 RPA 和问答系统的准确率。
ComIDP研发团队根据客户需求定制版面识别参数,不断更新迭代,准确率超过95%,顺利交付客户验收。
ComIDP 解决方案
ComIDP团队与该企业研发团队进行了深入交流,了解企业具体需求和业务目标,确保解决方案定制化、实用化,从数据采集、AI模型训练、模型优化到测试报告,为客户提供专业、灵活、高效的服务。
布局分析模型训练
通过收集财报、论文、报纸、书籍等不同类型的人工数据标注样本,研发团队训练出了适用于各行业的版面分析AI模型,该模型通过24个预定义标签,精准识别并分类页面中的标题、段落、表格、图片等各类元素,识别准确率超过95%。
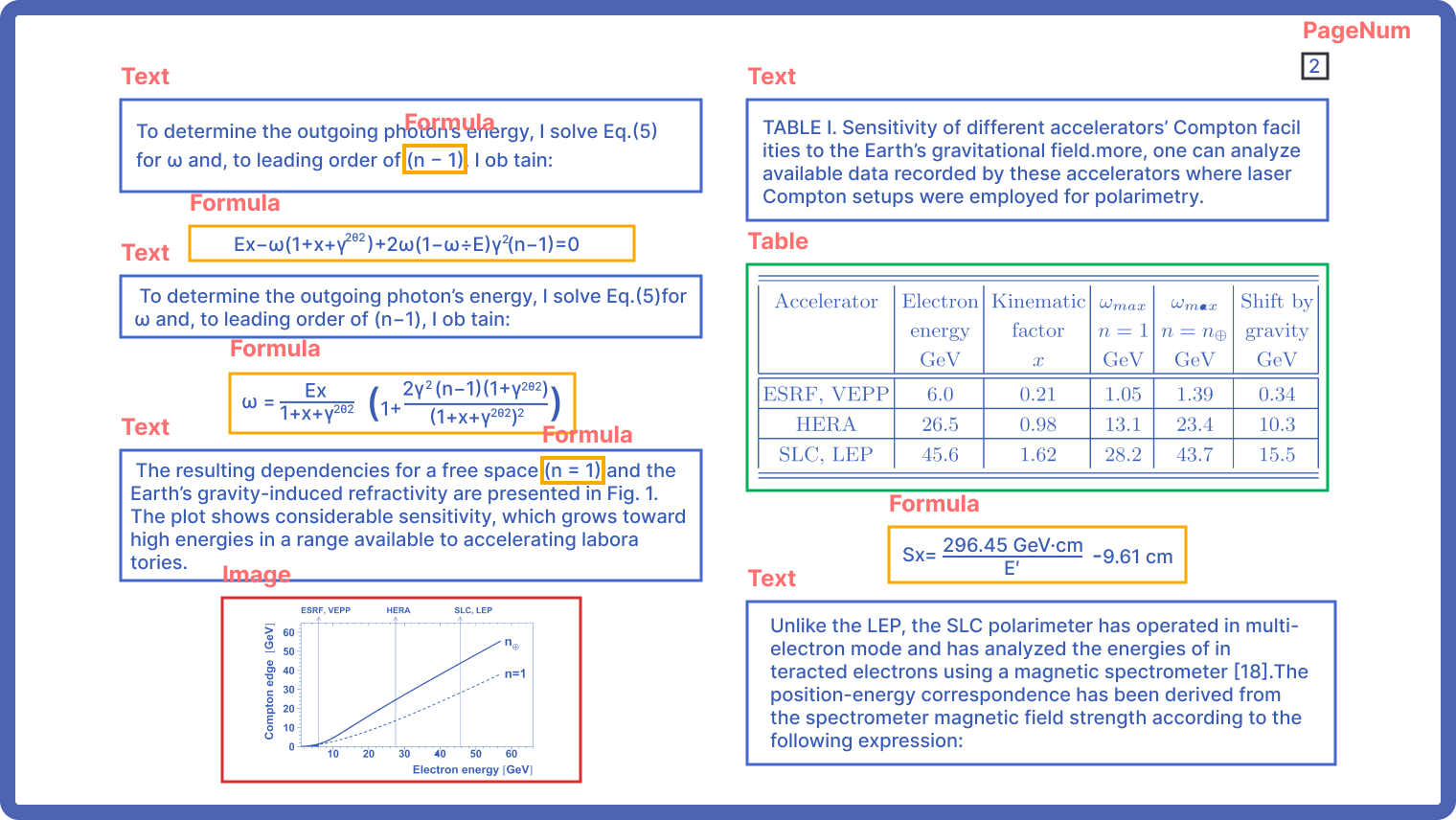
根据该企业数据标注的具体需求,我们进一步优化AI模型,通过精细化标注类型和规则,实现复杂文档内容的精准自动化数据标注。例如,针对技术文档中的代码块、公式块等,设计并调整了专门的识别算法,精准提取并区分这些特有内容。基于AI的ComIDP对文档布局进行几何和逻辑分析,确保99%还原文档布局和阅读逻辑结构,保持布局的完整性和一致性。根据客户要求,标注结果以标准化JSON格式输出,方便二次处理和数据分析。
测试报告验证效果
功能测试
AI 模型训练完成后,我们进行了多轮严苛的测试,验证模型性能,同时使用客户提供的示例作为验证集检测模型准确率,最终生成功能测试报告。报告详细阐述了我们的 AI OCR 模型在自动处理各种文档类型(包括不同格式、大小和语言)以及图章、图表、公式和流程图等元素时的行为。这些结果是模型的关键验收标准。
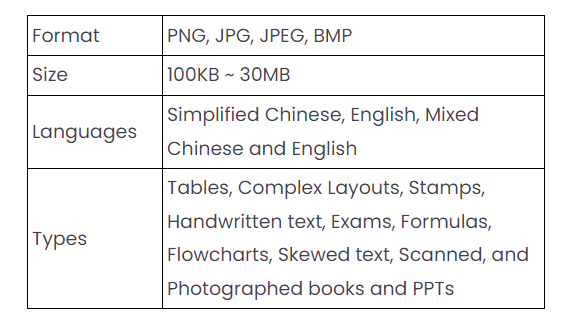
从测试报告中我们选定了ComIDP处理带公式文档的最终效果,结果显示文本和公式识别准确,客户对结果非常满意。

压力测试
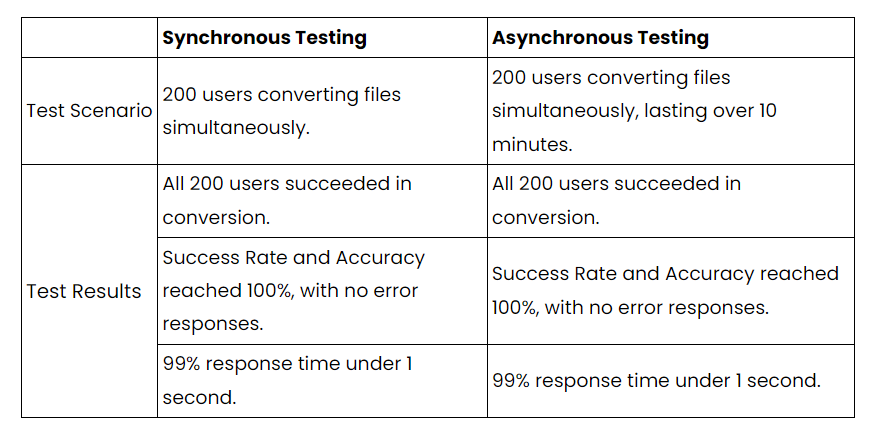
面对该企业每天有十几万份文档输入,我们进行了全面的压力测试,以确保系统能够承受巨大的文档输入压力。我们在同步和异步环境中分别测试了带和不带 OCR 的 PDF 转 Word(网格布局)。我们的压力测试报告表明,ComIDP 在高负载下保持了稳定性、准确性和快速响应,证明了其在高负载任务中的出色性能和可靠性。
GPU&CPU 速度测试
此外,我们还部署了 GPU 来加速文档处理速度。通过比较相同任务的 GPU 和 CPU 效率,我们得到了详细的 OCR GPU&CPU 速度比较报告。
下图展示了 ComIDP 使用 GPU 与 CPU 处理 100 个图像样本的时间消耗。测试表明,在双 GPU 系统的双容器环境中,ComIDP平均每分钟处理多达20,000 张图像。GPU 处理时间比 CPU 快100 倍,在处理大规模文档时具有显著的速度优势,大大缩短了时间并提高了效率。针对客户的实际应用和文档处理需求,我们提供了定制的集群部署解决方案,以确保ComIDP在实际应用中的高效率。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号