JUC Java并发编程 十分详细 java.util.concurrent
文章目录
进程和线程
进程

线程

两者之间的对比

线程的上下文切换
当系统的内存不够的时候,可以关闭一些线程,将内存由其他的线程进行使用,这个时候需要进行线程的切换,存在进程上下文的概念;
并行和并发
并行 parallel
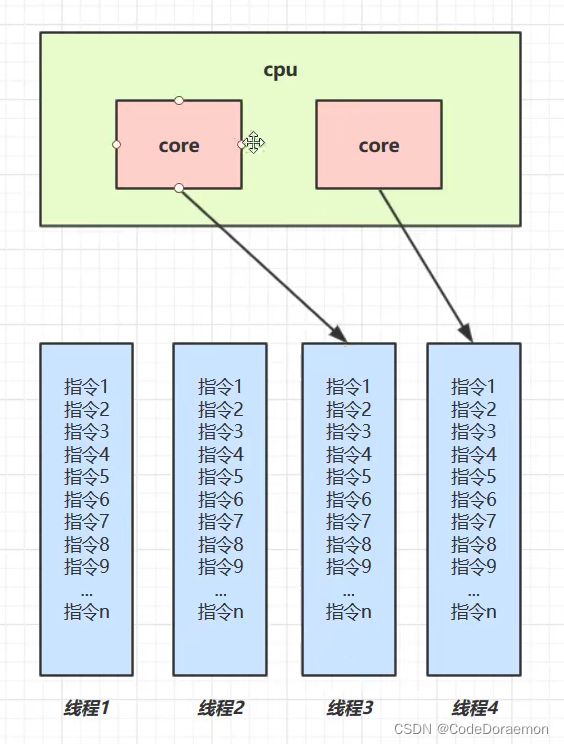
多核 cpu 同时执行多个线程,是真正的并发;
并发 concurrent
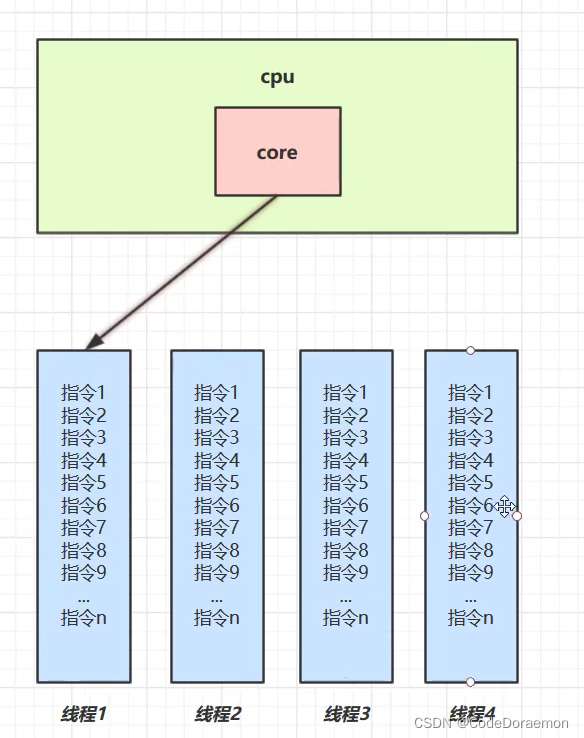
单核 cpu 进行线程的快速切换
操作系统中存在任务调度器,将 cpu 时间片交给不同的线程执行,cpu 在线程之间切换的速度非常快,人是感觉不到的;
微观串行,宏观并行;

举例说明

并行 并发的测试结果

同步 异步
从方法调用的角度来讲
需要等待结果的返回,才能继续运行的是同步
不需要等到结果的返回,就能继续执行操作是异步
同步在多线程的另外含义:多个线程之间同步进行

关于日志文件的配置
pom
下面的两个配置都是需要的
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.10</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
logback.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration
xmlns="http://ch.qos.logback/xml/ns/logback"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://ch.qos.logback/xml/ns/logback logback.xsd">
<!--控制的输出是 控制台进行输出,实际当中会在日志文件中进行输出-->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<!--%date{HH:mm:ss.SSS} %c -->
<!--设置了日志打印输出的时间格式-->
<pattern>%date{HH:mm:ss.SSS} %c [%t] - %m%n</pattern>
</encoder>
</appender>
<!--获取的日志是 debug 级别-->
<!--
name:用来指定受此logger约束的某一个包或者具体的某一个类。
level:用来设置打印级别(TRACE, DEBUG, INFO, WARN, ERROR, ALL 和 OFF),还有一个值INHERITED或者同义词NULL,代表强制执行上级的级别。如果没有设置此属性,那么当前logger将会继承上级的级别。
addtivity:用来描述是否向上级logger传递打印信息。默认是true。
appender-ref则是用来指定具体appender的。
-->
<logger name="c" level="debug" additivity="false">
<appender-ref ref="STDOUT"/>
</logger>
<!--根logger,也是一种logger,且只有一个level属性-->
<root level="ERROR">
<appender-ref ref="STDOUT"/>
</root>
</configuration>
创建以及运行线程
线程的创建以及启动分为两步,先创建,然后运行
thread
@Slf4j(topic = "c.test")
public class Test1 {
public static void main(String[] args) {
Thread t = new Thread() {
@Override
public void run() {
log.debug("running");
}
};
t.setName("t1");
t.start();
log.debug("main is running");
}
}
Runnable
/**
* 线程与任务分离开
*
* Runnable 里面定义了任务
*
* 然后传递到 Thread 进行线程
*/
@Slf4j(topic = "c.Test2")
public class Test2 {
public static void main(String[] args) {
/**
* Runnable r = new Runnable() {
* @Override
* public void run() {
* log.debug("running");
* }
* };
*/
Runnable r = () -> {log.debug("running");};
Thread t = new Thread(r);
t.setName("t2");
t.start();
log.debug("main is running");
}
}
Thread 与 Runnable 之间的关系
Thread 实现的匿名内部类,本质上面还是一种 Thread 类的继承,将线程以及任务放在了一起,使用 Runnable 将线程与任务分开,使得更加的灵活;

@Slf4j(topic = "c.Test12")
public class Test12 {
public static void main(String[] args) throws InterruptedException {
// 实际上使用的是创建的 Thread 线程的构造器 (Runnable,"name")
// 由于里面没有输入的参数,直接使用 lambda 表达式即可
// 任何对象在创建的时候,都是会使用构造函数的,构造函数使用什么的形式,将相关的参数进行传递即可
Thread t1 = new Thread(() -> {
System.out.println("this a new thread");
}
}, "t1");
t1.start();
}
}
FutureTask
接收 Callable 类型的参数,用来处理返回结果的情况
线程之间的通讯可以用的到
@Slf4j(topic = "c.Test3")
public class Test3 {
public static void main(String[] args) throws Exception {
FutureTask<Integer> task = new FutureTask<Integer>(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
log.debug("running...");
return 100;
}
});
Thread t = new Thread(task, "t1");
t.start();
// 获取返回结果 主线程得到的返回结果
log.debug("{}", task.get());
log.debug("main is running...");
}
}
线程运行原理
栈与栈帧

线程启动的时候,每个线程都会分配一个虚拟机栈,栈帧就是当前线程调用的每一个方法,在方法调用结束之后,方法会退出来栈,释放内存;
当前线程调用一个方法,这个方法作为一个栈帧放在栈里面;
图解栈与栈帧
public class TestFrams {
public static void main(String[] args) {
method1(10);
}
private static void method1(int x) {
int y = x + 1;
Object m = method2();
System.out.println(m);
}
private static Object method2() {
Object n = new Object();
return n;
}
}
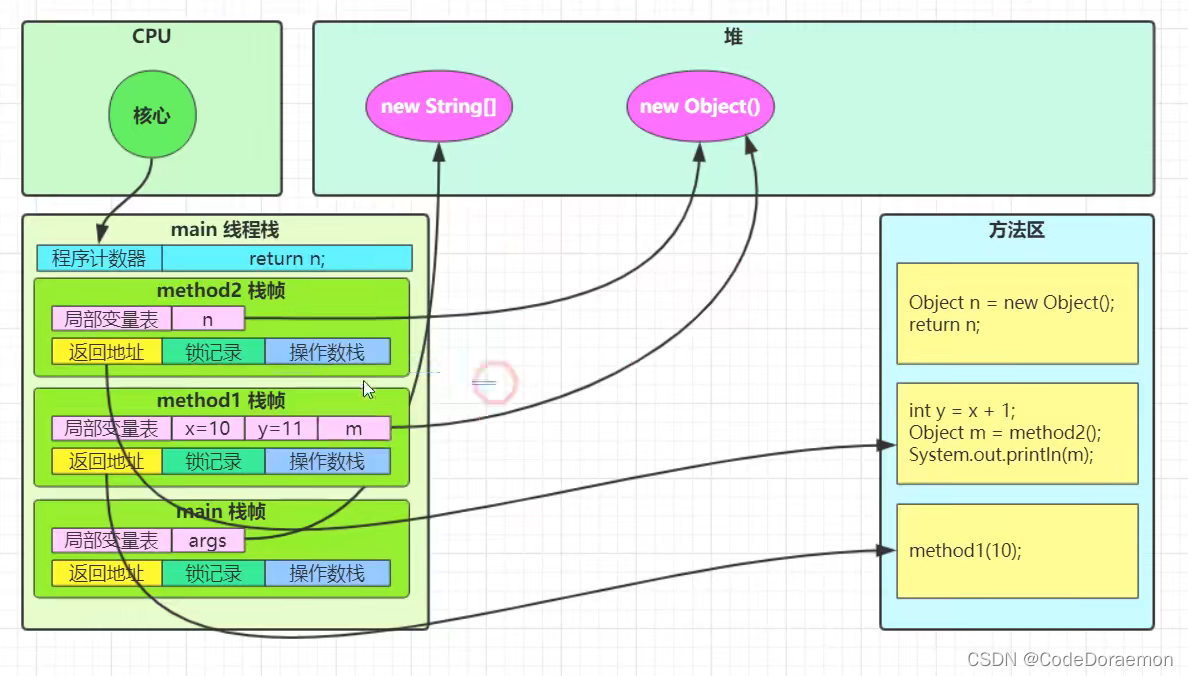
方法调用结束,将 method1 以及 method2 内存释放即可
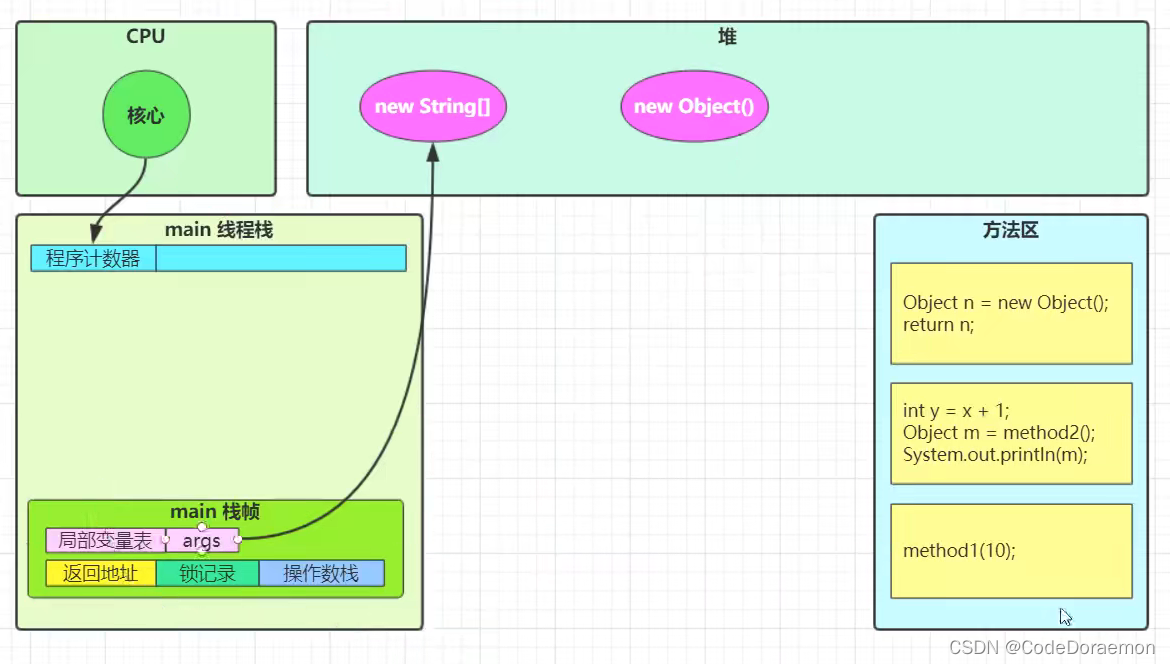
栈帧小结
线程是有自己的栈帧,自己的程序计数器,相互之间是不会影响的;
线程的上下文切换
什么是线程的上下文切换
线程从使用 cpu 到不使用 cpu 之间进行的一次转换,转换到了另外的线程进行执行;

对于线程执行的状态是需要记录的,否则,不知道从什么地方开始执行线程;
线程中的常用方法
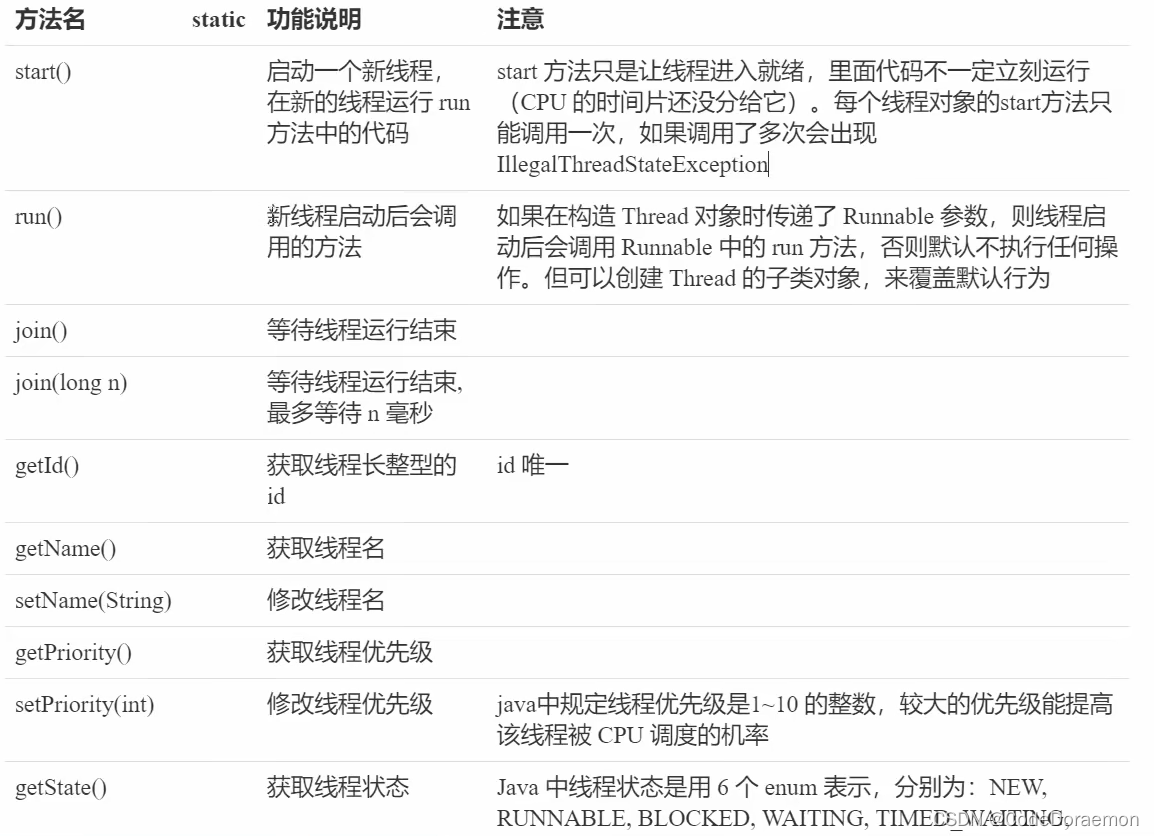

join 用于线程之间的通信
start 与 run
start 表示启动线程
run 表示线程启动之后需要执行的代码
启动一个线程必须使用 start() ,直接调用 run 方法,不能启动多线程的执行,只是一个普通的方法执行了;
sleep 与 yield

yield:使得线程从运行状态变成就绪状态,将 cpu 时间片交出来,让其他的线程进行使用;
sleep() 是进入Time Waiting 状态;
Time Wairing 状态是 Java 定义的一种阻塞状态的细分;
yield 的实现依赖于任务调度器;有时候可能出现的结果是,想要将 cpu 时间片让出去,但是,没有其他的线程需要使用,所以出现让不出去的结果;
yield 与 sleep 之间的区别
一个线程调用了 yield 还是有机会继续获得 cpu 时间片继续运行的;
但是 Time Waiting 状态就是 阻塞状态,必须等到时间到了以后,才能执行,在这个期间是没有办法得到 cpu 时间片的;
sleep 是存在等待时间的,但是 yield 是几乎没有等待时间的;
join() 线程的同步可以使用
@Slf4j(topic = "c.Test10")
public class Test10 {
static int r = 0;
public static void main(String[] args) throws InterruptedException {
test1();
}
private static void test1() throws InterruptedException {
log.debug("开始");
Thread t1 = new Thread(() -> {
log.debug("开始");
sleep(1);
log.debug("结束");
r = 10;
},"t1");
t1.start();
// 主线程执行到这里的时候,不会继续执行下去,而是会等待 t1 线程执行结束之后,才会继续执行自己的代码
t1.join();
log.debug("结果为:{}", r);
log.debug("结束");
}
}

主线程就是想要获取到 t1 线程中的数值,怎么比较好的获取到呢?
此时使用 join() 方法即可;
直接使用 sleep() 这个解决方式不是十分的好;
join() 等待线程结束;在上面的代码的体现就是主线程会一直等待知道 t1 线程执行结束;
同步 小案例
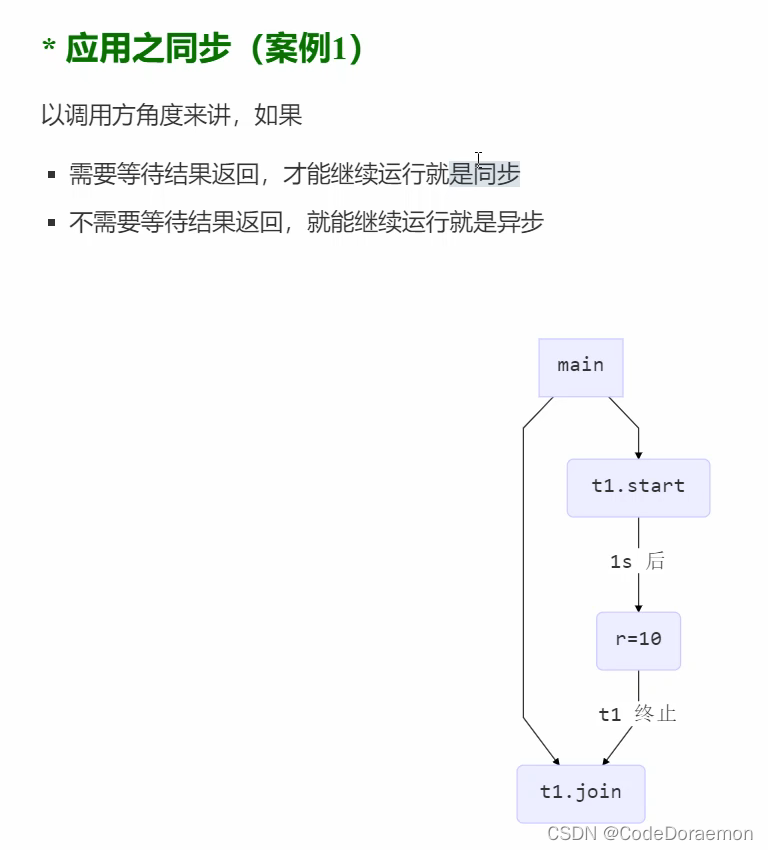
上面的案例中,体现出来了同步的概念,在调用了之后,需要等待运行结果,这就是同步;
如何实现多个线程的同步呢?可以使用分别调用多个线程的 join() 方法即可;
多线程运行的时间计算:需要的最长时间的线程的时间就是总运行的时间;
join(long) 有时间限制的等待
当等待的时间超过了限制之后,就不会继续等待了;直接退出去不等待了;
具有时效的等待;
interrupt() 打断 sleep wait join 的线程 阻塞线程

在打断标志的地方,按道理打断标志应该为 true ;但是这种阻塞是的线程在打断之后,报出来了异常,打断为假
interrupt 打断正常运行的线程
结合打断标识,可以主线程可以让分支线程主动的选择是不是确定自己结束后面的代码执行;
@Slf4j(topic = "c.Test12")
public class Test12 {
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(()->{
while (true) {
// 主线程中虽然让 t1 线程进行打断,但是具体是不是打断需要 t1 线程自己决定,主线程打断之后
// 打断标识在这里会变成真的,所以可以使用打断标识进行正确的打断即可
boolean interrupt = Thread.currentThread().isInterrupted();
if (interrupt) {
log.debug("被打断了,退出去循环");
break;
}
}
},"t1");
t1.start();
// 为什么需要主线程先 sleep() 一秒钟呢?为了让 t1 线程先运行一下,不然 t1 还没有sleep 就打断了 程序没有达到自己的期望输出
Thread.sleep(1);
log.debug("interrupt");
// 这个时候使用了打断标识,可以合理的将线程进行打断处理
t1.interrupt();
}
}
interrupt 的多线程设计模式 两阶段终止模式 (Two Phase Termination)
简单理解就是一种好的使用一个线程停止另外一个线程的方法;
这个好的方法就是使用 两阶段终止莫斯

监控线程的案例
上面的错误思路是,stop 以及 exit 导致程序错误的执行,是不建议使用的;
每隔一段时间进行线程的监测,观察是否打断线程;

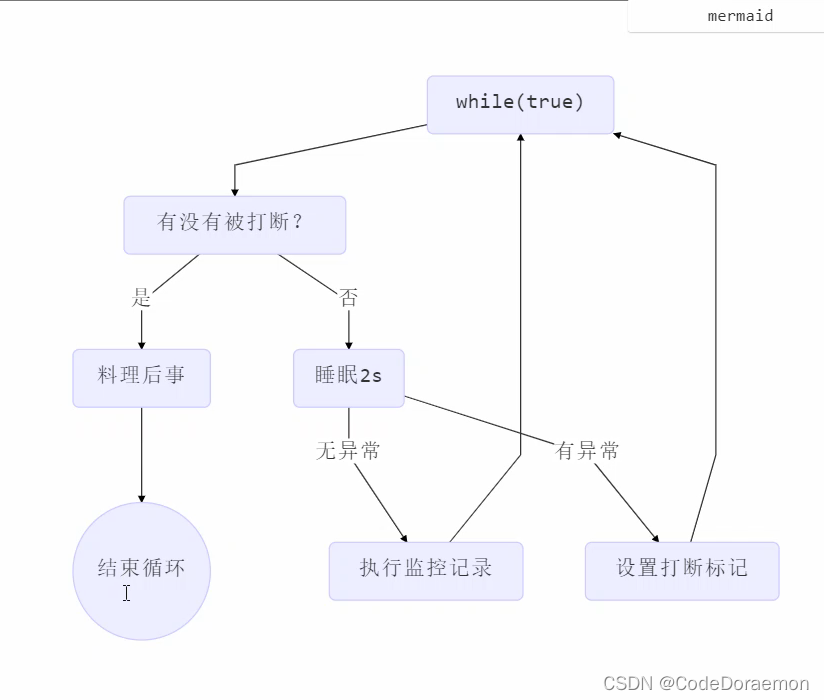
后面的存在异常之后,打断标记会变为 false 此时可以重新对于 false 进行处理将其改变为 true 或者不进行改变;当程序运行到打断标记为 true 的时候,线程才会被终止;
@Slf4j(topic = "c.Test13")
public class Test13 {
public static void main(String[] args) throws InterruptedException {
TwoPhaseTermination twoPhaseTermination = new TwoPhaseTermination();
twoPhaseTermination.start();
Thread.sleep(3500);
twoPhaseTermination.stop();
}
}
@Slf4j(topic = "c.Two")
class TwoPhaseTermination{
private Thread monitor;
// 启动监控线程
public void start() {
monitor = new Thread(()->{
while (true) {
Thread current = Thread.currentThread();
if (current.isInterrupted()) {
log.debug("终止当前线程的执行");
break;
}
try {
Thread.sleep(1000);
log.debug("执行监控记录");
} catch (InterruptedException e) {
e.printStackTrace();
// 重新设置打断标志,因为是在异常中执行的,打断标志为 false,重新设置之后,为了打断标志为 真
// 打断标志会变为 true 线程才会被真正的终止
current.interrupt(); // 两次打断 终止线程的执行
}
}
});
monitor.start();
}
// 关闭监控线程
public void stop() {
// monitor 就是监测线程,这个是正常调用线程的 interrupt 方法,其他的方法也是可以调用的;
monitor.interrupt();
}
}
运行结果:
19:58:05.922 c.Two [Thread-0] - 执行监控记录
19:58:06.930 c.Two [Thread-0] - 执行监控记录
19:58:07.932 c.Two [Thread-0] - 执行监控记录
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at com.luobin.concurrent.TwoPhaseTermination.lambda$start$0(Test13.java:38)
at java.lang.Thread.run(Thread.java:748)
19:58:08.421 c.Two [Thread-0] - 终止当前线程的执行
interrupt 打断 park 线程
@Slf4j(topic = "c.Test15")
public class Test15 {
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(()->{
log.debug("parking");
LockSupport.park();
log.debug("unpark");
log.debug("打断状态:{}",Thread.interrupted());
// 上面的 interrupted 修改为 false 下面的 park 会继续的执行
// park 会继续执行
LockSupport.park();
log.debug("unpark");
},"t1");
t1.start();
// 放置还没有进入 park 直接打断
Thread.sleep(1000);
// 打断 park 的状态
t1.interrupt();
}
}
小结:
park 方法本身会使得当前线程进入阻塞状态;
Thread.currentThread().isInterrupted() 会打断 park 线程;使得线程打断,停止运行;
Thread.interrupted() 不会打断 park park 会继续的执行;
不推荐使用的方法 过时的方法

容易导致线程死锁的产生,不建议使用;过时的方法
线程优先级
可以设置优先级别,最低的优先级别是 1 ,最高的优先级别是 10,默认的优先级别是 5 ;
线程的优先级,会提示调度器调度该线程,仅仅是一个提示,调度器是可以忽略你的提示的;
在 cpu 比较忙的时候,线程的优先级高的线程会获得更多的时间片,但是在 cpu 比较闲的时候,优先级几乎是没有作用的;
@Slf4j(topic = "c.Test9")
public class Test9 {
public static void main(String[] args) {
Runnable task1 = () -> {
int count = 0;
for (;;) {
System.out.println("---->1 " + count++);
}
};
Runnable task2 = () -> {
int count = 0;
for (;;) {
// Thread.yield();
System.out.println(" ---->2 " + count++);
}
};
Thread t1 = new Thread(task1, "t1");
Thread t2 = new Thread(task2, "t2");
t1.setPriority(Thread.MIN_PRIORITY);
t2.setPriority(Thread.MAX_PRIORITY);
t1.start();
t2.start();
}
}
小结
无论是 yield 还是设置的优先等级,都不能最终的决定任务调度的最终结果,只有任务调度器本省可以决定;
yield 以及 线程优先级仅仅是对于线程调度器的一个提示而已;
案例 防止 CPU 占用率达到 100%
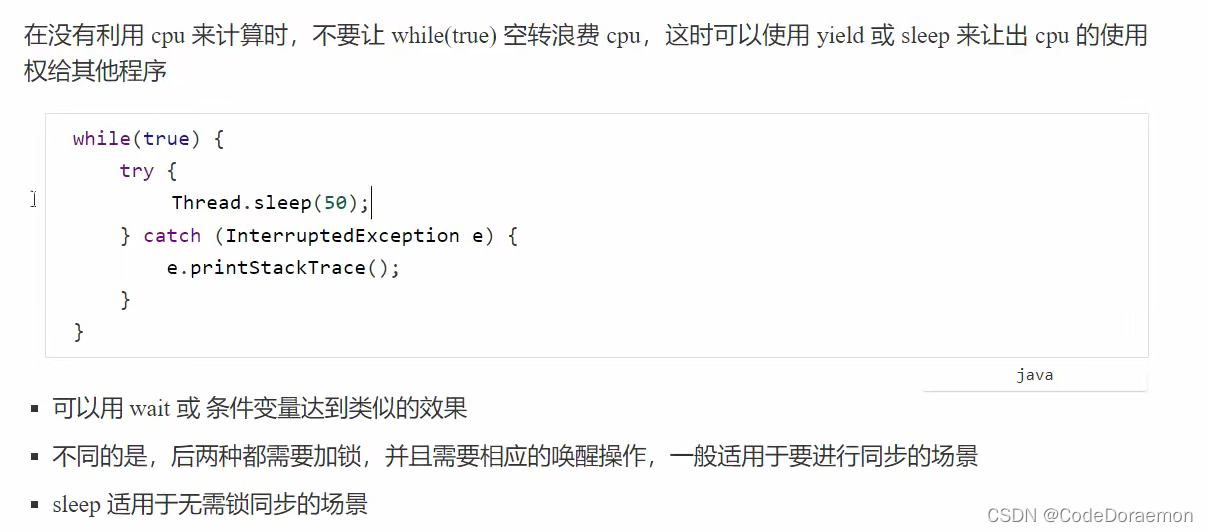
只是编写 while true 存在问题中间可以加一个 sleep() 避免空转;
主线程以及守护线程
在默认的情况下面,Java 进行需要等待所有的线程执行完毕之后,才会结束进行的运行,但是不会等待守护线程的结束,守护线程没有执行结束,也是会被强制结束的,备胎舔狗线程;

线程的运行状态 5 种? 6 种?
操作系统的层面
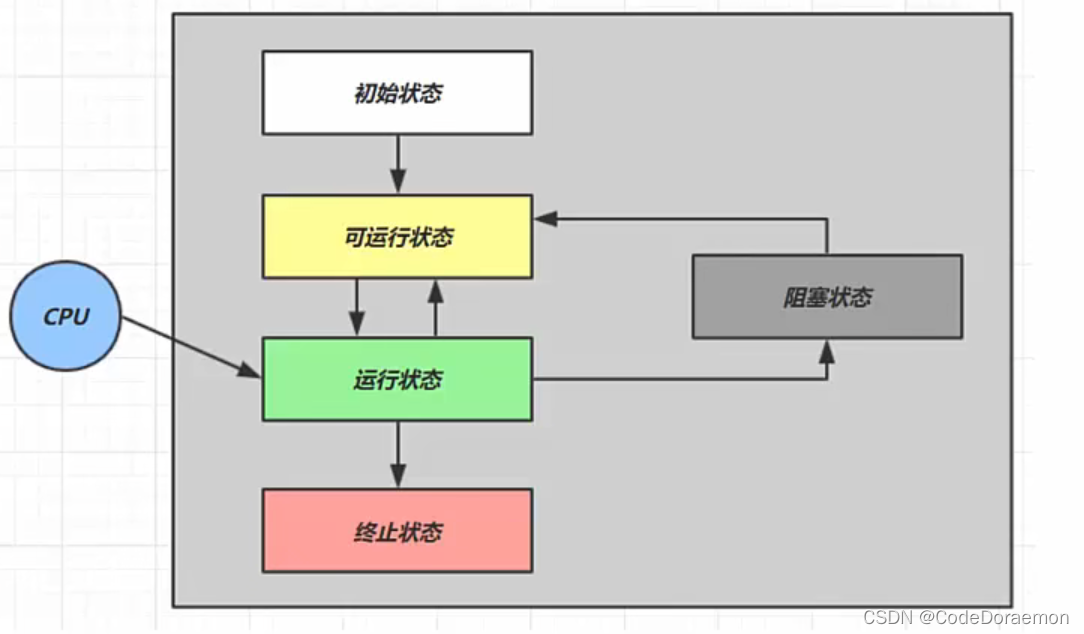

从 Java API 层面进行描述
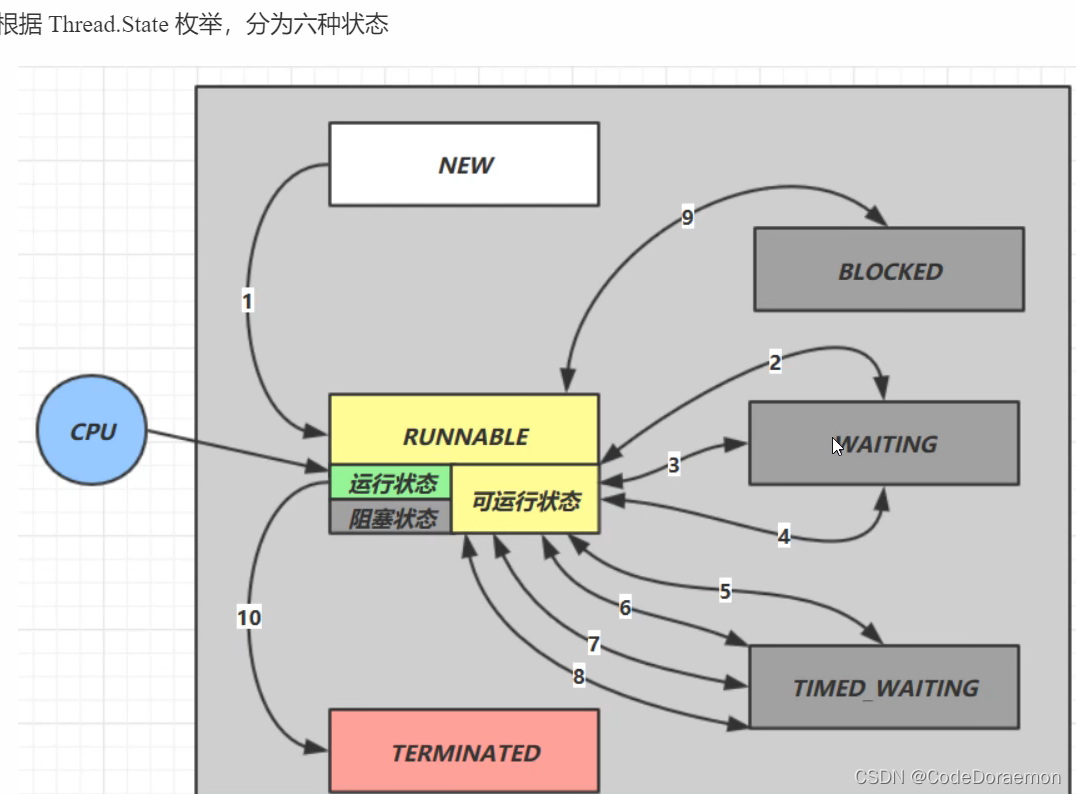
Java 源代码中将线程的运行状态分为 6 种,使用枚举记性分类的;
NEW 表示线程刚创建,没有使用 start 方法
RUNNABLE 当调用了 start() 方法之后,注意,Java API 层面的 RUNNABLE 状态涵盖了 操作系统 层面的【可运行状态】、【运行状态】和【阻塞状态】(由于 BIO 导致的线程阻塞,在 Java 里无法区分,仍然认为是可运行)
BLOCKED , WAITING , TIMED_WAITING 都是 Java API 层面对【阻塞状态】的细分
TERMINATED 当线程代码运行结束
6 种状态的代码演示
@Slf4j(topic = "c.TestState")
public class TestState {
public static void main(String[] args) throws IOException {
// new
Thread t1 = new Thread("t1") {
@Override
public void run() {
log.debug("running...");
}
};
// runnable
Thread t2 = new Thread("t2") {
@Override
public void run() {
while(true) { // runnable
}
}
};
t2.start();
// Terminate
Thread t3 = new Thread("t3") {
@Override
public void run() {
log.debug("running...");
}
};
t3.start();
// 有时间限制的等待
Thread t4 = new Thread("t4") {
@Override
public void run() {
synchronized (TestState.class) {
try {
Thread.sleep(1000000); // timed_waiting
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
t4.start();
// 需要等待 线程 t2 的执行结束才会停止执行代码。所以处于 waiting z状态
Thread t5 = new Thread("t5") {
@Override
public void run() {
try {
t2.join(); // waiting
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
t5.start();
// TestState.class 先被 t4 线程加锁,然后下面的这个线程拿不到锁,所以到了 blocked(被封锁) 的状态
Thread t6 = new Thread("t6") {
@Override
public void run() {
synchronized (TestState.class) { // blocked
try {
Thread.sleep(1000000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
t6.start();
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("t1 state {}", t1.getState());
log.debug("t2 state {}", t2.getState());
log.debug("t3 state {}", t3.getState());
log.debug("t4 state {}", t4.getState());
log.debug("t5 state {}", t5.getState());
log.debug("t6 state {}", t6.getState());
System.in.read();
}
}
执行结果
11:59:52.996 c.TestState [t3] - running...
11:59:53.501 c.TestState [main] - t1 state NEW
11:59:53.502 c.TestState [main] - t2 state RUNNABLE
11:59:53.502 c.TestState [main] - t3 state TERMINATED
11:59:53.502 c.TestState [main] - t4 state TIMED_WAITING
11:59:53.502 c.TestState [main] - t5 state WAITING
11:59:53.502 c.TestState [main] - t6 state BLOCKED
阶段小结

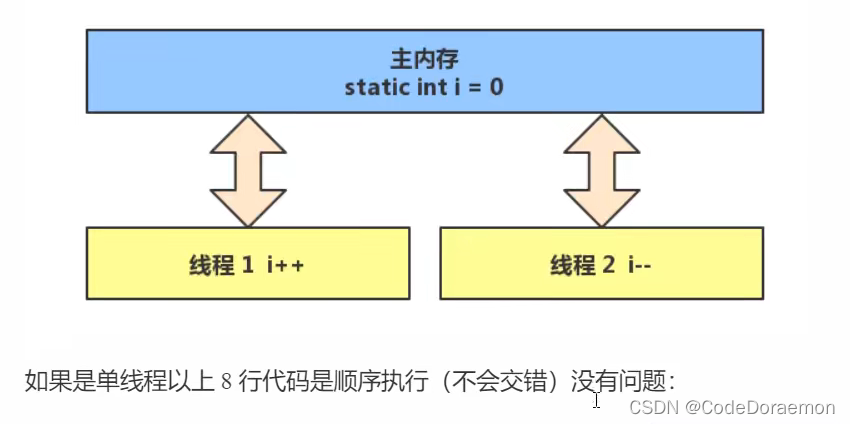
共享问题
共享资源带来的问题
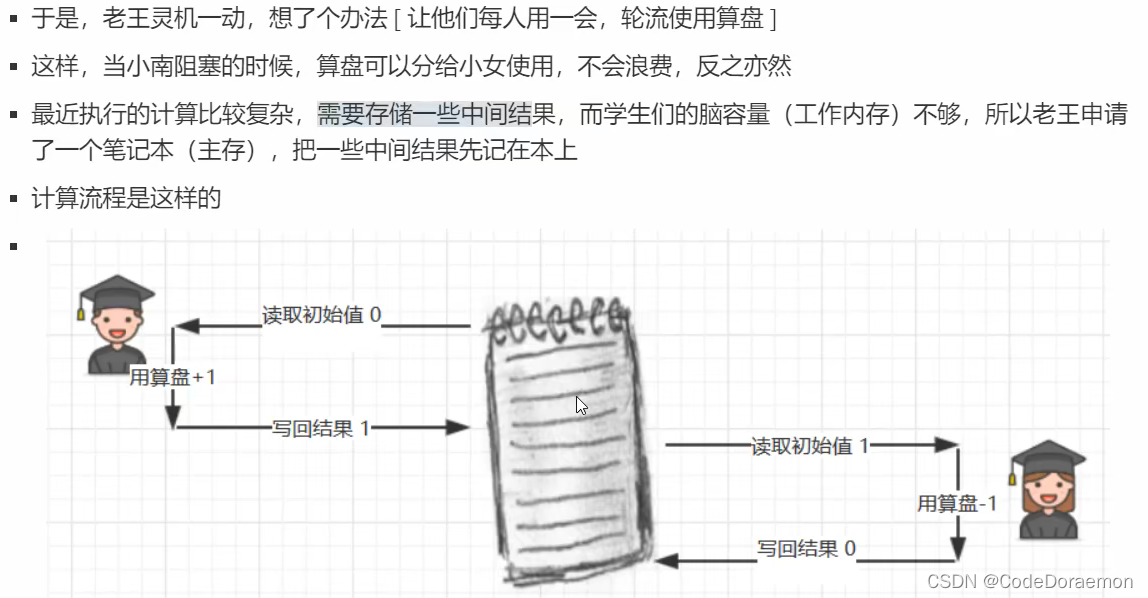
代码模拟实现
@Slf4j(topic = "c.Test17")
public class Test17 {
static int count = 0;
public static void main(String[] args) throws InterruptedException{
Thread t1 = new Thread(()-> {
for (int i = 0; i < 5000; i++) {
count++;
}
},"t1");
Thread t2 = new Thread(()-> {
for (int i = 0; i < 5000; i++) {
count--;
}
},"t2");
t1.start();
t2.start();
t1.join();
t2.join();
log.debug("count 现在的数值是:{}",count);
}
}
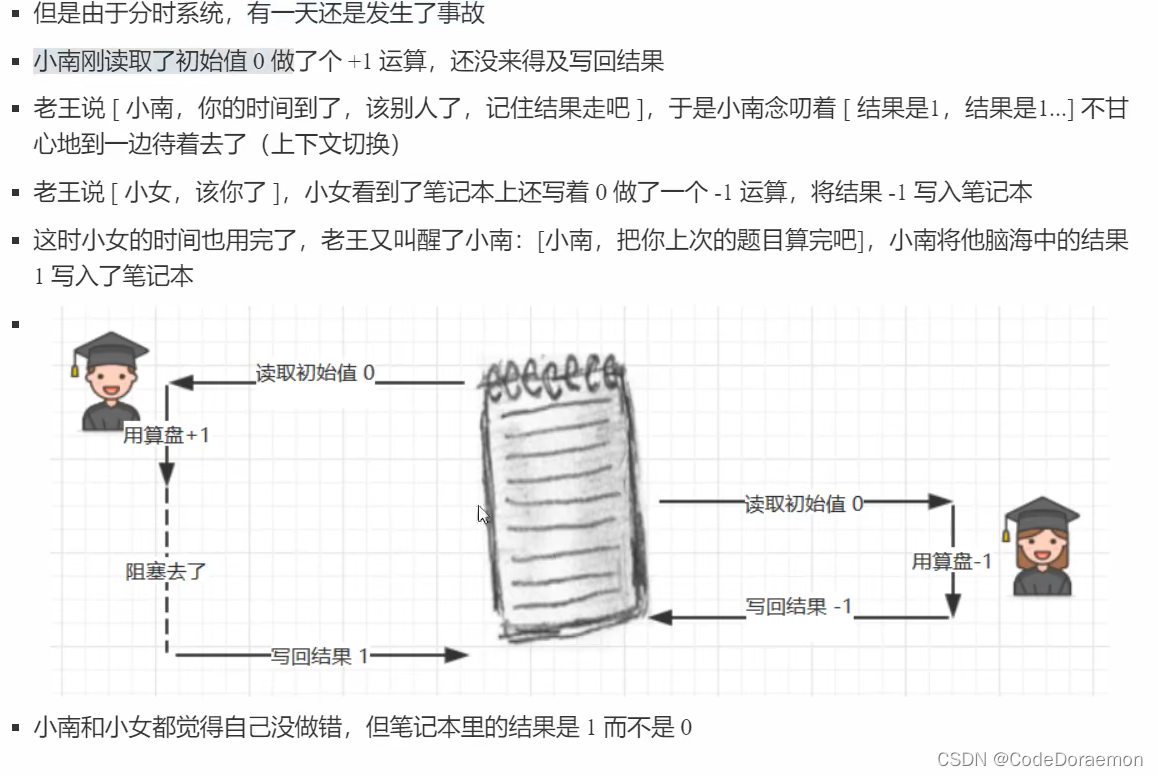
上面的代码中,结果不一定是 0 ,下面是分析,涉及到线程安全的问题:


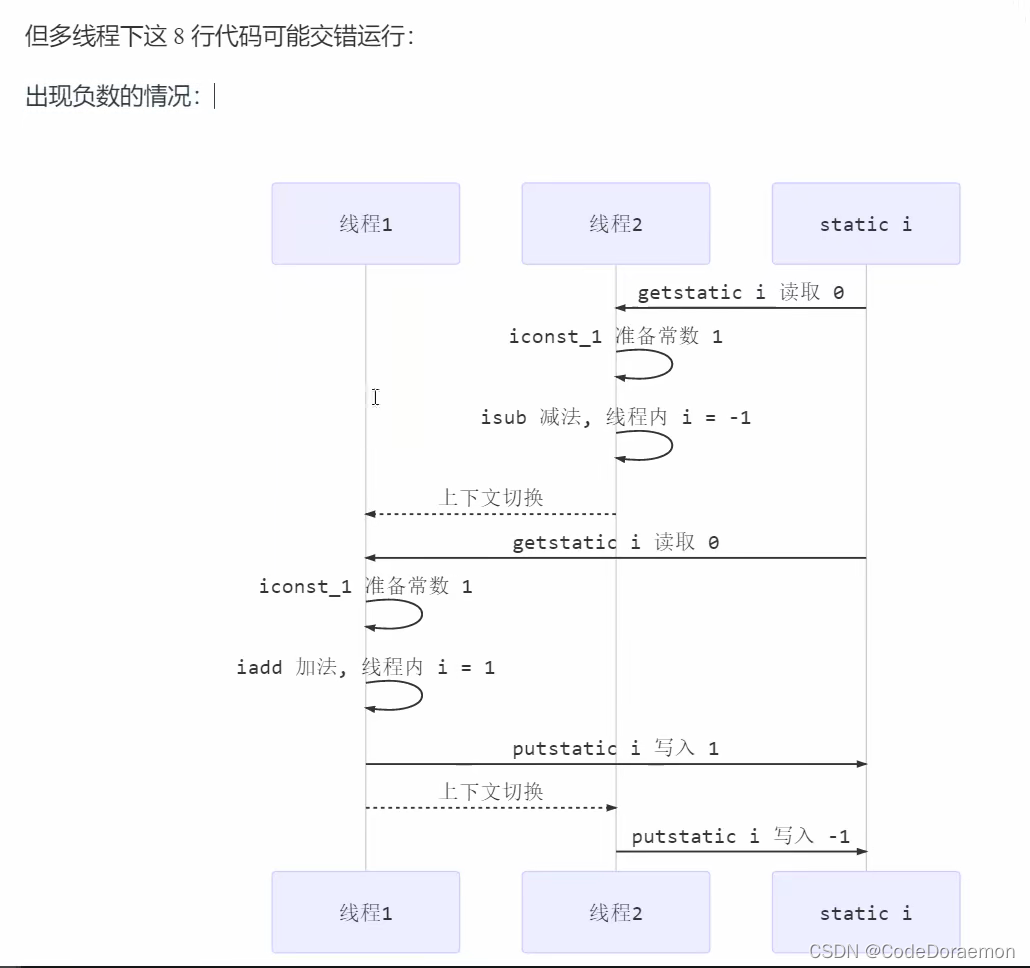
虽然做了一次加法以及一次减法,但是由于指令的交错,使得最终的结果显示的不正确;
一个加法线程在执行结束之后,还没有来得及写入更新,线程进行了上下文切换,在另一个减法线程写入更新前,加法的线程更新了,随后减法的线程更新了,导致最终是减法的结果,加法的线程被覆盖掉了,产生了不正常的状态;
下面展示为 结果为 1 的情况,这种情况也是不正确的:
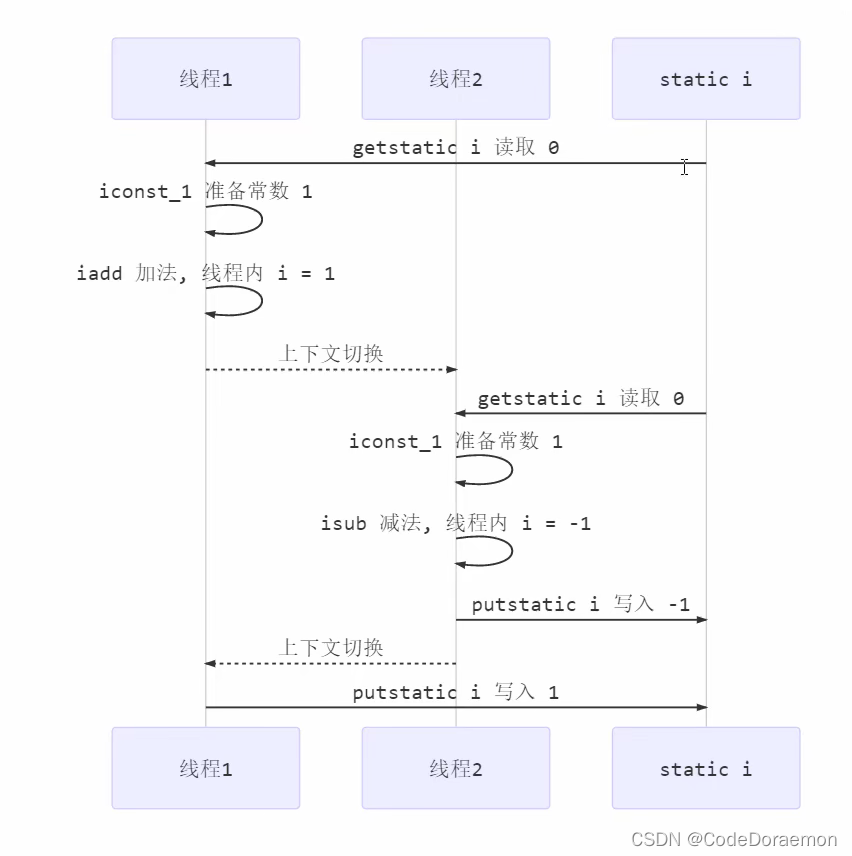
虽然做了一次加法以及一次减法,但是由于指令的交错,使得最终的结果显示的不正确;
根本原因就是上下文切换导致的指令交错,导致了错误的执行结果;造成了多线程访问安全的问题;
临界区 Critical Section
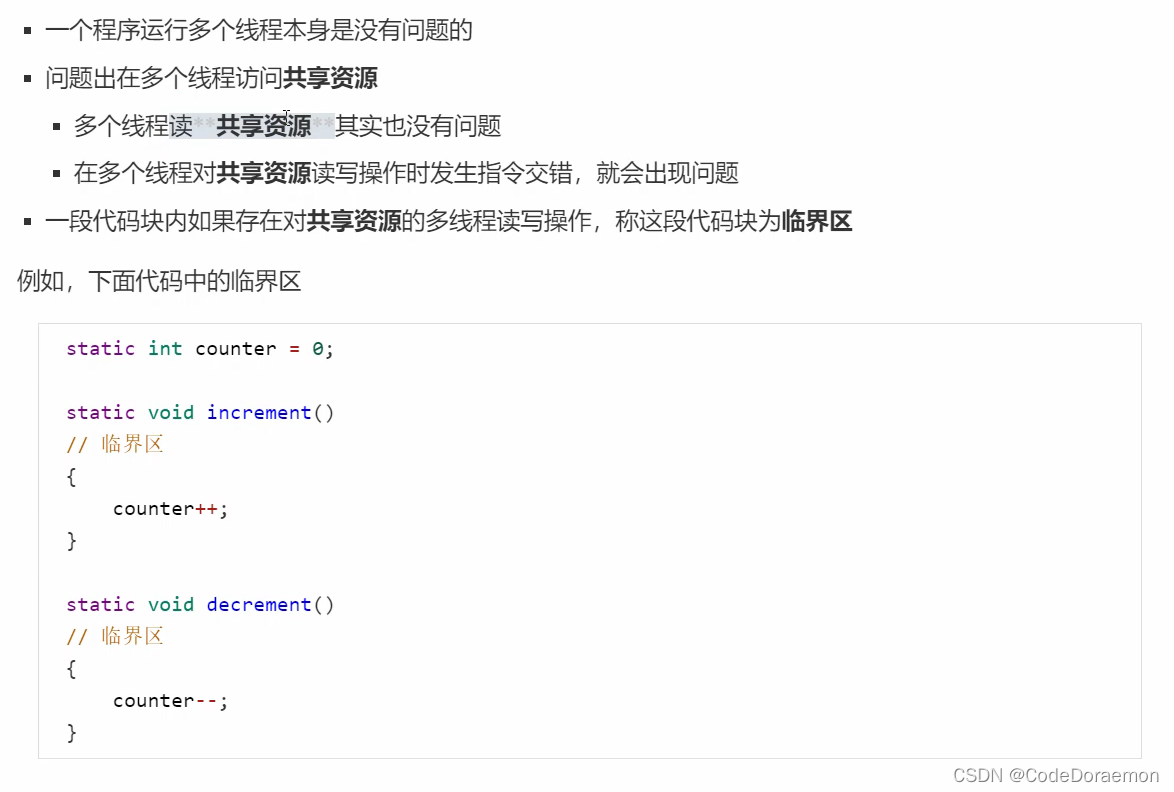
多个线程共享的时候,发生了指令交错,引发出来的临界区的概念;
一段代码存在对共享资源的 多线程 读写操作,叫做临界区
竞态条件
多个线程在临界区内执行,由于代码的执行序列不同,从而产生的导致结果无法预测,叫做竞态条件;
避免临界区的竞态条件的发生,采用下面的处理方式
1、阻塞方式的解决方案
2、非阻塞方式的解决方案

synchronized

保证在里面的对象是将来多线程访问的同一个变量;
同一个时刻,只能有一个线程拿到对象锁,其他线程是访问不到的;其他的线程进入阻塞状态,也就是所谓的 block 状态;
这样子避免了还没有来得及保存数据就发生了上下文切换,导致的数据返回结果的问题;
当前线程使用结束之后,释放锁,让其他的线程得到对象锁,继续进行访问;
使用图解进行上述 synchronized 的解释
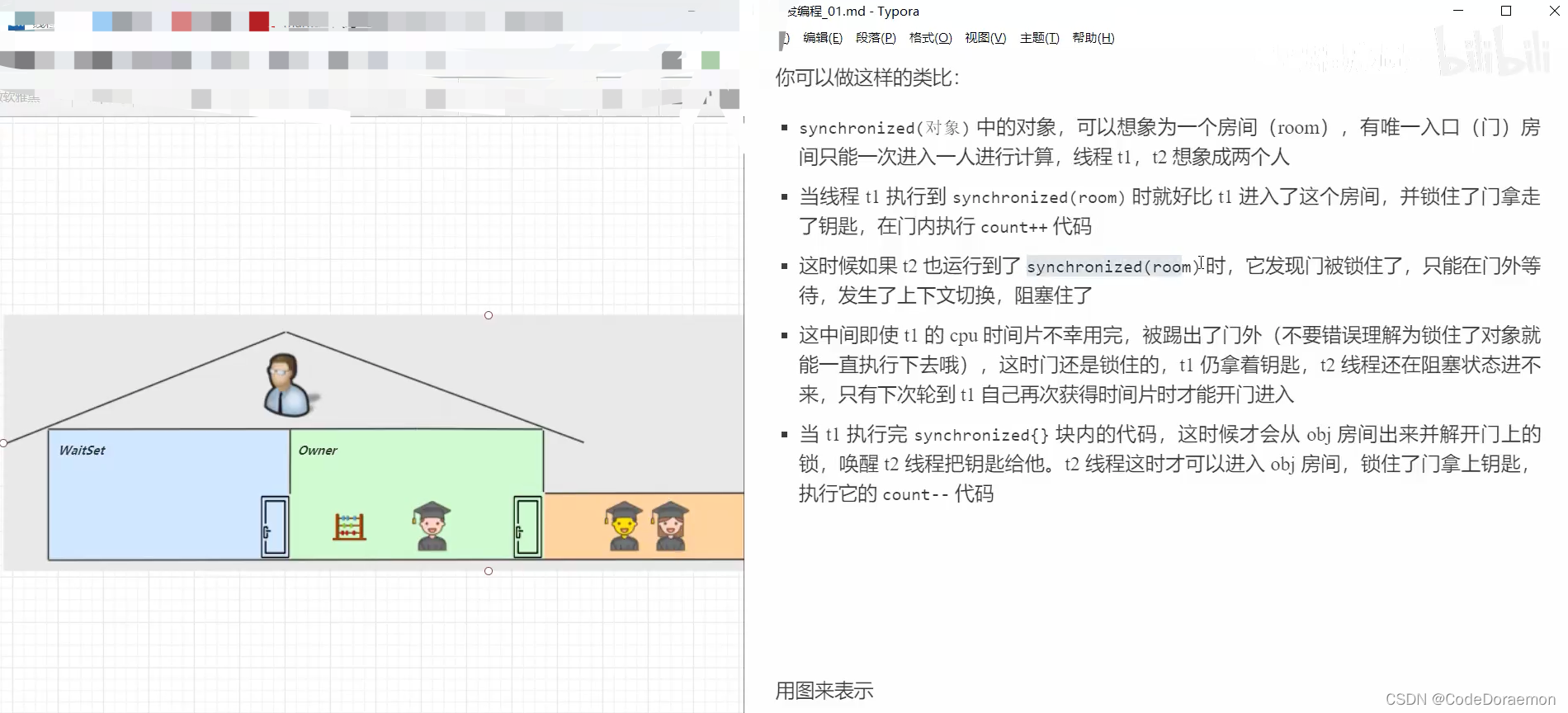
上述图的含义就是:一个线程必须将所有的代码块中的代码执行结束之后,才会把锁交还回去,其他线程处于阻塞状态是获取不到锁的,因为cpu 时间片不会分配给阻塞线程,只有当前线程执行完毕,他可以唤醒阻塞线程,进行下面的相关操作;
使用严谨的方式进行表示 (参考黑马程序员)
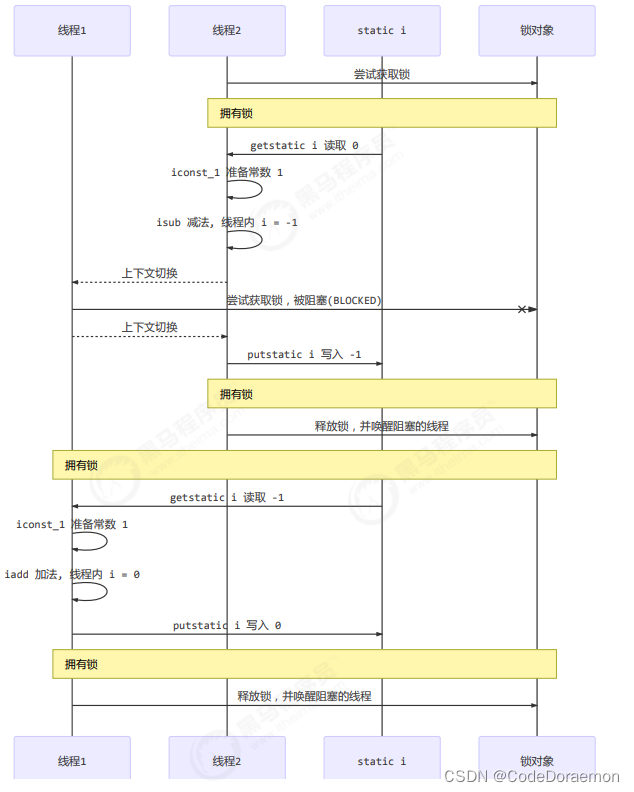
思考
synchronized 实际上是使用了对象锁,保证了临界区域内代码的原子性,临界区域的代码对于外面是不可以分割的,不会被线程切换打断;

下面的问题是对于加不加对象锁的讨论,只有多个线程同时加了对象锁,那么才能保证临界区代码执行的原子性,才不会产生由于线程上下文切换锁导致的问题;
使用面向对象的思想进行上面的代码优化
@Slf4j(topic = "c.Test17")
public class Test17 {
public static void main(String[] args) throws InterruptedException {
Room room = new Room();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 5000; i++) {
room.increment();
}
}, "t1");
Thread t2 = new Thread(() -> {
for (int i = 0; i < 5000; i++) {
room.decrease();
}
}, "t2");
t1.start();
t2.start();
t1.join();
t2.join();
log.debug("count 现在的数值是:{}",room.getCounter());
}
}
class Room {
private int count = 0;
public void increment() {
// 锁住当前的对象 this 指代的就是当前的 Room 对象
synchronized (this) {
count++;
}
}
public void decrease() {
synchronized (this) {
count--;
}
}
public int getCounter() {
synchronized (this) {
return count;
}
}
}
synchronized 加在方法上

synchronized 是对象锁,只是锁住对象,不是锁方法的,可以在方法书写的时候,使用 synchronized 进行申明这是锁住的对象,也就是锁住了方法中的所有代码块;
锁住的是 this 对象;
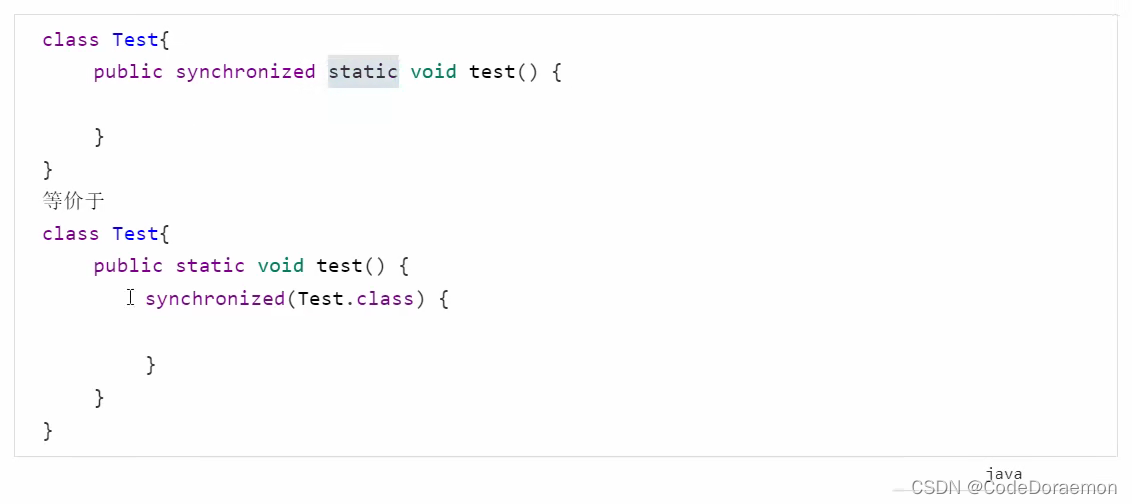
将 synchronized 加在静态方法上面,也是同样的道理;只不过这个时候锁住的是类对象,不是当前对象,类对象是:Test.class
类对象以及普通对象的理解

类:定义了一套规则
类对象:.class 文件
普通对象:.class 文件实例化出来的普通对象
理解的不太准确,后续仍然需要理解;
线程八锁 synchronized 的理解
锁住了 this
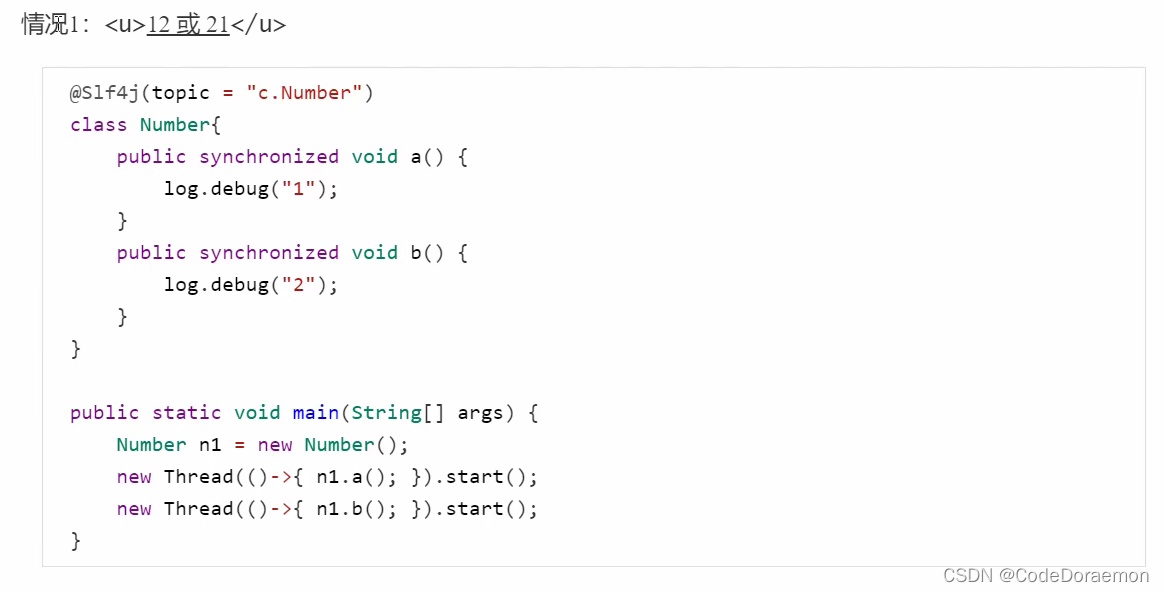
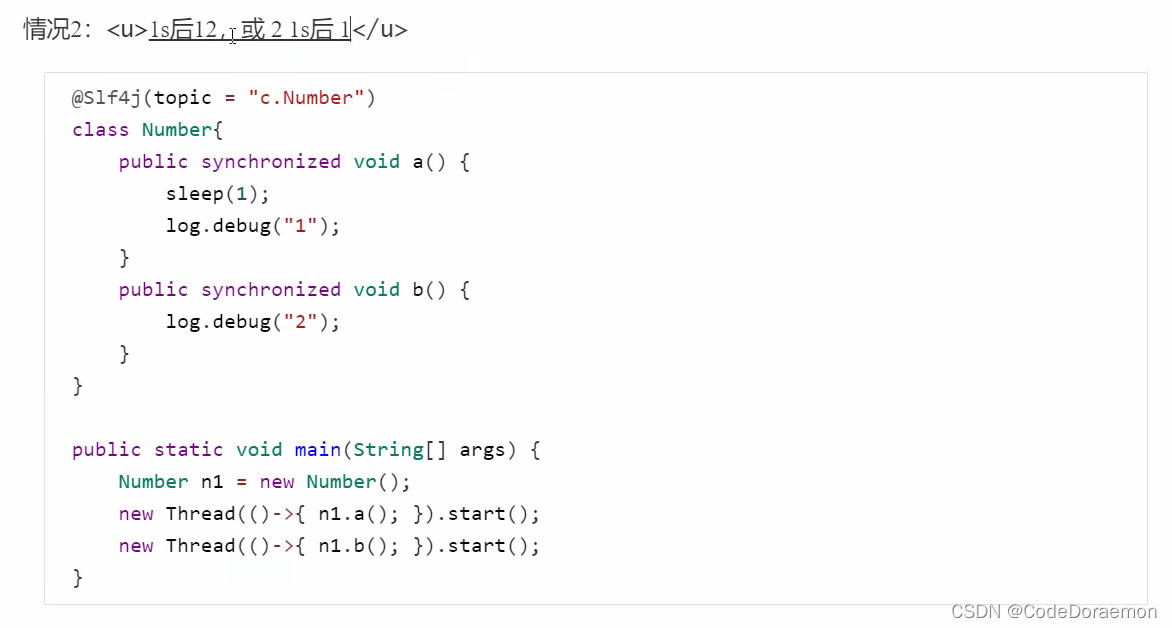
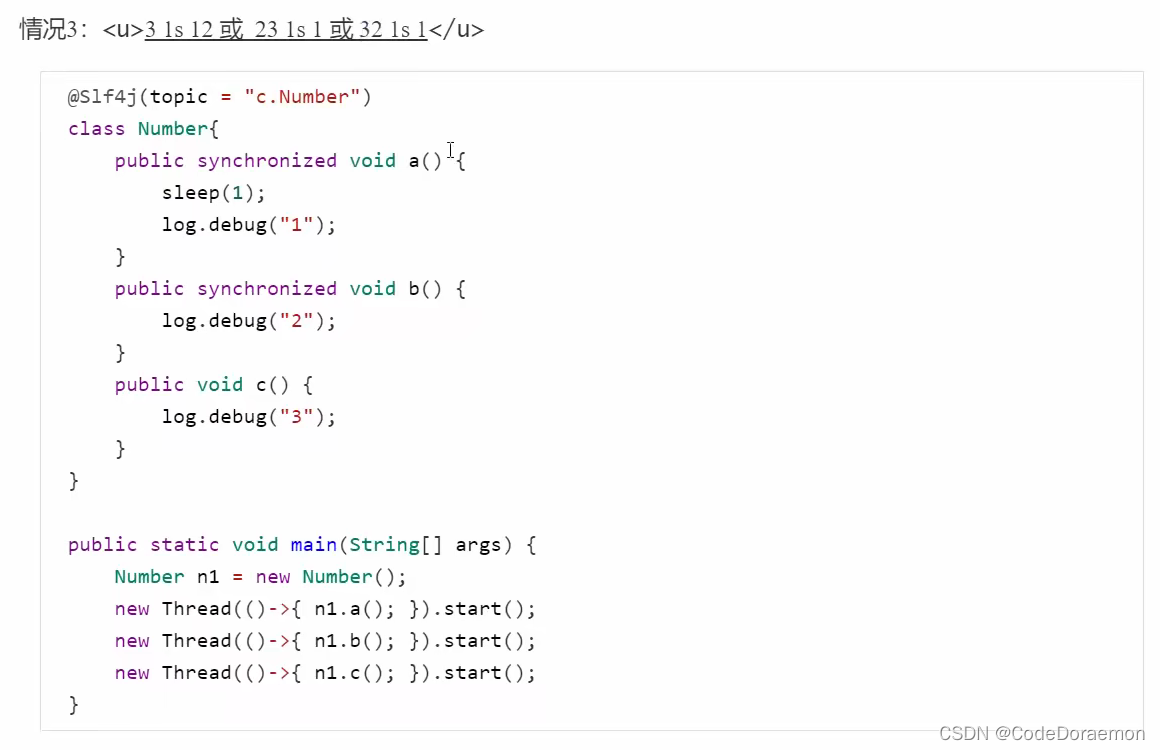
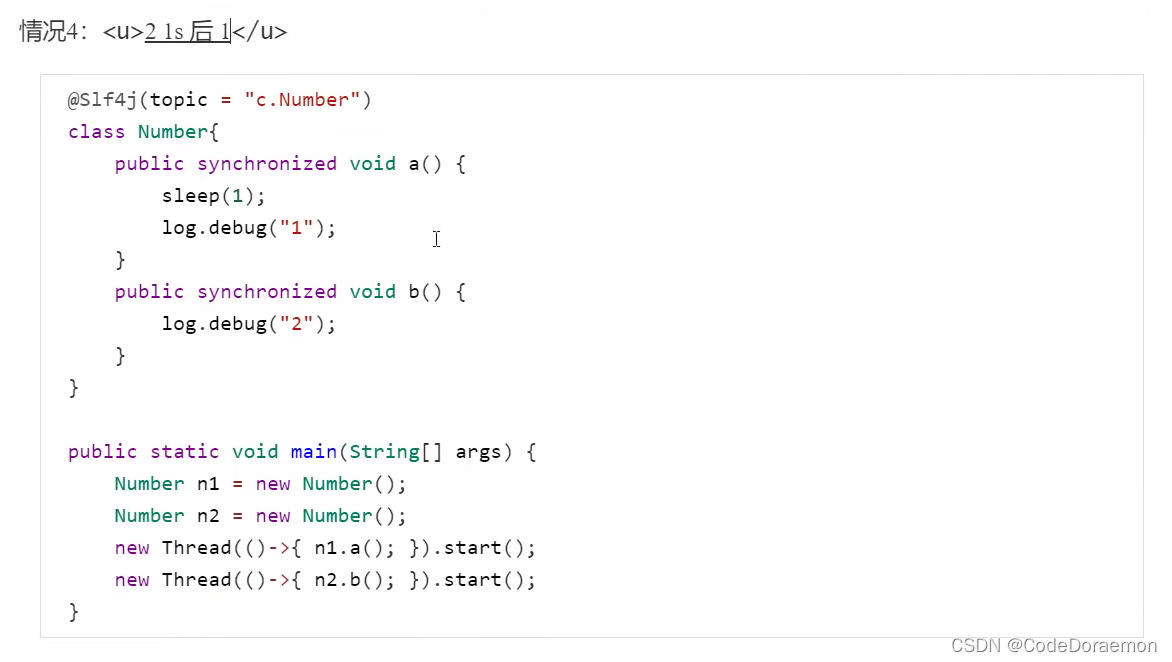
5、一个使用的是类锁,一个使用的是对象锁,两者之间是没有影响的,所以先执行 2 等待 1 s 之后,执行 1
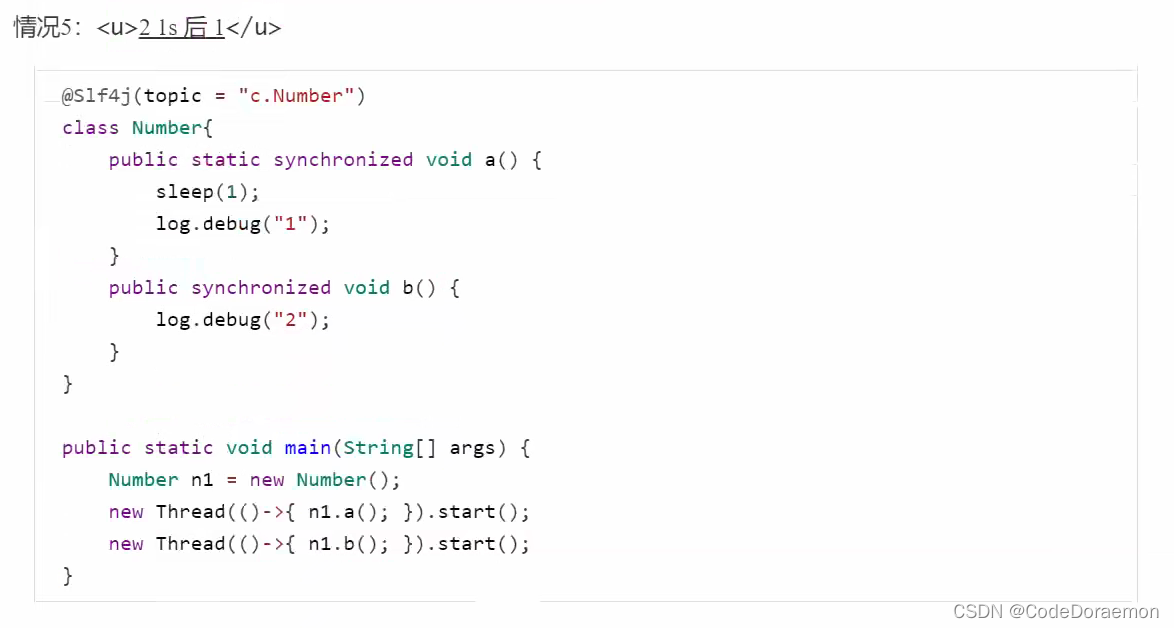
6、使用的都是类锁,也就是使用的是一把锁,所以两者之间会灯虎等待
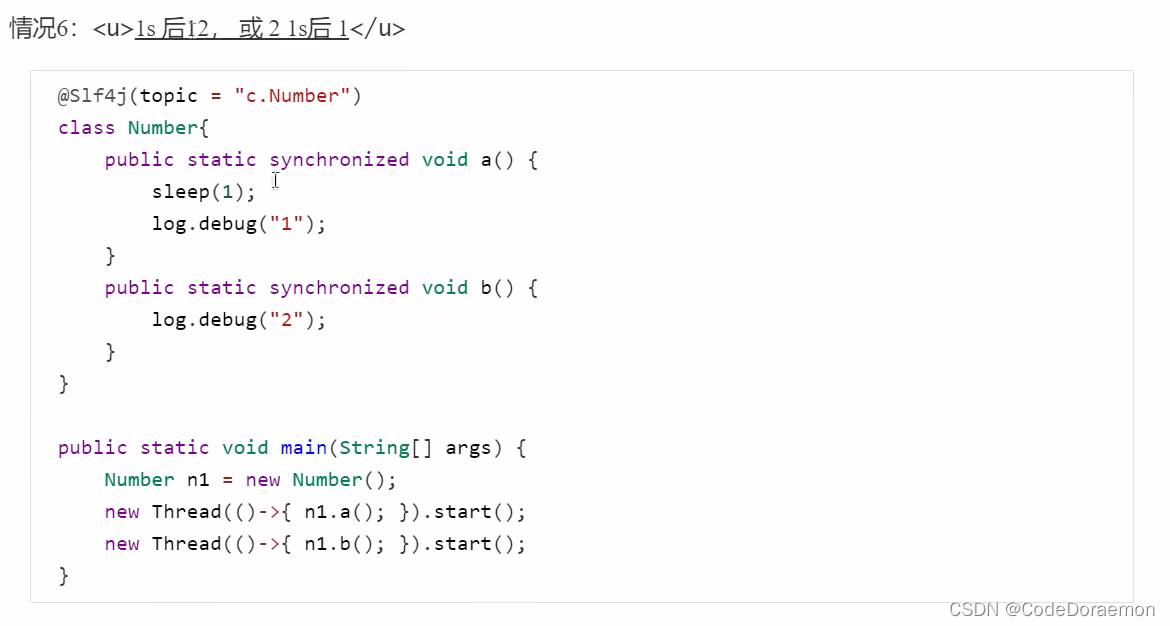
小结上面的 synchronized 的问题,就是先要清楚,获得的是什么锁,多个线程使用一把锁需要相互等待,使用不同的锁是不需要等待的;
一定需要分析是不是一把锁,是类锁还是对象锁,这个是十分重要的,并且锁的对象是不是同一个;
线程安全分析
变量的线程安全分析

局部变量的线程安全分析
下面的情况中,i 在栈中没有被共享,所示是不存在线程安全的问题的;
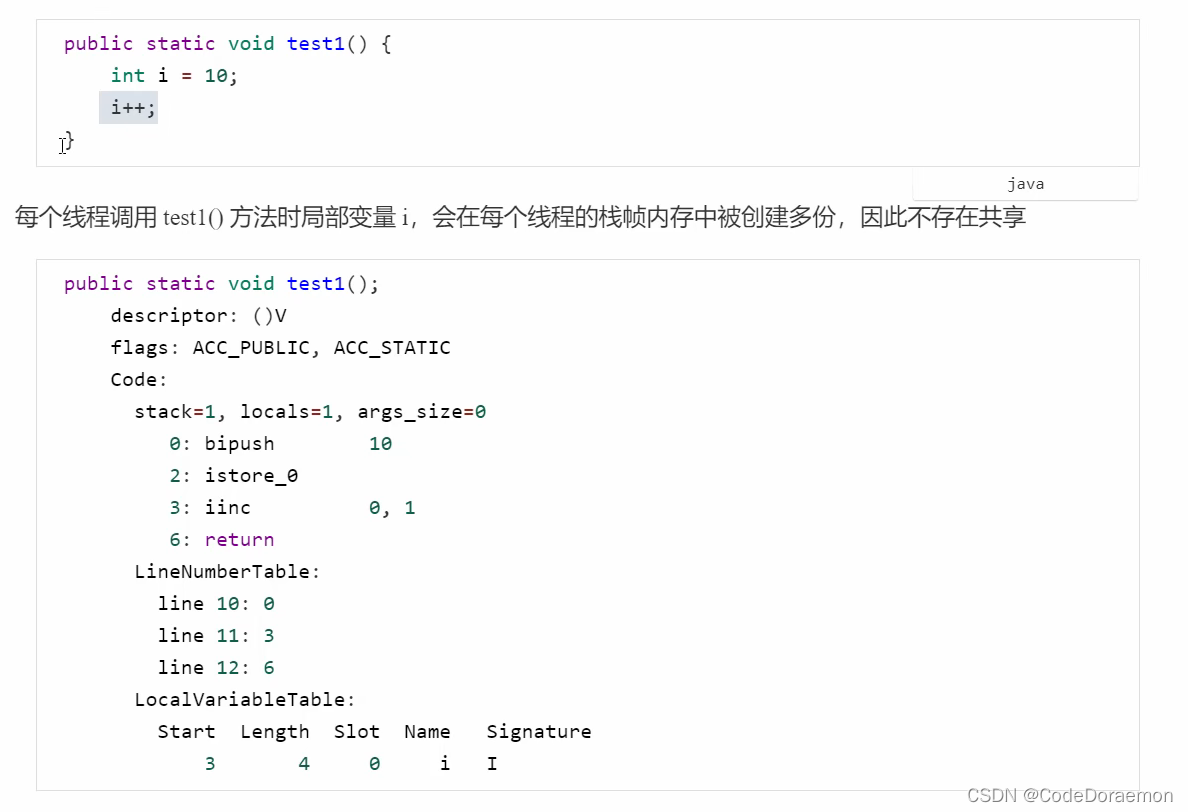
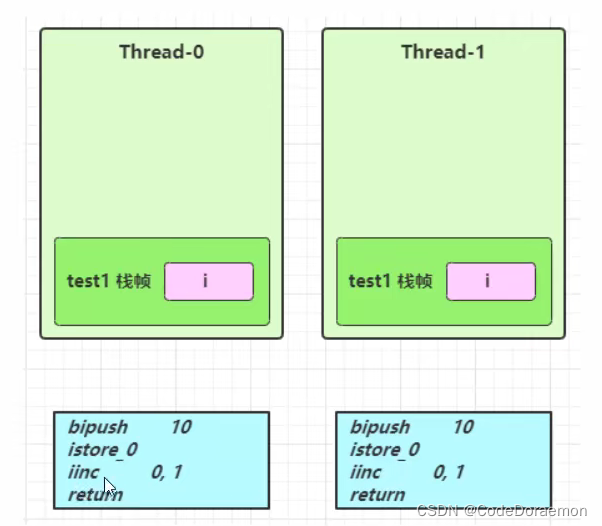
不存在线程安全的问题;
list 是成员变量
list 的创建在类的内部,引用关系,可能是下图所示:

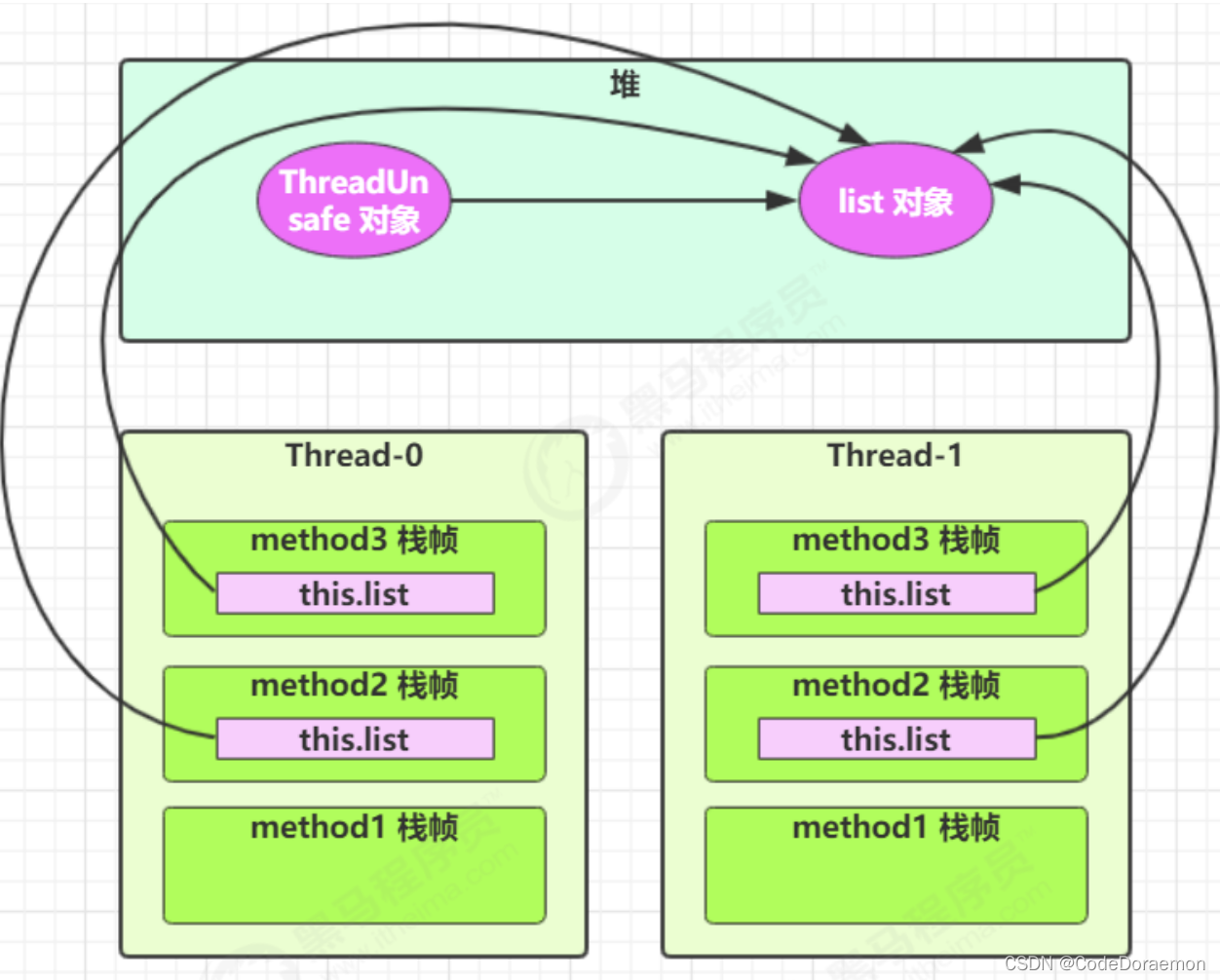
如果局部变量引用的是一个对象,那么可能产生线程安全的问题,因为对象是保存在堆内存空间的,可能导致堆内存共享,进而导致的线程安全问题;
list 是局部变量,局部创建出来的
list 也就是在 方法体重创建出来的;
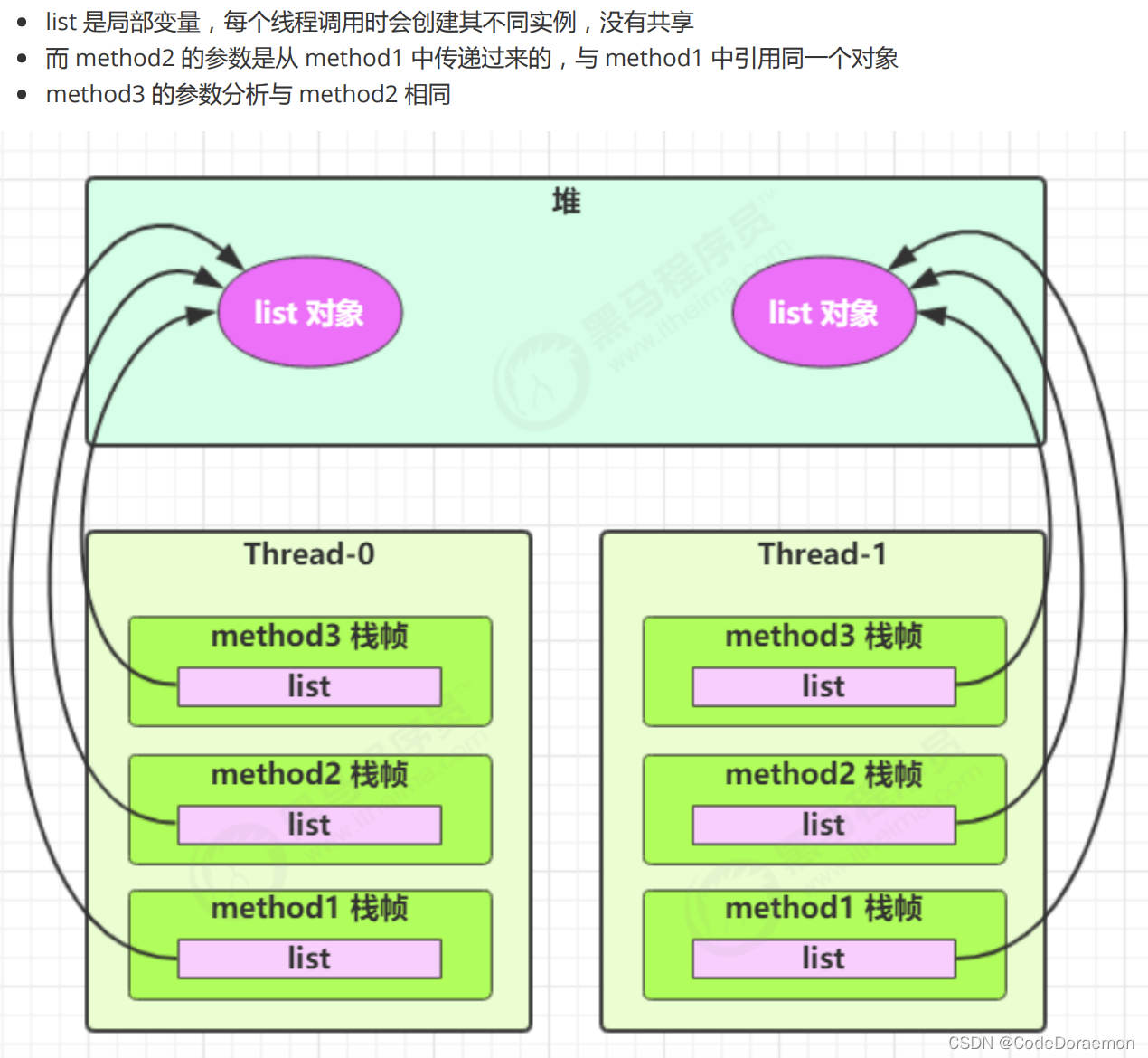
局部变量是引用的情况之下,如果这个引用是局部变量,也就是创建出来的对象是在局部中创建的,那么是没有线程安全问题的,
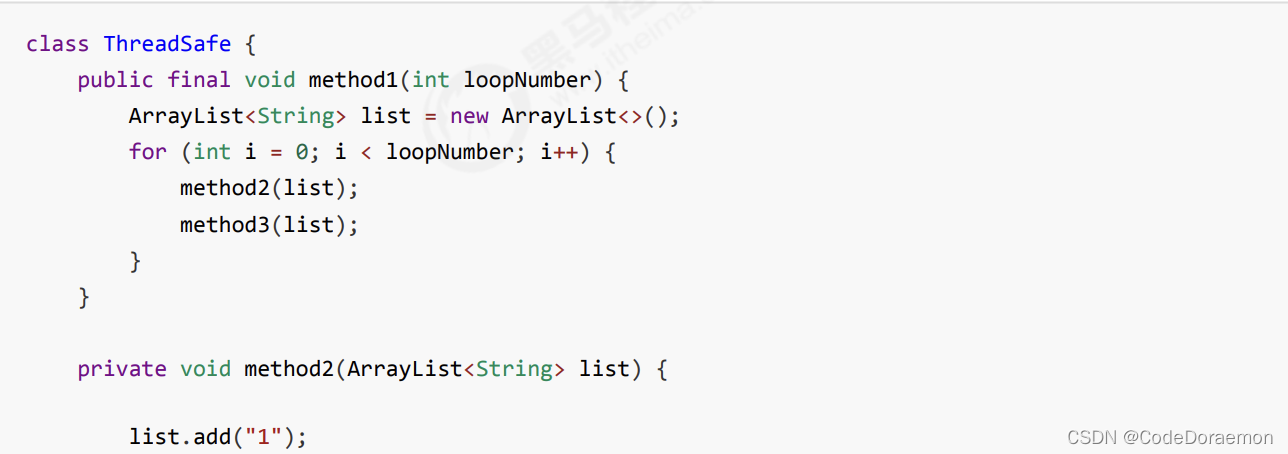

但是如果将局部变量的引用暴露出去,是有可能发生线程安全的问题的;
这个暴露出去指的是由于创建了子类,子类中开启了一个新线程,不能控制子类的行为,局部变量的引用可能同时被多个线程访问到,进而存在线程安全的问题;
privite 的方法在子类中是没有办法重写的,可以保护线程的安全;
防止子类进行方法的重写,可以在方法上面加上去 final;
加上去 final privite 可以起到一定的线程安全的作用;
常见的线程安全类的学习

需要注意两点:
1、方法是原子的
2、多个方法组合到一起不是原子的,因为多个方法的组合没有 sychronized 进行修饰;
下面的方法的组合使用,可能由于线程的上下文切换导致的线程安全问题的产生;

不可变类线程安全性
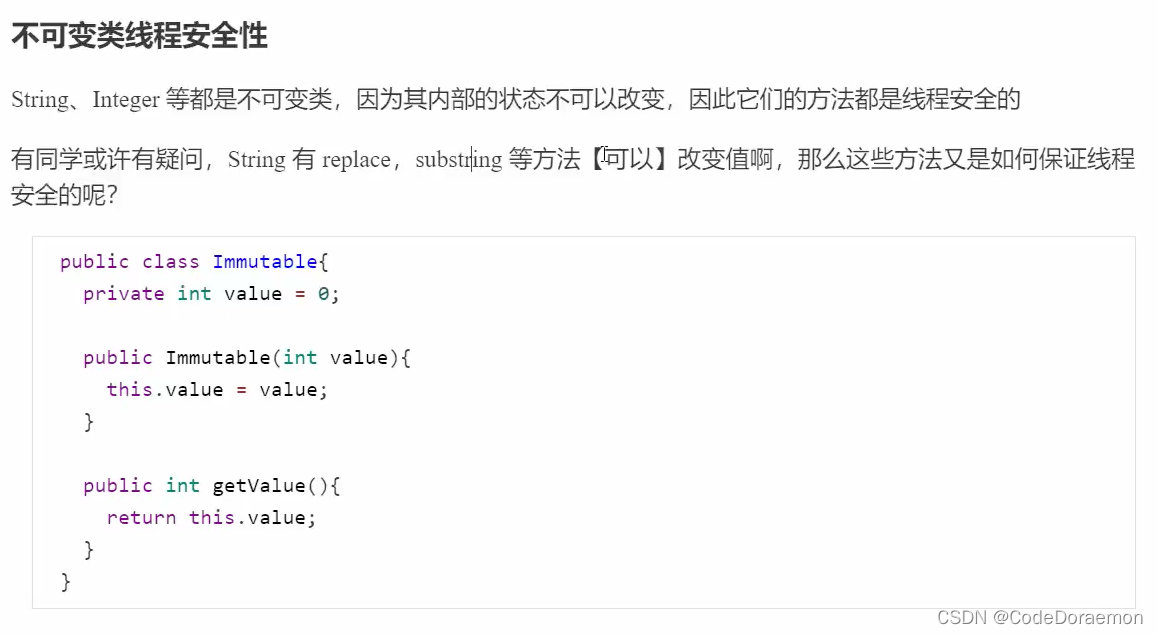
String 怎么保证线程安全的?
public String substring(int beginIndex, int endIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > value.length) {
throw new StringIndexOutOfBoundsException(endIndex);
}
int subLen = endIndex - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
return ((beginIndex == 0) && (endIndex == value.length)) ? this
: new String(value, beginIndex, subLen);
}
没有改变原来的 value 的数值,而是直接复制创建出来的新的字符串,所以说 String 是不可变的;
不可变类都是线程安全的,因为其值是不能被改变的,所以是安全的;
线程安全判断
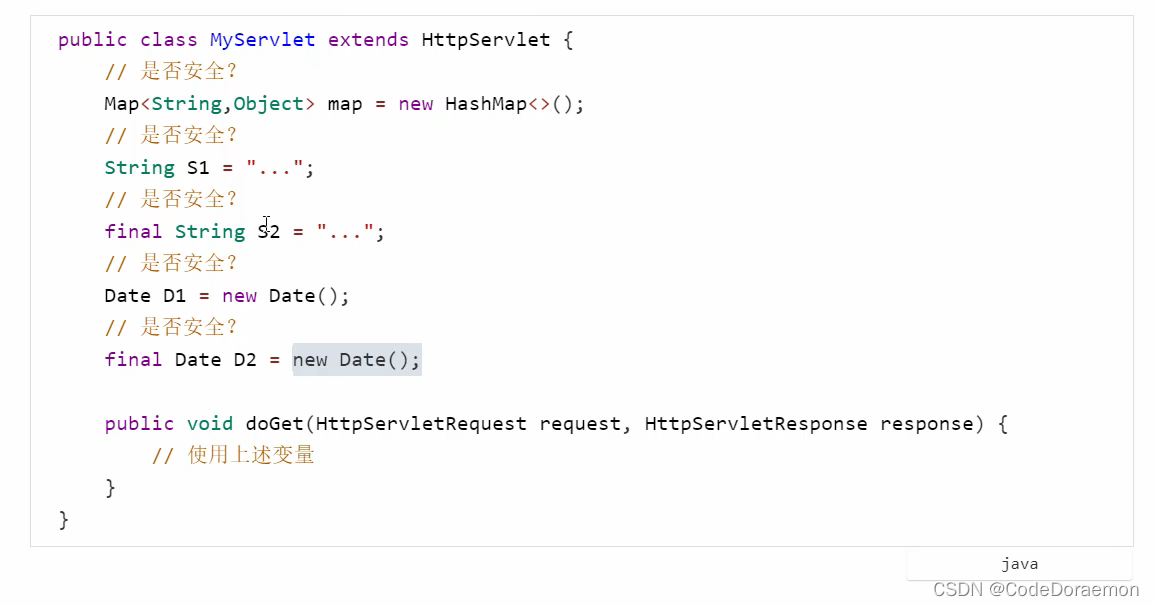
HashMap 不安全
Date 加不加 final 都是不安全的,因为日期会发生变化,加上去 final 只是说明了引用是不会发生变化的,里面的内容是有可能发生变化的;
属性可以修改的类产生的对象都是线程不安全的;

UserServiceImpl 都是线程不安全的;
因为里面的 count 属性是可以进行修改的,所以是不安全的;

存在线程安全,单例模式下面,会被多个线程访问,所以可能产生问题,牵扯到对象的成员变量的修改,就会产生线程安全的问题;
没有成员变量的类,一般都是线程安全的;观察里面的局部变量,方法内部的局部变量,
最好是将 Connection 变成私有的局部变量,而不是共享的成员变量;
使用 final privite 一定程度上面可以是线程安全的;
使用线程安全写一个简单的卖票程序
@Slf4j(topic = "c.ExerciseSell")
public class ExerciseSell {
public static void main(String[] args) throws InterruptedException {
// 模拟多个人同时进行买票
TicketWindow1 ticketWindow = new TicketWindow1(1000);
// 将所有的线程放到集合中
// 因为 这个 ArrayList 不会被多个线程进行访问,所以这里可以使用这个;
// 多线程下面就不能使用这个了
List<Thread> threadList = new ArrayList<>();
// 将卖出去的票放入到 List 里面,使用线程安全的 Vector
List<Integer> sellAmount = new Vector<>();
for (int i = 0; i < 200; i++) {
Thread thread = new Thread(()->{
// ticketWindow ticketWindow 是两个共享变量,所以不存在方法的组合之后就变得线程不安全
// 如果这两个变量是同一个变量的两个方法那么就会产生错误
int count = ticketWindow.sell(randomAmount(5));
sellAmount.add(count);
});
Thread.sleep(randomAmount(5));
threadList.add(thread);
thread.start();
}
// 将所有的线程添加到主线程中
// 将线程全部加入到主线程是为了得到所有线程的运行结果,使得线程安全,否则全部线程的运行结果可能出错
for (Thread thread : threadList) {
log.debug("当前线程是:" + thread.getName());
thread.join();
}
// 统计卖出去的票以及剩下来的票加起来等于 100000 说明是安全的;
log.debug("剩余的票是: " + ticketWindow.getCount());
log.debug("卖出去的票是 :" + sellAmount.stream().mapToInt(i -> i).sum());
}
static Random random = new Random();
// Random 返回伪随机数
public static int randomAmount(int amount) {
return random.nextInt(amount) + 1;
}
}
class TicketWindow{
private int count;
public TicketWindow(int count) {
this.count = count;
}
public int getCount() {
return count;
}
// 关于卖票 这个一定是需要是线程安全的;
public synchronized int sell(int amount) {
if (this.count >= amount) {
this.count -= count;
return amount;
} else {
return 0;
}
}
}
***深入学习 synchronized 底层 - Monitor 概念
32 位虚拟机中
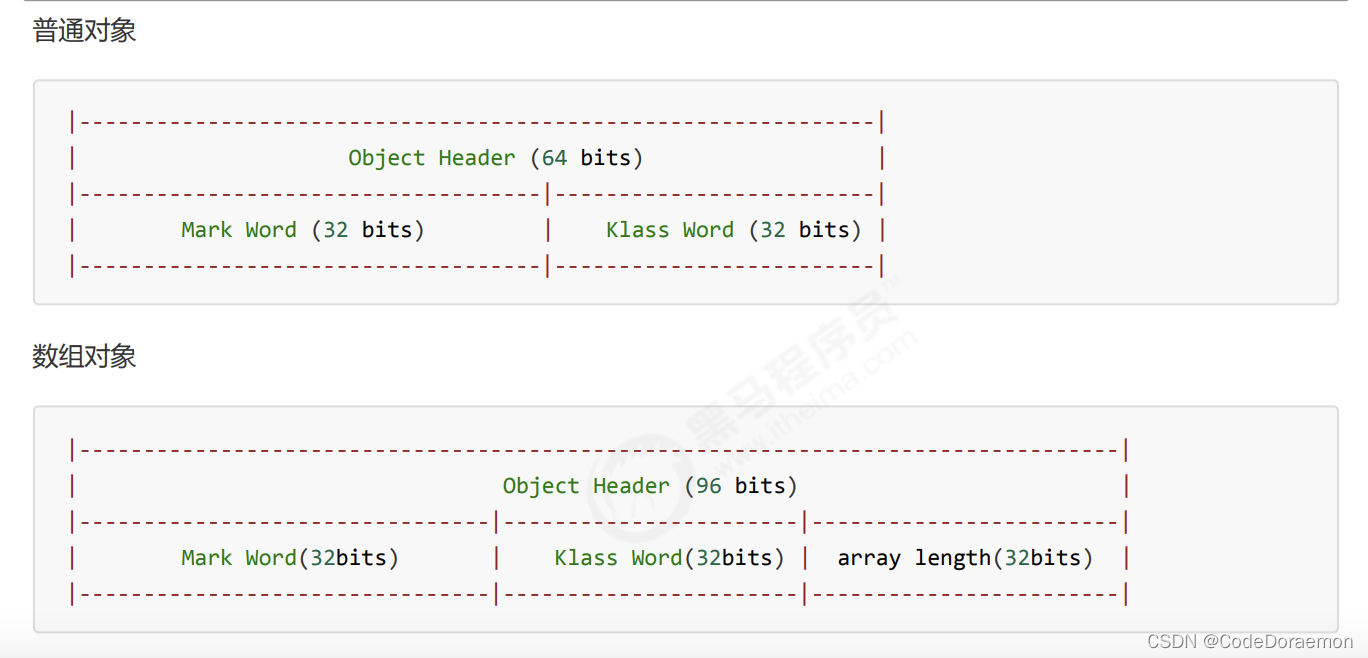
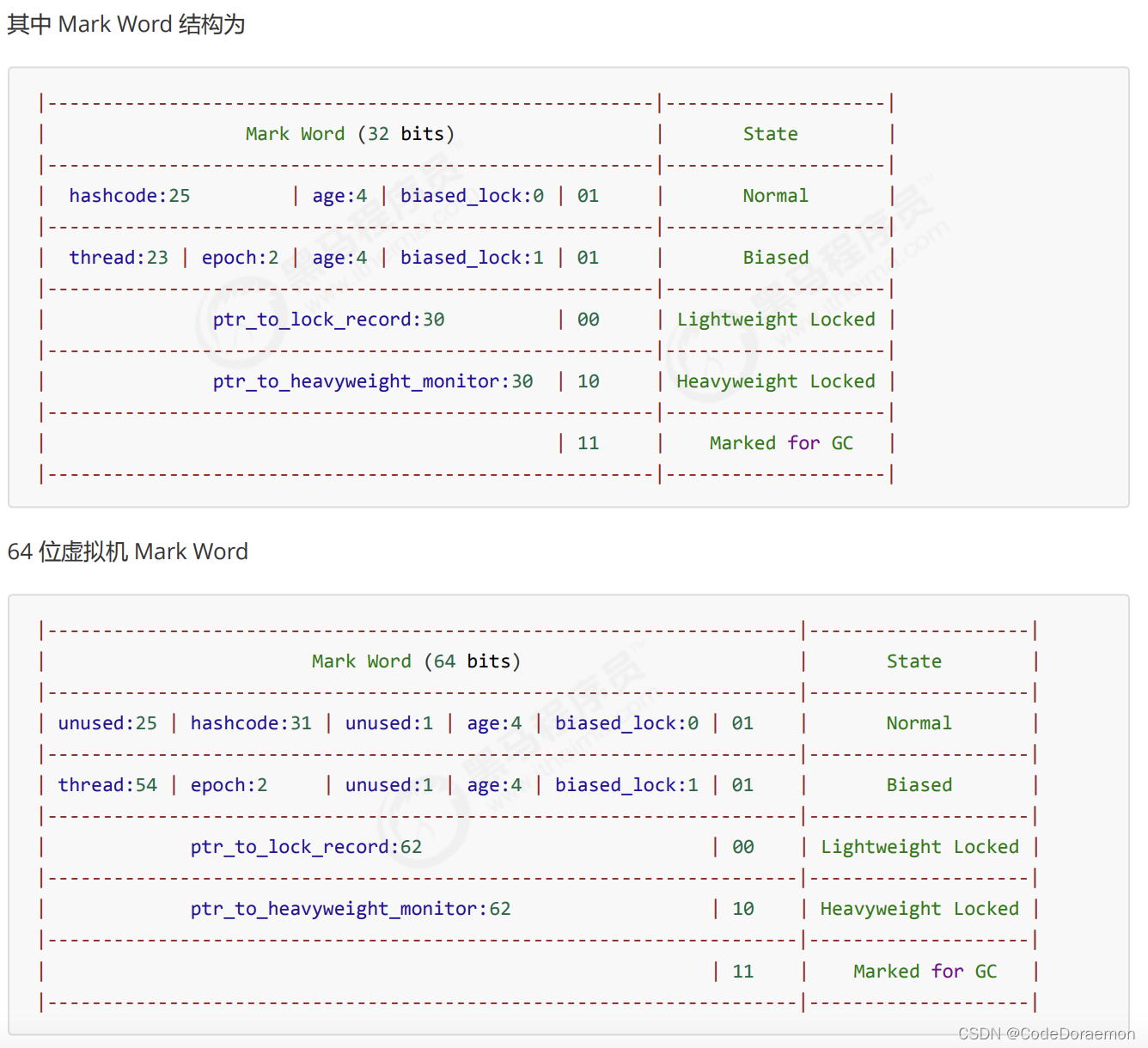
Monitor 在底层就是一个锁 翻译叫做监视器或者管理;
每个 Java 对象都是可以关联一个 Monitor 对象的;
- 当一个线程访问临界区代码块的时候,它是第一个访问这个临界区代码块的,他这个时候会获得 obj 对象对应的监视器 Monitor ,获得之后就会一直占有 这个 obj 的锁,这个进程与 Monitor 的 Owner 进行关联;后面进来的 Thread-1 Thread-3 ,由于没有锁,所以只能进入等待的状态,也就是阻塞状态 BLOCKED;
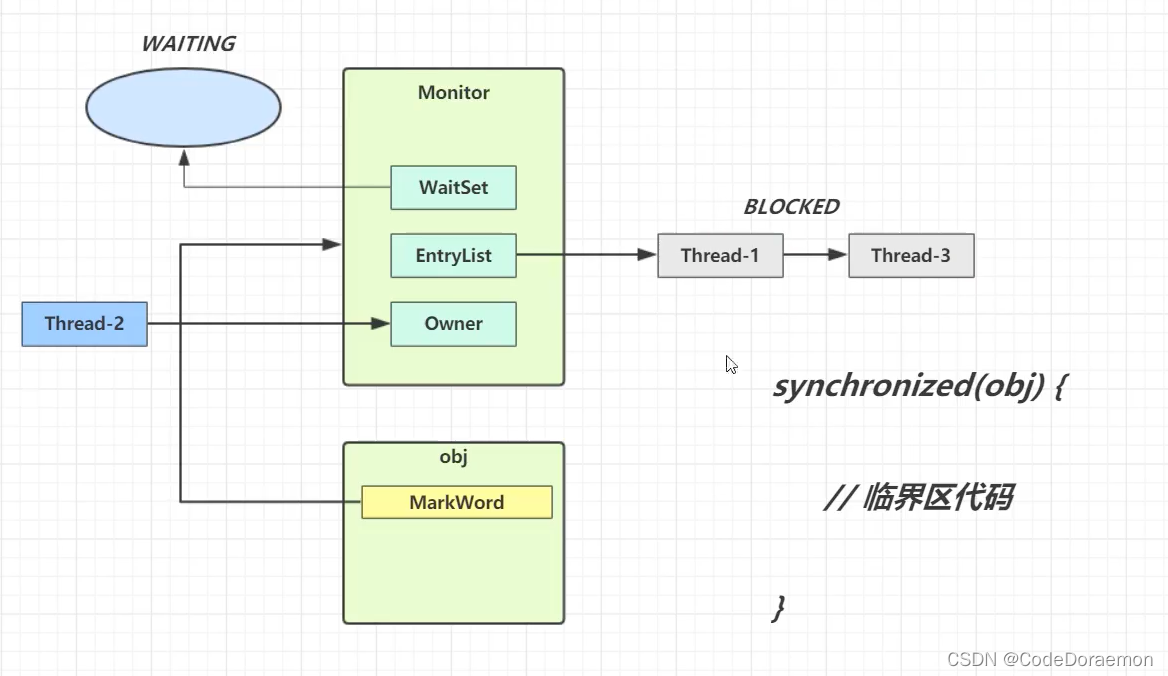
Thread-2 执行结束之后,就会将 Owner 空出来,让等待队列的 Thread-1 Thread-3 的一个叫醒,然后竞争
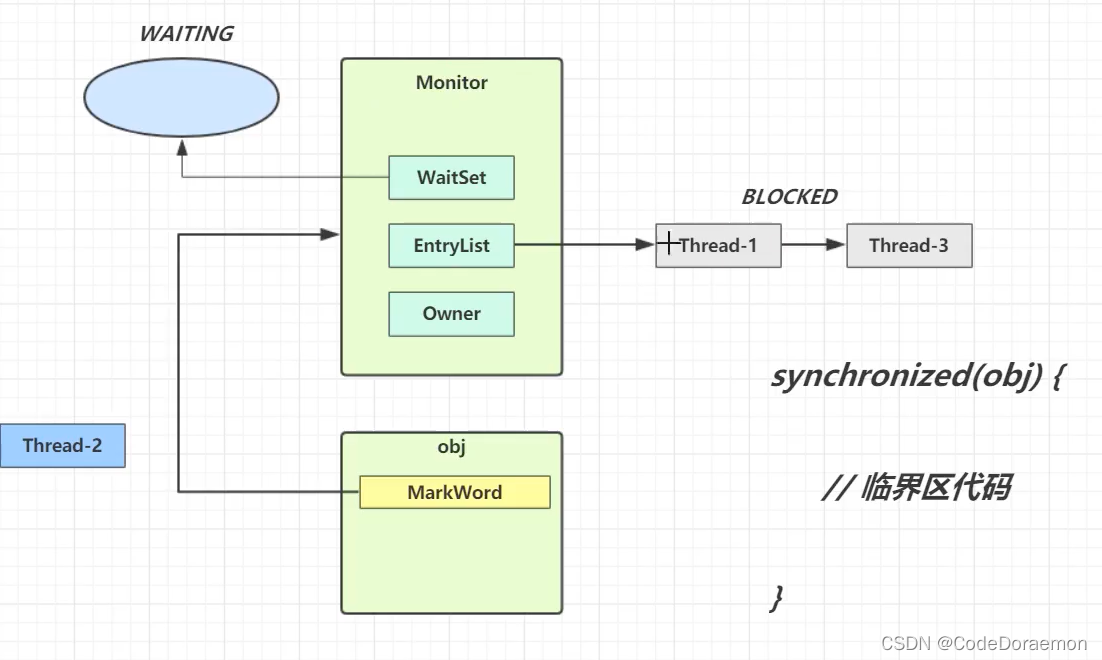
竞争之后,假设 Thread-3 获得了锁,然后 Thread-3 继续等待,具体什么线程会获得锁,根据 JVM 的具体实现即可判断;
竞争一般是非公平的;
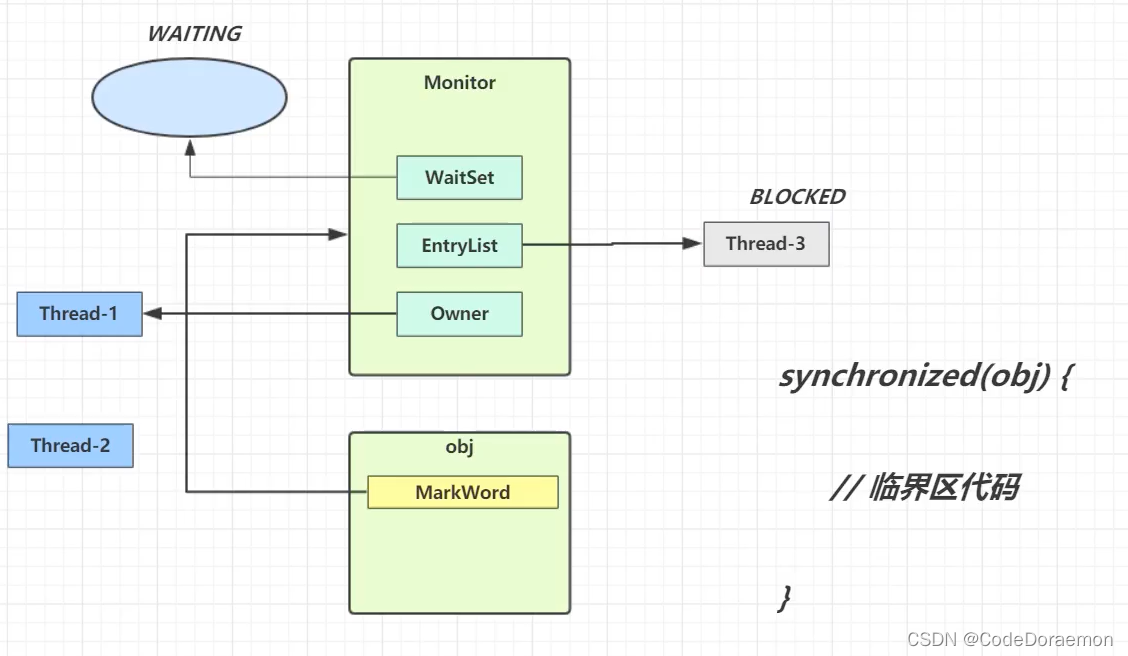
Monitor 总是会充当一个锁的角色,因为对象会与锁进行关联;
同一个对象会和同一个 Monitor 之间进行关联
上面执行过程的小结
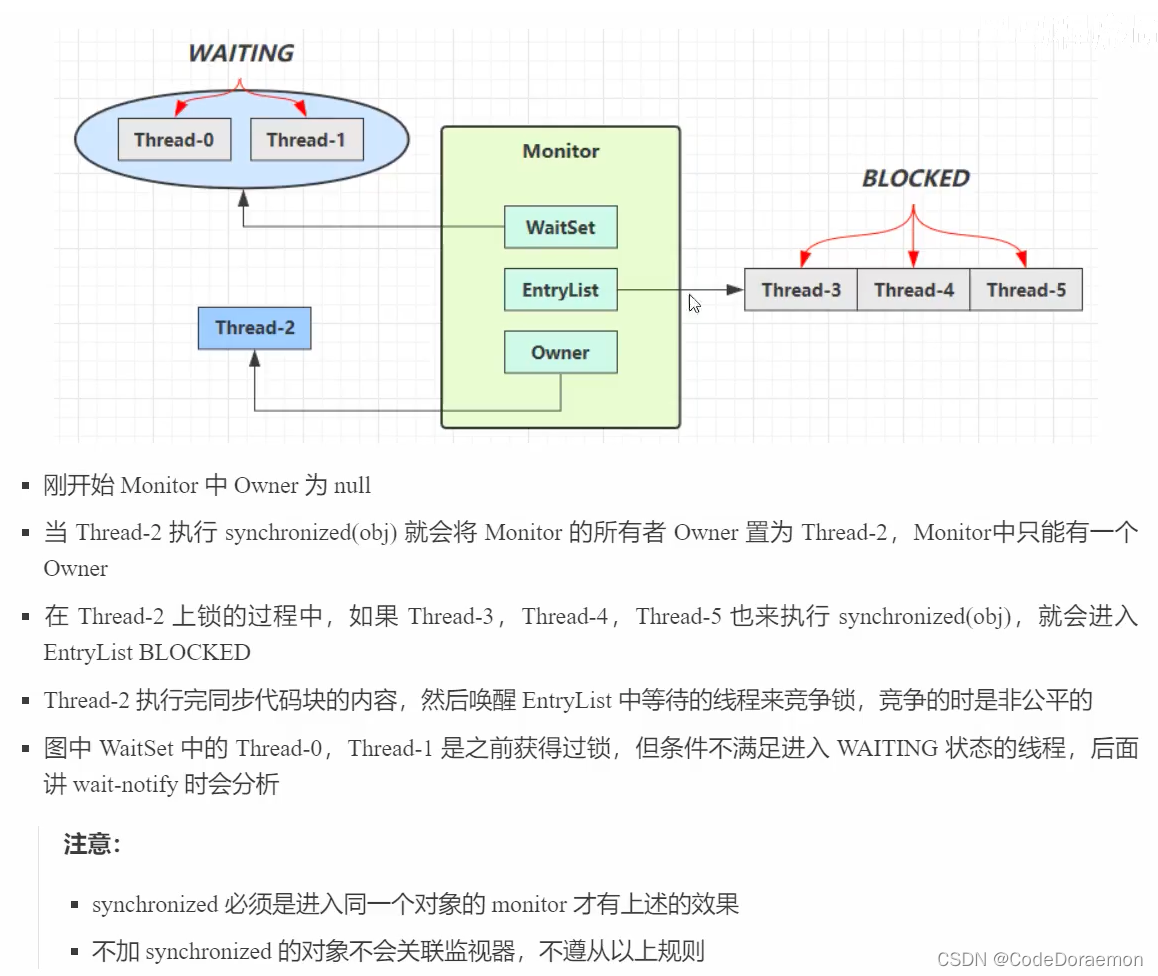
注意:
1、 synchornized 必须进入同一个对象的 Monitor 才会有上面的效果,进而实现线程安全
2、不加 synchornized 的对象不会关联监视器,是不会遵守上面的规则的;
***从Java 字节码的角度学习 Monitor
原始的 Java 代码

反编译之后的字节码指令
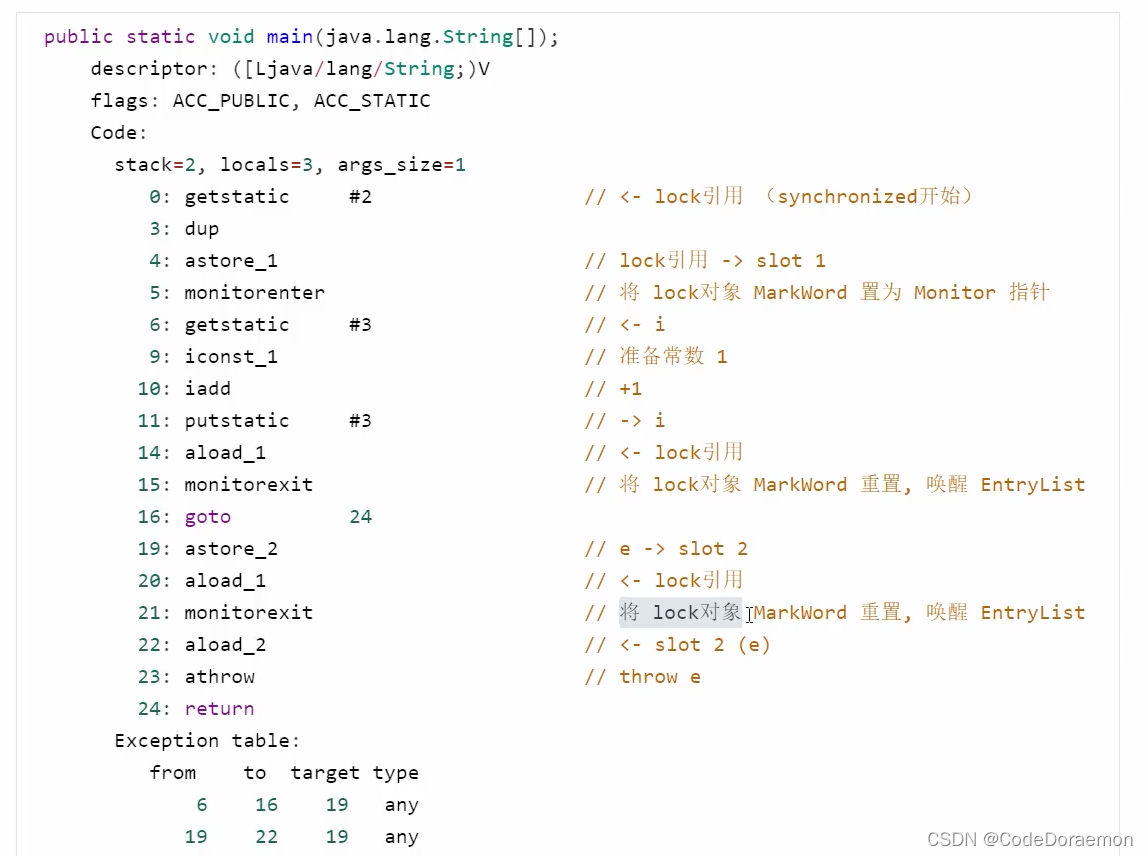
public class com.luobin.concurrent.Test20 {
static final java.lang.Object lock;
static int counter;
public com.luobin.concurrent.Test20();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Code:
0: getstatic #7 // Field lock:Ljava/lang/Object;
3: dup
4: astore_1 // 记录 Owner指向的指针
5: monitorenter
6: getstatic #13 // Field counter:I
9: iconst_1
10: iadd
11: putstatic #13 // Field counter:I
14: aload_1
15: monitorexit
16: goto 24
19: astore_2
20: aload_1
21: monitorexit
22: aload_2
23: athrow
24: return
Exception table: // 发生异常的话执行 19 -22 正常执行 6 - 16
from to target type
6 16 19 any
19 22 19 any
static {};
Code:
0: new #2 // class java/lang/Object
3: dup
4: invokespecial #1 // Method java/lang/Object."<init>":()V
7: putstatic #7 // Field lock:Ljava/lang/Object;
10: iconst_0
11: putstatic #13 // Field counter:I
14: return
}
synchronized 使用的重量级锁的优化
由于重量级锁的加上去,导致系统的整体的运行效率是比较低下的,这个时候进行优化,提出来了轻量级锁,偏向锁等概念;
轻量级锁优化实现对重量级锁的优化
使用轻量锁的核心是,虽然是多线程可以进行访问,但是访问的时间是错开的,可以使用轻量锁;
轻量级锁失败之后,会加上去一个重量级锁;

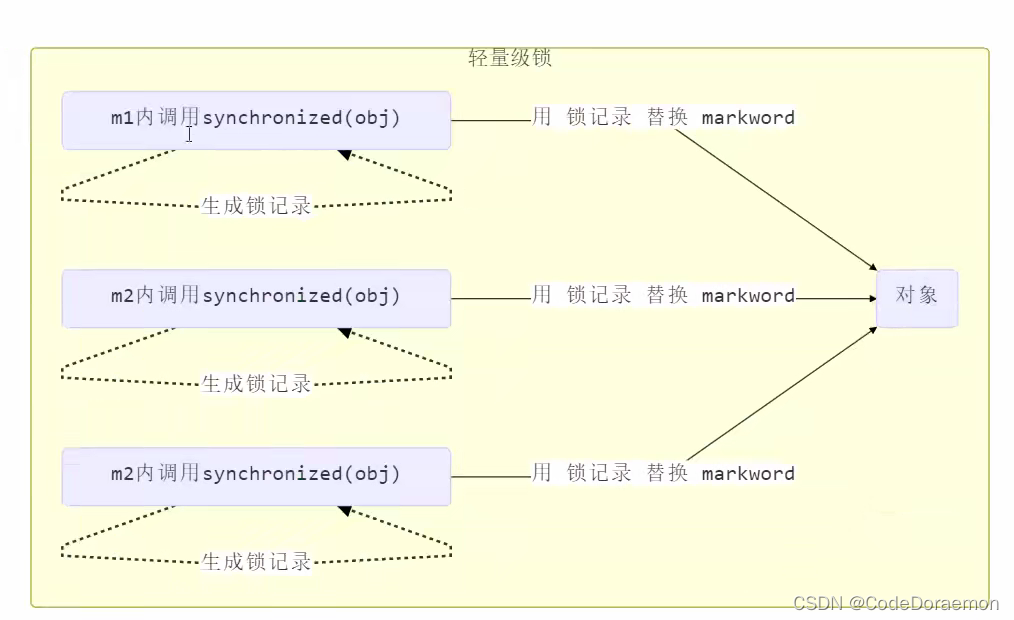
轻量级锁的实现原理
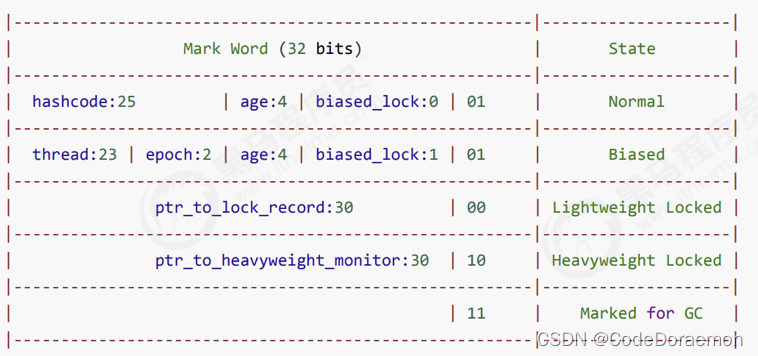
Object(这个对象用来充当锁,也就是 synchornized 里面锁住的对象,在底层这个对象会和Monitor进行关联) 里面存在对象头,对象体;
Lock Record 里面保存锁对象 Object 的引用地址以及 要加锁的对象的 MarkWord(在对象头里面)(Mark Word 的介绍上面存在的)
创建的锁记录对象不是 Java 层面的,是 JVM 层面创建的;
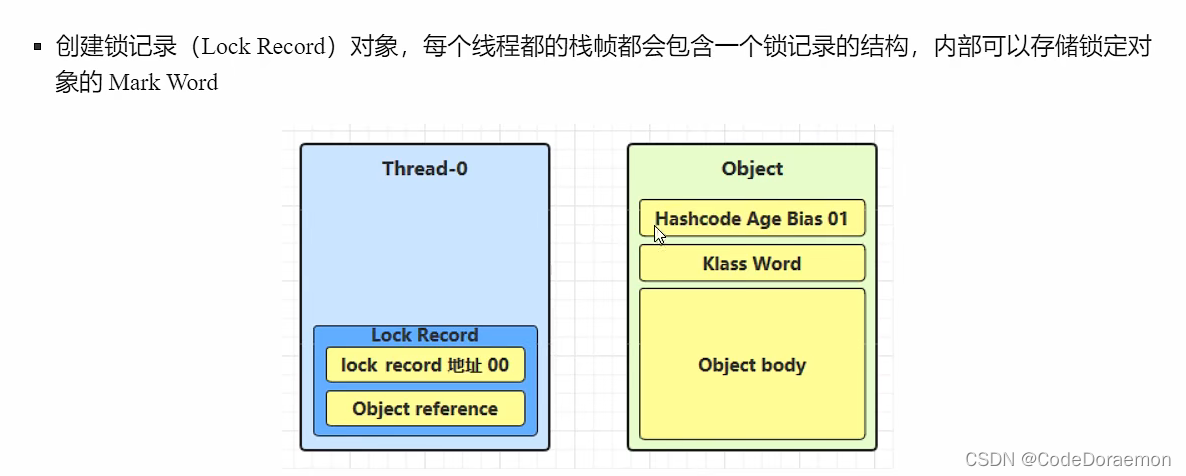
尝试将锁记录进行替换,从(01)无锁状态替换为轻量级锁;
原来的创建出来的对象(Object)的锁从 01(无锁) 变为了 00 变成了轻量级锁;
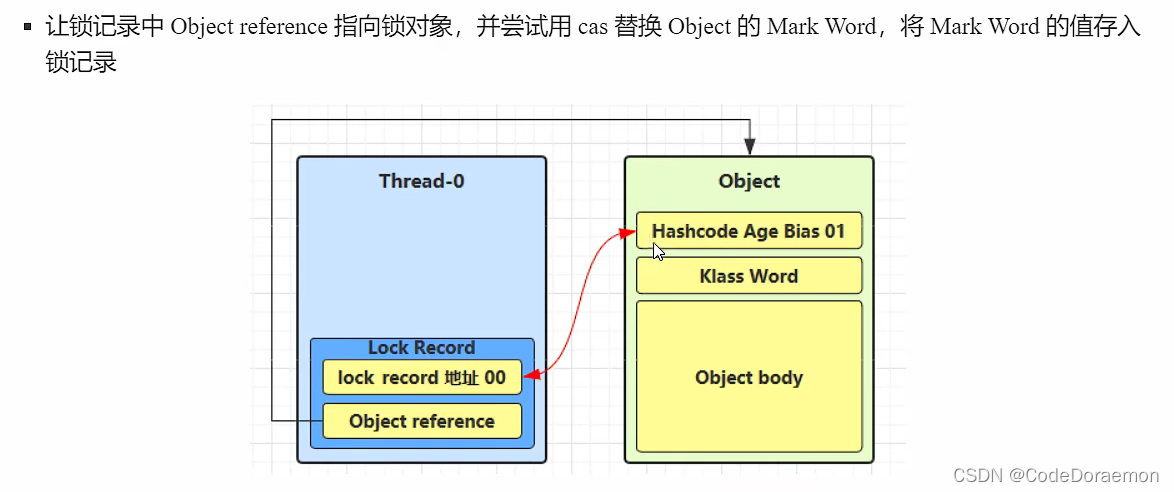
转换成功表示的是:从无锁的状态 01 转换到了轻量级锁状态 00
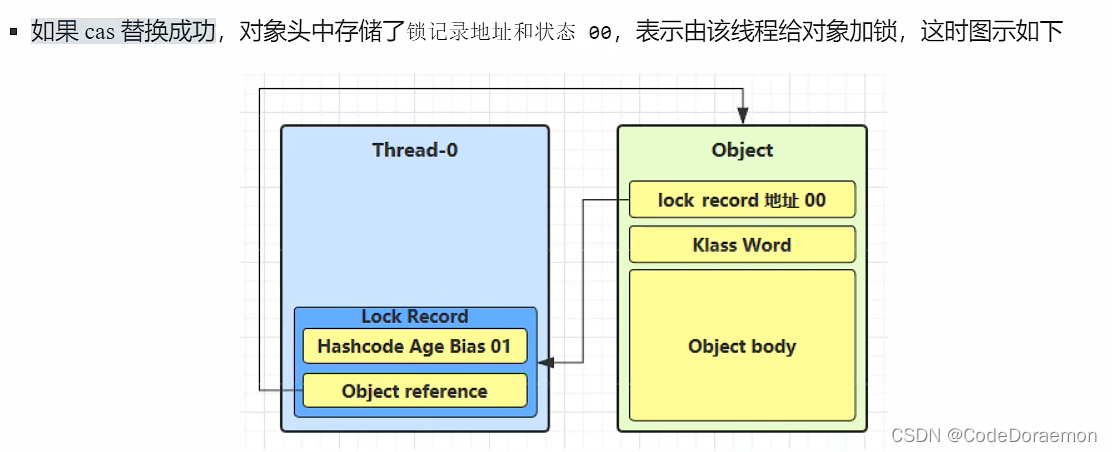
可以观察到的是:Lock Record 对象里面的第一行的数据和 Object 对象头中的数据进行了交换;达到了加上去轻量级锁;
cas 操作,保证交换的过程是原子性的,保证同时成功或者同时失败;
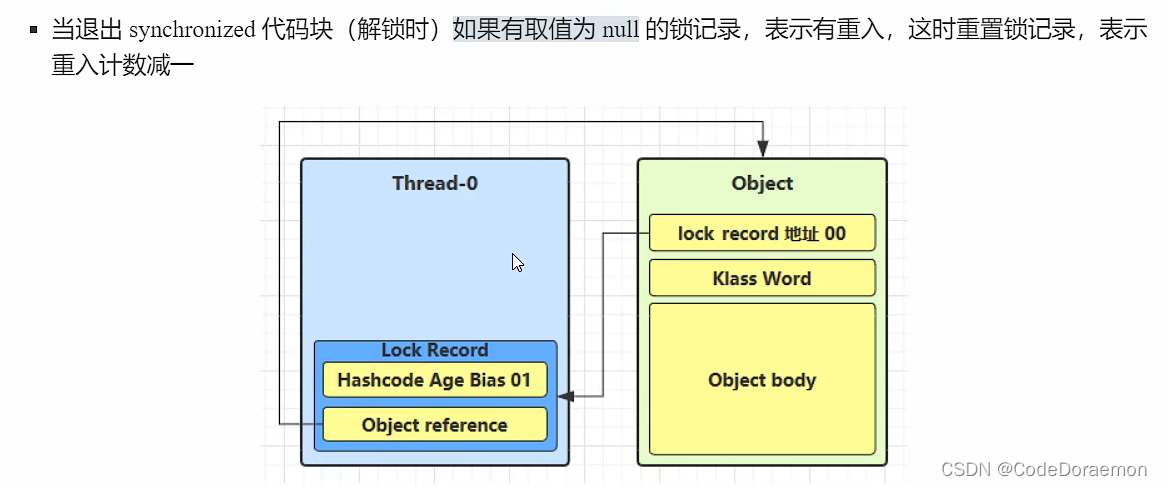
如果是自己再次进行了锁重入,加一个 Lock Record 作为重入的计数;
这个时候的 cas 交换是不会成功的,因为他自己拿着锁,在上一个 Lock Record 对象中;
锁记录可以看出来,对于同一个对象加了多少把锁;
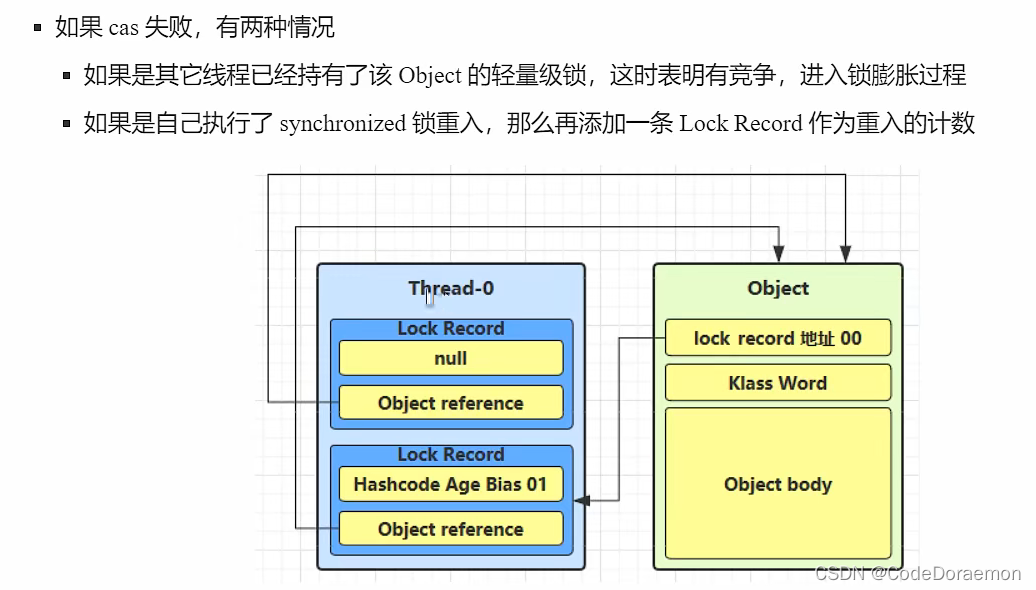

锁膨胀
在尝试加上去轻量级锁的过程中, CAS 操作无法完成,这个时候可能就是因为其他的线程为这个对象加上去了对象锁,存在了竞争,这个时候便产生了锁膨胀,此时需要将轻量级锁转换为重量级锁;
加锁的目的,锁的转换的目的就是一方面保持着一定的性能,另外一方面考虑到线程安全的问题;
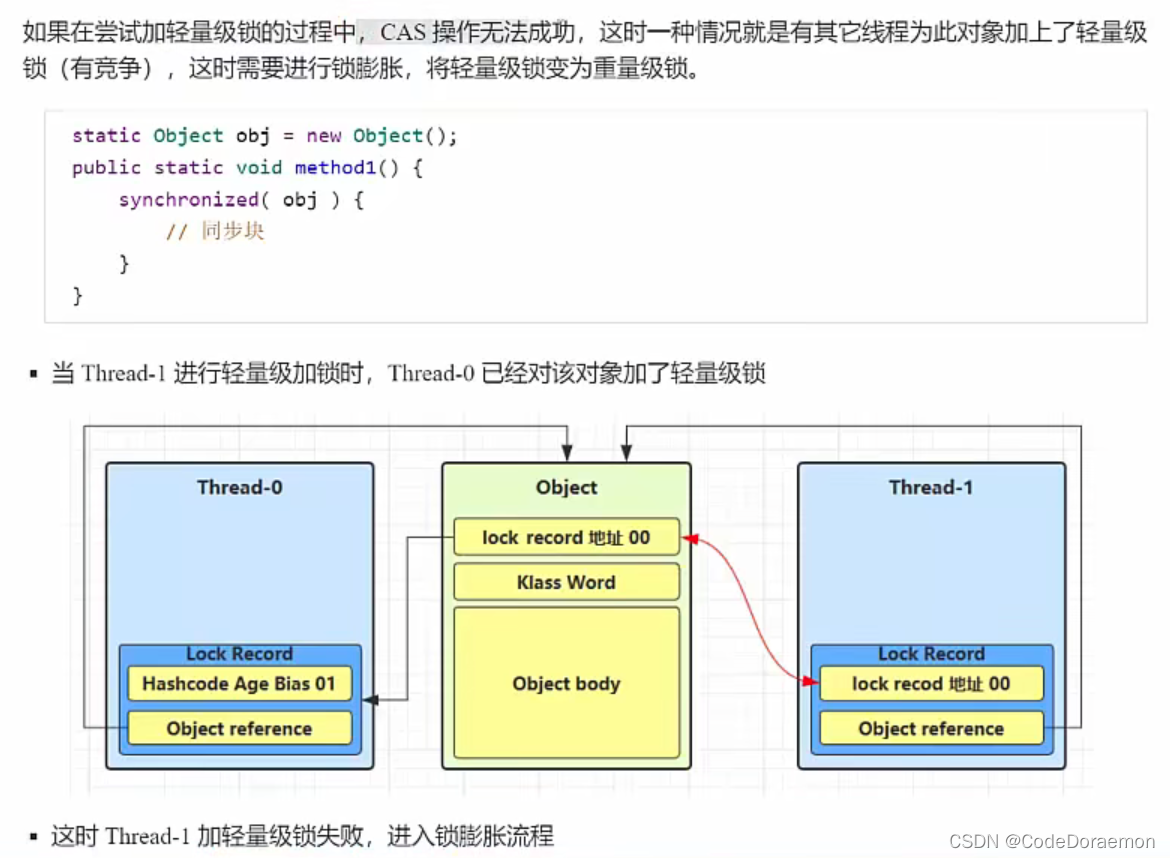
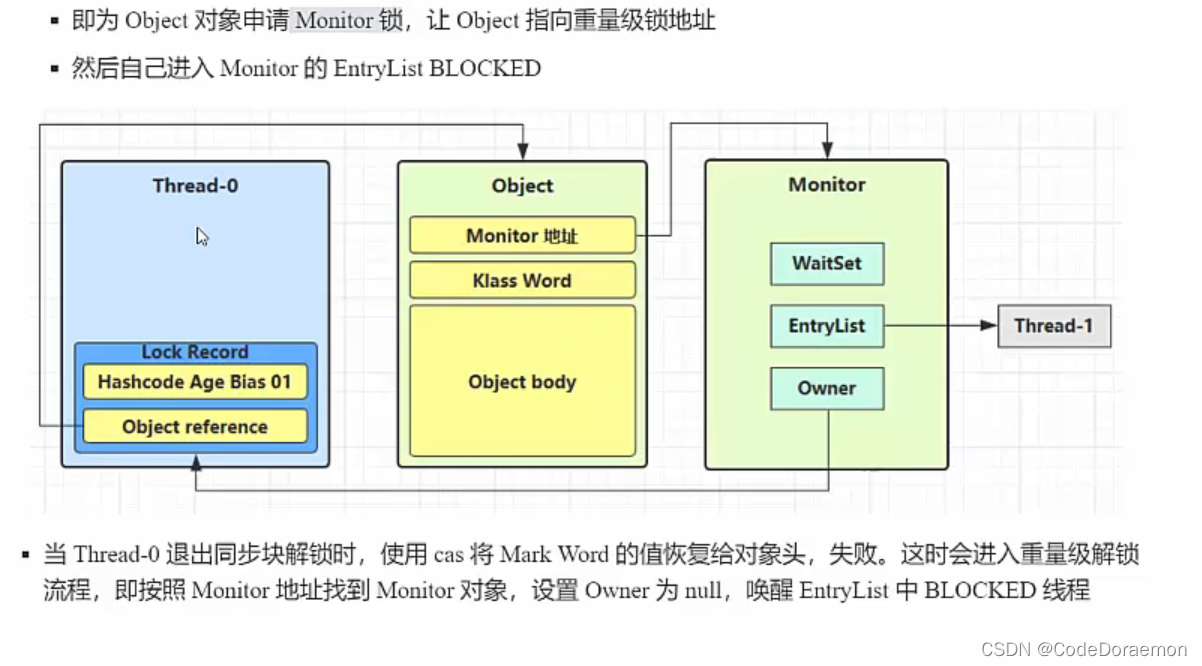
这个时候,这个 object 对象就会加一个重量级别的锁,此时 Monitror 才会和这个 Object 进行关联,新进来的线程就可以到 EntryList 进入等待的状态,找了一个休息的地方;
如果没有将轻量级锁转换为重量级锁,那么新进来的线程就没有地方去了,但是这个线程还是需要运行的,所以不得不转换成重量级锁;
Monitor 地址后两位变成了(10) 也就是变成了重量级锁;
自旋操作实现优化重量级锁
当重量级锁在竞争的时候,可以使用自旋来进行优化,如果当前线程自旋成功(也就是持有锁的线程已经退出了同步块,释放了锁),这个时候就可以避免阻塞,避免了阻塞之后,在多核 CPU 下面可以提升性能;
没有优化之前,一个线程成为了 Monitor 的Owner ,其他的线程想要访问的时候,需要进入到 EntryList 进行阻塞等待,直到当前线程释放了锁,他才会被唤醒,可能执行自己的相关内容;
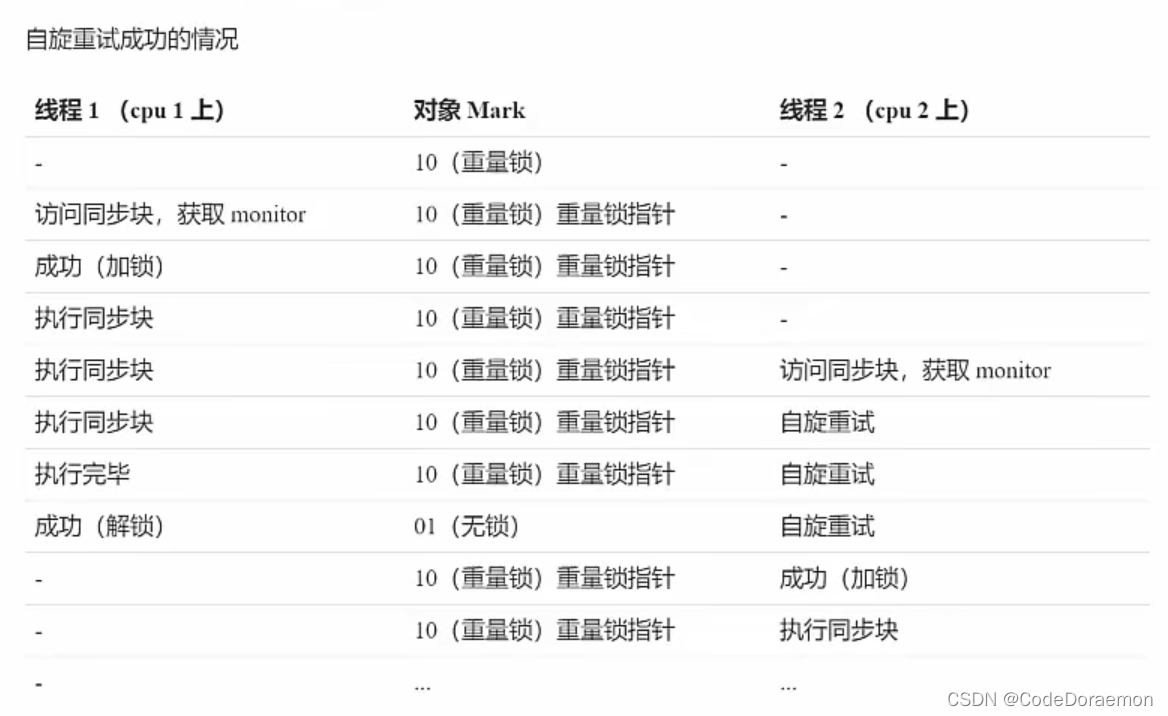
所谓的自旋,就是先不要直接进入阻塞的链表中,先尝试看当前线程有没有释放锁,释放之后,直接执行自己的代码块,不要进入阻塞链表,减少的线程的唤醒次数,可以节约性能;
自旋的操作,适合多核 CPU ,是不适合单核 CPU 的;单核下面是没有意义的;
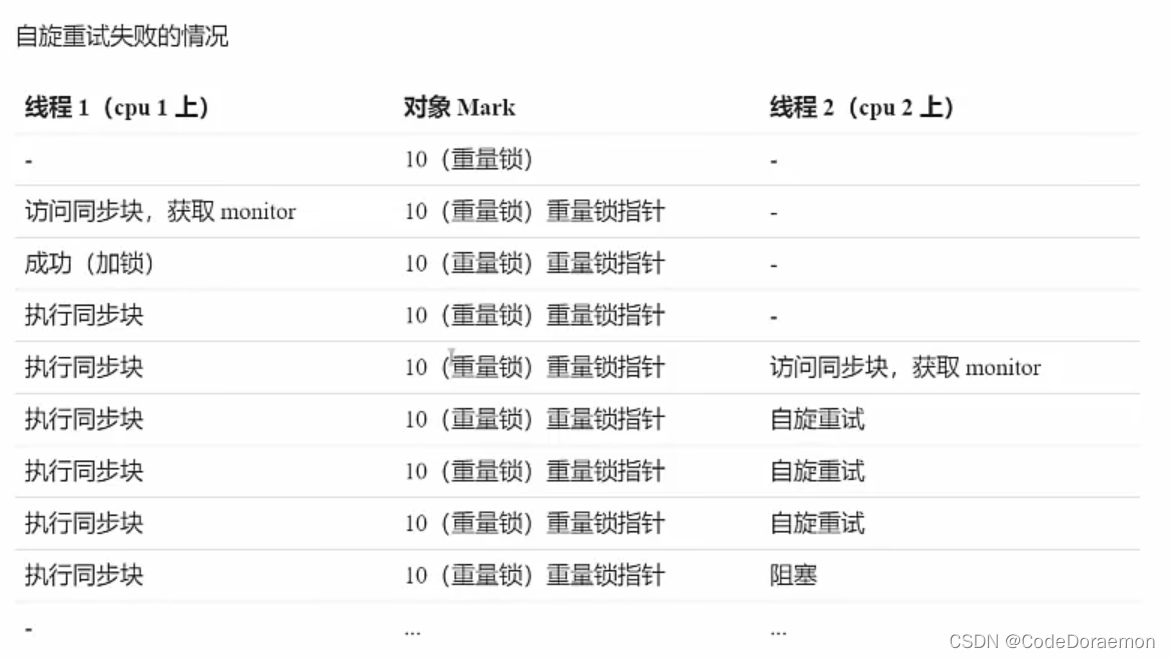
当进行了几次的自旋之后,还是不能执行自己的线程,那么就进入阻塞状态;
在 Java 的底层中,自旋是没有办法控制的,底层的自旋是比较智能的,自适应的;比如对象刚刚的一次自旋成功了,后面这个线程访问的时候,自旋成功的可能性就会大一些;反之,可能少自旋或者不自旋;
自旋本身是会占用 CPU 时间的,单核下面是浪费时间,多核 CPU 才能发挥优势;
Java 7 以后不能控制是不是开启自旋功能;
偏向锁实现优化轻量级锁
轻量级别锁在没有竞争的时候(只有当前线程一个线程),每次的重入仍然是需要 cas 操作的,每次都执行 cas 操作是比较消耗资源的,这个时候考虑到使用偏向锁进行优化了;
偏向锁:只有第一次使用 cas 线程将线程 ID 设置到 Mark Word 的头部,之后发现这个线程的 ID 是自己,还是自己的重入,那么就不用实现 cas 操作了,之后不发生竞争,这个对象就归线程所有,减少了 cas 执行的次数,提高了运行效率;
这个时候在锁对象的头部分设置的是 线程 ID ,不是下面这 5 行里面的任意一行数据了,以前的轻量级锁是下面 5 行中的 第三行:Lightweught Locked;
换成ID 就是为了识别达到减少 cas 操作;
以后这个对象偏向于当前线程,起名曰偏向锁;
这个 cas 操作指的是 Lock Record 里面的地址和 Object Head里面 的Mard Word 内容进行交换,偏向锁可以减少这个交换;
下面表示的轻量级锁的每次对于这个 Object 的访问,每次都是需要 cas 操作的
下面的这个是使用了偏向锁的对于 Object 的访问,第一次的使用,将线程ID 放到对象的头部,以后访问直接看是不是同一个线程访问,是同一个线程访问的话,就不需要 CAS 操作了;
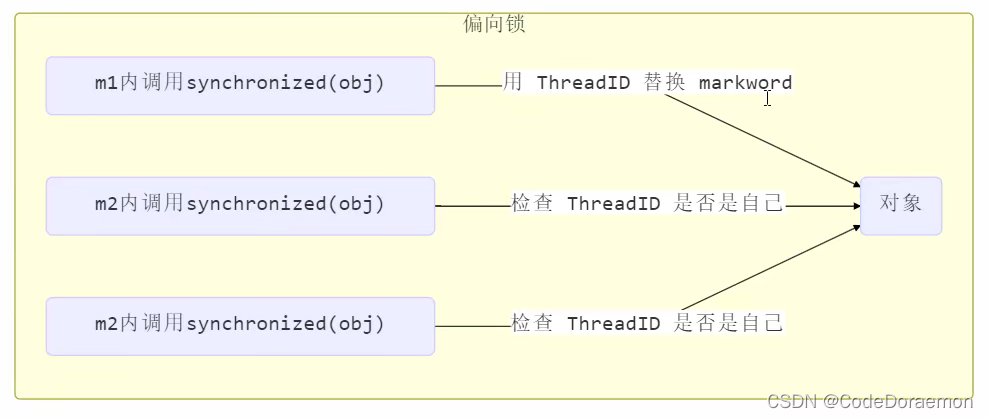
偏向锁的使用场景:只有一个线程使用的时候或者在冲突比较少的时候,使用偏向锁比较好,因为可以减少 CAS 的操作;
但是在多线程下面,不并且经常的伴随着锁的相互竞争,使用偏向锁是不太好的;
Java 程序启动的时候,Java 中可以禁止使用偏向锁的使用,在多线程的时候,一上来就是正常对象,可以设置禁用;默认是启用偏向锁的;
使用锁的顺序是:偏向锁 -> 轻量级锁 -> 重量级锁(自旋锁可以优化)
偏向锁的撤销
1 为什么调用了充当锁的对象的 hashCode 之后会禁用偏向锁? 101 -> 001
可偏向的对象调用了 hashCode() 之后,由于字节占满了,导致偏向锁失效;
原来的 64 位在下面的对象头中,hashCode 占用 31 ,但是如果把 hashCode 加入到对象头中,超过了 64 位,所以取消了偏向锁,保持 hashCode 可以保存进去;没有地方存储 hashCode 只能放弃偏向锁;

轻量级锁以及重量级锁都有额外的空间,可以存储 hashCode ,但是偏向锁是没有的,所以放弃了偏向锁;
2 其他线程使用偏向锁时候,偏向锁升级为轻量级锁
设置案例的时候,两个线程访问一个锁对象,需要错开调用,否则直接将锁转换为重量级锁,是不对的;
错开之后,偏向锁会升级为轻量级锁;
01 轻量级锁;
00 偏向锁;
10 重量级锁;
偏向锁的重偏向
对象被多个线程访问,但是访问之间是没有竞争的,会发生取消对当前线程偏向,重新偏向当前线程的操作,这个操作多了之后,对于系统性能的损耗还是比较大的,这个时候会考虑到是不是偏向错了;
这个时候会偏向到新的线程,减少系统的消耗,偏向给原来的线程,但是它来时反复跳,超过了容忍(阈值),换一个线程进行偏向,对于后面的线程进行批量的偏向,减少加锁,解锁之间的消耗;

偏向锁的批量撤销偏向
达到撤销的阈值之后,偏向锁会进行批量的撤销;

锁消除
JIT 会对热点代码进行优化处理,默认是打开的状态,这个时候在循环一定的次数的情况下,加不加 synchronized 结果是差不多的;
当把这个热点代码优化的开关关闭之后,不进行优化,加不加 synchronized 的效果是比较明显的;
所谓的锁消除的优化就是:
将 synchronized 里面的代码块进行优化处理,提高性能,当这种锁消除优化关闭之后,性能的差距是十分明显的;所以还是使用默认的锁消除优化比较好,在一定程度上;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号