pandas常用方法
安装方法
pip install pandas
Series没有列索引
series只有行索引,没有列索引
传参方式
- 列表、元组、array都可以直接传参
import pandas as pd
import numpy as np
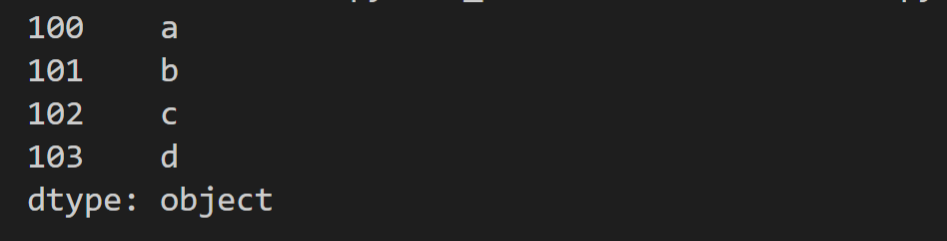
data = np.array(['a','b','c','d'])
#自定义索引标签(即显示索引)
s = pd.Series(data,index=[100,101,102,103])
print(s)
效果如图:
- 通过字典传参
import pandas as pd
import numpy as np
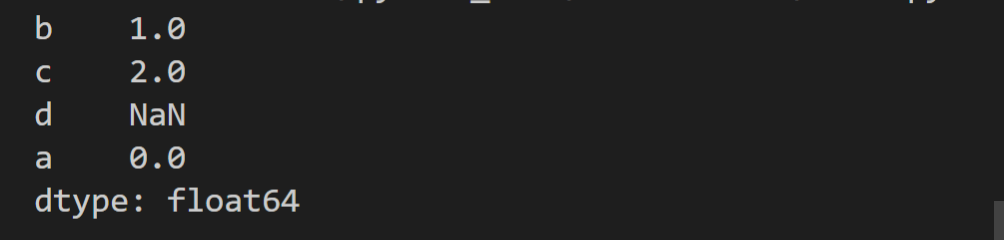
data = {'a' : 0., 'b' : 1., 'c' : 2.}
s = pd.Series(data,index=['b','c','d','a'])
print(s)
效果如图:
取值方式
import pandas as pd
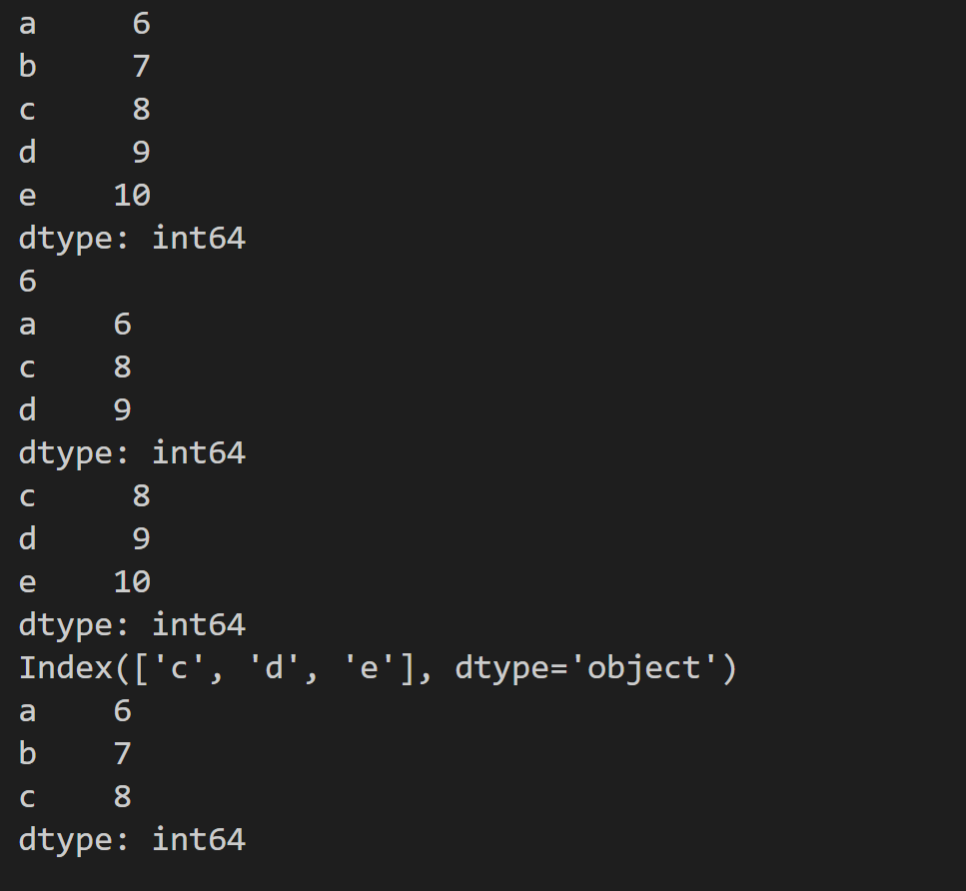
s = pd.Series([6,7,8,9,10],index = ['a','b','c','d','e'])
print(s)
print(s['a'])#取得索引为a的值
print(s[['a','c','d']])#取得索引为a,c,d的值
print(s[s>7])#取得大于7的值
print(s[s>7].index)#取得大于7的值的索引
print(s[:3])#取得前3个值
效果如图:
Series常用属性
| 名称 | 属性 |
|---|---|
| axes | 以列表的形式返回所有行索引标签。 |
| dtype | 返回对象的数据类型。 |
| empty | 返回一个空的 Series 对象。 |
| ndim | 返回输入数据的维数。 |
| size | 返回输入数据的元素数量。 |
| values | 以 ndarray 的形式返回 Series 对象。 |
| index | 返回一个RangeIndex对象,用来描述索引的取值范围。 |
isnull()&nonull()检测缺失值
import pandas as pd
#None代表缺失数据
s=pd.Series([1,2,5,None])
print(pd.isnull(s)) #是空值返回True
print(pd.notnull(s)) #空值返回False
DataFrame
创建DataFrame
import pandas as pd
pd.DataFrame( data, index, columns, dtype, copy)
| 参数名称 | 说明 |
|---|---|
| data | 输入的数据,可以是 ndarray,series,list,dict,标量以及一个 DataFrame。 |
| index | 行标签,如果没有传递 index 值,则默认行标签是 np.arange(n),n 代表 data 的元素个数。 |
| columns | 列标签,如果没有传递 columns 值,则默认列标签是 np.arange(n)。 |
| dtype | dtype表示每一列的数据类型。 |
| copy | 默认为 False,表示复制数据 data。 |
- 使用嵌套列表创建 DataFrame 对象
import pandas as pd
data = [['Alex',10],['Bob',12],['Clarke',13]]
df = pd.DataFrame(data,columns=['Name','Age'])#创建dataframe并设置列名
print(df)
- 字典嵌套列表创建
import pandas as pd
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]}
#设置行索引并创建dataframe
df = pd.DataFrame(data, index=['rank1','rank2','rank3','rank4'])
print(df)
筛选数据loc与iloc
- loc
说明:
使用loc的时候,想要多选就在[]里面再加入中括号,想要连续选的时候直接使用:号即可,行列同理。
iloc的用法与loc类似,只不过使用数字索引。普通切片的方法也不说明了。
# 导包
import numpy as np
import pandas as pd
#创建Dataframe
data=pd.DataFrame(np.arange(25).reshape(5,5),index=list('abcde'),columns=list('ABCDE'))
print(data)
print('*'*20)
print(data.loc[['a','b'],'A'])#取得a和b两行以及A列的数据
print('*'*20)
print(data.loc['a':'c',"A":"D"])#取得a到c行以及A到D列的数据
print('*'*20)
- 通过条件筛选(布尔索引)
import pandas as pd
# 创建一个简单的 Series
s = pd.Series([10, 20, 30, 40], index=['a', 'b', 'c', 'd'])
# 使用标签索引访问
print(s['a']) # 输出:10
print(s['b']) # 输出:20
# 创建一个 DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': [4, 5, 6]
}, index=['row1', 'row2', 'row3'])
# 通过标签访问行
print(df.loc['row1']) # 输出:col1 1
# col2 4
# 通过标签访问列
print(df['col1']) # 输出:row1 1
# row2 2
# row3 3
# 条件筛选:选出大于20的元素
print(s[s > 20]) # 输出:c 30
# d 40
# 条件筛选:选出 'col1' 中值大于 2 的行
print(df[df['col1'] > 2])
- 筛选时使用&、|代表且和或
import pandas as pd
# 创建一个示例 DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3, 4],
'col2': [5, 6, 7, 4]
})
# 使用 & (逻辑与)符号进行筛选,注意需要用括号括起来
result = df[(df['col1'] > 2) & (df['col2'] < 6)]
print(result)
添加、修改数据
- 普通切片方法添加列
import pandas as pd
info=[['Jack',18],['Helen',19],['John',17]]
df=pd.DataFrame(info,columns=['name','age'])
print(df)
df['gender']=['男','男','男']#添加一列
print(df)
#通过筛选将Jack名字替换为xiaohei
df.loc[:,'name'][df['name']=='Jack']='xiaohei'
- insert添加列
import pandas as pd
info=[['Jack',18],['Helen',19],['John',17]]
df=pd.DataFrame(info,columns=['name','age'])
print(df)
#注意是column参数
#数值1代表插入到columns列表的索引位置,注意位置是从零开始的
df.insert(1,column='score',value=[91,90,75])
print(df)
- 删除列pop
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']),
'three' : pd.Series([10,20,30], index=['a','b','c'])}
df = pd.DataFrame(d)
print ("Our dataframe is:")
print(df)
#使用pop方法删除,按列名删除
df.pop('two')
print (df)
- 删除行
import pandas as pd
df = pd.DataFrame([[1, 2], [3, 4]], columns = ['a','b'])
df2 = pd.DataFrame([[5, 6], [7, 8]], columns = ['a','b'])
df = pd.concat([df,df2])
print(df)
#注意此处调用了drop()方法,删除行索引的名字为0的行
df = df.drop(0)
print (df)
常用参数
| 名称 | 属性&方法描述 |
|---|---|
| T | 行和列转置。 |
| axes | 返回一个仅以行轴标签和列轴标签为成员的列表。 |
| dtypes | 返回每列数据的数据类型。 |
| empty | DataFrame中没有数据或者任意坐标轴的长度为0,则返回True。 |
| ndim | 轴的数量,也指数组的维数。 |
| shape | 返回一个元组,表示了 DataFrame 维度。 |
| size | DataFrame中的元素数量。 |
| values | 使用 numpy 数组表示 DataFrame 中的元素值。 |
| head() | 返回前 n 行数据。 |
| tail() | 返回后 n 行数据。 |
| shift() | 将行或列移动指定的步幅长度 |
零碎方法
-
set_index(“列名”,inplace=True)
设定哪一列为索引标签 -
df2.rename(columns={'ID': 'ID2'})#将df2中列名ID改为ID2
-
value_counts与sort_values
-
value_counts() 主要用于统计 Series 中每个唯一值的出现频率。它返回一个 Series,索引是原 Series 中的唯一值,值是这些唯一值在 Series 中出现的次数。
-
sort_values() 用于根据某一列(或多列)的值对 DataFrame 或 Series 进行排序。它允许你指定排序的列、排序的顺序(升序或降序),以及是否排序的过程中需要处理缺失值等。
-
head(),tail()就不举例了
describe()
提取所有的数字列统计结果
mean()均值
median():计算中位数
std():计算标准差
var():计算方差
sum():计算总和
min()/max():计算最小值/最大值
count():计算非缺失值的数量
• isnull():检查缺失值(isna() 和 isnull() 功能相同)
unique():去重操作,类似于{}
dropna():丢弃缺失值
fillna():填充缺失值
转换数据类型
mport pandas as pd
# 创建一个包含浮动数的 Series
s = pd.Series([1.2, 2.5, 3.7, 4.8])
# 将 Series 转换为整数类型
s_int = s.astype(int)
print(s_int)
apply函数
注意:使用的时候,是对每个列中的元素,单独进行appl中函数的操作,但是使用参数axis=1以后,就是对一行中的数进行操作。
# 创建一个 DataFrame
import pandas as pd
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6]
})
# 使用 apply() 对每列求和
result = df.apply(lambda x: x.sum())
print(result)
#如果你设置 axis=1,则会按行进行操作。
# 使用 apply() 对每行求和
result = df.apply(lambda x: x.sum(), axis=1)
print(result)
result=df.apply(lambda x:x+1)
print(df.sum(axis=1))
groupby()分组与agg聚合操作
# 创建一个 DataFrame
df = pd.DataFrame({
'Category': ['A', 'B', 'A', 'B', 'A'],
'Value': [10, 20, 30, 40, 50]
})
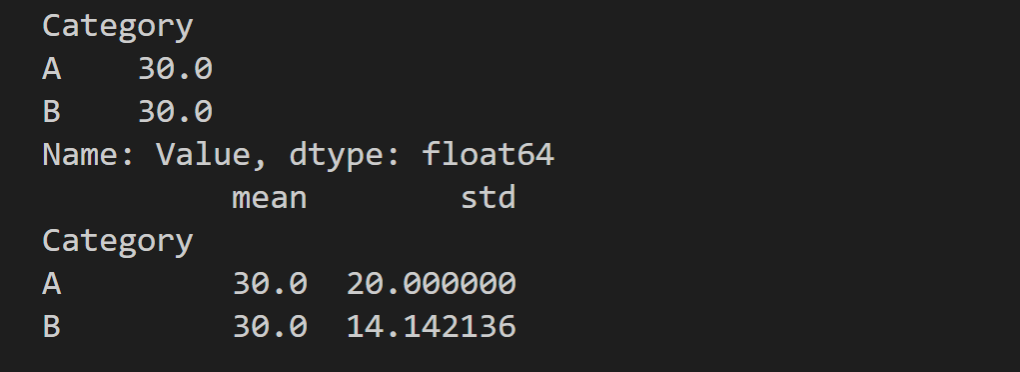
# 按 Category 列分组,并计算 Value 的均值
grouped = df.groupby('Category')['Value'].mean()
print(grouped)
# 按 Category 分组,并同时计算均值和标准差
grouped_agg = df.groupby('Category')['Value'].agg(['mean', 'std'])
print(grouped_agg)
效果如图:
pivot_table():生成透视表
透视表用于数据汇总与聚合,类似于 Excel 中的透视表。
pandas.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')
data: 输入的 DataFrame。
values: 需要聚合的列。
index: 用作行索引的列。
columns: 用作列索引的列。
aggfunc: 聚合函数,默认为 'mean',可以是 'sum'、'count'、'min'、'max' 等,也可以是多个函数的列表。
fill_value: 用于替换缺失值的值。
margins: 是否添加行/列的总计,默认为 False。
dropna: 是否删除全为 NaN 的列,默认为 True。
margins_name: 总计行/列的名称,默认为 'All'。
举例:
import pandas as pd
data = {
'Date': ['2023-01-01', '2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02', '2023-01-02'],
'City': ['New York', 'Los Angeles', 'New York', 'New York', 'Los Angeles', 'Los Angeles'],
'Temperature': [32, 75, 30, 28, 77, 80],
'Humidity': [60, 50, 65, 70, 55, 45]
}
df = pd.DataFrame(data)
print(df)
# index='Date':将 Date 列作为行索引。
# columns='City':将 City 列作为列索引。
# values='Temperature':对 Temperature 列进行聚合。
# aggfunc='mean':计算平均值。
pivot = pd.pivot_table(df, values='Temperature', index='Date', columns='City', aggfunc='mean')
print(pivot)
pivot = pd.pivot_table(df, values=['Temperature', 'Humidity'], index='Date', columns='City', aggfunc='mean')
print(pivot)
pivot = pd.pivot_table(df, values='Temperature', index='Date', columns='City', aggfunc=['mean', 'max'])
print(pivot)
pivot = pd.pivot_table(df, values='Temperature', index='Date', columns='City', aggfunc='mean', fill_value=0)
print(pivot)
concat与merge
- concat
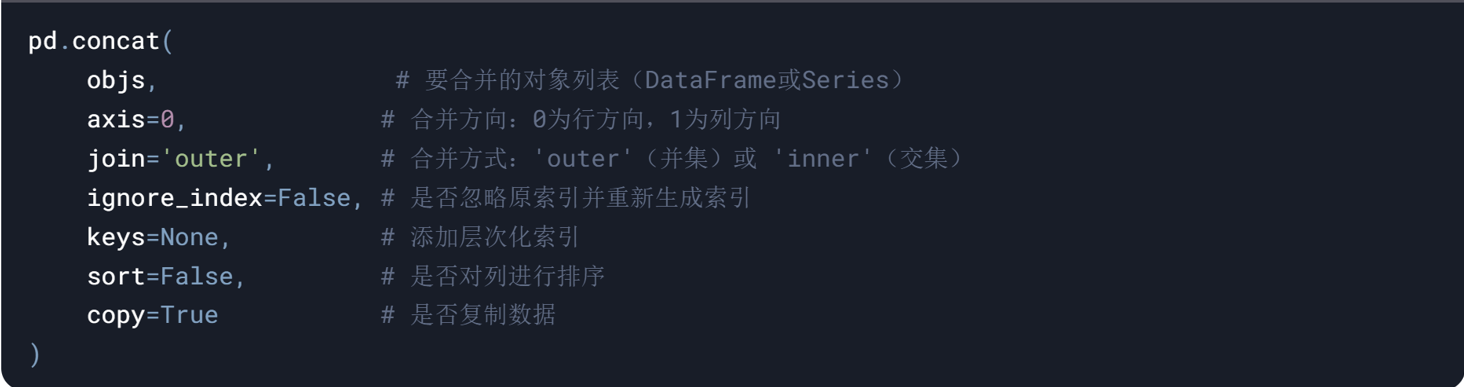
举例:
import pandas as pd
df = pd.DataFrame([[1, 2], [3, 4]], columns = ['a','b'])
df2 = pd.DataFrame([[5, 6], [7, 8]], columns = ['c','b'])
df1 = pd.concat([df,df2],ignore_index=True,join='outer')
print(df1)
df1=pd.concat([df,df2],ignore_index=True,axis=1)#按列拼接
print(df1)
- merge
说明:
merge
merge 主要用于基于某些键(key)将两个 DataFrame 按列进行合并,类似于 SQL 中的 JOIN 操作。
使用场景
当需要根据某些列的值将两个 DataFrame 合并时。
支持多种连接方式:inner、left、right、outer。
pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None, suffixes=('_x', '_y'))
left: 左侧的 DataFrame。
right: 右侧的 DataFrame。
how: 合并方式,默认为 'inner',可选值包括:
'inner': 内连接,只保留键值匹配的行。
'left': 左连接,保留左侧 DataFrame 的所有行。
'right': 右连接,保留右侧 DataFrame 的所有行。
'outer': 外连接,保留所有行,缺失值填充为 NaN。
on: 用于合并的列名(两个 DataFrame 中列名相同时)。
left_on: 左侧 DataFrame 中用于合并的列名。
right_on: 右侧 DataFrame 中用于合并的列名。
suffixes: 当两个 DataFrame 有相同列名时,用于区分列名的后缀,默认为 ('_x', '_y')。
举例:
import pandas as pd
# 左侧 DataFrame
df1 = pd.DataFrame({
'ID': [1, 2, 3, 4],
'Name': ['Alice', 'Bob', 'Charlie', 'David']
})
# 右侧 DataFrame
df2 = pd.DataFrame({
'ID': [2, 3, 4, 5],
'Age': [25, 30, 35, 40]
})
print("df1:")
print(df1)
print("\ndf2:")
print(df2)
#内连接
result = pd.merge(df1, df2, on='ID', how='inner')
print(result)
#左连接 (how='left'),以左边的数据的ID号为主,右连接同理
result = pd.merge(df1, df2, on='ID', how='left')
print(result)
#外连接 (how='outer')保留所有行,未匹配的行填充为 NaN。
result = pd.merge(df1, df2, on='ID', how='outer')
print(result)
#如果两个 DataFrame 的键列名不同,可以使用 left_on 和 right_on。
# 修改 df2 的键列名
df2 = df2.rename(columns={'ID': 'ID2'})#修改列名
# 合并
result = pd.merge(df1, df2, left_on='ID', right_on='ID2', how='inner')
print(result)
pandas字符串处理方法
pandas 提供了一些强大的工具来处理和操作字符串数据,尤其是通过 str 属性,可以方便地对 Series 中的字符串进行各种操作。下面我将介绍一些常见的字符串处理方法,包括基本的字符串操作、替换、查找、分割、正则表达式等。
注意:dataframe单独取一列也可以使用
- str.lower() / str.upper()
import pandas as pd
# 创建 Series
s = pd.Series(['Hello', 'world', 'Python'])
# 转换为小写
print(s.str.lower())
# 转换为大写
print(s.str.upper())
剩下的就不一个个的解释了
str.title()
将字符串中的每个单词首字母大写:
print(s.str.title())
str.capitalize()
将字符串的首字母大写,其他字母小写:
print(s.str.capitalize())
str.contains()
检查字符串是否包含子字符串,返回一个布尔值的 Series:
s = pd.Series(['apple', 'banana', 'cherry', 'date'])
检查是否包含字母 'a'
print(s.str.contains('a'))
str.startswith() / str.endswith()
# 检查是否以 'a' 开头
print(s.str.startswith('a'))
检查是否以 'e' 结尾
print(s.str.endswith('e'))
str.find() / str.index()
返回子字符串首次出现的索引位置,如果找不到返回 -1(find())或抛出异常(index()):
print(s.str.find('a'))
# 或者
# print(s.str.index('a')) # 如果找不到会抛出异常
str.replace()
# 将 'a' 替换为 'A'
print(s.str.replace('a', 'A'))
str.strip() / str.lstrip() / str.rstrip()
去除字符串的左右(或单侧)空格或指定字符:
str.split()
按指定分隔符将字符串分割成多个部分
str.join()
将多个字符串拼接在一起:
print(s.str.join(', '))
str.len()
str.count()
to_datetime()
将字符串转换为日期时间格式,通常用于时间序列分析:
dates = pd.Series(['2020-01-01', '2020-02-01', '2020-03-01'])
datetime_series = pd.to_datetime(dates)
read_csv()
-
header=0表示指定第一行为列名
-
使用 names 参数可以指定头文件的名称。
文件标头名是附加的自定义名称,但是你会发现,原来的标头名(列标签名)并没有被删除,此时您可以使用header参数来删除它。header=0表示指定第一行为列名,然后使用names=[]来代替,就实现了使用names重新设置列名 -
index_col:将 CSV 文件中的某一列或多列设置为 DataFrame 的行索引。
如果不指定 index_col,默认会生成一个从 0 开始的整数索引。
可以使用数字,也可以直接使用列名 -
to_csv()
Pandas 提供的 to_csv() 函数用于将 DataFrame 转换为 CSV 数据。如果想要把 CSV 数据写入文件,只需向函数传递一个文件对象即可。否则,CSV 数据将以字符串格式返回。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号