爬虫day1
1. get最简单的爬虫
使用requests包请求网址,并爬取网址,并获取其中html文件内容
import requests as r
url='http://www.baidu.com/'
#发起请求
response=r.get(url=url)
#获取响应数据
page_text=response.text
print(page_text)
print("finish")
#持久化存储
with open('./baidu.html','w',encoding='utf-8') as fp:
fp.write(page_text)
print("爬取数据结束")
2. 带上身份和参数的爬虫
UA:User-Agent(请求载体的身份标识)UA检测:门户网站的服务器会检测对应请求的载体身份标识,如果检测到请求的载体身份标识为某一款浏览器,说明该请求是正常的请求。
但是,如果检测到请求的载体身份标识不是基于某一款,则表示该请求为不正常的(爬虫)。则服务器端就可能拒绝该次请求
- UA伪装:骗服务器,让其以为是某一款浏览器发起的请求
import requests as r
header={'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Mobile Safari/537.36 Edg/134.0.0.0'}
url='http://www.baidu.com/s'
value=input('输入查找词:')
word={'wd':value}
response=r.get(url=url,params=word,headers=header)
#这里的get请求相当与访问 http://www.baidu.com/s ?wd=value的输入值
#如果有多个值比如 http://www.xiaohei.com/s ?wd=12&sd=13,相应的
#params参数就是多个键值的字典{'wd':12,'sd':13}
page_text=response.text
file_name='./'+value+'.html'
with open(file_name,'w',encoding='utf-8') as f:
f.write(page_text)
3. 使用post进行对json进行爬取
-
用途: 主要用于向服务器提交数据。
-
特点:
- 数据通过请求体传递,不会暴露在 URL 中。适合传输大量数据或敏感信息(如登录凭证、文件上传等)。不会被缓存,也不会保留在浏览器的历史记录中。没有长度限制。
-
爬虫中的应用:
- 适用于需要提交表单、登录、上传文件等场景。常用于需要与服务器进行交互的操作。
-
解析百度翻译
按F12后如下图操作,翻译的同时找到最后的sug,里面存放的就有后面情求参数的形式和json文件
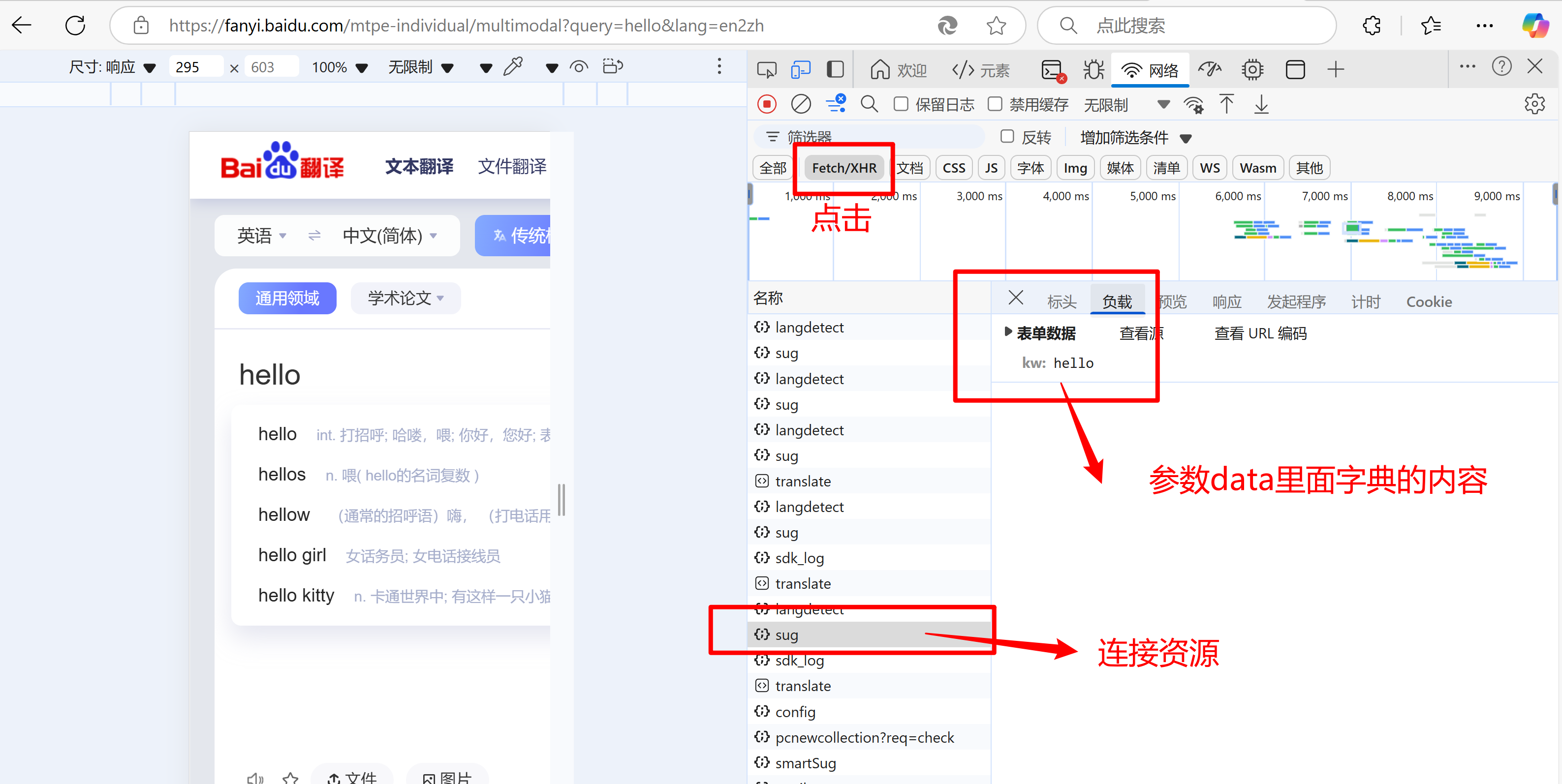
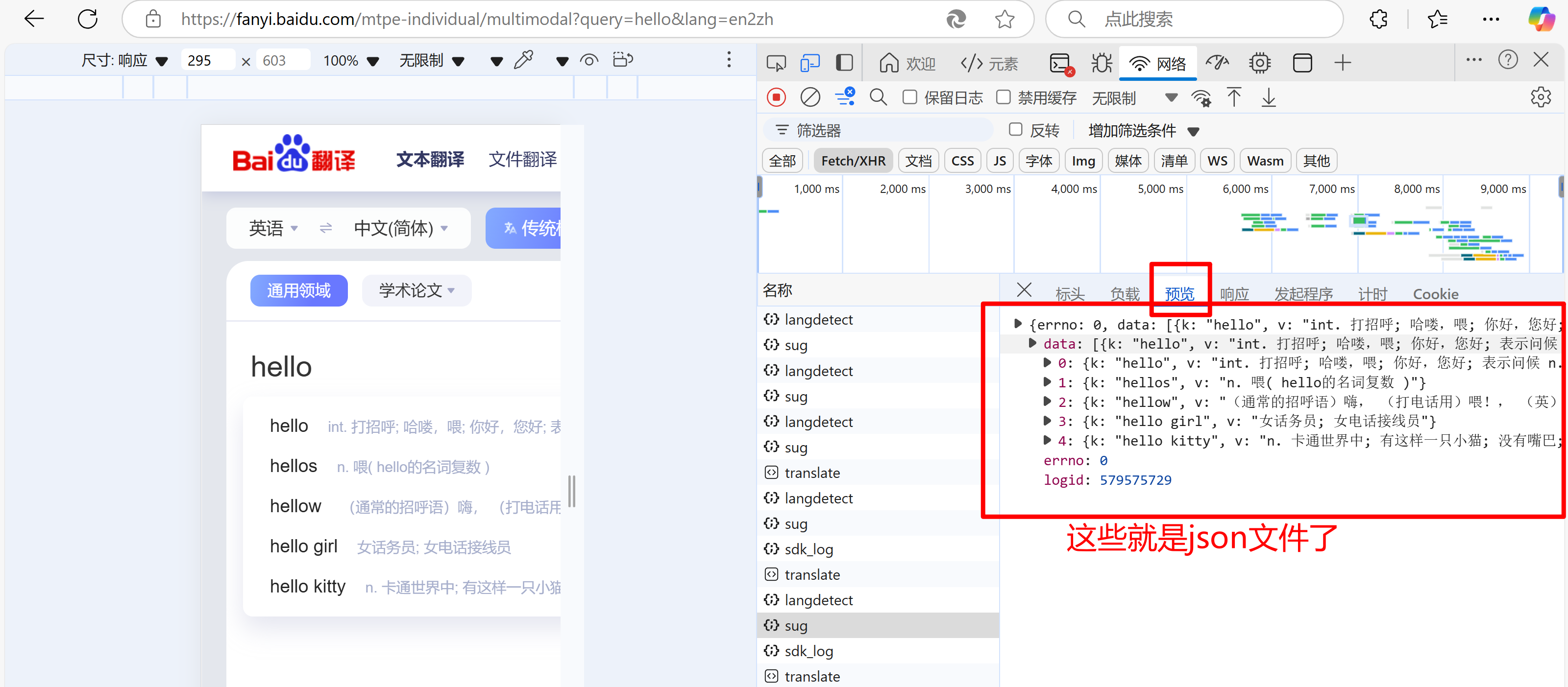
- 具体代码如下:
import requests as r
import json
post_param=input('输入单词:')
post_url='https://fanyi.baidu.com/sug'#在network中XHR里的sug中找的
data={'kw':post_param}#data为post请求中携带的参数,类似于get中的params
# header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3775.400 QQBrowser/10.6.4209.400'}
header={'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Mobile Safari/537.36 Edg/134.0.0.0'}
response=r.post(url=post_url,data=data,headers=header)
#获取响应数据:json()方法返回的是obj(如果确认响应数据是json类型,才可以使用)
page_dict=response.json()#返回的是字典对象
print(page_dict)
# 进行持久化存储json数据
file_name='./test.json'
with open(file_name,'w',encoding='utf-8') as fp:
json.dump(page_dict,fp=fp,ensure_ascii=False)#保存json数据,拿到的是中文,不能用ascii码
print('爬取结束!')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号