
本系列仅作翻译记录和个人总结
4.1 Steps Involved in Model Initialisation
-
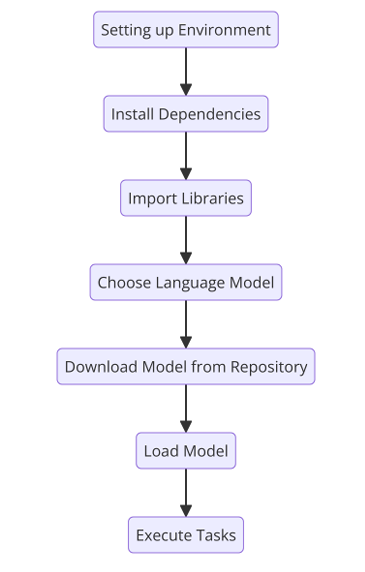
设置环境:配置环境,例如,如果可用,设置 GPU/TPU 使用,这可以显著加快模型加载和推理速度。
-
安装依赖项:确保所有必要的软件和库都已安装。通常包括像 \(pip\) 这样的包管理器和像 \(PyTorch\) 或 \(TensorFlow\) 这样的框架。
-
导入库:在您的脚本或笔记本中导入所需的库。常见的库包括 \(Hugging\, Face\) 的 \(transformers\)、用于 \(PyTorch\) 的 \(torch\) 以及其他实用库。
-
选择语言模型:根据您的任务需求选择适当的预训练语言模型。这可以是像 \(BERT\)、\(GPT-3\) 或其他在 \(Hugging\, Face\) 模型库上可用的模型。
-
从仓库下载模型:使用所选框架的功能从在线仓库下载预训练模型。例如,使用 \(transformers\) ,可以使用
AutoModel.from_pretrained('模型名称')。 -
在内存中加载模型:将模型加载到内存中,准备进行推理或进一步微调。此步骤确保模型权重已初始化并准备使用。
-
执行任务:使用已加载的模型执行所需任务。这可能涉及进行预测、生成文本或在新数据集上微调模型。
4.2 Tools and Libraries for Model Initialisation
\(Python\) 提供了广泛的库用于初始化大语言模型,既可以访问开源模型,也可以访问闭源模型。以下是一些值得注意的库:
-
\(Python\) 库:\(HuggingFace\)
描述:\(HuggingFace\) 以其对众多预训练大语言模型的支持而闻名,从 \(Phi-3\, mini\) 到 \(Llama-3\, 70B\)。\(HuggingFace\) 的一部分 \(transformers\) 库使用户能够通过 \(AutoModelForCausalLM\) 等类访问这些模型。该库支持加载微调模型以及 \(4-bit\) 量化模型。此外,\(transformers\) 库还包括 “pipeline” 功能,使使用预训练模型进行各种任务变得简单。 -
\(Python\) 框架:\(PyTorch\)
描述:\(PyTorch\) 提供了全面的工具和库,用于初始化和微调大语言模型。它为构建和部署深度学习模型提供了灵活高效的平台。\(HuggingFace\) 的 \(transformers\) 库弥合了 \(PyTorch\) 与其他框架之间的差距,增强了其在最先进的语言模型中的可用性。 -
\(Python\) 框架:\(TensorFlow\)
描述:\(TensorFlow\) 同样提供了广泛的工具和库,用于初始化和微调大型语言模型。与 \(PyTorch\) 类似,它受益于 \(HuggingFace\) 的 \(transformers\) 库,该库为处理大语言模型的最新进展提供了多功能且用户友好的 \(API\) 和接口。
4.3 Challenges in Model Initialisation
| 挑战 | 描述 |
|---|---|
| 与目标任务的一致性 | 预训练模型与您的特定任务或领域紧密对齐是至关重要的。这种初步对齐为后续的微调工作奠定了坚实的基础,从而提高了效率和结果。 |
| 理解预训练模型 | 在做出选择之前,彻底理解架构、能力、局限性以及模型最初训练的任务非常重要。没有这种理解,微调工作可能无法产生预期的结果。 |
| 可用性和兼容性 | 仔细考虑模型的文档、许可、维护和更新频率是必要的,以避免潜在问题并确保与您的应用程序的顺利集成。 |
| 模型架构 | 并不是所有模型在每个任务上都表现出色。每种模型架构都有其优缺点,因此选择与您的特定任务相符合的模型对于获得理想结果至关重要。 |
| 资源限制 | 加载预训练大型语言模型占用资源较多,需要更多计算。这些模型需要高性能的 \(CPU\) 和 \(GPU\),以及大量的磁盘空间。例如,\(Llama3\, 8B\) 模型至少需要 \(16GB\) 的内存才能加载并进行推理。 |
| 隐私 | 隐私和保密是选择大型语言模型(\(LLM\))时的关键因素。许多企业更倾向于不与外部 \(LLM\) 提供商共享数据。在这种情况下,将 \(LLM\) 托管在本地服务器上或通过私有云提供商使用预训练的 \(LLM\) 可以成为可行的解决方案。这些方法确保数据保持在公司的场所内,从而维护隐私和保密性。 |
| 成本和维护 | 在本地服务器上托管大语言模型需要大量时间和费用用于设置和持续维护。相反,利用云服务提供商可以减轻对资源维护的担忧,但会产生每月的账单费用。这些费用通常基于模型大小和每分钟请求数量等因素。 |
| 模型大小和量化 | 利用预训练模型,即使高内存消耗,也可以通过使用其量化版本来实现可行性。通过量化,可以用较低精度加载预训练权重,通常是 \(4\) 位或 \(8\) 位浮点,从而显著减少参数体积,同时保持相当的准确性。 |
| 预训练数据集 | 检查用于预训练的数据集,以评估模型对语言的理解。这些数据集非常重要,因为有专门用于代码生成的模型,我们不想使用那些模型来进行财经文本分类。 |
| 偏见意识 | 对于预训练模型中的潜在偏见保持警惕,尤其是在需要无偏见预测的情况下。可以通过测试不同的模型和回溯用于预训练的数据集来评估偏见意识。 |
4.4 Tutorials
HuggingFace tutorial for getting started with LLMs
本文来自博客园,作者:Cocoicobird,转载请注明原文链接:https://www.cnblogs.com/Cocoicobird/p/18975250

 浙公网安备 33010602011771号
浙公网安备 33010602011771号