
本系列仅作翻译记录和个人总结
微调大语言模型(\(LLM\))是一个综合过程,分为七个不同的阶段,每个阶段对于将预训练模型适应特定任务并确保最佳性能都是至关重要的。这些阶段涵盖了从初始数据集准备到最终部署和维护微调模型的各个方面。通过系统地遵循这些阶段,模型得以完善并量身定制以满足精确需求,最终增强了其生成准确且符合上下文的响应的能力。这七个阶段包括数据集准备、模型初始化、训练环境设置、微调、评估与验证、部署,以及监控和维护。
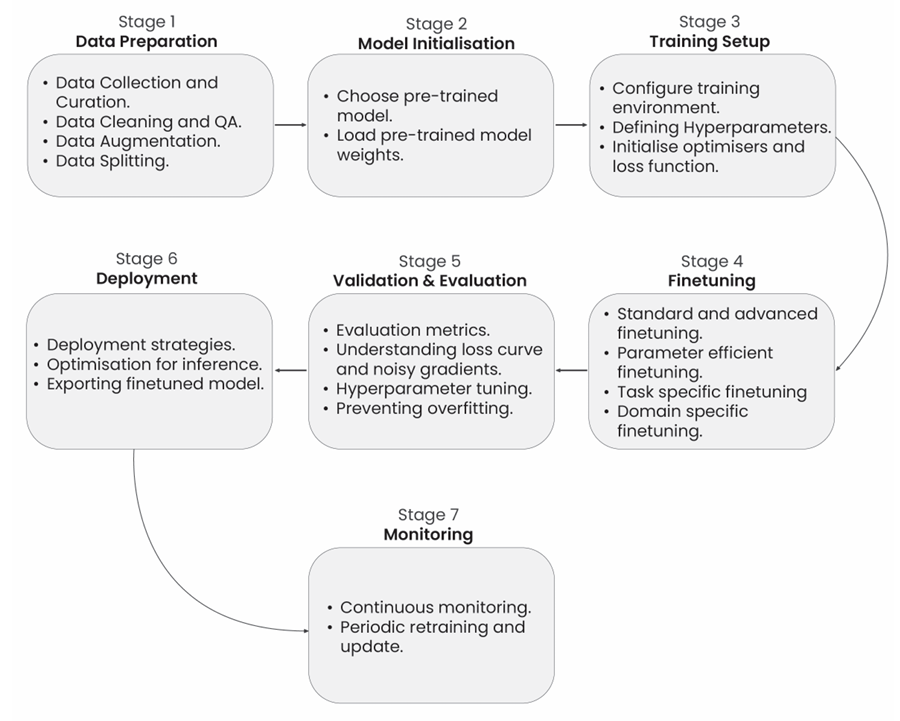
用于微调大语言模型(\(LLM\)),展示七个基本阶段:数据集准备、模型初始化、训练环境设置、微调、评估和验证、部署,以及监控和维护。每个阶段在将预训练模型适应特定任务并确保其在整个生命周期内的最佳性能方面都发挥着至关重要的作用。
2.1 Stage 1: Dataset Preparation
对大语言模型(\(LLM\))进行微调始于将预训练模型适应特定任务,通过使用新的数据集更新其参数。这涉及清理和格式化数据集,以符合目标任务,例如指令调优、情感分析或主题映射。数据集由 <输入,输出> 对组成,展示模型所期望的行为。例如,在指令调优中,数据集可能如下所示:
###Human: $<Input Query>$
###Assistant: $<Generated Output>$
在这里,“输入查询”是用户所问的内容,而“生成输出”是模型的回应。这些对的结构和风格可以根据任务的具体需求进行调整。
2.2 Stage 2: Model Initialisation
模型初始化是设置大语言模型在训练或部署之前的初始参数和配置的过程。这一步骤对于确保模型最佳性能、高效训练以及避免消失或爆炸梯度等问题至关重要。
2.3 Stage 3: Training Environment Setup
为 \(LLM\) 微调设置训练环境涉及配置必要的基础设施,以便将现有模型适应于特定任务。这包括选择相关的训练数据、定义模型的架构和超参数,并运行训练迭代以调整模型的权重和偏差。目标是提高LLM在生成准确和上下文适应性输出方面的表现,以符合特定应用,例如内容创作、翻译或情感分析。成功的微调依赖于仔细的准备和严格的实验。
2.4 Stage 4: Partial or Full Fine-Tuning
这个阶段涉及使用特定任务的数据集来更新大型语言模型(\(LLM\))的参数。完全微调更新模型的所有参数,确保全面适应新任务。或者,可以采用半微调(\(HFT\))或参数高效微调(\(PEFT\))方法,例如使用适配器层,部分微调模型。这种方法将在预训练模型上附加额外的层,以便用更少的参数进行高效微调,从而解决与计算效率、过拟合和优化相关的挑战。
2.5 Stage 5: Evaluation and Validation
评估和验证涉及对微调后的 \(LLM\) 在未见数据上的表现进行评估,以确保其良好的泛化能力并满足预期目标。评估指标,如交叉熵,用于测量预测错误,而验证则监测损失曲线和其他性能指标,以检测过拟合或欠拟合等问题。这个阶段有助于指导进一步的微调,以实现最佳的模型性能。
2.6 Stage 6: Deployment
部署大语言模型意味着使其在特定应用中可操作和可访问。这涉及将模型配置为在指定的硬件或软件平台上高效运行,确保它能够处理自然语言处理、文本生成或用户查询理解等任务。部署还包括设置集成、安全措施和监控系统,以确保其在实际应用中的可靠和安全性能。
2.7 Stage 7: Monitoring and Maintenance
在部署后监控和维护大语言模型(\(LLM\))至关重要,以确保持续的性能和可靠性。这包括不断跟踪模型的性能,解决出现的任何问题,并根据需要更新模型,以适应新数据或变化的要求。有效的监控和维护有助于维持模型的准确性和有效性。
本文来自博客园,作者:Cocoicobird,转载请注明原文链接:https://www.cnblogs.com/Cocoicobird/p/18963984

 浙公网安备 33010602011771号
浙公网安备 33010602011771号