
本系列仅作翻译记录和个人总结
1.1 Background of Large Language Models (LLMs)
大型语言模型(\(LLMs\))代表了计算系统在理解和生成自然语言方面的重大飞跃。\(LLMs\) 建立在传统语言模型(\(LMs\))如 \(N-gram\) 模型的基础上,解决了稀有词处理、过拟合以及捕捉复杂语言模式等局限性。诸如 \(GPT-3\) 和 \(GPT-4\) 等显著例子利用 \(Transformer\) 架构中的自注意力机制,有效管理序列数据并理解长程依赖关系。关键进展包括上下文学习以从提示中生成连贯的文本,以及基于人类反馈的强化学习(\(RLHF\))用于通过人类反应来改进模型。像提示工程、问答和对话互动等技术显著推动了自然语言处理(\(NLP\))领域的发展。
1.2 Historical Development and Key Milestones
语言模型是自然语言处理(\(NLP\))的基础,利用数学技术来概括涉及预测和生成的任务的语言规则和知识。在几十年的发展中,语言建模从早期的统计语言模型(\(SLMs\))演变为今天的先进大型语言模型(\(LLMs\))。这一快速进步使得大型语言模型能够以与人类能力相当的水平处理、理解和生成文本。下图展示了从早期统计方法到当前先进模型的大型语言模型的演变。
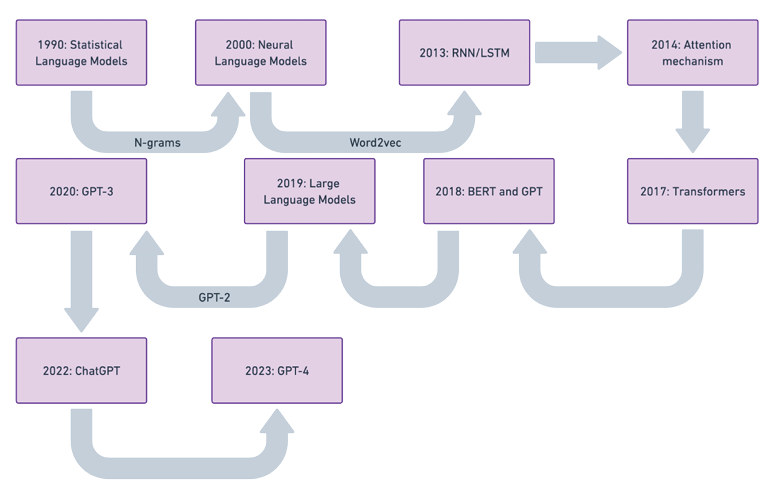
1.3 Evolution from Traditional NLP Models to State-of-the-Art LLMs
理解大语言模型需要追溯语言模型的发展历程,包括统计语言模型(\(SLMs\))、神经语言模型(\(NLMs\))、预训练语言模型(\(PLMs\))和大语言模型(\(LLMs\))。
1.3.1 Statistical Language Models (SLMs)
在 \(1990\) 年代出现的统计语言模型(\(SLMs\))使用概率方法分析自然语言,以确定文本中句子的可能性。例如,句子“我很开心”的概率 \(P(S)\) 如下所示:
这个概率可以使用条件概率来计算:
条件概率使用最大似然估计(\(Maximum\ Likelihood\ Estimation,MLE\))进行估计:
1.3.2 Neural Language Models (NLMs)
神经语言模型利用神经网络预测词序列,克服了传统统计语言模型的局限性。词向量使计算机能够理解单词的含义。像 \(Word2Vec\) 这样的工具将单词表示为向量空间中的点,语义关系通过向量的角度得以反映。神经语言模型由相互连接的神经元组成,组织成层,与人类大脑的结构类似。输入层连接词向量,隐藏层应用非线性激活函数,而输出层使用 \(Softmax\) 函数预测后续单词,将值转换为概率分布。
下图说明了神经语言模型的结构,突出了用于预测后续单词的层和连接。
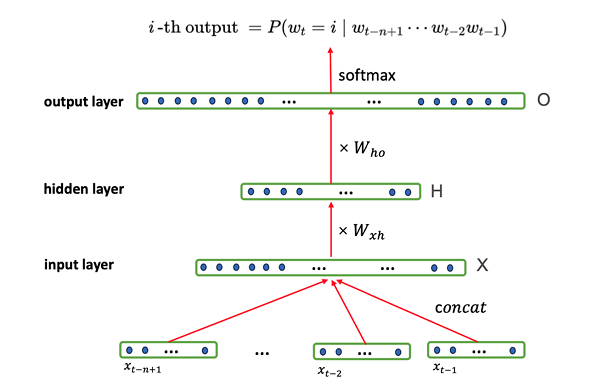
1.3.3 Pre-trained Language Models (PLMs)
预训练语言模型最初是在大量未标记的文本上进行训练,以理解基本的语言结构(预训练)。然后,它们会在一个更小的、特定任务的数据集上进行微调。这种“预训练和微调”的范式,以 \(GPT-2\) 和 \(BERT\) 为例,产生了多样化且有效的模型架构。
1.3.4 Large Language Models (LLMs)
像 \(GPT-3\)、\(GPT-4\)、\(PaLM\) 和 \(LLaMA\) 这样的大语言模型在包含数十亿参数的大规模文本语料库上进行训练。模型经历两阶段的过程:首先在广泛的语料库上进行预训练,随后通过与人类价值观的对齐。这种方法使大型语言模型更好地理解人类的命令和价值观。
1.4 Overview of Current Leading LLMs
大语言模型是自然语言处理中的强大工具,能够执行诸如翻译、摘要和对话互动等任务。\(Transformer\) 架构、计算能力和丰富的数据集的进步推动了它们的成功。这些模型接近人类水平的表现,使它们对于研究和实际应用来说变得不可或缺。大语言模型的快速发展激发了对架构创新、训练策略、扩展上下文长度、微调技术和多模态数据整合的研究。它们的应用超越了自然语言处理,促进人机交互和创建直观的人工智能系统。这突显了综合评审整合最新发展的重要性。
下图提供了当前领先的大语言模型的概述,突出了它们的能力和应用。
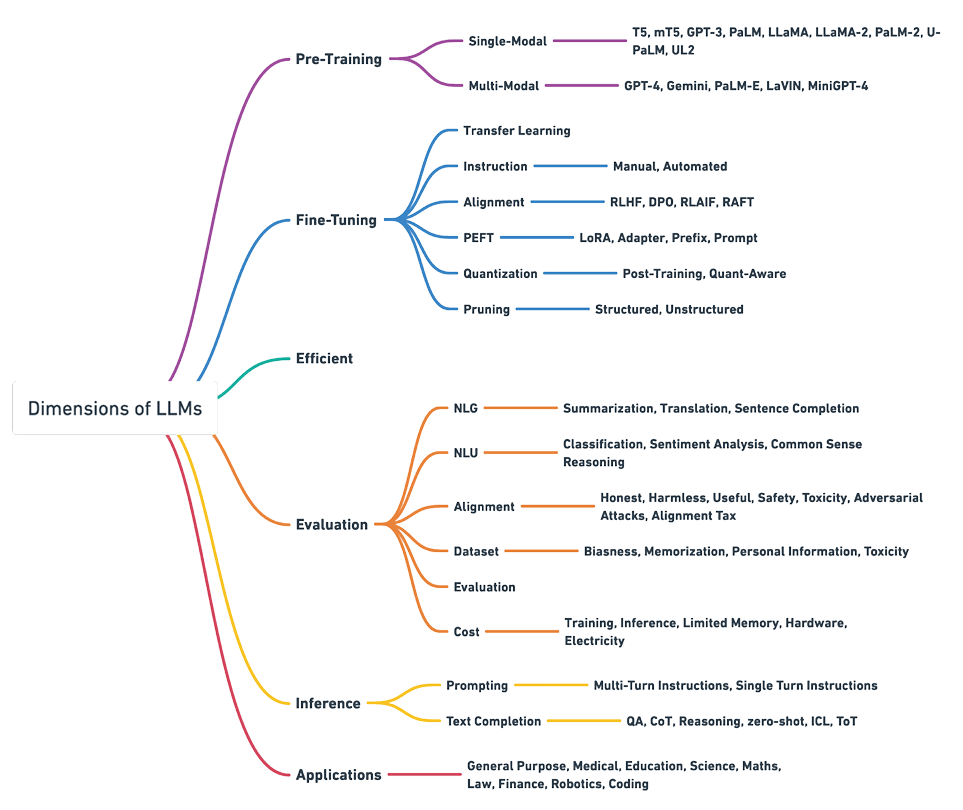
1.5 What is Fine-Tuning?
微调使用预训练模型,例如 \(OpenAI\) 的 \(GPT\) 系列,作为基础。这个过程涉及在更小的特定领域数据集上进一步训练。这种方法基于模型已有的知识,增强了在特定任务上的表现,同时减少了数据和计算需求。
微调将预训练模型学习到的模式和特征转移到新任务上,提高了性能并减少了训练数据需求。这在自然语言处理中的任务如文本分类、情感分析和问答中变得越来越受欢迎。
1.6 Types of LLM Fine-Tuning
1.6.1 Unsupervised Fine-Tuning
该方法不需要标记数据。相反,\(LLM\) 接触到来自目标领域的大量未标记文本,提升其对语言的理解。这种方法对法律或医疗等新领域很有用,但对于分类或摘要等特定任务的精确性较差。
1.6.2 Supervised Fine-Tuning (SFT)
\(SFT\) 涉及为大语言模型提供针对目标任务的标记数据。例如,在商业环境中对大语言模型进行文本分类的微调使用带类标签的文本片段数据集。虽然这种方法有效,但需要大量的标记数据,这可能会花费成本和时间。
1.6.3 Instruction Fine-Tuning via Prompt Engineering
这种方法依赖于为大语言模型提供自然语言指令,这对于创建专业助手非常有用。它减少了对大量标签数据的需求,但在很大程度上依赖于提示的质量。
1.7 Pre-training vs Fine-tuning
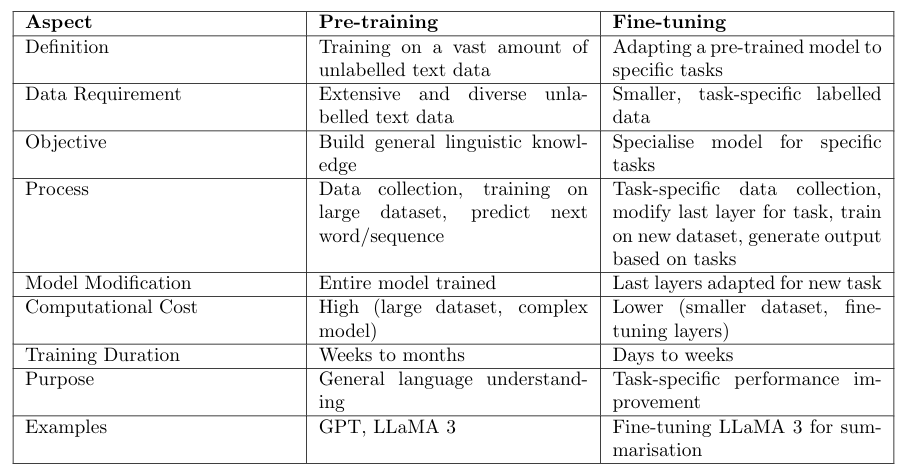
下表提供了预训练和微调之间的比较,突出了它们各自的特征和过程。
该表概述了预训练和微调阶段在定义、数据需求、目标、流程、模型修改、计算成本、训练时长及其各自目的等多个方面的关键差异,并通过示例突出具体模型和任务。预训练涉及在大量未标记数据上进行广泛训练,以建立一般语言知识,而微调则利用较小的带标记数据集将预训练模型适应于专业任务,专注于特定任务的性能提升。
1.8 Importance of Fine-Tuning LLMs
- 迁移学习:微调利用在预训练过程中获得的知识,将其调整为特定任务,从而减少计算时间和资源。
- 减少数据需求:微调需要更少的标记数据,专注于将预训练特征针对目标任务进行调整。
- 改善泛化能力:微调增强了模型对特定任务或领域的泛化能力,捕捉一般语言特征并对其进行定制。
- 高效的模型部署:微调模型在实际应用中更高效,计算效率高,适合特定任务。
- 对多种任务的适应性:微调后的大型语言模型可以适应广泛的任务,在多种应用中表现良好,而无需特定于任务的架构。
- 领域特定性能:微调使模型能够在领域特定任务中表现优秀,通过调整以符合目标领域的细微差别和词汇。
- 更快的收敛:微调通常能实现更快的收敛,因为它从已经捕捉到一般语言特征的权重开始。
1.9 Retrieval Augmented Generation (RAG)
利用自有数据的一个流行方法是将其纳入询问大模型时的提示中。这种方法被称为检索增强生成(\(RAG\)),涉及检索相关数据,并将其作为 \(LLM\) 的额外上下文使用。\(RAG\) 工作流程不仅仅是依赖于训练数据中的知识,而是提取相关信息,将静态的 \(LLM\) 与实时数据检索相连接。通过 \(RAG\) 架构,组织可以部署任何 \(LLM\) 模型,并通过提供少量自有数据来增强模型以返回相关结果。该过程避免了与微调或预训练模型相关的成本和时间。
传统的检索增强生成(\(RAG\))管道步骤如下图所示,描绘了从客户查询到响应生成的过程。管道以客户的问题开始,随后在向量数据库中进行语义搜索,在生成大语言模型的提示之前对数据进行上下文丰富。最终响应经过后处理并返回给客户。
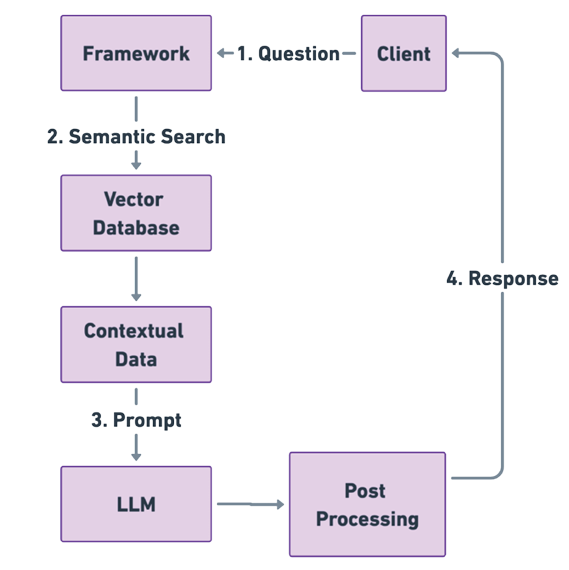
1.9.1 Traditional RAG Pipeline and Steps
- 数据索引:高效组织数据以便快速检索。这涉及到处理、分块和将数据存储在向量数据库中,使用如搜索索引、向量索引和混合索引等索引策略。
- 输入查询处理:优化用户查询以提高与索引数据的兼容性。这可以包括简化或对查询进行向量转换,以提高搜索效率。
- 搜索与排名:根据相关性检索和排名数据,使用如 \(TF-IDF\)、\(BM25\) 等搜索算法以及 \(BERT\) 等深度学习模型来理解查询的意图和上下文。
- 提示增强:将搜索结果中的相关信息纳入原始查询,以为大语言模型提供额外的上下文,从而增强响应的准确性和相关性。
- 响应生成:使用增强的提示生成响应,将大语言模型的知识与当前的具体数据结合起来,以确保高质量、具备上下文的答案。
1.9.2 Benefits of Using RAG
- 最新且准确的响应:通过当前的外部数据增强大语言模型的响应,提高准确性和相关性。
- 减少不准确的响应:将 \(LLM\) 的输出基于相关知识,降低生成错误信息的风险。
- 特定领域的响应:提供针对组织专有数据的上下文相关响应。
- 效率和成本效益:提供一种经济有效的方法来定制 \(LLM\),而无需进行广泛的模型微调。
1.9.3 Challenges and Considerations in Serving RAG
- 用户体验:确保适合实时应用的快速响应时间。
- 成本效率:管理提供数百万响应的相关成本。
- 准确性:确保输出准确,以避免错误信息。
- 及时性和相关性:保持响应和内容与最新数据同步。
- 业务上下文意识:将大语言模型的响应与特定业务上下文对齐。
- 服务可扩展性:在控制成本的同时管理增加的容量。
- 安全与治理:实施数据安全、隐私和治理的协议。
1.9.4 Use Cases and Examples
- 问答聊天机器人:将大语言模型与聊天机器人集成,从公司文件中生成准确的答案,以提升客户支持。
- 搜索增强:通过使用 \(LLM\) 生成的答案增强搜索引擎,提高信息查询的准确性。
- 知识引擎:使用公司数据,利用 \(LLM\) 回答与内部职能相关的问题,例如人力资源和合规。
1.9.5 Considerations for Choosing Between RAG and Fine-Tuning
在考虑外部数据访问时,对于需要访问外部数据源的应用程序,\(RAG\) 可能是一个更好的选择。另一方面,如果您需要模型调整其行为和写作风格,或融入特定领域的知识,则微调更为合适。在抑制幻觉和确保准确性方面,\(RAG\) 系统的表现往往更好,因为它们生成错误信息的概率较低。如果您拥有丰富的特定领域标记训练数据,微调可以实现更量身定制的模型行为,而在数据稀缺的情况下,\(RAG\) 系统则是稳健的替代方案。\(RAG\) 系统在数据频繁更新或变化的环境中提供动态数据检索能力的优势。此外,确保模型决策过程的透明性和可解释性至关重要。在这种情况下,\(RAG\) 系统提供的洞察力在仅进行微调的模型中通常是不可获得的。
下图比较了不同场景中所需的模型适应性与所需的外部知识水平,突显了检索增强生成(\(RAG\))、微调及其在问答系统、客户支持自动化和总结任务等各种上下文中的混合应用的作用。
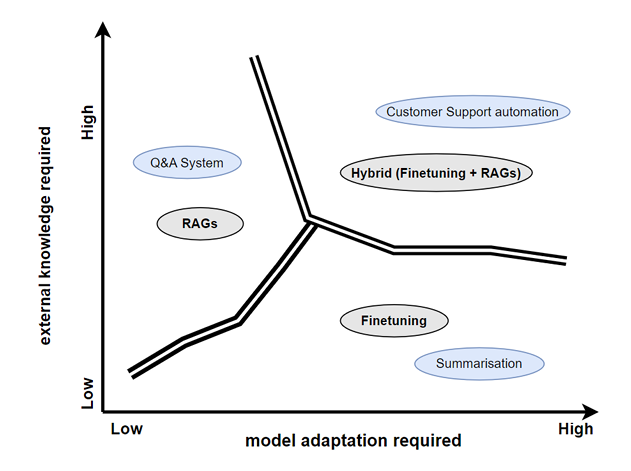
1.10 Objectives of the Report
1.10.1 Goals and Scope
本报告的主要目标是对大语言模型的微调技术进行全面分析。这涉及探讨理论基础、实际实施策略和挑战。报告考察了各种微调方法、它们的应用以及最近的进展。
1.10.2 Key Questions and Issues Addressed
本报告围绕微调大语言模型提出了关键问题,首先深入探讨了 \(LLMs\) 的基础知识、发展历程及其在自然语言处理中的重要性。定义了微调,区别于预训练,并强调其在将模型调整为特定任务中的作用。主要目标包括提高模型在特定应用和领域中的性能。
该报告概述了一个结构化的微调过程,具有高层次的管道、视觉表示和详细的阶段解释。它涵盖了实际实施策略,包括模型初始化、超参数定义,以及参数高效微调(\(Parameter-Efficient\ Fine-Tuning,PEFT\))和检索增强生成(\(RAG\))等微调技术,还探讨了行业应用、评估方法、部署挑战以及最新进展。
1.10.3 Overview of the Report Structure
报告的其余部分提供了对大规模语言模型微调的全面理解。主要章节包括对微调流程的深入研究、实际应用、模型对齐、评估指标和面临的挑战。结尾部分讨论了微调技术的发展,强调了正在进行的研究挑战,并为研究人员和从业者提供了见解。
本文来自博客园,作者:Cocoicobird,转载请注明原文链接:https://www.cnblogs.com/Cocoicobird/p/18950580

 浙公网安备 33010602011771号
浙公网安备 33010602011771号