9.模型选择+过拟合和欠拟合 [跟着沐神-动手学深度学习]
模型选择
训练误差和泛化误差
1. 训练误差(Training Error)
定义:模型在训练数据集上的平均预测误差(即模型“记住”训练数据的能力)。
计算公式(以分类问题为例):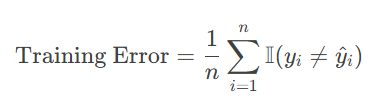
其中n是训练样本,yi是真实标签,模型预测标签
特点:
训练误差低 ≠ 模型好(可能是过拟合)。
优化目标:通过损失函数(如交叉熵、均方误差)直接最小化训练误差。
2. 泛化误差(Generalization Error)
定义:模型在未见过的数据(测试集或真实场景)上的预期误差(即模型“泛化”到新数据的能力)。
计算公式: ![]()
其中Pdata是真实数据分布,L是损失函数,f(x)是模型预测。
特点:
泛化误差是模型能力的终极评价标准。
无法直接计算(因为真实数据分布未知),通常用测试集误差近似。
训练误差(training error)是指, 模型在训练数据集上计算得到的误差。 泛化误差(generalization error)是指, 模型应用在同样从原始样本的分布中抽取的无限多数据样本时,模型误差的期望。
验证数据集和测试数据集
·验证数据集:一个用来评估模型好坏的数据集
·例如拿出 50% 的训练数据
·不要跟训练数据混在一起(常犯错误)
·测试数据集:只用一次的数据集。例如
·未来的考试
·我出价的房子的实际成交价
·用在 Kaggle 私有排行榜中的数据集
K-则交叉验证
在没有足够多数据时使用
算法:
将训练数据分割成 K块
For i= 1, .., K
使用第i块作为验证数据集,其余的作为训练数据集
报告K个验证集误差的平均
常用:K=5或10
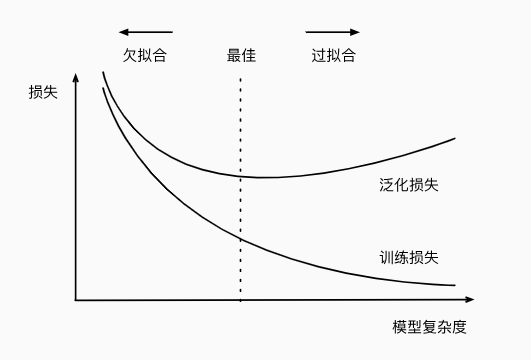
过拟合和欠拟合
什么是过拟合和欠拟合?

模型容量:拟合各种函数的能力,低容量的模型难以拟合训练数据,高容量的模型可以记住所有的训练数据
过拟合
定义:模型在训练数据上表现极好(训练误差很低),但在测试数据或新数据上表现差(泛化误差高)。即:模型“死记硬背”训练数据,但无法泛化到新数据。
表现:训练误差 ≈ 0,但测试误差远高于训练误差。模型对训练数据中的噪声或异常值过于敏感。
原因:1.模型复杂度过高(如神经网络层数太多、决策树过深)。2.训练数据不足(模型“记住”了少量样本)。3.数据噪声大(模型拟合了噪声而非真实规律)。4.训练迭代次数过多(在梯度下降中,模型过度优化训练数据)。
欠拟合
定义:模型在训练数据和测试数据上表现均较差(训练误差和泛化误差都很高)。即:模型“学不会”数据中的规律,拟合能力不足。
表现:训练误差高,测试误差也高。模型预测能力弱,无法捕捉数据的关键特征。
原因:1.模型过于简单(如线性模型拟合非线性数据)。2.特征工程不足(未提取有效特征)。3.训练不足(如训练轮次太少,梯度下降未收敛)。4.数据噪声过大(模型无法学习有效模式)。
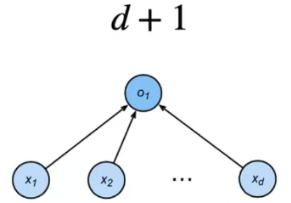
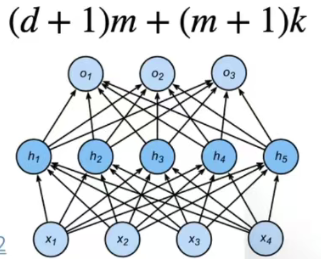
估计模型容量
·难以在不同的种类算法之间比较
·例如数模型和神经网络
·给定一个模型种类,将有两个主要因素
·参数的个数
·参数值的选择范围

 浙公网安备 33010602011771号
浙公网安备 33010602011771号