8.多层感知机+代码实现 [跟着沐神-动手学深度学习]
感知机
·给定输入x,权重w,和偏移b,感知机输出:
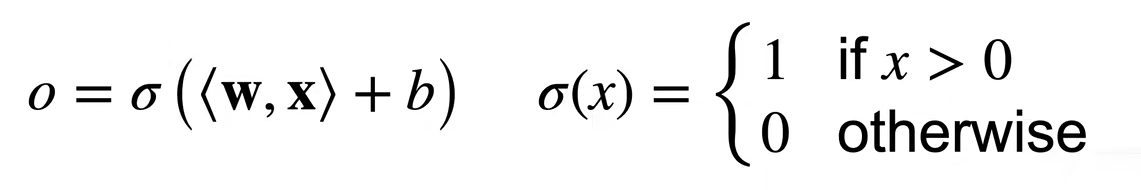
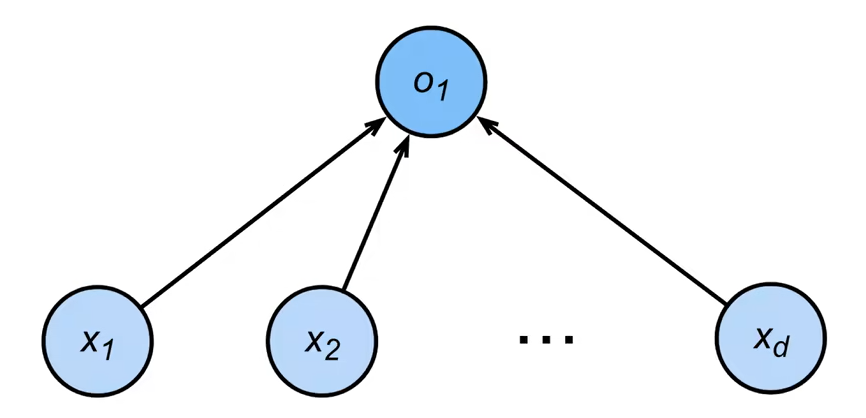
二分类:-1或1。二分类Vs线性回归输出的是实数 二分类 Vs Softmax回归输出的是概率 (Softmax可以做多分类)
训练感知机
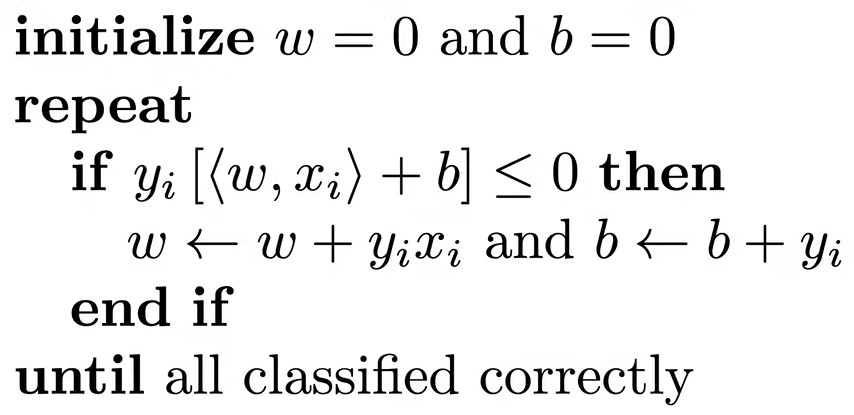
这个算法算是一个梯度下降,等价于使用批量大小为1的梯度下降,并使用损失函数![]()
例子
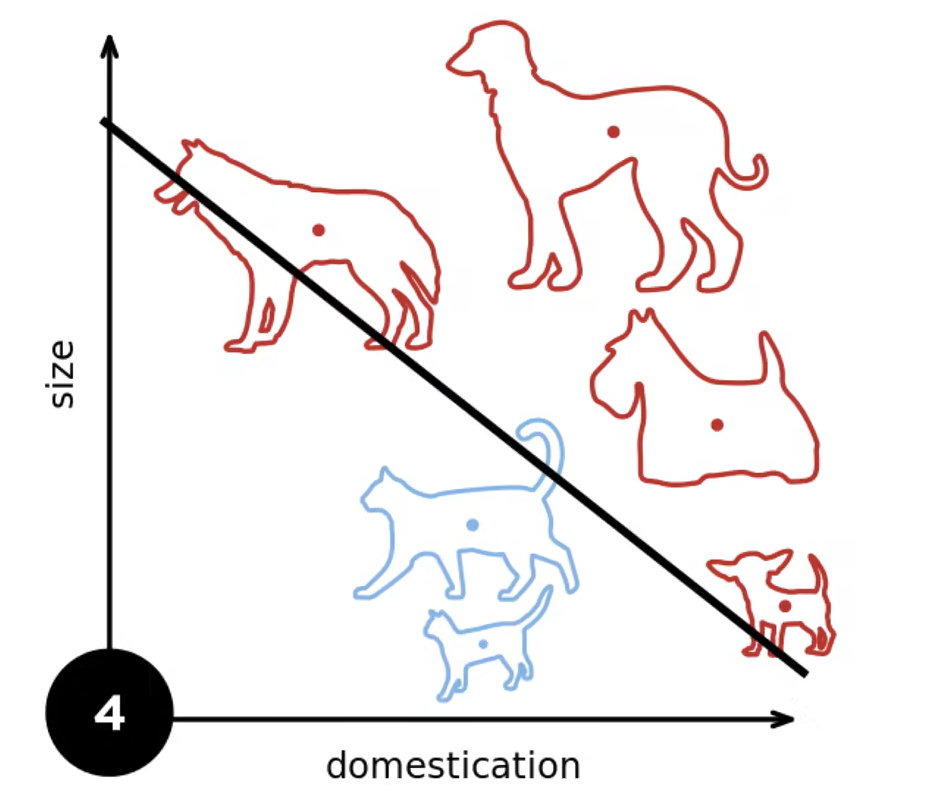
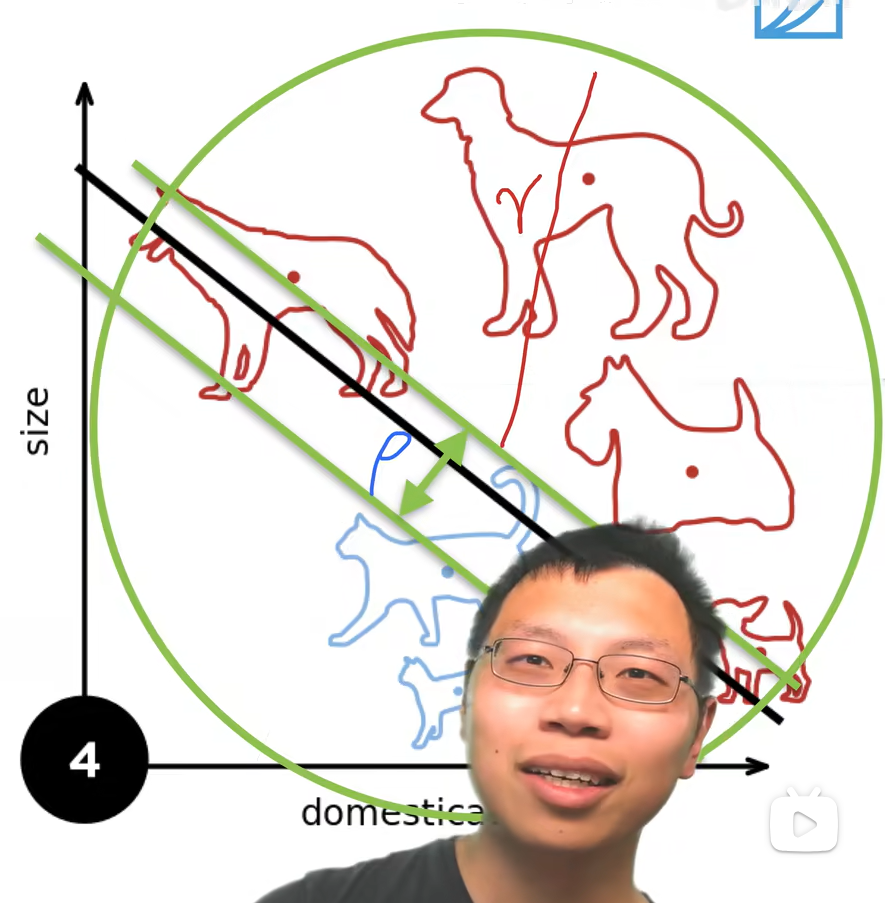
收敛定理
·数据在半径r内
·余量ρ分类两类 ![]() 对于
对于 ![]()
·感知机保证在![]() 步后收敛
步后收敛
XOR问题(Minsky & Papert,1969)
感知机不能拟合XOR函数,它只能产生线性分割面
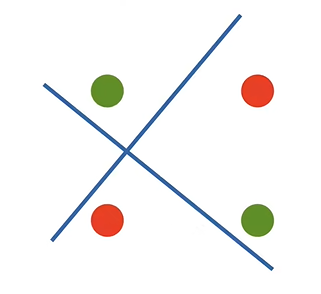
1.感知机是一个二分类模型,是最早的AI模型之一 2.它的求解算法等价于使用批量大小为1的梯度下降 3.它不能拟合XOR函数,导致第一次AI寒冬
多层感知机
学习XOR
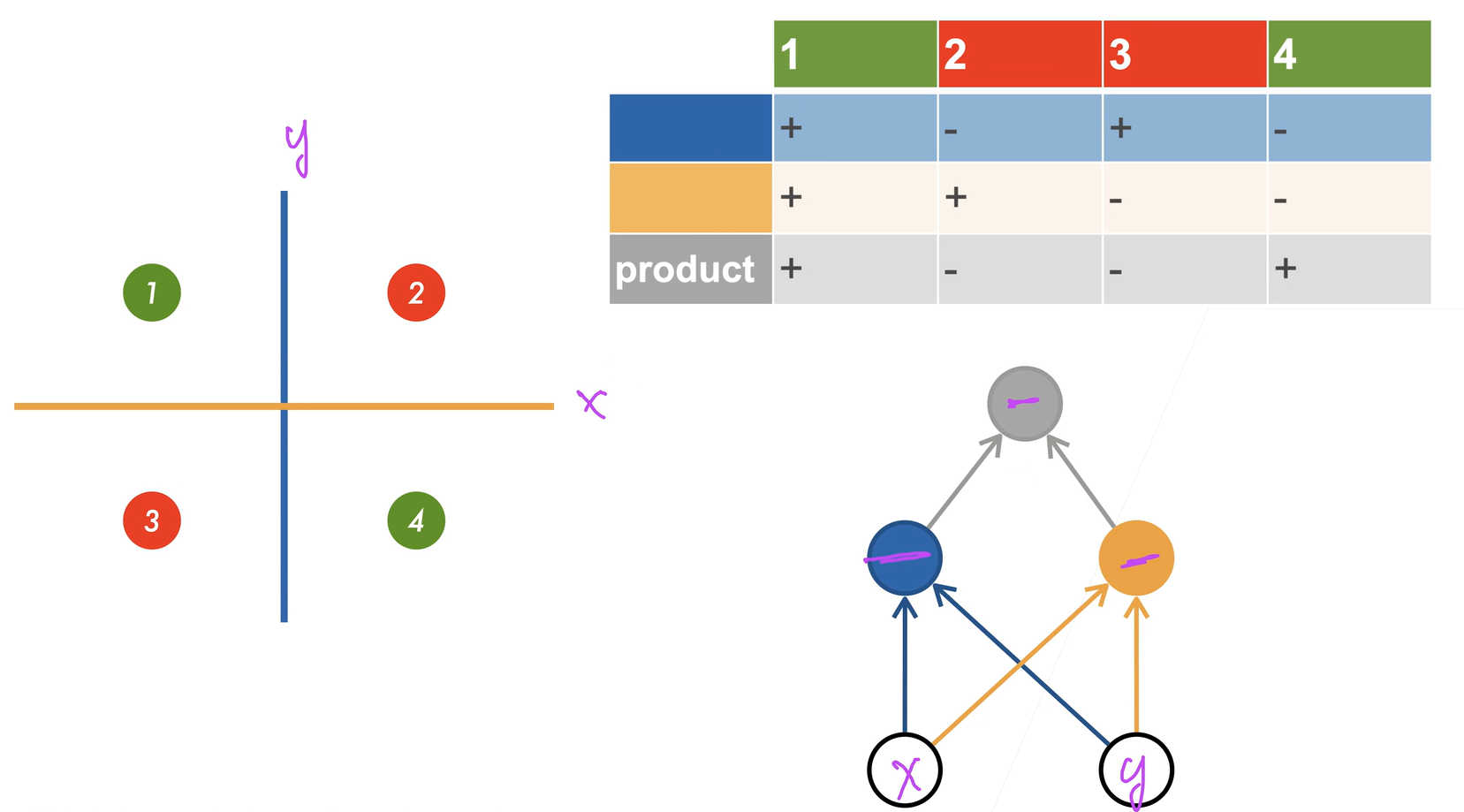
将四个类进行线性分类无法完成,采用多层感知机进行
单隐藏层
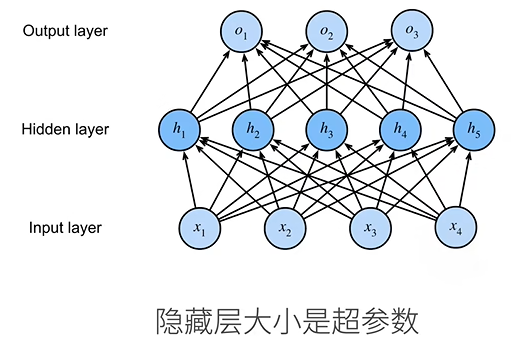
单分类
·输入X∈Rn
·隐藏层W1∈Rm×n ,b1∈Rm
·输出层W2∈Rm,b2∈R 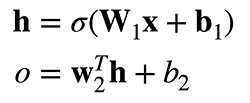 σ是按元素的激活函数
σ是按元素的激活函数
为什么需要非线性激活函数?
![]() 任然是线性,σ不能是线性函数,不然就等价于单层感知机
任然是线性,σ不能是线性函数,不然就等价于单层感知机
Sigmoid激活函数
将输入投影到(0,1),是一个软的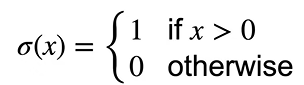
![]()
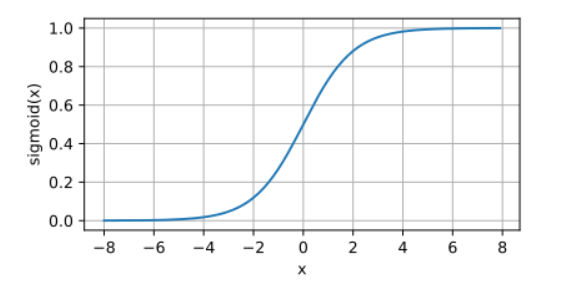
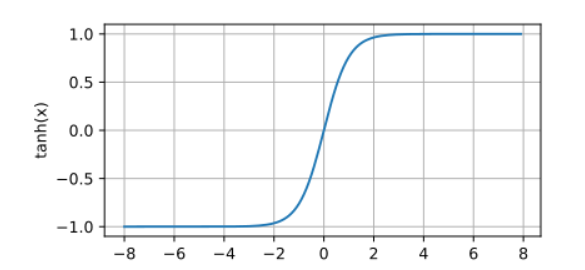
Tanh激活函数
将投影到(-1,1)
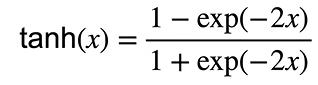
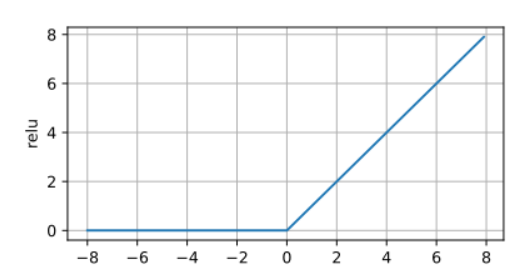
ReLU激活函数
ReLU:rectified Linear unit
![]()
多类分类
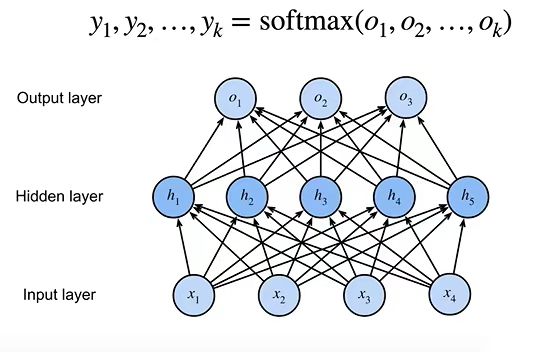
·输入X∈Rn
·隐藏层W1∈Rm×n ,b1∈Rm
·输出层W2∈Rm×k,b2∈Rk
y = softmax(o)
多隐藏层
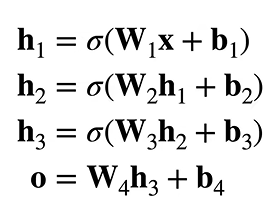
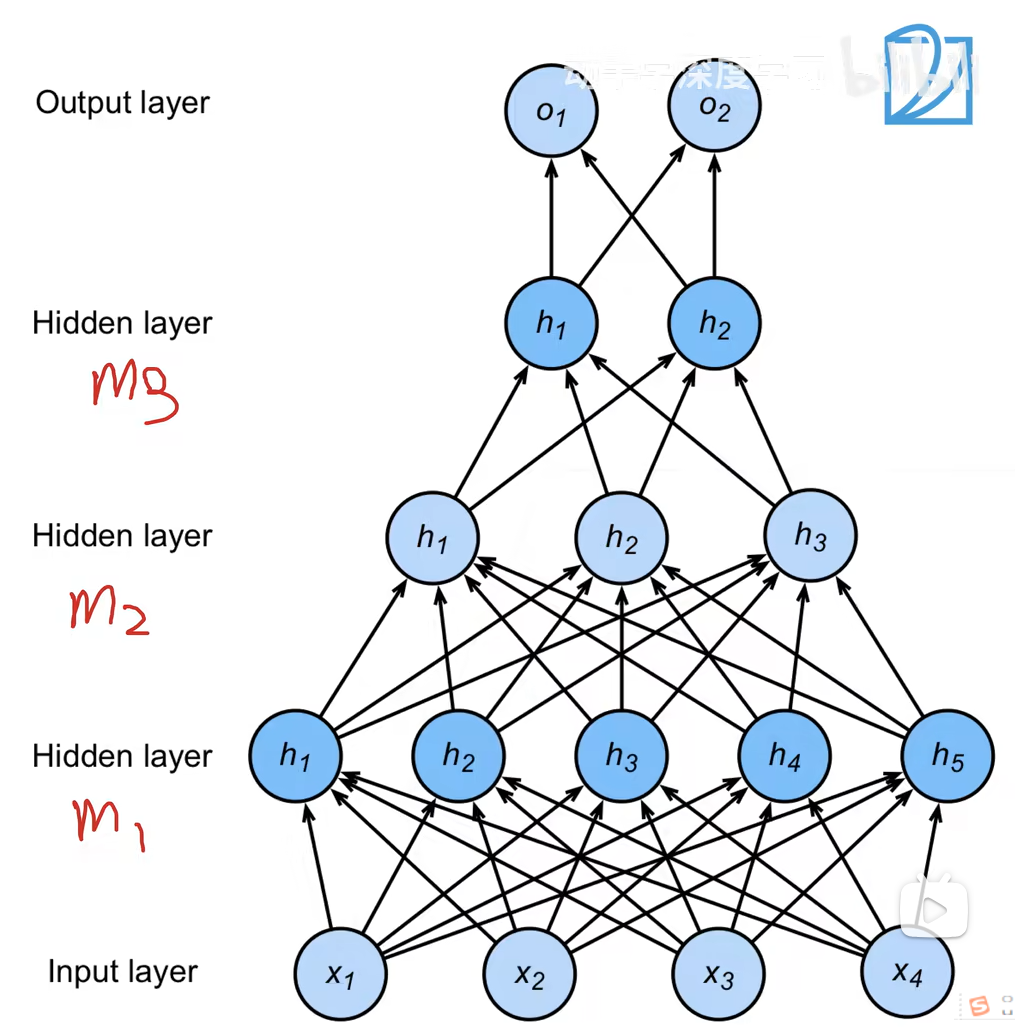
超参数:1.隐藏层数 2.每层隐藏层的大小
·多层感知机使用隐藏层和激活函数来得到非线性模型
·常用激活函数Sigmoid ,Tanh ,ReLU
·使用Softmax来处理多类分类
·超参数为隐藏层数,和各个隐藏层大小
多层感知机从零开始
实现一个具有单隐藏层的多层感知机,它包含256个隐藏单元
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
num_inputs=784:输入层大小,对应MNIST数据集中28×28=784像素的图像 num_outputs=10:输出层大小,对应10个数字类别(0-9) num_hiddens=256:隐藏层大小(256个神经元)
权重和偏置参数:
第一层权重 W1:形状:784×256(输入层→隐藏层)用标准正态分布初始化后缩小100倍(防止初始值过大)requires_grad=True 表示需要计算梯度(用于反向传播)
第一层偏置 b1:形状:256维向量(与隐藏层对应)初始化为全0 初始化为零梯度为0,参数不会更新,相当于隐藏层只有一个单元
第二层权重 W2:形状:256×10(隐藏层→输出层) 同样缩小初始化值
第二层偏置 b2:形状:10维向量(与输出层对应)
实现ReLU激活函数
 生成一个形状大小和数据类型一样但元素全为0,求一个最大值
生成一个形状大小和数据类型一样但元素全为0,求一个最大值
实现模型
 -1转成二维,输出:第一层的输出与第二层的权重做矩阵乘法加上偏差
-1转成二维,输出:第一层的输出与第二层的权重做矩阵乘法加上偏差
训练过程与Softmax过程一样

 浙公网安备 33010602011771号
浙公网安备 33010602011771号