7.Softmax回归+损失函数+图片分类数据集 [跟着沐神-动手学深度学习]
Softmax回归
分类问题
从图片分类问题开始,可以用一个标量表示每个像素值,每个图像对应四个特征x1,x2,x3,x4,假设每个图像属于类别“猫”“鸡”和“狗”中的一个。
然后,我们要选择如何表示标签。 我们有两个明显的选择:最直接的想法是选择, 其中整数分别代表狗猫鸡。 这是在计算机上存储此类信息的有效方法。
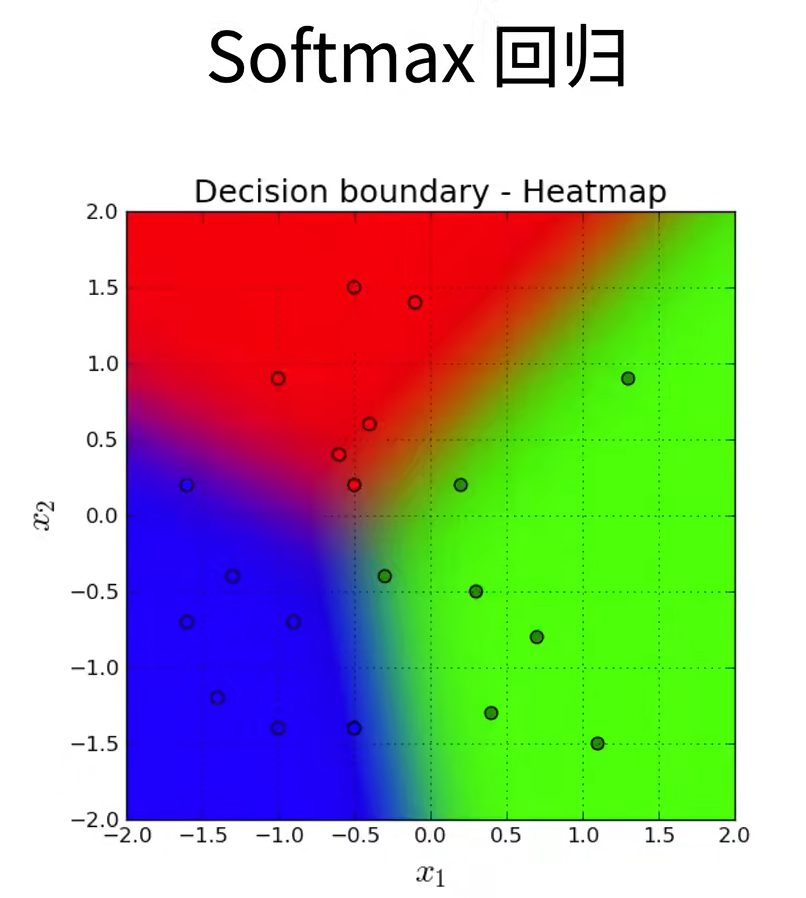
经典的分类例子:
手写数字识别

Kaggle上的分类问题
1.将人类蛋白质显微镜图片分成28类
2.恶意软件分类
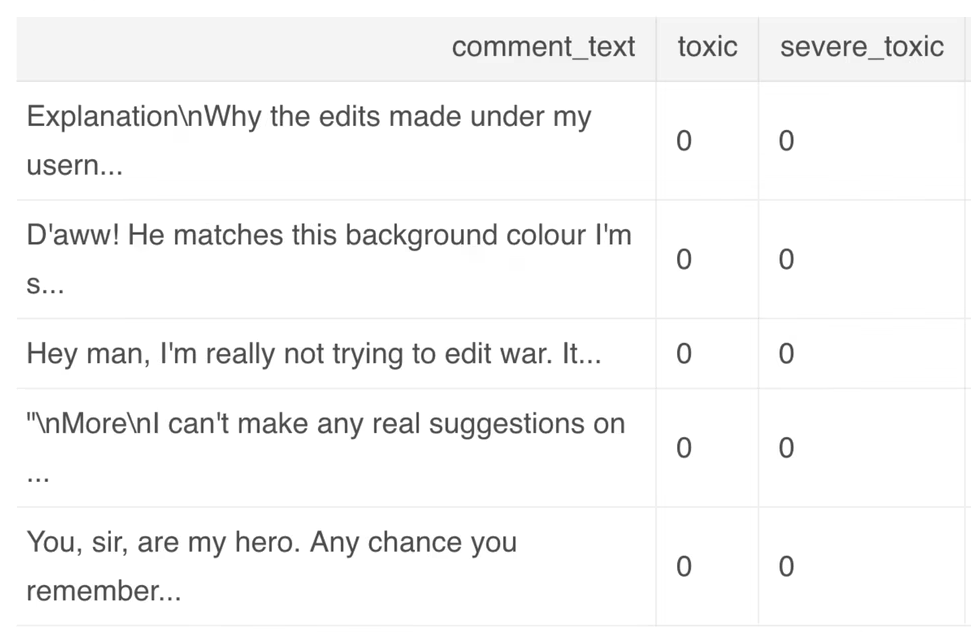
3.恶意评论分类
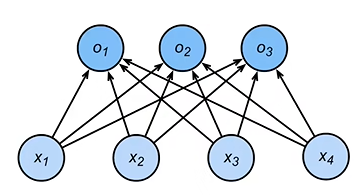
从回归过渡到分类问题
回归与分类的相似:
回归:1.单连续数值输出 2.自然区间R 3.跟真实的区别作为损失
分类:1.通常多个输出 2.输出i是预测为第i类的置信度
均方损失
对类别进行一位有效编码 y = [y1,y2,....,yn]T ,yi为1则i=y,为0则为其他类别。使用均方损失训练
无校验比例
对类别进行一位有效编码
置信度Oy - Oi 远远大于 Δ(y,i)
输出匹配概率(非负,和为1)

这里,对于所有的j总有0≤yi≤1。 因此,可以视为一个正确的概率分布。 softmax运算不会改变未规范化的预测之间的大小次序,只会确定分配给每个类别的概率。
Softmax和交叉熵损失
交叉熵常用来衡量两个概率的区别 ![]() ,关心正确类的预测值置信度要够大。
,关心正确类的预测值置信度要够大。

损失函数
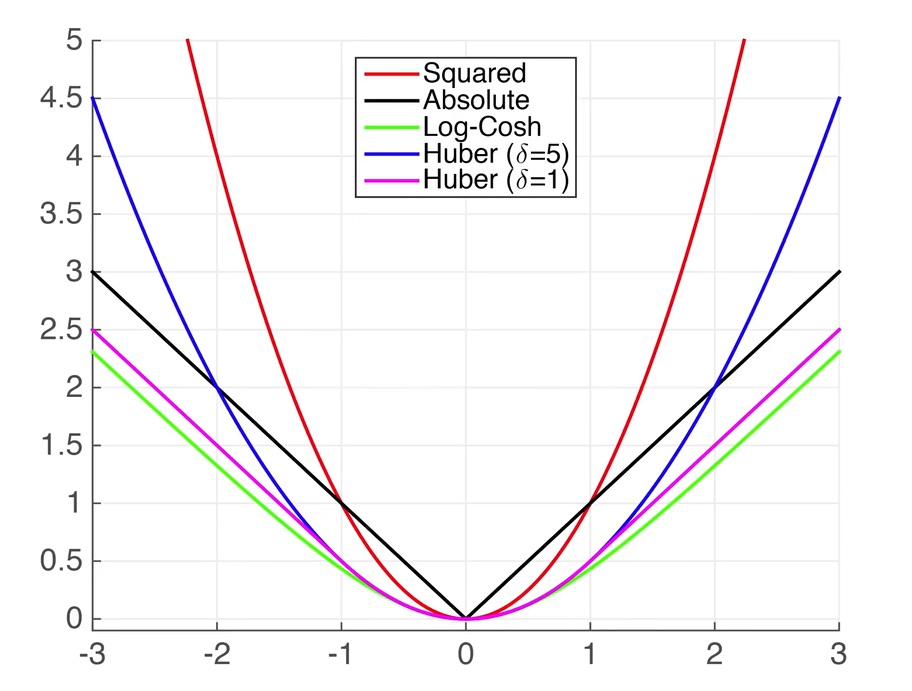
损失函数用来衡量预测值和真实值之间的区别是机器学习重要的概念。
L2 Loss
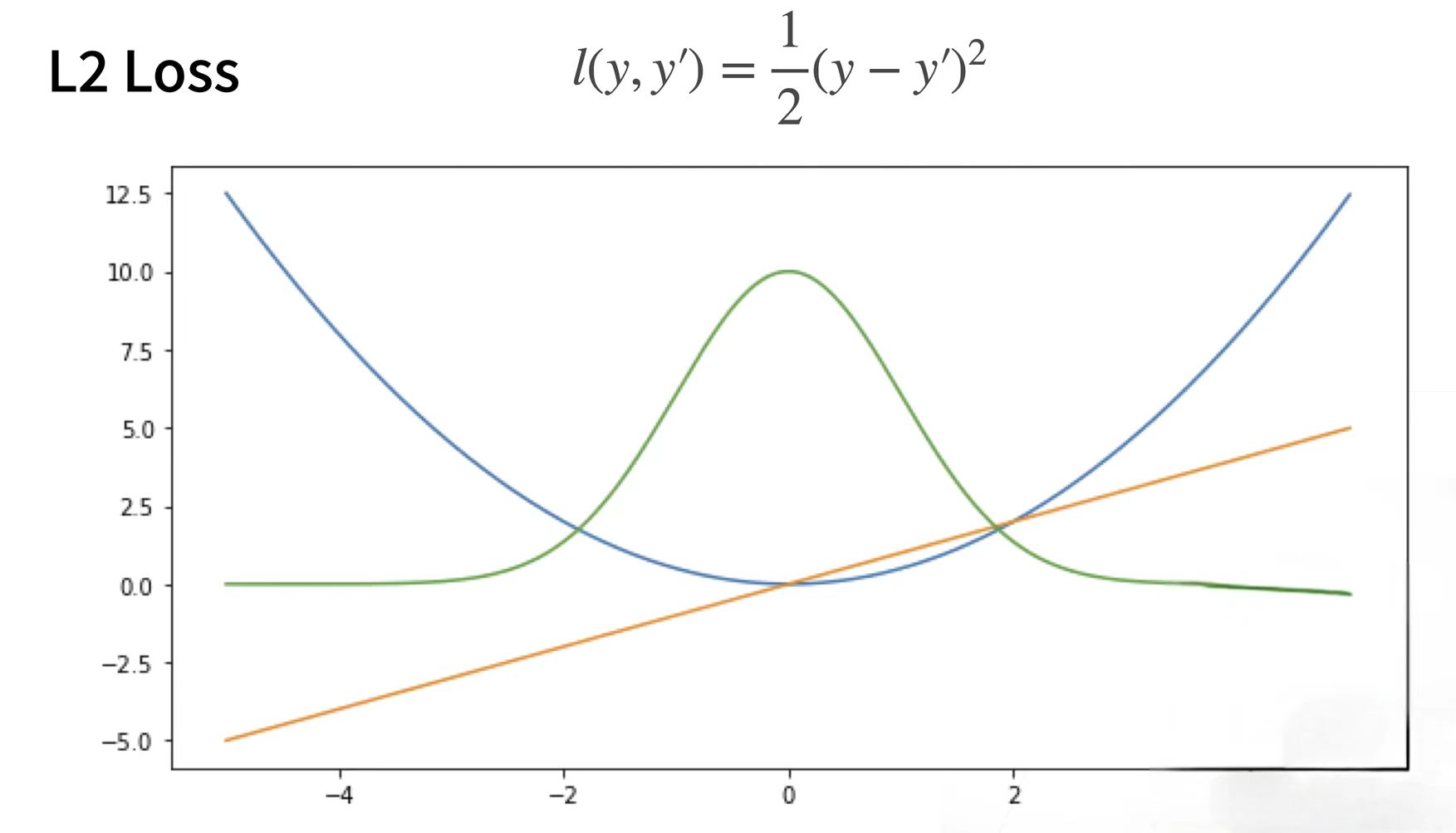
蓝色的曲线表示:当y为0时,变换预测值y'
橙色的:表示损失函数的梯度
绿色:表示似然函数e的-l次方(高斯分布)
L1 Loss
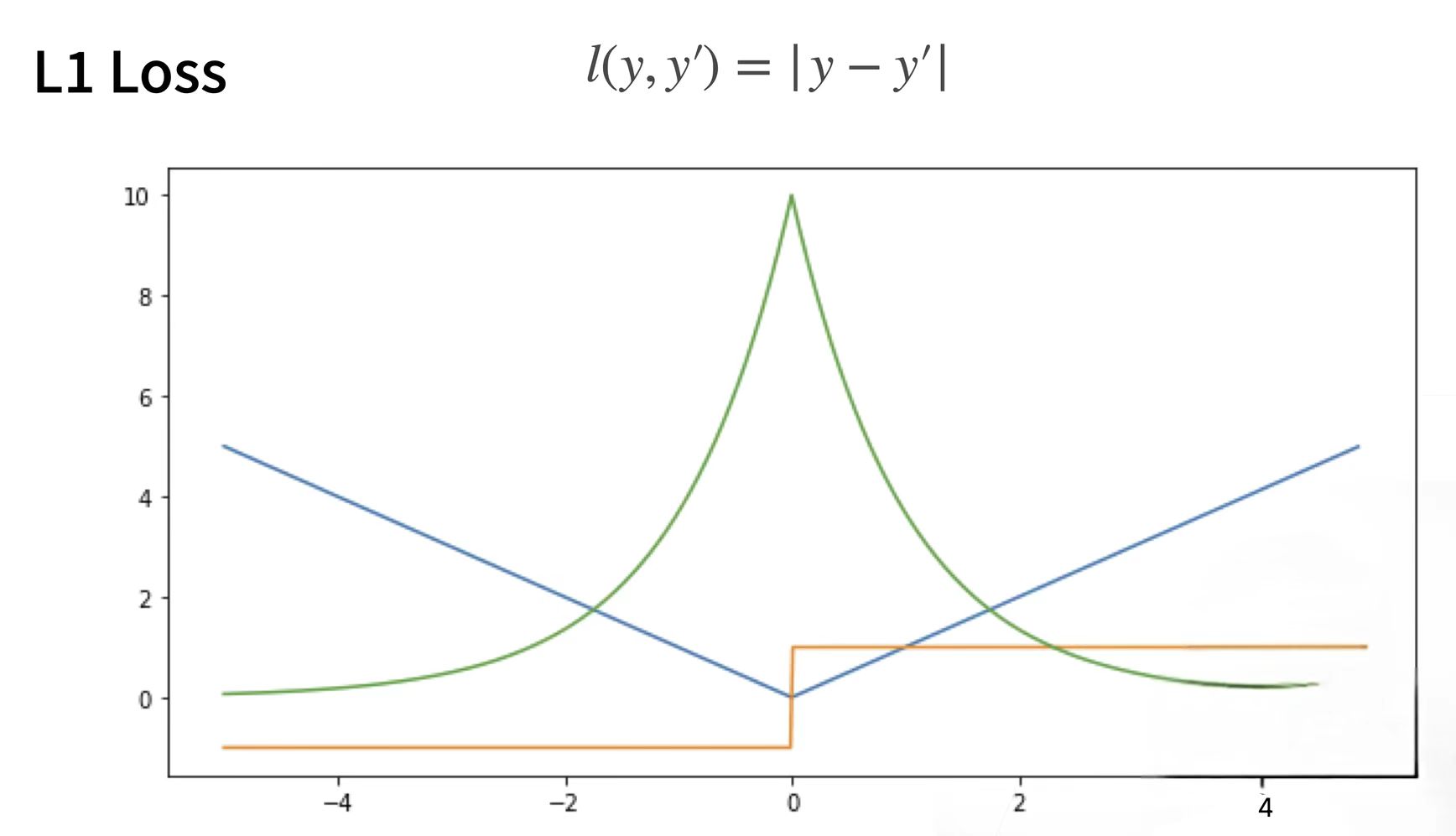
绝对值损失函数
L1 loss在零点不平滑,用的较少。一般来说,L1正则会制造稀疏的特征,大部分无用的特征的权重会被置为0。 (适合回归任务,简单的模型,由于神经网络通常解决复杂问题,很少使用。)
L2 loss:对离群点比较敏感,如果feature是unbounded的话,需要好好调整学习率,防止出现梯度爆炸的情况。L2正则会让特征的权重不过大,使得特征的权重比较平均。 (适合回归任务,数值特征不大,问题维度不高)
用一个新的损失函数结合L1 Loss 和 L2 Loss的好处: Huber`s Robust Loss
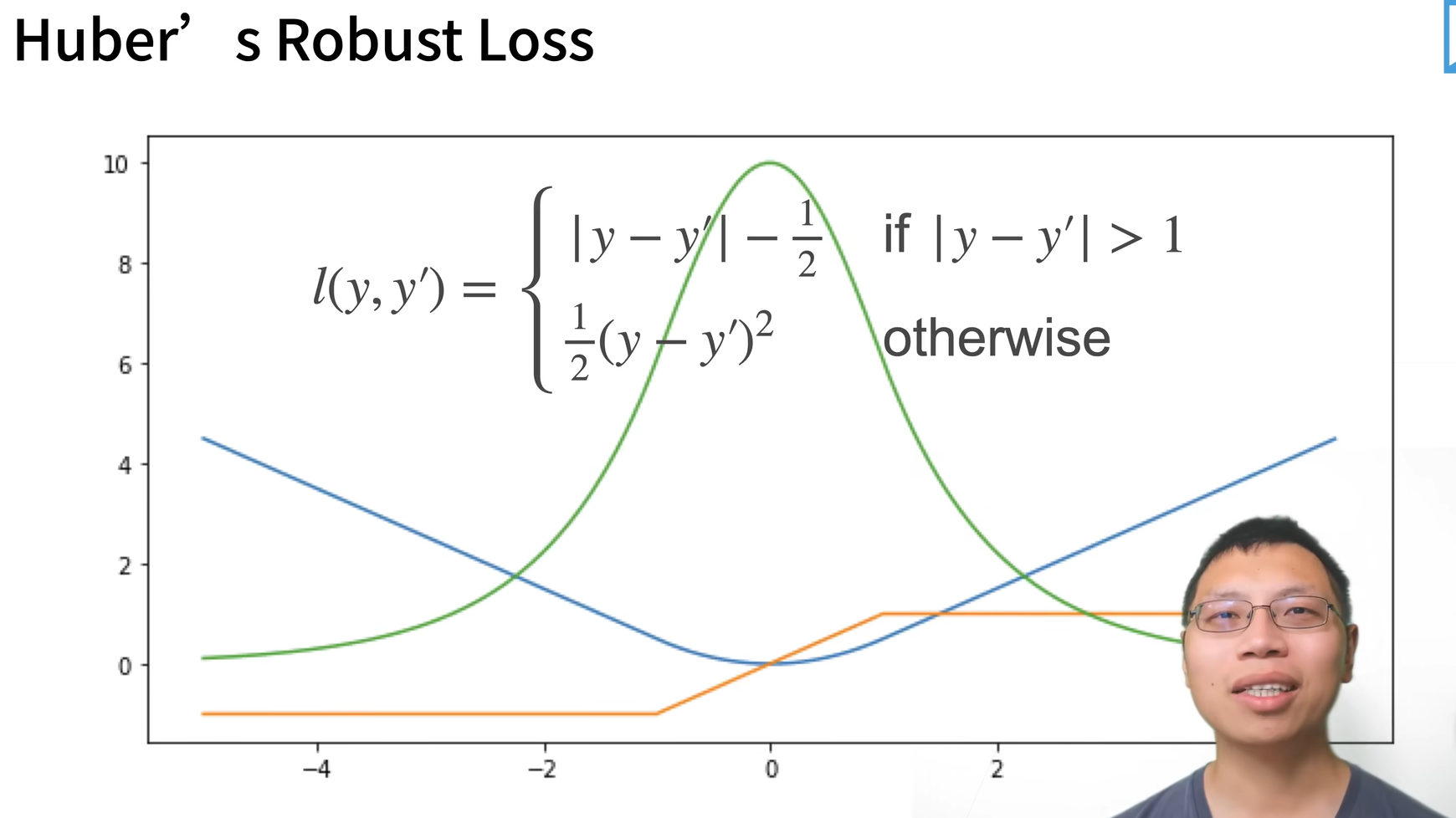
定义:当预测值与真实值相差比较大的时候(绝对值大于1时),这是一个绝对值误差;当预测值与真实值靠得比较近的时候(小于等于1时),为一个平方误差。
好处:当预测值与真实值相差比较远时,不管怎样梯度都在往回拉,保证优化平滑。
图片分类
对多类分类的数据集读取
torchvision:pytorch对于计算机视觉模型识别的一个库
通过框架中的内置函数将数据集下载并读取到内存中,Transforms.ToTensor将图片转成pytorch的一个tensor
 将图片集下载到上级目录的data中,train下载的为训练数据集,Transform=trans表示得到的是pytorch的tensor而不是一堆图片,download=true默认网上下载。
将图片集下载到上级目录的data中,train下载的为训练数据集,Transform=trans表示得到的是pytorch的tensor而不是一堆图片,download=true默认网上下载。
test_data唯一不一样的是train等于Flase
softmax回归的从零开始实现
pytorch/chapter_linear-networks/softmax-regression-scratch.ipynb
Softmax初始化权重参数与偏置项在本实现中,每个图像被展平为长度为784的向量(图片大小 28*28=784),如何初始化参数 W 和 b,其中权重参数使用均值为 0、标准差为 0.01 (偏移)的正态分布随机生成,而偏置初始化为 0。10为模型输出维度(数据集中有10个类别)。

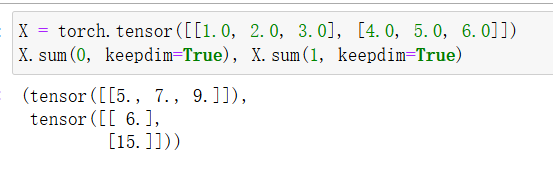
sum运算符如何沿着张量中的特定维度工作,同一列:轴0,同一行:轴1。下面的X形状为(2,3)的张量。
实现Softmax的操作
实现Softmax的步骤:
1.对每个项求幂(exp);
2.对每一行求和(小批量中每个样本是一行),得到每个样本的规范化常数;
3.将每一行除以规范化常数,确保结果和为1。

softmax函数的核心在于它将输入的分数转换为概率分布,对于一个向量X的每一个分量Xij,先将所有类别的原始分数通过指数函数转换为正数,再通过总和归一化,确保所有概率之和为 1,这样模型的输出就是一个概率分布,可以用来做分类预测。
keepdim 参数决定是否保留原始张量的维度大小。keepdim=True 会保留求和的维度,但该维度的大小会变为 1;而 keepdim=False(默认)会将求和的维度去掉。
在每个sum函数中,每个dim参数指定了在哪个维度上进行求和操作。Softmax在特定的维度上计算指数和,然后在该维度上进行归一化,得到概率分布。

实现Softmax回归模型
 代码定义了输入如何通过网络映射到输出,使用了reshape函数将每张原始图像展平为向量。
代码定义了输入如何通过网络映射到输出,使用了reshape函数将每张原始图像展平为向量。
·输入:X 是一个输入特征张量(通常是批量数据)。 ·输出:经过 Softmax 后的概率分布(每个类别的预测概率)。
(1)X.reshape((-1, W.shape[0])) 作用:将输入 X 展平成二维矩阵,形状为 [batch_size, num_features]。 -1 表示自动计算该维度大小(根据输入总元素数和 W.shape[0] 推断)。 W.shape[0] 是权重矩阵 W 的第一维大小,对应输入特征的维度。
示例: 若 X 是 3D 张量(如图像数据形状为 [batch_size, height, width]),展平后变为 [batch_size, height * width]。 若 X 已经是二维的(如 [batch_size, num_features]),则 reshape 无实际变化。
(2)torch.matmul(展平后的X, W) 矩阵乘法:计算线性变换 XW。 输入形状:[batch_size, num_features]。 权重 W 形状:[num_features, num_classes]。 输出形状:[batch_size, num_classes](每个样本对每个类别的得分)。
(3)+ b 添加偏置:对线性变换的结果加上偏置项 b(形状为 [num_classes])。 广播机制会自动将 b 加到每个样本的输出上。
(4)Softmax 函数:将线性得分转换为概率分布。 公式:![]() 。 输出形状:[batch_size, num_classes],每行是一个样本的类别概率(和为1)。
。 输出形状:[batch_size, num_classes],每行是一个样本的类别概率(和为1)。
交叉熵损失函数

创建一个数据样本y_hat,其中包含2个样本在3个类别的预测概率, 以及它们对应的标签y,使用y作为y_hat中概率的索引。取出第0个样本索引为0的数和第1个样本索引为2的数。
实现交叉熵损失函数
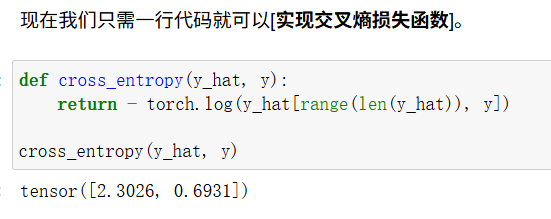
做的是分类问题,因此需要将预测类别与真实y元素进行比较
 按照每一行,取预测概率最大的类别作为预测结果,并与真实标签进行比较。
按照每一行,取预测概率最大的类别作为预测结果,并与真实标签进行比较。
·y_hat.argmax(axis=1):返回预测概率最大的类别索引。 cmp:判断预测类别和真实类别是否相同,并转换为浮点数求和。
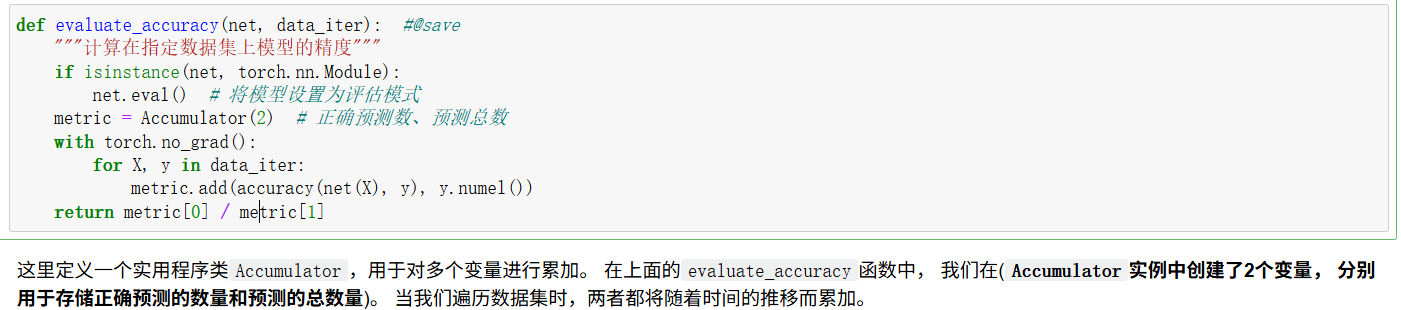
evaluate_accuracy函数用于在测试集上评估模型精度:
isinstance(object, class_or_type):object:要检查的对象。 class_or_type:类(类型)或由类/类型组成的元组。 返回值:如果 object 是 class_or_type 的实例(或元组中某一类的实例),返回 True;否则返回 False。
Accumulator 是一个辅助类,用于记录训练过程中的损失和精度. :

Softmax回归的训练
train_epoch_ch3函数会遍历训练数据集的所有批次,计算损失、更新模型参数,并统计训练损失和准确率。
·使用nn.Module,net.train()需要计算梯度。
·使用长度为3的迭代器来累加需要的信息
·train_iter:每次迭代返回一个批次的 X(输入特征)和 y(真实标签)。 例如:X.shape = [batch_size, ...],y.shape = [batch_size]。
·y_hat:模型的预测输出(logits)。 l:当前批次的损失值(可能是标量或向量,取决于 loss 的实现)。
·zero_grad():清除之前累积的梯度。 mean().backward():对批次的损失取平均后反向传播。 step():根据梯度更新模型参数。
·sum().backward():对批次的损失求和后反向传播。 updater(X.shape[0]):调用自定义的更新方法(例如手动实现 SGD)。
·累加的值: 1.当前批次的损失总和(float(l.sum()))。 2.当前批次的正确预测数(accuracy(y_hat, y))。 3.当前批次的样本数(y.numel())。
·计算均值: 平均训练损失 = 总损失 / 总样本数(metric[0] / metric[2])。 平均训练准确率 = 总正确数 / 总样本数(metric[1] / metric[2])。
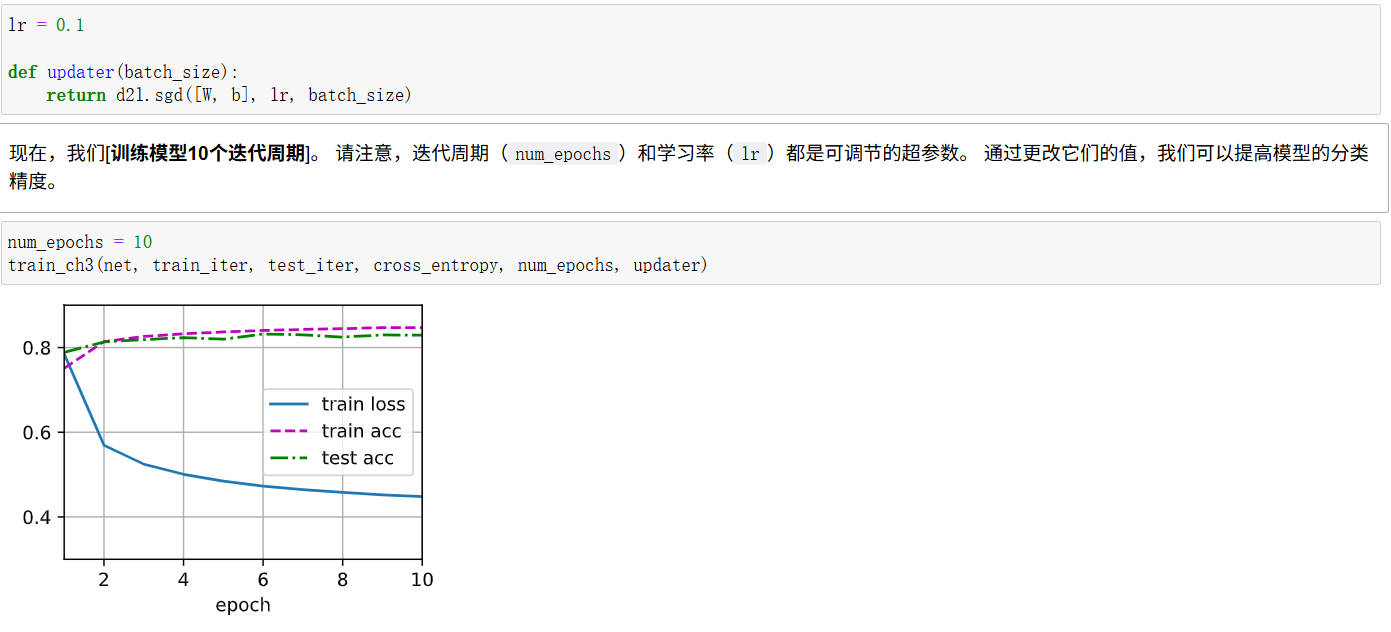
模型的训练

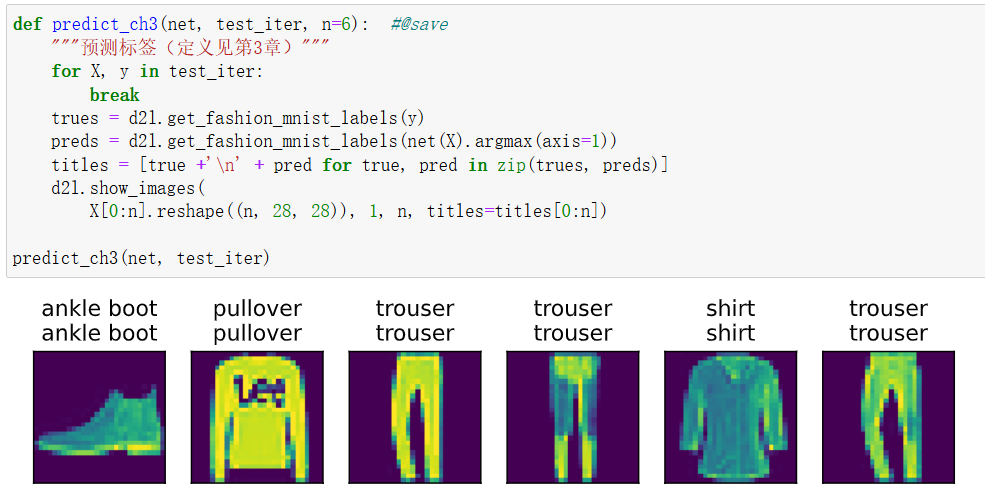
预测

 浙公网安备 33010602011771号
浙公网安备 33010602011771号