浅说并查集
浅说并查集
并查集是一种树形的数据结构,顾名思义,它用于处理一些集合的合并及查询问题。
初始化
并查集的基础是一个数组 \(fa\):\(fa_x\) 代表 \(x\) 的“上级”。初始每个点的“父亲”都是它自己,即 \(fa_i=i\)。
之后并查集的题目会给出一些关系,将一些点连接起来,所以这些点的父亲可能会发生改变:
for(int i=1;i<=n;i++) fa[i]=i;
合并及查询
并查集的核心。
查询
在并查集的题目中,我们会知道所有点的“父亲”是谁。那我们怎么知道这个点最老的祖先是谁呢?
对于这个点,只需要一层一层地往上查询,就能知道这个点最老的祖先了。
我们可以用递归思想求出这个点最老的祖先:
int find(int x){
if(fa[x]==x) return x;
return find(fa[x]);
}
你也可以使用三目运算符缩小代码复杂度:
int find(int x){
return fa[x]==x?x:find(fa[x]);
}
合并
查询都有了,那合并总得弄一个吧。不合并怎么知道这个点的祖先到底是谁。
如下图,直接把一棵树合并到另一棵树里(合并树根就行了):
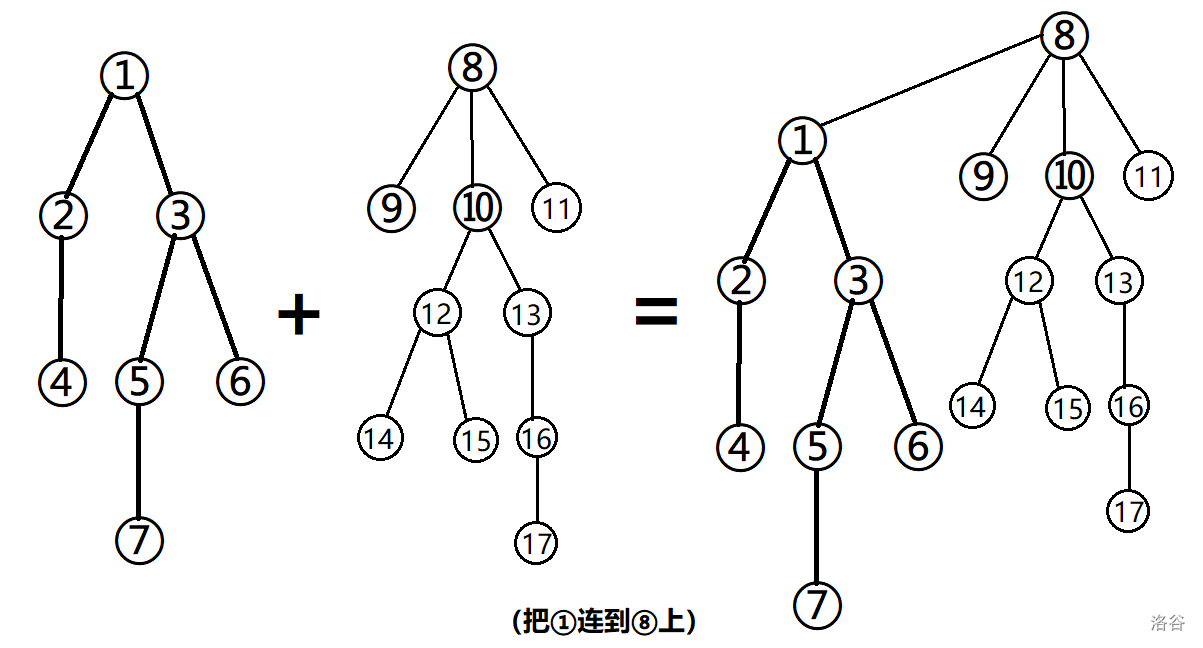
都看到了,要把两个数合并到一个集合里,得把这两个集合的根节点中的一个连到另一个上:
void connent(int x,int y){
int fx=find(x),fy=find(y);
if(fx!=fy) fa[fx]=fy;
}
优化
查询优化:路径压缩
众所周知,我们在查询的时候,如果树的高度太高,查询的时候这个时间复杂度就很难受。得想个优化办法!
想一下,如果把每一个点的“父亲”直接变成它最老的祖先,不就行了吗?
这个操作只需在查询的同时更改每个点的上级就行了:
int find(int x){
if(fa[x]==x) return x;
return fa[x]=find(fa[x]);
}
或三目运算符:
int find(int x){
return fa[x]==x?x:fa[x]=find(fa[x]);
}
这个方法可以超级有效地优化时间复杂度,但是会破坏树的结构,在一些情况下不能使用。
合并优化:按秩合并
这个优化方法可以从根本上解决树的高度的问题。
很简单,只要开一个 \(h\) 数组记录每一棵树的高度,再把高度低的树合并到高度高的树上:
void connent(int x,int y){
int fx=find(x),fy=find(y);
if(fx!=fy){
if(h[fx]<h[fy]) fa[fx]=fy;
else if(h[fx]>h[fy]) fa[fy]=fx;
else fa[fx]=fy,h[fy]++;
}
}
优化总结
路径压缩和按秩合并同时使用,查询操作的时间复杂度有时甚至可以降到 \(O(1)\)。
路径压缩的优化程度直接把我 \(1.2\texttt s\) 的数据点直接降到 \(700\texttt{ms}\) 了(洛谷题库)。
按秩合并没有路径压缩的优化效果强。所以我喜欢只用路径压缩。其实是我懒得打按秩合并。
最小生成树:\(\textrm{Kruskal}\)
从边入手的求最短路的算法。
基于贪心;从小到大加边。加边、合并、查找的操作都基于并查集。
给边的权值排序,再从小到大(最大生成树反过来)扫一遍,计数到 \(n-1\) 时停止算法,输出答案。扫的过程中,如果两个点的祖先不一样,及两个点尚未联通,我们才能添加这两个点之间的路径:
int kruskal(){
sort(a+1,a+m+1,cmp);
int sum=0,egs=0;
for(int i=1;i<=m;i++){
int fs=find(a[i].s),ft=find(a[i].t);
if(fs!=ft){
sum+=a[i].v,egs++;
fa[fs]=ft;
if(egs==n-1) return sum;
}
}
return -1;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号