TCP/IP协议栈在Linux内核中的运行时序分析
一.概述
1.Linux系统概述
Linux,全称GNU/Linux,是一种免费使用和自由传播的类Unix操作系统,其内核由林纳斯·本纳第克特·托瓦兹于1991年10月5日首次发布,它主要受到Minix和Unix思想的启发,是一个基于POSIX和Unix的多用户、多任务、支持多线程和多CPU的操作系统。它能运行主要的Unix工具软件、应用程序和网络协议。它支持32位和64位硬件。Linux继承了Unix以网络为核心的设计思想,是一个性能稳定的多用户网络操作系统。Linux有上百种不同的发行版,如基于社区开发的debian、archlinux,和基于商业开发的Red Hat Enterprise Linux、SUSE、Oracle Linux等。

1.1 Linux内核整体架构和子系统划分

上图说明了Linux内核的整体架构。根据内核的核心功能,Linux内核提出了5个子系统,分别负责如下的功能:
1. Process Scheduler,也称作进程管理、进程调度。负责管理CPU资源,以便让各个进程可以以尽量公平的方式访问CPU。
2. Memory Manager,内存管理。负责管理Memory(内存)资源,以便让各个进程可以安全地共享机器的内存资源。另外,内存管理会提供虚拟内存的机制,该机制可以让进程使用多于系统可用Memory的内存,不用的内存会通过文件系统保存在外部非易失存储器中,需要使用的时候,再取回到内存中。
3. VFS(Virtual File System),虚拟文件系统。Linux内核将不同功能的外部设备,例如Disk设备(硬盘、磁盘、NAND Flash、Nor Flash等)、输入输出设备、显示设备等等,抽象为可以通过统一的文件操作接口(open、close、read、write等)来访问。这就是Linux系统“一切皆是文件”的体现(其实Linux做的并不彻底,因为CPU、内存、网络等还不是文件,如果真的需要一切皆是文件,还得看贝尔实验室正在开发的"Plan 9”的)。
4. Network,网络子系统。负责管理系统的网络设备,并实现多种多样的网络标准。
5. IPC(Inter-Process Communication),进程间通信。IPC不管理任何的硬件,它主要负责Linux系统中进程之间的通信。
每个部分分别处理一项明确的功能,又向其它各个部分提供自己所完成的功能,相互协调,共同完成操作系统的任务。
在本文中,我们着重需要了解Linux网络子系统
1.2 Linux网络子系统(Network)
网络子系统在Linux内核中主要负责管理各种网络设备,并实现各种网络协议栈(在本篇博客中,主要是表示TCP/IP协议栈),最终实现通过网络连接其它系统的功能。在Linux内核中,网络子系统几乎是自成体系,它包括5个子模块(见下图),它们的功能如下:

- Network Device Drivers,网络设备的驱动,用于控制所有的外部设备及控制器。由于存在大量不能相互兼容的硬件设备(特别是嵌入式产品),所以也有非常多的设备驱动。因此,Linux内核中将近一半的Source Code都是设备驱动,大多数的Linux底层工程师(特别是国内的企业)都是在编写或者维护设备驱动,而无暇估计其它内容(它们恰恰是Linux内核的精髓所在)。
- Device Independent Interface, 该模块定义了描述硬件设备的统一方式(统一设备模型),所有的设备驱动都遵守这个定义,可以降低开发的难度。同时可以用一致的形势向上提供接口。
- Network Protocols,实现各种网络传输协议,例如IP, TCP, UDP等等。
- Protocol Independent Interface,屏蔽不同的硬件设备和网络协议,以相同的格式提供接口(socket)。
- System Call interface,系统调用接口,向用户空间提供访问网络设备的统一的接口。
同大多数操作系统一样,Linux内核采用分层结构来处理网络中的数据包。
Linux分层的结构同网络协议的分层结构相匹配,对网络部分分为了网络协议层、网络设备层、设备驱动功能层和网络媒介层。
2.TCP/IP 协议栈概述
2.1 TCP/IP概念
互联网协议套件(Internet Protocol Suite,缩写IPS)是网络通信模型,以及整个网络传输协议家族,为网际网络的基础通信架构。它常通称为TCP/IP协议族,简称TCP/IP,因为该协议家族的两个核心协议:TCP(传输控制协议)和IP(网际协议),为该家族中最早通过的标准。由于在网络通讯协议普遍采用分层的结构,当多个层次的协议共同工作时,类似计算机科学中的堆栈,因此又称为TCP/IP协议栈。这些协议最早发源于美国国防部(缩写为DoD)的ARPA网项目,因此也称作DoD模型(DoD Model)。这个协议族由互联网工程任务组负责维护。
TCP/IP提供了点对点链接的机制,将资料应该如何封装、寻址、传输、路由以及在目的地如何接收,都加以标准化。它将软件通信过程抽象化为四个抽象层,采取协议堆栈的方式,分别实现出不同通信协议。协议族下的各种协议,依其功能不同,分别归属到这四个层次结构之中,常视为是简化的七层OSI模型。
2.2 TCP/IP 协议栈
TCP/IP 协议栈是一系列网络协议的总和,是构成网络通信的核心骨架,它定义了电子设备如何连入因特网,以及数据如何在它们之间进行传输。TCP/IP 协议采用4层结构,分别是应用层、传输层、网络层和链路层,每一层都呼叫它的下一层所提供的协议来完成自己的需求。由于我们大部分时间都工作在应用层,下层的事情不用我们操心;其次网络协议体系本身就很复杂庞大,入门门槛高,因此很难搞清楚TCP/IP的工作原理,通俗一点讲就是,一个主机的数据要经过哪些过程才能发送到对方的主机上。
在TCP/IP协议栈中,整个通信网络的任务,可以划分成不同的功能块,即抽象成所谓的 ” 层”。用于互联网的协议可以比照TCP/IP参考模型进行分类。TCP/IP协议栈起始于第三层协议IP(互联网协议)。所有这些协议都在相应的RFC文档中讨论及标准化。重要的协议在相应的RFC文档中均标记了状态: “必须“ (required) ,“推荐“ (recommended) ,“可选“ (elective)。其它的协议还可能有“ 试验“(experimental) 或“ 历史“(historic) 的状态。
其中必须协议最为重要,是所有TCP/IP都必须要实现的协议,包括IP和ICMP。对于一个路由器(router) 而言,有这两个协议就可以运作了,虽然从应用的角度来看,这样一个路由器 意义不大。实际的路由器一般还需要运行许多“推荐“使用的协议,以及一些其它的协议。
2.3 OSI模型和TCP/IP模型

TCP/IP五层协议和OSI的七层协议有着对应关系,如下图所示:

其中TCP/IP协议的数据链路层和物理层,可以统称为网络接入层,在对应层面需要通过如下协议来实现层级间的交互。
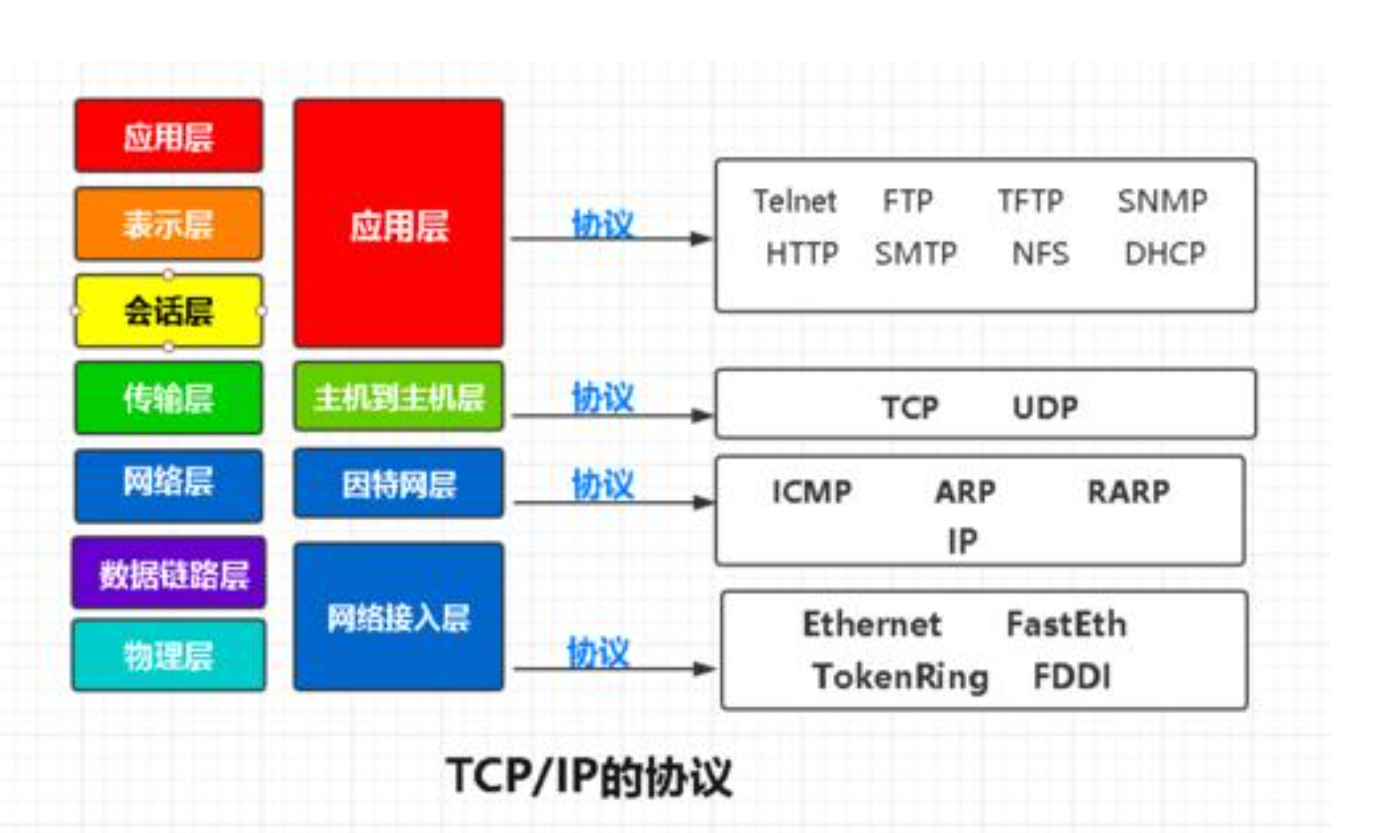
通常人们认为OSI模型的最上面三层(应用层、表示层和会话层)在TCP/IP组中是一个应用层。由于TCP/IP有一个相对较弱的会话层,由TCP和RTP下的打开和关闭连接组成,并且在TCP和UDP下的各种应用提供不同的端口号,这些功能能够由单个的应用程序(或者那些应用程序所使用的库)增加。与此相似的是,IP是按照将它下面的网络当作一个黑盒子的思想设计的,这样在讨论TCP/IP的时候就可以把它当作一个独立的层。
在这里我们着重了解TCP/IP协议组。
3.其他Linux相关概念介绍
3.1 系统调用
unix内核分为用户态和内核态,在用户态下程序不内直接访问内核数据结构或者内核程序,只有在内核态下才可访问。请求内核服务的进程使用系统调用的特殊机制,每个系统调用都设置了一组识别进程请求的参数,通过执行CPU指令完成用户态向内核态的转换。
在Linux系统中,操作系统为用户提供了系统调用的接口,系统调用接口都基本是以sys开头的函数。
3.2 Socket
在操作系统中,通常会为应用程序提供一组应用程序接口(API),称为套接字接口(英语:socket API)。应用程序可以通过套接字接口,来使用网络套接字,以进行资料交换。最早的套接字接口来自于4.2 BSD,因此现代常见的套接字接口大多源自Berkeley套接字标准。在套接字接口中,以IP地址及端口组成套接字地址,它提供一组通用函数来支持各种不同的协议。Linux中socket结构是struct sock,这个结构定义了socket所需要的所有状态信息,包括socket所使用的协议以及可以在socket上执行的操作。
Socket API函数
- socket 初始化创建socket对象,通常是第一个调用的socket函数。 成功时,返回非负数的socket描述符;失败是返回-1。socket描述符是一个指向内部数据结构的指针,它指向描述符表入口。调用socket()函数时,socket执行体将建立一个socket,为一个socket数据结构分配存储空间。
- connect 建立连接 connect()通常由TCP类型客户端调用,用来与服务器建立一个TCP连接,实际是发起3次握手过程,连接成功返回0,连接失败返回1。
- bind() 绑定本机端口 将创建的socket绑定到指定的IP地址和端口上,通常是第二个调用的socket函数。返回值:0代表成功,-1代表出错。当socket函数返回一个描述符时,只是存在于其协议族的空间中,并没有分配一个具体的协议地址(这里指IPv4/IPv6和端口号的组合),bind函数可以将一组固定的地址绑定到sockfd上。通常服务器在启动的时候都会绑定一个众所周知的协议地址,用于提供服务,客户就可以通过它来接连服务器;而客户端可以指定IP或端口也可以都不指定,未分配则系统自动分配。
- listen 监听端口 listen()函数仅被TCP类型的服务器程序调用,实现监听服务。当socket()创建socket时,被假设为主动式套接字,也就是说它是一个将调用connect()发起连接请求的客户端套接字;函数listen()将套接口转换为被动式套接字,指示内核接受向此套接字的连接请求,调用此系统调用后tcp 状态机由close转换到listen。
- accept 接受连接 accept()函数仅被TCP类型的服务器程序调用,从已完成连接队列返回下一个建立成功的连接,如果已完成连接队列为空,线程进入阻塞态睡眠状态。成功时返回套接字描述符,错误时返回-1。如果accpet()执行成功,返回由内核自动生成的一个全新socket描述符,用它引用与客户端的TCP连接。通常我们把accept()第一个参数成为监听套接字,把accept()功能返回值成为已连接套接字。
- recv, recvfrom 数据接收 TCP类型的数据接收。recv()从接收缓冲区拷贝数据。成功时,返回拷贝的字节数,失败返回-1。阻塞模式下,recv/recvfrom将会阻塞到缓冲区里至少有一个字节(TCP)/至少有一个完整的UDP数据报才返回,没有数据时处于休眠状态。若非阻塞,则立即返回,有数据则返回拷贝的数据大小,否则返回错误-1。
- send, sendto 数据发送 TCP类型的数据发送。每个TCP套接口都有一个发送缓冲区,它的大小可以用SO_SNDBUF这个选项来改变。调用send函数的过程,实际是内核将用户数据拷贝至TCP套接口的发送缓冲区的过程:若len大于发送缓冲区大小,则返回-1;否则,查看缓冲区剩余空间是否容纳得下要发送的len长度,若不够,则拷贝一部分,并返回拷贝长度;若缓冲区满,则等待发送,有剩余空间后拷贝至缓冲区;若在拷贝过程出现错误,则返回-1。
- close, shutdown 关闭套接字
Socket通信流程图大致如下:

对于网站,通信模型是服务器与客户端之间的通信。两端都建立了一个Socket对象,然后通过Socket对象对数据进行传输。通常服务器处于一个无限循环,等待客户端的连接。
3.3 设备驱动程序
Linux把所有的硬件设备分为三大类:字符设备、块设备、网络设备。所有的网络消息都需要通过网络设备发出,这里Linux通过调用net_device的接口实现,但是每个设备要根据自身的情况针对性性地实现这些接口。
字符设备:字符设备是能够像字节流(类似文件)一样被访问的设备,有字符设备驱动程序来实现这种特性。字符设备驱动程序通常至少要实现open、close、read、write系统调用。
块设备:块设备也是通过设备节点来访问。块设备上能够容纳文件系统。在大多数unix系统中,进行I/O操作时块设备每次只能传输一个或多个完整的块,而每块包含512字节(或更2的更高次幂字节的数据)。linux可以让应用程序向字符设备一样读写块设备,允许一次传递任意多字节的数据。
网络设备:网络设备不同于字符设备和块设备,它是面向报文的而不是面向流的,它不支持随机访问,也没有请求缓冲区。由于不是面向流的设备,因此将网络接口映射到文件系统中的节点比较困难。内核和网络设备驱动程序间的通讯,完全不同于内核和字符以及块驱动程序之间的通讯,内核调用一套和数据包传输相关的函数而不是read,write。网络接口没有像字符设备和块设备一样的设备号,只有一个唯一的名字,如eth0、eth1等,而这个名字也不需要与设备文件节点对应。
二.send和recv过程中TCP/IP协议栈相关的运行任务实体及相互协作的时序分析
网络栈初始化
Linux系统进行前期的准备工作后,系统跳转到init/main.c下的start_kernel函数执行。

start_kernel函数经过平台初始化,内存初始化,陷阱初始化,中断初始化,进程调度初始化,缓冲区初始化等,然后执行socket_init(),最后开中断执行init()。
内核的网络战初始化函数socket_init()函数的实现在net/socket.c中
oid sock_init(void)//网络栈初始化 { int i; printk("Swansea University Computer Society NET3.019\n"); /* * Initialize all address (protocol) families. */ for (i = 0; i < NPROTO; ++i) pops[i] = NULL; /* * Initialize the protocols module. */ proto_init(); #ifdef CONFIG_NET /* * Initialize the DEV module. */ dev_init(); /* * And the bottom half handler */ bh_base[NET_BH].routine= net_bh; enable_bh(NET_BH); #endif }
在其中将地址组协议NPROTO进行初始化,并用BSD协议来定义操作函数的接口(实现在pop[i]),具体定义在net.h中:
struct proto_ops { int family; int (*create) (struct socket *sock, int protocol); int (*dup) (struct socket *newsock, struct socket *oldsock); int (*release) (struct socket *sock, struct socket *peer); int (*bind) (struct socket *sock, struct sockaddr *umyaddr, int sockaddr_len); int (*connect) (struct socket *sock, struct sockaddr *uservaddr, int sockaddr_len, int flags); int (*socketpair) (struct socket *sock1, struct socket *sock2); int (*accept) (struct socket *sock, struct socket *newsock, int flags); int (*getname) (struct socket *sock, struct sockaddr *uaddr, int *usockaddr_len, int peer); int (*read) (struct socket *sock, char *ubuf, int size, int nonblock); int (*write) (struct socket *sock, char *ubuf, int size, int nonblock); int (*select) (struct socket *sock, int sel_type, select_table *wait); int (*ioctl) (struct socket *sock, unsigned int cmd, unsigned long arg); int (*listen) (struct socket *sock, int len); int (*send) (struct socket *sock, void *buff, int len, int nonblock, unsigned flags); int (*recv) (struct socket *sock, void *buff, int len, int nonblock, unsigned flags); int (*sendto) (struct socket *sock, void *buff, int len, int nonblock, unsigned flags, struct sockaddr *, int addr_len); int (*recvfrom) (struct socket *sock, void *buff, int len, int nonblock, unsigned flags, struct sockaddr *, int *addr_len); int (*shutdown) (struct socket *sock, int flags); int (*setsockopt) (struct socket *sock, int level, int optname, char *optval, int optlen); int (*getsockopt) (struct socket *sock, int level, int optname, char *optval, int *optlen); int (*fcntl) (struct socket *sock, unsigned int cmd, unsigned long arg); };
在其中定义了一系列操作函数,通过参数传递socket完成操作。
然后完成对proto_init()协议初始化:
void proto_init(void) { extern struct net_proto protocols[]; /* Network protocols 全局变量,定义在protocols.c中 */ struct net_proto *pro; /* Kick all configured protocols. */ pro = protocols; while (pro->name != NULL) { (*pro->init_func)(pro); pro++; } /* We're all done... */ }
在上图循环中,执行了关键的inet_proto_init()函数,进行INET域协议的初始化。定义参数inet_proto_ops,然后
printk("IP Protocols: "); for(p = inet_protocol_base; p != NULL;) //将inet_protocol_base指向的一个inet_protocol结构体加入数组inet_protos中 { struct inet_protocol *tmp = (struct inet_protocol *) p->next; inet_add_protocol(p); printk("%s%s",p->name,tmp?", ":"\n"); p = tmp; } /* * Set the ARP module up */ arp_init();//对地址解析层进行初始化 /* * Set the IP module up */ ip_init();//对IP层进行初始化
完成对地址解析层和IP层协议的初始化,之后需要对应的网络设备进行初始化。
- 进行硬件上的准备工作,检查网络设备是否存在,如果存在,则检测设备所使用的硬件资源。
- 进行软件接口上的准备工作,分配 net_device 结构体并对其数据结构和函数指针成员赋值。
- 获得设备的私有信息指针并初始化各成员的值。如果私有信息中包括自旋锁或信号量等并发或同步机制,则需对其进行初始化。
对 net_device 结构体成员及私有数据的赋值都可能需要与硬件初始化工作协同进行,即硬件检测出了相应的资源,需要根据检测结果填充 net_device 结构体成员和私有数据。
asmlinkage void __init start_kernel(void) { ... parse_early_param();//间接调用parse_args parse_args(...); //处理内核引导程序(boot loader)在引导期间传给内核的参数, ... init_IRQ(); //初始化硬件中断 tick_init(); init_timers(); //定时器用于支持后续初始化工作的运行。 hrtimers_init(); softirq_init(); //初始化软件中断 ... rest_init(); //这里会通过kernel_thread函数调用内核线程init(kernel_init). } static init __ref kernel_init(void *unused) { kernel_init_freeable(); //Linux-3.12 在这里调用do_basic_setup free_initmem(); //用于释放已经不再需要的内存。 ..... run_init_process(execute_command) ... } static void __init do_basic_setup(void) { cpuset_init_smp(); usermodehelper_init(); shmem_init(); driver_init(); init_irq_proc(); do_ctors(); usermodehelper_enable(); do_initcalls(); //初始化内核子系统和内建的设备驱动 random_int_secret_init(); }
/* * 网络设备驱动的初始化函数模板 */ void xxx_init(struct net_device *dev) { /* 设备的私有信息结构体 */ struct xxx_priv *priv; /* 检查设备是否存在和设备所使用的硬件资源 */ xxx_hw_init(); /* 初始化以太网设备的公用成员 */ ether_setup(); /* 设置设备的成员函数指针 */ ndev->netdev_ops = &xxx_netdev_ops; ndev->ethtool_ops = &xxx_ethtool_ops; dev->watchdog_timeo = timeout; /* 取得私有信息,并初始化它 */ priv = netdev_priv(dev); ``` /* 初始化设备私有数据区 */ }
同时基于网络交互 客户端——服务器 的结构,Linux5.4.34的客户端服务器代码如下:
客户端
1 #include <stdio.h> /* perror */ 2 #include <stdlib.h> /* exit */ 3 #include <string.h> /* memset */ 4 #include <sys/wait.h> /* waitpid */ 5 #include"socketwrapper.h" 6 7 #define true 1 8 #define false 0 9 10 #define PORT 3490 /* Server的端口 */ 11 #define MAXDATASIZE 100 /* 一次可以读的最大字节数 */ 12 13 int main(int argc, char *argv[]) 14 { 15 int sockfd, numbytes; 16 char buf[MAXDATASIZE]; 17 struct hostent *he; /* 主机信息 */ 18 struct sockaddr_in their_addr; /* 对方地址信息 */ 19 if (argc != 2) 20 { 21 fprintf(stderr, "usage: client hostname\n"); 22 exit(1); 23 } 24 25 /* get the host info */ 26 if ((he = Gethostbyname(argv[1])) == NULL) 27 { 28 /* 注意:获取DNS信息时,显示出错需要用herror而不是perror */ 29 /* herror 在新的版本中会出现警告,已经建议不要使用了 */ 30 perror("gethostbyname"); 31 exit(1); 32 } 33 34 if ((sockfd = Socket(PF_INET, SOCK_STREAM, 0)) == -1) 35 { 36 perror("socket"); 37 exit(1); 38 } 39 40 their_addr.sin_family = AF_INET; 41 their_addr.sin_port = Htons(PORT); /* short, NBO */ 42 their_addr.sin_addr = *((struct in_addr *)he->h_addr_list[0]); 43 memset(&(their_addr.sin_zero), 0, 8); /* 其余部分设成0 */ 44 45 if (Connect(sockfd, (struct sockaddr *)&their_addr, 46 sizeof(struct sockaddr)) == -1) 47 { 48 perror("connect"); 49 exit(1); 50 } 51 52 if( Send(sockfd, "Hi, server\n", 9, 0) < 0) 53 { 54 printf("send msg error: %s(errno: %d)\n", strerror(errno), errno); 55 exit(0); 56 } 57 58 if ((numbytes = Recv(sockfd, buf, MAXDATASIZE, 0)) == -1) 59 { 60 perror("recv"); 61 exit(1); 62 } 63 64 buf[numbytes] = '\0'; 65 printf("Received: %s", buf); 66 Close(sockfd); 67 68 return true; 69 }
服务器代码
1 #include <stdio.h> /* perror */ 2 #include <stdlib.h> /* exit */ 3 #include <string.h> /* memset */ 4 #include <sys/wait.h> /* waitpid */ 5 #include"socketwrapper.h" 6 7 #define true 1 8 #define false 0 9 10 #define MYPORT 3490 /* 监听的端口 */ 11 #define BACKLOG 10 /* listen的请求接收队列长度 */ 12 #define MAXDATASIZE 100 /*最大接受客户端字节数*/ 13 14 int main() 15 { 16 int sockfd, new_fd; /* 监听端口,数据端口 */ 17 struct sockaddr_in sa; /* 自身的地址信息 */ 18 struct sockaddr_in their_addr; /* 连接对方的地址信息 */ 19 unsigned int sin_size; 20 21 char buf[MAXDATASIZE]; 22 int n; 23 24 if ((sockfd = Socket(PF_INET, SOCK_STREAM, 0)) == -1) 25 { 26 perror("socket"); 27 exit(1); 28 } 29 30 sa.sin_family = AF_INET; 31 sa.sin_port = Htons(MYPORT); /* 网络字节顺序 */ 32 sa.sin_addr.s_addr = INADDR_ANY; /* 自动填本机IP */ 33 memset(&(sa.sin_zero), 0, 8); /* 其余部分置0 */ 34 35 if (bind(sockfd, (struct sockaddr *)&sa, sizeof(sa)) == -1) 36 { 37 perror("bind"); 38 exit(1); 39 } 40 41 if (Listen(sockfd, BACKLOG) == -1) 42 { 43 perror("listen"); 44 exit(1); 45 } 46 47 /* 主循环 */ 48 while (1) 49 { 50 sin_size = sizeof(struct sockaddr_in); 51 new_fd = Accept(sockfd, 52 (struct sockaddr *)&their_addr, &sin_size); 53 if (new_fd == -1) 54 { 55 perror("accept"); 56 continue; 57 } 58 59 printf("Got connection from %s\n", 60 inet_ntoa(their_addr.sin_addr)); 61 62 n=Recv(new_fd,buf,MAXDATASIZE) 63 if (fork() == 0) 64 { 65 /* 子进程 */ 66 if (Send(new_fd, "Hello, world!\n", 14, 0) == -1) 67 perror("send"); 68 Close(new_fd); 69 exit(0); 70 } 71 buf[n] = '\0'; 72 printf("recv msg from client: %s\n", buf); 73 74 Close(new_fd); 75 76 /*清除所有子进程 */ 77 while (waitpid(-1, NULL, WNOHANG) > 0) 78 ; 79 } 80 Close(sockfd); 81 return true; 82 }
交互流程如下图所示(在上面介绍socket通信中可以看到此图)
Linux系统send和recv过程介绍
1.Send和recv函数解析
1 #include <sys/socket.h> 2 ssize_t recv(int sockfd, void *buff, size_t nbytes, int flags); 3 ssize_t send(int sockfd, const void *buff, size_t nbytes, int flags);
recv 和send的前3个参数等同于read和write。
flag的参数值为0或以下:

对于Send()而言,函数参数表示的含义为:
sockfd:指定发送端套接字描述符。
buff: 存放要发送数据的缓冲区
nbytes: 实际要改善的数据的字节数
flags: 一般设置为0
在传输过程中,
1) send先比较发送数据的长度nbytes和套接字sockfd的发送缓冲区的长度,如果nbytes > 套接字sockfd的发送缓冲区的长度, 该函数返回SOCKET_ERROR;
2) 如果nbtyes <= 套接字sockfd的发送缓冲区的长度,那么send先检查协议是否正在发送sockfd的发送缓冲区中的数据,如果是就等待协议把数据发送完,如果协议还没有开始发送sockfd的发送缓冲区中的数据或者sockfd的发送缓冲区中没有数据,那么send就比较sockfd的发送缓冲区的剩余空间和nbytes
3) 如果 nbytes > 套接字sockfd的发送缓冲区剩余空间的长度,send就一起等待协议把套接字sockfd的发送缓冲区中的数据发送完
4) 如果 nbytes < 套接字sockfd的发送缓冲区剩余空间大小,send就仅仅把buf中的数据copy到剩余空间里(注意并不是send把套接字sockfd的发送缓冲区中的数据传到连接的另一端的,而是协议传送的,send仅仅是把buf中的数据copy到套接字sockfd的发送缓冲区的剩余空间里)。
5) 如果send函数copy成功,就返回实际copy的字节数,如果send在copy数据时出现错误,那么send就返回SOCKET_ERROR; 如果在等待协议传送数据时网络断开,send函数也返回SOCKET_ERROR。
6) send函数把buff中的数据成功copy到sockfd的改善缓冲区的剩余空间后它就返回了,但是此时这些数据并不一定马上被传到连接的另一端。如果协议在后续的传送过程中出现网络错误的话,那么下一个socket函数就会返回SOCKET_ERROR。(每一个除send的socket函数在执行的最开始总要先等待套接字的发送缓冲区中的数据被协议传递完毕才能继续,如果在等待时出现网络错误那么该socket函数就返回SOCKET_ERROR)
7) 在unix系统下,如果send在等待协议传送数据时网络断开,调用send的进程会接收到一个SIGPIPE信号,进程对该信号的处理是进程终止。
对于Recv()函数,函数参数表示的含义为:
sockfd: 接收端套接字描述符
buff: 用来存放recv函数接收到的数据的缓冲区
nbytes: 指明buff的长度
flags: 一般置为0
1) recv先等待s的发送缓冲区的数据被协议传送完毕,如果协议在传送sock的发送缓冲区中的数据时出现网络错误,那么recv函数返回SOCKET_ERROR
2) 如果套接字sockfd的发送缓冲区中没有数据或者数据被协议成功发送完毕后,recv先检查套接字sockfd的接收缓冲区,如果sockfd的接收缓冲区中没有数据或者协议正在接收数据,那么recv就一起等待,直到把数据接收完毕。当协议把数据接收完毕,recv函数就把s的接收缓冲区中的数据copy到buff中(注意协议接收到的数据可能大于buff的长度,所以在这种情况下要调用几次recv函数才能把sockfd的接收缓冲区中的数据copy完。recv函数仅仅是copy数据,真正的接收数据是协议来完成的)
3) recv函数返回其实际copy的字节数,如果recv在copy时出错,那么它返回SOCKET_ERROR。如果recv函数在等待协议接收数据时网络中断了,那么它返回0。
4) 在unix系统下,如果recv函数在等待协议接收数据时网络断开了,那么调用 recv的进程会接收到一个SIGPIPE信号,进程对该信号的默认处理是进程终止。
2.不同网络层次的运行时序分析
2.1 应用层
应用层的各种网络应用程序基本上都是通过 Linux Socket 编程接口来和内核空间的网络协议栈通信的。Linux Socket 是Linux 操作系统的重要组成部分之一,是网络应用程序的基础。从层次上来说,它位于应用层,位于传输层协议之上,屏蔽了不同网络协议之间的差异,同时也是网络编程的入口,它提供了大量的系统调用,构成了网络程序的主体。
在内核中与socket对应的系统调用是sys_soceket,所谓的创建套接口,就是在sockfs这个文件系统中创建一个节点,从Linux/Unix的角度来看,该节点是一个文件,不过这个文件具有非普通文件的属性,于是起了--个独特的名字socket。由于sockfs文件系统是系统初始化时就保存在全局指针sock_mnt中的,所以申请一个inode的过程便以sock_mnt为参数。
socket函数本身,经过glibc库对其封装,它将通过int 0x80产生-一个软件中断,由内核导向执行sys_socket,基本上参数会原封不动地传入内核,它们分别是(1) int family,(2) int type, (3) int protocol。
当我们建立好socket之后(网际交互有了对应的精准端口),并完成了三次握手确认,以使用send()函数或sendmsg()函数进行数据的发送工作,代码如下:
SYSCALL_DEFINE2(socketcall, int, call, unsigned long __user *, args) { //...预处理... switch (call) { //...其他调用... case SYS_SEND: err = __sys_sendto(a0, (void __user *)a1, a[2], a[3], NULL, 0); break; case SYS_SENDTO: err = __sys_sendto(a0, (void __user *)a1, a[2], a[3], (struct sockaddr __user *)a[4], a[5]); break; case SYS_RECV: err = __sys_recvfrom(a0, (void __user *)a1, a[2], a[3], NULL, NULL); break; case SYS_RECVFROM: err = __sys_recvfrom(a0, (void __user *)a1, a[2], a[3], (struct sockaddr __user *)a[4], (int __user *)a[5]); break; case SYS_SENDMSG: err = __sys_sendmsg(a0, (struct user_msghdr __user *)a1, a[2], true); break; case SYS_RECVMSG: err = __sys_recvmsg(a0, (struct user_msghdr __user *)a1, a[2], true); break; } return err; }
数据接收(recv)过程中,代码如下
int __sys_recvfrom(int fd, void __user *ubuf, size_t size, unsigned int flags, struct sockaddr __user *addr, int __user *addr_len) { struct msghdr msg; //...预处理... //在接受数据之前,检查用户空间的地址是否可读 err = import_single_range(READ, ubuf, size, &iov, &msg.msg_iter); //...... //通过文件描述符fd来找到需要的结构体 sock = sockfd_lookup_light(fd, &err, &fput_needed); //...... //接收数据 err = sock_recvmsg(sock, &msg, flags); if (err >= 0 && addr != NULL) { //将内核空间的数据传递至用户空间 err2 = move_addr_to_user(&address, msg.msg_namelen, addr, addr_len); if (err2 < 0) err = err2; } //更新文件的引用计数 fput_light(sock->file, fput_needed); out: return err; }
sock->ops->recvmsg即inet_recvmsg,最后在inet_recvmsg中调用的是tcp_recvmsg
主要调用流程如下

数据发送(send)过程中,主要函数代码如下,与接收的源码非常相似
int __sys_sendto(int fd, void __user *buff, size_t len, unsigned int flags, struct sockaddr __user *addr, int addr_len) { struct msghdr msg; //...预处理... //在接受数据之前,检查用户空间的地址是否可读 err = import_single_range(WRITE, buff, len, &iov, &msg.msg_iter); //...... //通过文件描述符fd来找到需要的结构体 sock = sockfd_lookup_light(fd, &err, &fput_needed); //...... if (addr) { //将用户空间的数据传递至内核空间 err = move_addr_to_kernel(addr, addr_len, &address); //...... } //...... //发送数据 err = sock_sendmsg(sock, &msg); out_put: //更新文件的引用计数 fput_light(sock->file, fput_needed); out: return err; }
过程中需要调用如下函数:

代码断点调试结果如下:

2.2 传输层
在传输层中,Linux系统调用Tcp_sendmsg函数检查链接状态,并同时获取链接的MSS。创建该数据包的 sk_buffer 数据结构实例 skb,从 userspace buffer 中拷贝 packet 的数据到 skb 的 buffer。构造数据包头部,接而计算 TCP 校验和(ack)和顺序号(seq)。最后调用ip_queue_xmit函数将数据包传输到网际层进行处理。
这里主要对Tcp_sendmsg函数的调用逻辑进行补充分析,该函数只要检查已经建立的 TCP connection 的状态,然后获取有效的 MSS,Tcp_sendmsg函数的内部调用顺序如下: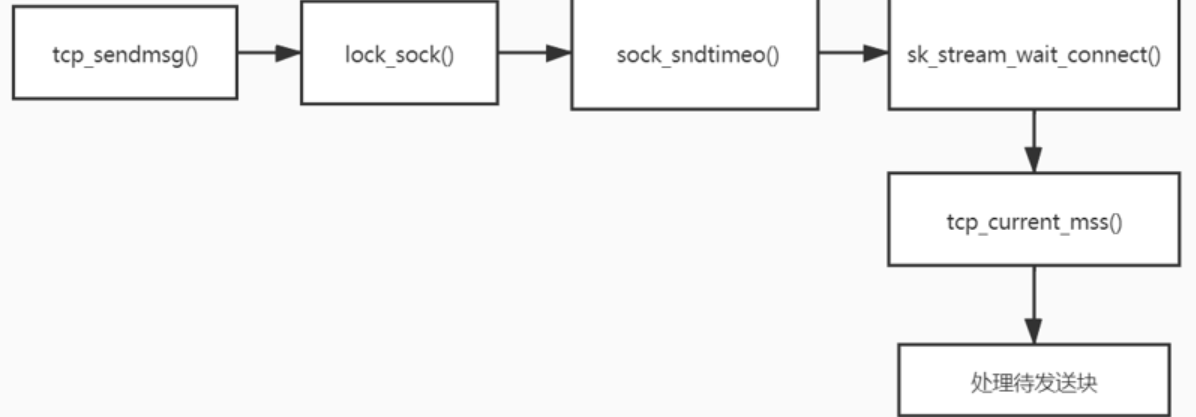
1.Tcp_sendmsg分析:sendmsg系统调用在TCP层的实现
2.lock_sock():获取套接口的锁
3.sock_sndtimeo()根据标志计算阻塞超时时间
4.sk_stream_wait_connect():对于不能发送信息状态须等待连接正确建立,超时
5.tcp_current_mss():获得有效的MSS
tcp_sendmsg函数会调用tcp_write_xmit函数,tcp_write_xmit函数会调用tcp_transmit_skb,在这里实现了TCP层面向连接的逻辑。
整体的流程图如下所示

其中非常关键的tcp_sendmsg函数如下所示:
int tcp_sendmsg(struct sock *sk, struct msghdr *msg, size_t size) { struct tcp_sock *tp = tcp_sk(sk); struct sk_buff *skb; int flags, err, copied = 0; int mss_now = 0, size_goal, copied_syn = 0; long timeo; ...... /* Ok commence sending. */ copied = 0; restart: mss_now = tcp_send_mss(sk, &size_goal, flags); while (msg_data_left(msg)) { int copy = 0; int max = size_goal; skb = tcp_write_queue_tail(sk); if (tcp_send_head(sk)) { if (skb->ip_summed == CHECKSUM_NONE) max = mss_now; copy = max - skb->len; } if (copy <= 0 || !tcp_skb_can_collapse_to(skb)) { bool first_skb; new_segment: /* Allocate new segment. If the interface is SG, * allocate skb fitting to single page. */ if (!sk_stream_memory_free(sk)) goto wait_for_sndbuf; ...... first_skb = skb_queue_empty(&sk->sk_write_queue); skb = sk_stream_alloc_skb(sk, select_size(sk, sg, first_skb), sk->sk_allocation, first_skb); ...... skb_entail(sk, skb); copy = size_goal; max = size_goal; ...... } /* Try to append data to the end of skb. */ if (copy > msg_data_left(msg)) copy = msg_data_left(msg); /* Where to copy to? */ if (skb_availroom(skb) > 0) { /* We have some space in skb head. Superb! */ copy = min_t(int, copy, skb_availroom(skb)); err = skb_add_data_nocache(sk, skb, &msg->msg_iter, copy); ...... } else { bool merge = true; int i = skb_shinfo(skb)->nr_frags; struct page_frag *pfrag = sk_page_frag(sk); ...... copy = min_t(int, copy, pfrag->size - pfrag->offset); ...... err = skb_copy_to_page_nocache(sk, &msg->msg_iter, skb, pfrag->page, pfrag->offset, copy); ...... pfrag->offset += copy; } ...... tp->write_seq += copy; TCP_SKB_CB(skb)->end_seq += copy; tcp_skb_pcount_set(skb, 0); copied += copy; if (!msg_data_left(msg)) { if (unlikely(flags & MSG_EOR)) TCP_SKB_CB(skb)->eor = 1; goto out; } if (skb->len < max || (flags & MSG_OOB) || unlikely(tp->repair)) continue; if (forced_push(tp)) { tcp_mark_push(tp, skb); __tcp_push_pending_frames(sk, mss_now, TCP_NAGLE_PUSH); } else if (skb == tcp_send_head(sk)) tcp_push_one(sk, mss_now); continue; ...... } ...... }
tcp_sendmsg的第一件事情,把数据拷贝到struct sk_buff。先声明一个变量copied初始化为0,这表示拷贝了多少数据,紧接着是一个循环,while (msg_data_left(msg))即如果用户的数据没有发送完毕,就一直循环。循环里声明了一个copy变量,表示这次拷贝的数值,在循环的最后有copied += copy,将每次拷贝的数量都加起来,这里只需要看一次循环做了哪些事情:
第一步,tcp_write_queue_tail从TCP写入队列sk_write_queue中拿出最后一个struct sk_buff,在这个写入队列中排满了要发送的 struct sk_buff,为什么要拿最后一个呢?这里面只有最后一个,可能会因为上次用户给的数据太少,而没有填满。
第二步,tcp_send_mss会计算MSS即Max Segment Size。这个意思是说,在网络上传输的网络包的大小是有限制的,而这个限制在最底层开始就有。MTU(Maximum Transmission Unit,最大传输单元)是二层的一个定义,以以太网为例MTU为1500个Byte,前面有6个Byte的目标MAC地址,6个Byt的源 MAC地址,2个Byte的类型,后面有4个Byte的CRC校验,共1518个Byte。在IP层,一个IP数据报在以太网中传输,如果它的长度大于该MTU值,就要进行分片传输。
在 TCP 层有个MSS,等于MTU 减去IP头,再减去TCP头,也就是在不分片的情况下,TCP里面放的最大内容。在这里max是struct sk_buff的最大数据长度,skb->len是当前已经占用的skb的数据长度,相减得到当前skb的剩余数据空间。
第三步,如果copy小于0,说明最后一个struct sk_buff已经没地方存放了,需要调用sk_stream_alloc_skb重新分配struct sk_buff,然后调用skb_entail,将新分配的sk_buf放到队列尾部。struct sk_buff 是存储网络包的重要数据结构,在应用层数据包叫data,在TCP层称为segment,在IP层叫packet,在数据链路层称为frame。
sk_buff结构体:
这个结构体是套接字的缓冲区,详细记录了一个数据包的组成,时间、网络设备、各层的首部及首部长度和数据的首尾指针。
下面是他的定义,
struct sk_buff { /* These two members must be first. */ struct sk_buff *next; struct sk_buff *prev; ktime_t tstamp; struct sock *sk; struct net_device *dev; /* * This is the control buffer. It is free to use for every * layer. Please put your private variables there. If you * want to keep them across layers you have to do a skb_clone() * first. This is owned by whoever has the skb queued ATM. */ char cb[48] __aligned(8); unsigned long _skb_refdst; #ifdef CONFIG_XFRM struct sec_path *sp; #endif unsigned int len, data_len; __u16 mac_len, hdr_len; union { __wsum csum; struct { __u16 csum_start; __u16 csum_offset; }; }; __u32 priority; kmemcheck_bitfield_begin(flags1); __u8 local_df:1, cloned:1, ip_summed:2, nohdr:1, nfctinfo:3; __u8 pkt_type:3, fclone:2, ipvs_property:1, peeked:1, nf_trace:1; kmemcheck_bitfield_end(flags1); __be16 protocol; void (*destructor)(struct sk_buff *skb); #if defined(CONFIG_NF_CONNTRACK) || defined(CONFIG_NF_CONNTRACK_MODULE) struct nf_conntrack *nfct; #endif #ifdef NET_SKBUFF_NF_DEFRAG_NEEDED struct sk_buff *nfct_reasm; #endif #ifdef CONFIG_BRIDGE_NETFILTER struct nf_bridge_info *nf_bridge; #endif int skb_iif; #ifdef CONFIG_NET_SCHED __u16 tc_index; /* traffic control index */ #ifdef CONFIG_NET_CLS_ACT __u16 tc_verd; /* traffic control verdict */ #endif #endif __u32 rxhash; __u16 queue_mapping; kmemcheck_bitfield_begin(flags2); #ifdef CONFIG_IPV6_NDISC_NODETYPE __u8 ndisc_nodetype:2; #endif __u8 ooo_okay:1; __u8 l4_rxhash:1; kmemcheck_bitfield_end(flags2); /* 0/13 bit hole */ #ifdef CONFIG_NET_DMA dma_cookie_t dma_cookie; #endif #ifdef CONFIG_NETWORK_SECMARK __u32 secmark; #endif union { __u32 mark; __u32 dropcount; }; __u16 vlan_tci; sk_buff_data_t transport_header; sk_buff_data_t network_header; sk_buff_data_t mac_header; /* These elements must be at the end, see alloc_skb() for details. */ sk_buff_data_t tail; sk_buff_data_t end; unsigned char *head, *data; unsigned int truesize; atomic_t users; };
这里主要说明下后面几个后面的四个属性的含义head、data、tail、end
head是缓冲区的头指针,data是数据的起始地址,tail是数据的结束地址,end是缓冲区的结束地址。char cb[48] __aligned(8);中的48个字节是控制字段,配合各层协议工作,为每层存储必要的控制信息。

alloc_skb()函数 该函数的作用是在上层协议要发送数据包的时候或网络设备准备接收数据包的时候会调用alloc_skb()函数分配sk_buff结构体,需要释放时调用kfree_skb()函数。
static inline struct sk_buff *alloc_skb(unsigned int size, gfp_t priority) { return __alloc_skb(size, priority, 0, NUMA_NO_NODE); }
这里使用内联函数,非内联函数调用会进堆栈的切换,造成额外的开销,而内联函数可以解决这一点,可以提高执行效率,只是增加了程序的空间开销。
kfree_skb()函数 该函数就是释放不被使用的sk_buff结构
void kfree_skb(struct sk_buff *skb) { if (unlikely(!skb)) return; if (likely(atomic_read(&skb->users) == 1)) smp_rmb(); else if (likely(!atomic_dec_and_test(&skb->users))) return; trace_kfree_skb(skb, __builtin_return_address(0)); __kfree_skb(skb); }
在结构体sk_buff中,最后几项, head指向分配的内存块起始地址,data这个指针指向的位置是可变的,它有可能随着报文所处的层次而变动。每一次skb_push 和skb_pull函数执行,都会改变指针指向。
当接收报文时,从网卡驱动开始,通过协议栈层层往上传送数据报,通过增加skb->data的值,来逐步剥离协议首部。而要发送报文时,各协议会创建sk_buff{},在经过各下层协议时,通过减少skb->data的值来增加协议首部。tail指向数据的结尾,end指向分配的内存块的结束地址。要分配这样一个结构,sk_stream_alloc_skb会最终调用到__alloc_skb,在这个函数里面除了分配一个sk_buff结构之外,还要分配sk_buff指向的数据区域。
好,当tcp_sendmsg解析完了之后,操作系统检测到缓冲区中有数据,即会调用tcp_push_one,发送一个数据包,然后tcp_write_xmit开始发送网络包
static bool tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle, int push_one, gfp_t gfp) { struct tcp_sock *tp = tcp_sk(sk); struct sk_buff *skb; unsigned int tso_segs, sent_pkts; int cwnd_quota; ...... max_segs = tcp_tso_segs(sk, mss_now); while ((skb = tcp_send_head(sk))) { unsigned int limit; ...... tso_segs = tcp_init_tso_segs(skb, mss_now); ...... cwnd_quota = tcp_cwnd_test(tp, skb); ...... if (unlikely(!tcp_snd_wnd_test(tp, skb, mss_now))) { is_rwnd_limited = true; break; } ...... limit = mss_now; if (tso_segs > 1 && !tcp_urg_mode(tp)) limit = tcp_mss_split_point(sk, skb, mss_now, min_t(unsigned int, cwnd_quota, max_segs), nonagle); if (skb->len > limit && unlikely(tso_fragment(sk, skb, limit, mss_now, gfp))) break; ...... if (unlikely(tcp_transmit_skb(sk, skb, 1, gfp))) break; repair: /* Advance the send_head. This one is sent out. * This call will increment packets_out. */ tcp_event_new_data_sent(sk, skb); tcp_minshall_update(tp, mss_now, skb); sent_pkts += tcp_skb_pcount(skb); if (push_one) break; } ......
其又将调用发送函数tcp_transmit_skb,来判断数据大小是否超出窗口,决定是否要进行分块处理,其中所有的SKB都经过该函数进行发送。最后进入到ip_queue_xmit到网络层。因为tcp会进行重传控制,所以有tcp_write_timer函数,进行定时。
tcp_transmit_skb是tcp发送数据位于传输层的最后一步,这里首先对TCP数据段的头部进行了处理,然后调用了网络层提供的发送接口icsk->icsk_af_ops->queue_xmit(sk, skb, &inet->cork.fl);实现了数据的发送,自此,数据离开了传输层,传输层的任务也就结束了。
网际层向传输层方向:
其中tcp层的数据接收主要在tcp_v4_rcv中进行处理
int tcp_v4_rcv(struct sk_buff *skb) { struct net *net = dev_net(skb->dev); struct sk_buff *skb_to_free; int sdif = inet_sdif(skb); int dif = inet_iif(skb); const struct iphdr *iph; const struct tcphdr *th; bool refcounted; struct sock *sk; int ret; ............. if (skb_checksum_init(skb, IPPROTO_TCP, inet_compute_pseudo)) goto csum_error; ............. lookup: sk = __inet_lookup_skb(&tcp_hashinfo, skb, __tcp_hdrlen(th), th->source, th->dest, &refcounted); ............. process: if (sk->sk_state == TCP_TIME_WAIT) ............. if (sk->sk_state == TCP_NEW_SYN_RECV) ............. if (unlikely(iph->ttl < inet_sk(sk)->min_ttl)) ............. put_and_return: if (refcounted) sock_put(sk); ............. no_tcp_socket: ............. discard_it: ............. discard_and_relse: ............. do_time_wait: ............. switch (tcp_timewait_state_process(inet_twsk(sk), skb, th)) { case TCP_TW_SYN: { struct sock *sk2 = inet_lookup_listener(); ............. case TCP_TW_ACK: ............. case TCP_TW_RST: tcp_v4_send_reset(sk, skb); ............. case TCP_TW_SUCCESS:; }
tcp_v4_rcv判断状态为listen时会直接调用tcp_v4_do_rcv;如果是其他状态,将TCP包投递到目的套接字进行接收处理。如果套接字未被上锁则调用tcp_v4_do_rcv。当套接字正被用户锁定,TCP包将暂时排入该套接字的后备队列(sk_add_backlog)。
Tcp_v4_do_ecv检查状态如果是established,就调用tcp_rcv_established函数,tcp_rcv_established用于处理已连接状态下的输入,处理过程根据首部预测字段分为快速路径和慢速路径。在快路中,若无数据,则处理输入ack,释放该skb,检查是否有数据发送,有则发送。
其余函数功能如下
1.__inet_lookup_v4_lookup():在ehash或者bhask中查找传输控制块,若无找到则进行退出, 并通过tcp_v4_send_reset(skb)发送RST段给对方,如果报文被损坏则无法发送rst,直接丢包
2.xfrm4_policy_check():进行安全检查
3.sk_filter():看是否符合过滤器规则
4.tcp_v4_do_rcv():传输层处理TCP段的主入口
5.tcp_rcv_established():当连接已经建立时,用快速路径处理报文
6. tcp_v4_hnd_req():为侦听套口,处理半连接状态的ACK消息
7. tcp_child_process():不是侦听套接字,说明已经建立了半连接。调用此函数初始化子传输控制块,如果失败则向客户端发送rst段,即tcp_v4_send_reset()
代码验证结果如下

2.3 网际层

Ip_queue_xmit:将TCP端打包成IP数据报
Dst_output:封装了输出数据报目的路由缓存项中的输出端口(分为两类:单播,组播)
Ip_output: 处理单播数据报,设置数据报的输出网络设备以及网络层协议类型参数。
Ip_finish_output:观察数据报长度是否大于MTU,若大于,则调用ip_fragment分片,否则调用ip_finish_output2输出;
Ip_ finish_output2: 对skb的头部空间进行检查,看是否能够容纳下二层头部,若空间不足,则需要重新申请skb;然后,获取邻居子系统,并通过邻居子系统输出。
输入数据包在网际层的处理过程中,发挥关键枢纽作用的是ip_rcv函数,它的作用是对数据包做各种合法性检查:协议头长度、协议版本、数据包长度、校验和等。 然后调用网络过滤子系统的回调函数对数据包进行安全过滤, 如果数据包通过过滤系统,则调用ip_rcv_finish函数对数据包进行实际处理接口层。
它是netfilter钩子函数,如果允许包传递则返回1。如果返回其他值说明这个包被hook给消耗掉了。
其中hook为NF_INET_PRE_ROUTING(定义在include/uapi/linux/netfilter.h)
okfn指向ip_rcv_finish()函数。ip_rcv_finish()也定义在:net/ipv4/ip_input.c
static int ip_rcv_finish(struct sk_buff *skb) { const struct iphdr *iph = ip_hdr(skb); struct rtable *rt; /* * 获取数据包传递的路由信息,如果 skb->dst 数据域为空,就通过路由子系统获取, * 如果 ip_route_input 返回错误信息,表明数据包目标地址不正确,扔掉数据包 */ if (skb_dst(skb) == NULL) { int err = ip_route_input_noref(skb, iph->daddr, iph->saddr, iph->tos, skb->dev); ............. } /* * 如果配置了流量控制功能,则更新QoS的统计信息 */ ............. if (unlikely(skb_dst(skb)->tclassid)) { ............. } ............. /* 在此函数中确定下一步对数据包的处理函数是哪一个,实际是调用函数指针 skb->dst->input * 函数指针的值可能为 ip_local_deliver 或 ip_forward 函数 */ return dst_input(skb); drop: kfree_skb(skb); return NET_RX_DROP; }
ip_queue_xmit是ip层提供给tcp层发送回调,大多数tcp发送都会使用这个回调,tcp层使用tcp_transmit_skb封装了tcp头之后调用该函数。Ip_queue_xmit实际上是调用__ip_queue_xmit。
1 int __ip_queue_xmit(struct sock *sk, struct sk_buff *skb, struct flowi *fl, 2 __u8 tos) 3 { 4 struct inet_sock *inet = inet_sk(sk); 5 struct net *net = sock_net(sk); 6 struct ip_options_rcu *inet_opt; 7 struct flowi4 *fl4; 8 struct rtable *rt; 9 struct iphdr *iph; 10 int res; 11 12 /* Skip all of this if the packet is already routed, 13 * f.e. by something like SCTP. 14 */ 15 rcu_read_lock(); 16 inet_opt = rcu_dereference(inet->inet_opt); 17 fl4 = &fl->u.ip4; 18 rt = skb_rtable(skb); 19 if (rt) 20 goto packet_routed;
接下来,Skb_rtable(skb)获取skb中的路由缓存,然后判断是否有缓存,如果有缓存就直接进行packet_routed。
数据包从IP层上传至传输层IP层处理完成后,如果是本地数据则调用ip_local_deliver函数,此函数的作用是如果IP数据包被分片了,在这里重组数据包。 然后再次通过NF_HOOK宏进入过滤子系统,最后调用ip_local_deliver_finish函数将数据包传递给传输层相关协议。
Linux内核支持的传输层协议都实现了各自的协议处理函数(如UDP、TCP协议),然后将协议处理函数放到struct net_protocol结构体中。 最后将struct net_protocol结构体注册到inet_protos[MAX_INET_PROTOS]全局数组中, 网络层协议头中的protocol数据域描述的协议编码,就是该协议在inet_protos全局数组中的索引号。
ip_rcv_finish 函数最终会调用ip_route_input函数,进入路由处理环节。它首先会调用 ip_route_input 来更新路由,然后查找 route,决定该 package 将会被发到本机还是会被转发还是丢弃:
如果是发到本机的话,调用ip_local_deliver 函数,可能会做 de-fragment(合并多个 IP packet),然后调用ip_local_deliver函数。该函数根据 package 的下一个处理层的 protocal number,调用下一层接口,包括 tcp_v4_rcv (TCP), udp_rcv (UDP),icmp_rcv (ICMP),igmp_rcv(IGMP)。对于 TCP 来说,函数 tcp_v4_rcv 函数会被调用,从而处理流程进入 TCP 栈。
ip分组也可能转发到另一台计算机。如果需要转发 (forward),则进入转发流程这就需要调用ip_forward函数。ip_forward使用NF_HOOK挂钩函数,挂钩编号为NF_INET_FORWARD,回调函数为ip_forward_finish。该函数会 (1)处理 Netfilter Hook (2)执行 IP fragmentation (3)调用 dev_queue_xmit,进入链路层处理流程。
int ip_forward(struct sk_buff *skb) { //...其他处理... return NF_HOOK(NFPROTO_IPV4, NF_INET_FORWARD, net, NULL, skb, skb->dev, rt->dst.dev, ip_forward_finish); } static int ip_forward_finish(struct net *net, struct sock *sk, struct sk_buff *skb) { struct ip_options *opt = &(IPCB(skb)->opt); __IP_INC_STATS(net, IPSTATS_MIB_OUTFORWDATAGRAMS); __IP_ADD_STATS(net, IPSTATS_MIB_OUTOCTETS, skb->len); #ifdef CONFIG_NET_SWITCHDEV if (skb->offload_l3_fwd_mark) { consume_skb(skb); return 0; } #endif if (unlikely(opt->optlen)) ip_forward_options(skb); skb->tstamp = 0; return dst_output(net, sk, skb); }
验证如下所示

2.4 数据链路层和物理层
Linux 提供了一个 Network device的抽象层,将设备抽象为单纯的文件,将网络设备抽象为流文件。具体的物理网络设备在设备驱动中需要实现其实现在 linux/net/core/dev.c中的的虚函数。Network Device抽象层调用具体网络设备的函数来实现数据的发送与接收。
上层调用dev_queue_xmit进入链路层的处理流程,实际上调用的是__dev_queue_xmit
1 static int __dev_queue_xmit(struct sk_buff *skb, struct net_device *sb_dev) 2 { 3 struct net_device *dev = skb->dev; 4 struct netdev_queue *txq; 5 struct Qdisc *q; 6 int rc = -ENOMEM; 7 bool again = false; 8 9 skb_reset_mac_header(skb); 10 11 if (unlikely(skb_shinfo(skb)->tx_flags & SKBTX_SCHED_TSTAMP)) 12 __skb_tstamp_tx(skb, NULL, skb->sk, SCM_TSTAMP_SCHED); 13 14 /* Disable soft irqs for various locks below. Also 15 * stops preemption for RCU. 16 */ 17 rcu_read_lock_bh(); 18 19 skb_update_prio(skb); 20 21 qdisc_pkt_len_init(skb); 22 #ifdef CONFIG_NET_CLS_ACT 23 skb->tc_at_ingress = 0; 24 # ifdef CONFIG_NET_EGRESS 25 if (static_branch_unlikely(&egress_needed_key)) { 26 skb = sch_handle_egress(skb, &rc, dev); 27 if (!skb) 28 goto out; 29 } 30 # endif 31 #endif 32 /* If device/qdisc don't need skb->dst, release it right now while 33 * its hot in this cpu cache. 34 */ 35 if (dev->priv_flags & IFF_XMIT_DST_RELEASE) 36 skb_dst_drop(skb); 37 else 38 skb_dst_force(skb); 39 40 txq = netdev_core_pick_tx(dev, skb, sb_dev); 41 q = rcu_dereference_bh(txq->qdisc); 42 43 trace_net_dev_queue(skb); 44 if (q->enqueue) { 45 rc = __dev_xmit_skb(skb, q, dev, txq); 46 goto out; 47 } 48 49 /* The device has no queue. Common case for software devices: 50 * loopback, all the sorts of tunnels... 51 52 * Really, it is unlikely that netif_tx_lock protection is necessary 53 * here. (f.e. loopback and IP tunnels are clean ignoring statistics 54 * counters.) 55 * However, it is possible, that they rely on protection 56 * made by us here. 57 58 * Check this and shot the lock. It is not prone from deadlocks. 59 *Either shot noqueue qdisc, it is even simpler 8) 60 */ 61 if (dev->flags & IFF_UP) { 62 int cpu = smp_processor_id(); /* ok because BHs are off */ 63 64 if (txq->xmit_lock_owner != cpu) { 65 if (dev_xmit_recursion()) 66 goto recursion_alert; 67 68 skb = validate_xmit_skb(skb, dev, &again); 69 if (!skb) 70 goto out; 71 72 HARD_TX_LOCK(dev, txq, cpu); 73 74 if (!netif_xmit_stopped(txq)) { 75 dev_xmit_recursion_inc(); 76 skb = dev_hard_start_xmit(skb, dev, txq, &rc); 77 dev_xmit_recursion_dec(); 78 if (dev_xmit_complete(rc)) { 79 HARD_TX_UNLOCK(dev, txq); 80 goto out; 81 } 82 } 83 HARD_TX_UNLOCK(dev, txq); 84 net_crit_ratelimited("Virtual device %s asks to queue packet!\n", 85 dev->name); 86 }
在发送报文中,先检查是否有enqueue的规则,如果有即调用dev_xmit_skb进入拥塞控制的flow,如果没有且txq处于On的状态,那么就调用dev_hard_start_xmit直接发送到driver。
调用dev_hard_start_xmit
1 struct sk_buff *dev_hard_start_xmit(struct sk_buff *first, struct net_device *dev, 2 struct netdev_queue *txq, int *ret) 3 { 4 struct sk_buff *skb = first; 5 int rc = NETDEV_TX_OK; 6 7 while (skb) { 8 struct sk_buff *next = skb->next; 9 10 skb_mark_not_on_list(skb); 11 rc = xmit_one(skb, dev, txq, next != NULL); 12 if (unlikely(!dev_xmit_complete(rc))) { 13 skb->next = next; 14 goto out; 15 } 16 17 skb = next; 18 if (netif_tx_queue_stopped(txq) && skb) { 19 rc = NETDEV_TX_BUSY; 20 break; 21 } 22 } 23 24 out: 25 *ret = rc; 26 return skb; 27 }
调用xmit_one,然后调用netdev_start_xmit,实际上是调用__netdev_start_xmit()。
1 __netdev_start_xmit(const struct net_device_ops *ops, 2 struct sk_buff *skb, struct net_device *dev, 3 bool more) 4 { 5 __this_cpu_write(softnet_data.xmit.more, more); 6 return ops->ndo_start_xmit(skb, dev); 7 }
调用各网络设备实现的ndo_start_xmit回调函数指针,其为数据结构struct net_device,从而把数据发送给网卡,物理层在收到发送请求之后,通过 DMA 将该主存中的数据拷贝至内部RAM(buffer)之中。在数据拷贝中,同时加入符合以太网协议的相关header,IFG、前导符和CRC。对于以太网网络,物理层发送采用CSMA/CD,即在发送过程中侦听链路冲突。
一旦网卡完成报文发送,将产生中断通知CPU,然后驱动层中的中断处理程序就可以删除保存的skb了。
接收数据时会触发软终端,软中断会触发内核网络模块中的软中断处理函数,内核中的ksoftirqd进程专门负责软中断的处理,当它收到软中断后,就会调用相应软中断所对应的处理函数,对于网卡驱动模块抛出的软中断,ksoftirqd会调用网络模块的net_rx_action函数。
net_rx_action调用网卡驱动里的naqi_poll函数来一个一个的处理数据包。在poll函数中,驱动会一个接一个的读取网卡写到内存中的数据包,内存中数据包的格式只有驱动知道。驱动程序将内存中的数据包转换成内核网络模块能识别的skb格式,然后调用napi_gro_receive函数。
1 gro_result_t napi_gro_receive(struct napi_struct *napi, struct sk_buff *skb) 2 { 3 gro_result_t ret; 4 5 skb_mark_napi_id(skb, napi); 6 trace_napi_gro_receive_entry(skb); 7 8 skb_gro_reset_offset(skb); 9 10 ret = napi_skb_finish(dev_gro_receive(napi, skb), skb); 11 trace_napi_gro_receive_exit(ret); 12 13 return ret; 14 } 15 EXPORT_SYMBOL(napi_gro_receive);
napi_gro_receive会直接调用netif_receive_skb_core。netif_receive_skb_core调用 __netif_receive_skb_one_core,将数据包交给上层ip_rcv进行处理。
1 static int __netif_receive_skb_one_core(struct sk_buff *skb, bool pfmemalloc) 2 { 3 struct net_device *orig_dev = skb->dev; 4 struct packet_type *pt_prev = NULL; 5 int ret; 6 7 ret = __netif_receive_skb_core(skb, pfmemalloc, &pt_prev); 8 if (pt_prev) 9 ret = INDIRECT_CALL_INET(pt_prev->func, ipv6_rcv, ip_rcv, skb, 10 skb->dev, pt_prev, orig_dev); 11 return ret; 12 }
待内存中的所有数据包被处理完成后(即poll函数执行完成),启用网卡的硬中断,即完成了本次数据包的交付。
此部分函数调用大致如下

调试结果如下

三.通过TCP传输的协议栈运行时序图


 浙公网安备 33010602011771号
浙公网安备 33010602011771号