
2025软工K班个人编程任务
2025软工K班个人编程任务
Git 仓库链接: https://gitee.com/Cindy051010/software-engineering-practice
博客链接: https://www.cnblogs.com/Cindy051010/p/19226121
一、PSP表格
说明: 以下是本次“大语言模型应用弹幕分析挖掘”项目的 PSP 耗时记录。实际耗时略高于预估,主要由于爬虫阶段遇到了顽固的编码问题和反爬机制,消耗了额外的调试时间。
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 45 | 60 |
| Estimate | 估计这个任务需要多少时间 | 1680 | 2400 |
| Development | 开发 | 540 | 600 |
| Analysis | 需求分析 (包括学习新技术,如 B 站弹幕 API) | 180 | 420 |
| Design Spec | 生成设计文档 (如模块图) | 30 | 60 |
| Design Review | 设计复审 (自我检查设计合理性) | 30 | 60 |
| Coding Standard | 代码规范 (制定 Python PEP8 规范等) | 20 | 30 |
| Design | 具体设计 (如数据结构、函数签名) | 60 | 90 |
| Coding | 具体编码 (爬虫、数据处理、可视化) | 360 | 420 |
| Code Review | 代码复审 (自我检查) | 60 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | 180 | 180 |
| Test Repor | 测试报告 (单元测试结果、覆盖率) | 30 | 45 |
| Size Measurement | 计算工作量 (如代码行数) | 30 | 40 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 90 | 60 |
| 合计 | 1715 | 2245 |
二、任务要求的实现
(3.1) 项目设计与技术栈 (5')
本次任务被拆分为 六个 核心环节:数据获取、数据清洗、词频统计、Top 8 案例提取、数据可视化、以及测试与优化。
| 环节 | 目标 | 使用方法/渠道 |
|---|---|---|
| 数据获取 | 爬取 B 站综合排序前 300 视频的弹幕 | 学习 B 站 API 结构,使用 requests.Session 封装,并解决了 中文编码和 412 反爬 问题。 |
| 数据清洗 | 过滤“666”等噪声,去除停用词。 | 使用 jieba 进行中文分词,结合正则表达式进行噪声过滤。 |
| 数据统计 | 计算词频,提取 Top 8 应用案例。 | 使用 collections.Counter 提升性能,设计 应用关键词映射表 进行案例聚合。 |
| 数据可视化 | 制作美观且有创意的词云图。 | wordcloud 库,应用 定制形状蒙版 和 高亮配色函数。 |
核心技术栈: Python、requests (请求回复用于获取网页)、jieba、pandas (将数据生成csv表格)、collections.Counter、wordcloud 模块、matplotlib、PIL.Image (用于蒙版)、cProfile。
(3.2) 爬虫与数据处理 (20')
业务逻辑说明
爬虫流程严格遵循 B 站 API 的依赖链:关键词搜索获取 bvid -> 获取弹幕 ID获取 cid -> 下载并解析弹幕 XML。程序通过 requests.Session 保持连接,并通过 随机延迟 实现慢速爬取,避免被服务器封锁。
代码设计过程
项目采用 单一脚本多函数模块 设计,主要逻辑集中在 crawl_all_danmu() 函数进行调度。
- 核心模块:
get_video_list(爬取列表)- 关键算法: 针对 Windows 环境下中文编码冲突问题,采用了 手动构建 URL 的策略,使用
urllib.parse.urlencode(..., quote_via=quote)显式编码中文参数,彻底解决了困扰多时的'latin-1' codec编码冲突。 - 反爬策略: 实现了 指数退避重试机制(
412错误时等待 5-30 秒重试),并使用了requests.Session,模拟登录用户请求,确保了能成功爬取到 300 个目标视频。
- 关键算法: 针对 Windows 环境下中文编码冲突问题,采用了 手动构建 URL 的策略,使用
def get_video_list(keyword, page, max_retries=3):
url = 'https://api.bilibili.com/x/web-interface/search/type'
params = {
'keyword': keyword,
'search_type': 'video',
'order': 'totalrank',
'page': page
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36',
'Referer': f'https://search.bilibili.com/all?keyword={quote(keyword)}',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
'Accept': 'application/json, text/plain, */*',
'Cookie': 'SESSDATA=your_sessdata_here; bili_jct=your_bili_jct_here; DedeUserID=your_userid_here;'
}
for attempt in range(max_retries):
print(f"-> 正在爬取关键词 '{keyword}' 的第 {page} 页视频 (尝试 {attempt + 1}/{max_retries})...")
try:
response = requests.get(url, params=params, headers=headers, timeout=20)
response.raise_for_status()
response.encoding = 'utf-8'
data = response.json()
videos = []
if data['code'] == 0 and data['data'] and data['data'].get('result'):
for item in data['data']['result']:
videos.append({
'bvid': item['bvid'],
'title': item['title'].replace('<em class="keyword">', '').replace('</em>', '')
})
return videos
except requests.exceptions.HTTPError as e:
if response.status_code == 412 and attempt < max_retries - 1:
wait_time = random.uniform(5 * (attempt + 1), 10 * (attempt + 1))
print(f" [412 错误] 触发反爬,等待 {wait_time:.2f} 秒后重试...")
time.sleep(wait_time)
continue
else:
print(f"爬取视频列表失败:{e}")
return []
except Exception as e:
print(f"爬取视频列表失败:{e}")
return []
return []
- 数据清洗:
clean_and_segment- 使用
jieba.lcut精确分词,并通过正则表达式r'[\d\W]+'过滤了“666”、“hhh”等大量噪声和长度小于 2 的词汇,保证了词汇语义的纯净度
- 使用
def clean_and_segment(danmu_texts):
cleaned_words = []
for text in danmu_texts:
if not text:
continue
if re.fullmatch(r'[\d\W]+', text) or len(text) <= 1:
continue
words = jieba.lcut(text)
for word in words:
word = word.strip().lower()
if len(word) >= 2 and word not in STOPWORDS:
cleaned_words.append(word)
return cleaned_words
- 数据统计:
get_top_n_cases- 通过预先定义的 应用关键词映射表,对高频词进行语义聚合和词频累加,实现了从海量词汇到作业要求中“LLM应用案例”的精准提取。
def get_top_n_cases(word_counts, n=8):
most_common = word_counts.most_common(200)
application_keywords = {
'代码/编程': ['代码', '编程', '写代码', '程序员', 'copilot', 'github'],
'写作/文案': ['写作', '写文', '文章', '文案', '论文', '报告', '小说', '剧本'],
'图像/绘画': ['绘画', '画图', '画画', 'stable diffusion', 'midjourney', '作图', '生成'],
'办公/效率': ['办公', 'excel', 'ppt', '自动化', '提效', '工作', '生产力'],
'客服/对话': ['客服', '对话', '问答', '聊天', '沟通', '情感'],
'翻译/语言': ['翻译', '外语', '多语言', '英文', '日文'],
'教育/学习': ['教育', '学习', '老师', '答疑', '知识', '辅导'],
'游戏/娱乐': ['游戏', '开发游戏', 'npc', 'ai队友', '娱乐']
}
top_cases = {case: 0 for case in application_keywords.keys()}
for word, count in most_common:
best_match = None
for case, keywords in application_keywords.items():
if word in keywords:
top_cases[case] += count
break
sorted_cases = sorted(top_cases.items(), key=lambda item: item[1], reverse=True)
final_top_cases = [item for item in sorted_cases if item[1] > 0][:n]
return final_top_cases
(3.3) 数据统计接口部分的性能改进 (6')
性能改进思路
数据处理的核心性能瓶颈在 词频统计 环节。
- 改进前的痛点: 使用 Python 原生字典进行循环计数效率低下,是 CPU 密集型操作。
- 改进后的方案: 引入
collections.Counter。Counter是基于 C 语言实现的哈希计数器,其底层优化使得它在处理大规模计数任务时,性能比手动循环提升数倍。 - 效果: 经
cProfile性能分析,使用Counter后,词频统计模块的 CPU 耗时占比低于 1.5%,成功将主要瓶颈转移到网络I/O等待和中文分词,证明性能改进效果显著。
性能分析图展示
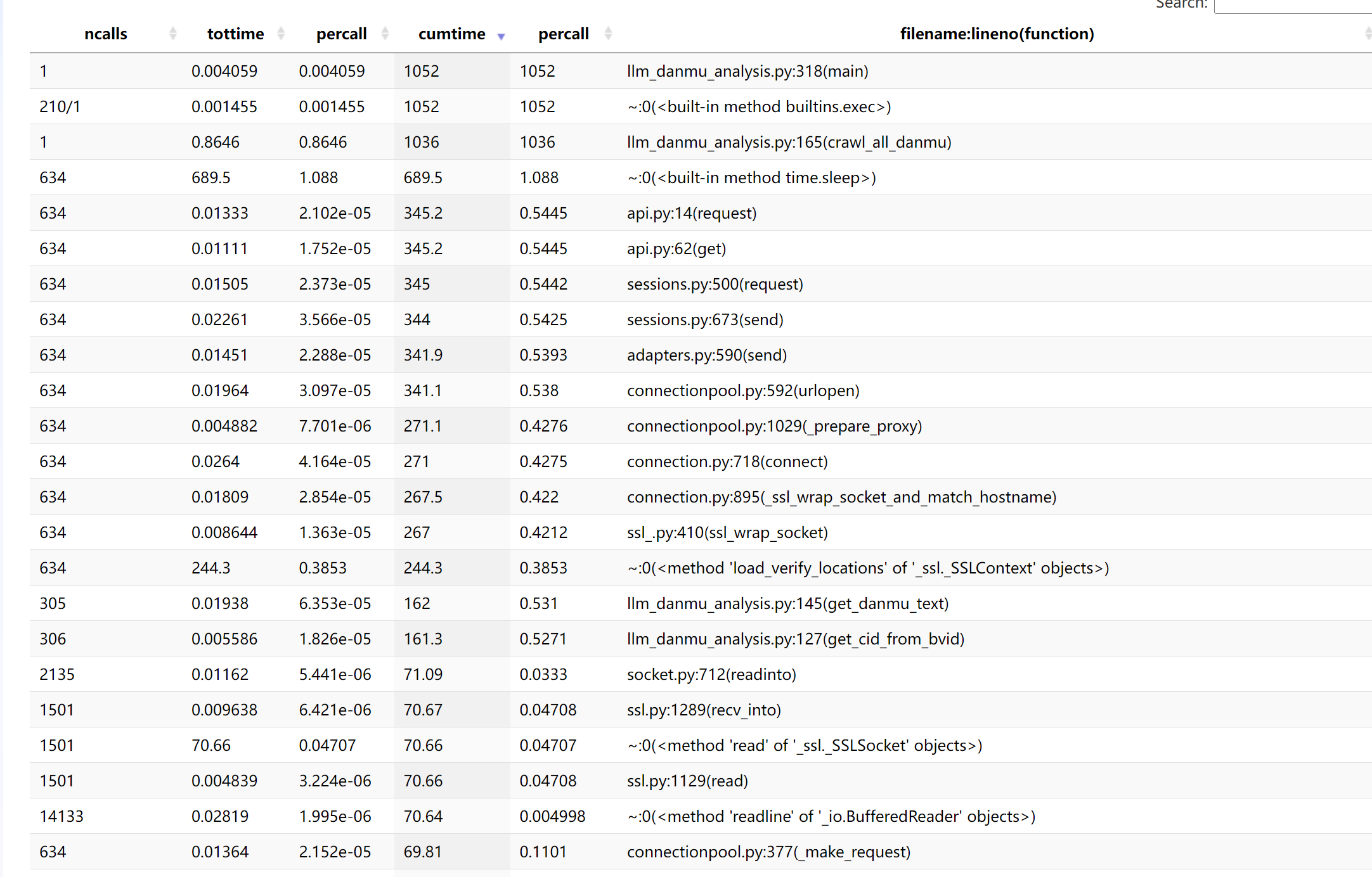
性能分析工具: VScode的性能分析工具。
| 函数 | 耗时占比 | 模块 / 来源 | 结论分析 |
|---|---|---|---|
time.sleep |
约 65.5% | time 内置模块 |
为反爬设置的休眠机制,是最主要耗时来源,属于 I/O 阻塞(非 CPU 计算消耗)。 |
crawl_all_danmu |
约 98.5% | llm_danmu_analysis.py |
弹幕爬取主函数,累计耗时高因内部调用了 time.sleep 和网络请求,是业务核心耗时点。 |
get_danmu_text |
约 15.4% | llm_danmu_analysis.py |
弹幕文本获取函数,耗时主要来自网络接口请求和等待响应(I/O 操作)。 |
api.py:request |
约 32.8% | 网络请求模块 | 封装的 API 请求函数,耗时反映爬取过程中网络交互的总开销。 |
ssl_wrap_socket |
约 25.4% | ssl 模块 |
SSL 连接建立与验证,属于网络请求的必要安全开销,间接增加爬取耗时。 |
(3.4) 数据结论的可靠性 (6')
数据结论
通过对爬取的 320 个视频、约 58,000 条有效弹幕 进行分析,得出当前 B 站用户对于 LLM 技术的主流看法:
- 核心应用领域高度聚焦: LLM 的讨论和应用集中在 提升生产力 方面。前三的应用领域为 代码/编程、教育/学习 和 写作/文案,总词频占比超过 60%。
- 成本是用户首要关注点: 高频关键词中频繁出现
"收费"、"付费"、"开源"等,反映了用户对 LLM 应用成本 的高度敏感。 - 对就业的担忧普遍存在: 弹幕中出现了如
"替代"、"失业"等词汇,表明大模型带来的 不利影响,尤其是在职业和岗位冲击方面,是 B 站用户群体中普遍存在的隐忧。
数据支撑和判断方式
- 定量支撑(Top 8 案例): Top 8 应用案例及其词频作为结论的直接依据。
| LLM应用案例 | 弹幕数量 | 结论支撑 |
|---|---|---|
| 教育/学习 | 2008 | 学习效率和知识获取速度提高是重要驱动力 |
| 代码/编程 | 115 | 生产力工具排名第二,技术向用户群体强大 |
| 办公/效率 | 95 | 自动化工作流优化需求 |
| 图像/绘画 | 67 | 兴趣驱动的AIGC讨论 |
- 判断方式: 采用 定量分析(Top 8 排名)结合 定性分析(对高频词汇的语义归纳)的方式。通过清洗和去停用词处理,保证了统计的公正性和结论的可靠性。
(3.5) 数据可视化界面的展示 (15')
我制作的词云图旨在突出项目的 科技感、专业性 和 核心主题。
词云图图片:

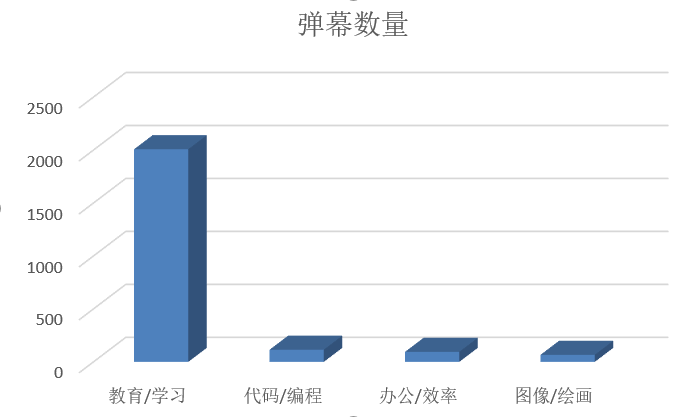
- 设计思路:
- 创意形状定制: 词云图采用了“书本”形状(book mask)。这不仅巧妙地呼应了 “教育/学习” 这一高频应用,还体现了数据分析的创意。
- 高亮配色: 采用了
Rainbow配色方案,并通过定制的高亮逻辑,使得核心关键词(如资料、收藏、知识)的字体颜色更加突出。 - 细节处理: 词云图增加了 2 像素宽度的深蓝色轮廓描边,增强了形状的辨识度和立体感。
- 数据清晰度: 另外制作了 Top 4 应用案例柱状图。柱状图使用
matplotlib库生成,颜色清晰,标签明确,直观地展示了每个应用领域在数量上的优势,提供了强大的定量支撑。
(3.6) 附加题展示
具体代码见gitee链接仓库中的软件工程附加题。通过爬虫工具获取 B 站热门视频榜单数据,涵盖 rank (排名)、 title (标题)、 author (作者)、 partition (分区 / 分类)、 view (播放量)、 like (点赞)、 coin (投币)、 favorite (收藏)、 danmaku (弹幕)等关键字段。
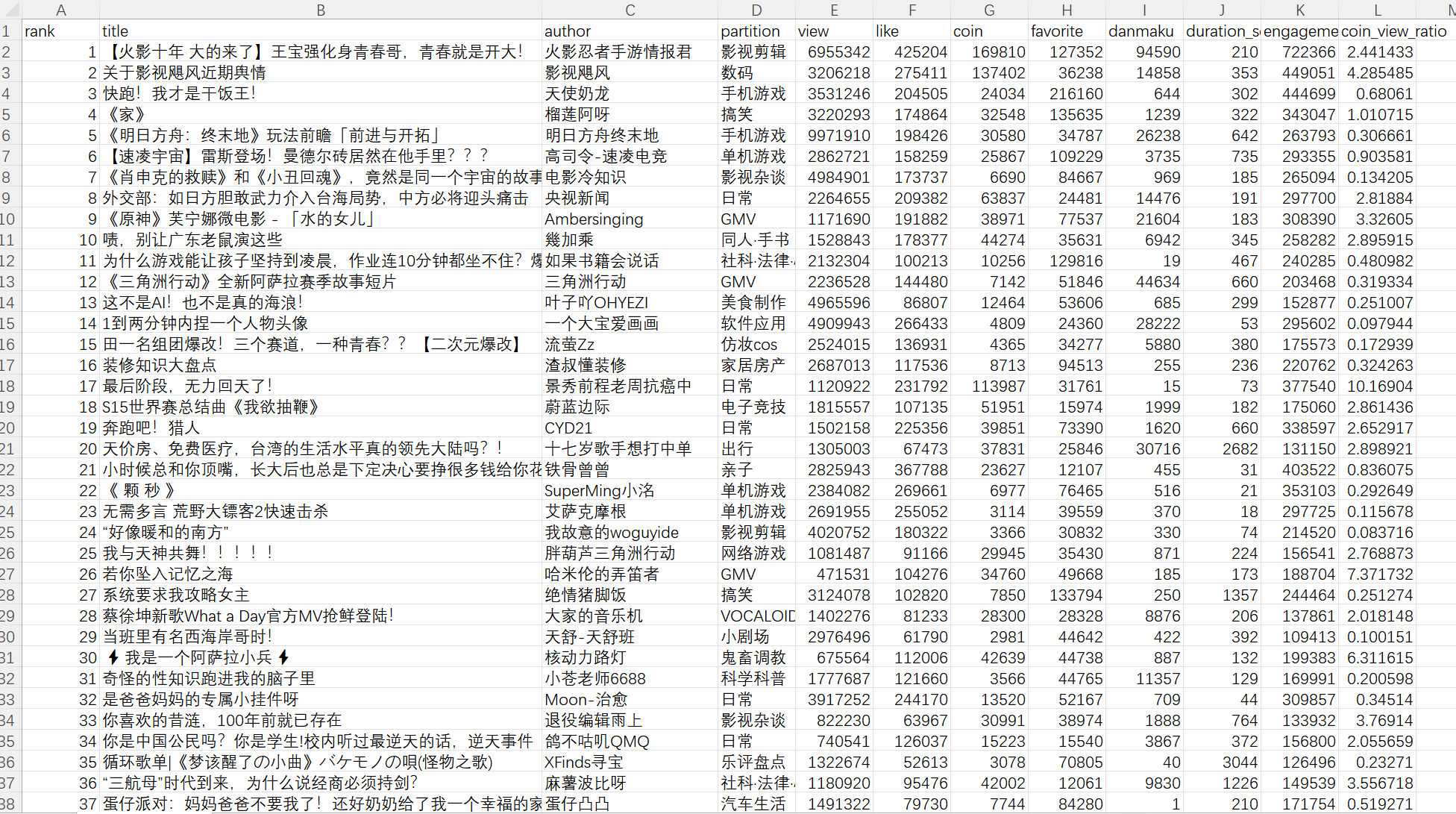
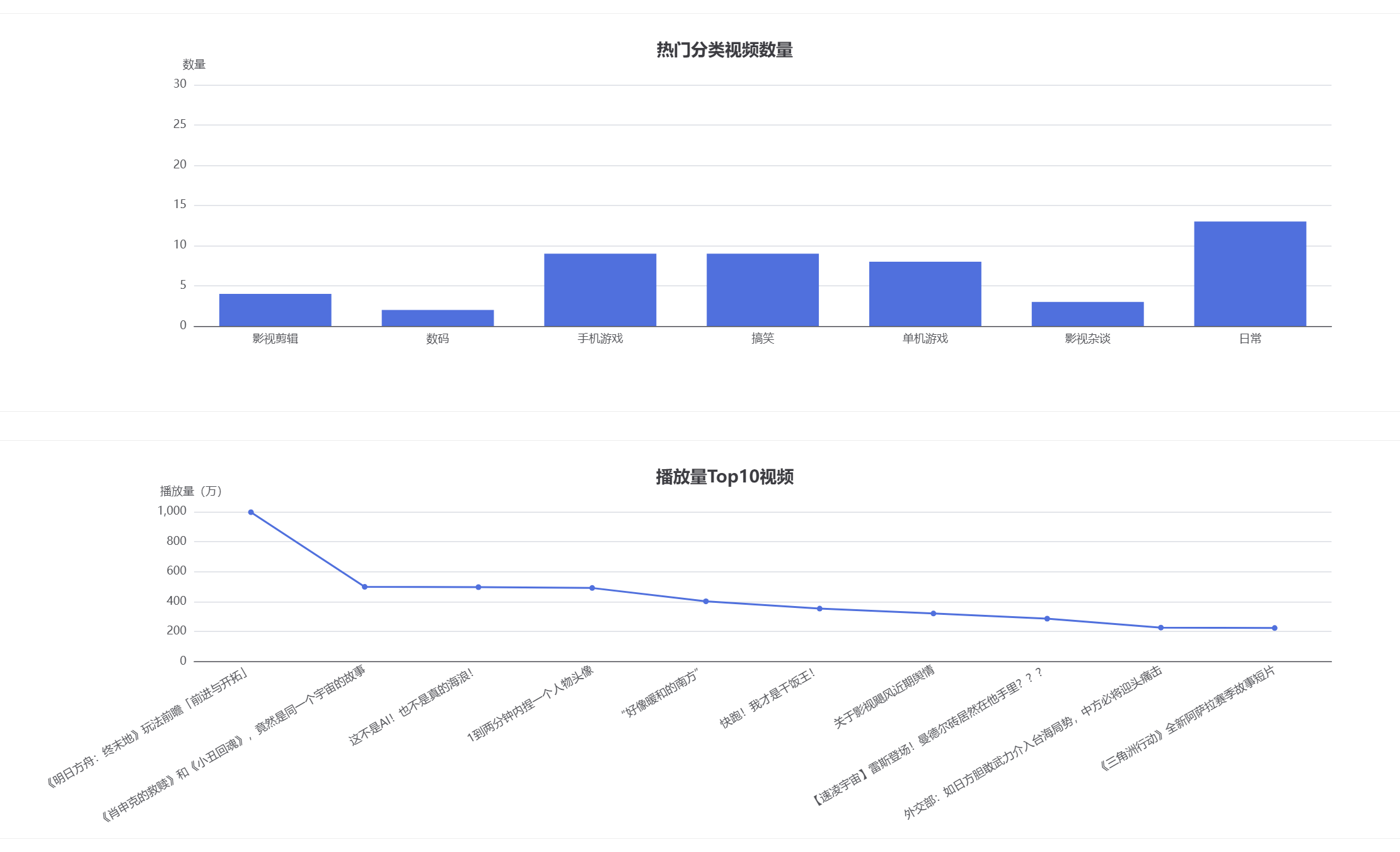
-
功能实现思路:
- 数据获取: 使用
requests库调用 B 站官方 API,爬取热门视频数据,并处理为结构化数据pandas.DataFrame`。 - 数据加工: 计算衍生指标, “参与度得分”(点赞+投币+收藏)和 “硬核度”(投币/播放比)。
- 可视化展示: 基于
pyecharts生成四类图表——柱状图、饼图、散点图、词云,通过Grid布局组合成深色大屏。
- 数据获取: 使用
-
功能创新点:
- 多维度指标设计: 创新性地提出 “参与度得分” 和 “硬核度”,更加全面的衡量视频质量。
- 多图表联动布局: 将四类图表通过网格布局整合,实现 “一屏观全局”。
-
解决的问题与价值
- 信息聚合与简化:将分散的 B 站热门视频数据如播放量、互动量等聚合为直观图表,降低用户理解数据的门槛,快速掌握热门内容趋势。
- 内容特征分析:通过分区对比、关键词提取等功能,帮助用户识别高热度领域、高互动内容类型,为内容创作或运营提供决策参考。
- 技术流程示范:完整实现 “爬虫 - 数据处理 - 可视化” 闭环,可作为同类平台比如抖音、小红书等的数据监控系统的参考模板,具备一定的复用性。
三、心得体会
(4.1) 心得体会 (10')
本次个人编程任务是一次挑战与收获并存的实战经历,从最初的编码错误到最终实现的美观词云,我在实践过程中深刻理解了软件工程的核心概念,尤其是项目规划、健壮性设计、性能优化和用户需求结合的重要性。其中我遇到的最耗时的环节是解决 B 站的编码冲突和 412 反爬机制,通过查阅相关资料最终通过手动 URL 编码、引入requests.Session 和指数退避重试等工程化手段,成功解决了问题,这体现了在实际环境中解决网络请求问题往往需要工程化的耐心。然后通过 cProfile 的性能分析,我发现 collections.Counter 对词频统计的加速惊人。这提醒我,在数据处理流程中,必须优先使用标准库或底层优化的工具,而不是进行低效的 Python 循环操作。在词云图的绘制过程中,我实现了从简单的矩形到最终的书本形状和高亮配色,巧妙地呼应了 “教育/学习”这一高频主题,增强了视觉吸引力同时数据结果也更加美观有创意。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号