第9章 基于水色图像的水质评价
一、背景与挖掘目标
从事渔业生产有经验的从业者可通过观察水色变化调控水质,以维持养殖水体生态系统中浮游植物、微生物类、浮游动物等合理的动态平衡。由于这些多是通过经验和肉眼观察进行判断,存在主观性引起的观察性偏倚,使观察结果的可比性、可重复性降低,不易推广应用。当前,数字图像处理技术为计算机监控技术在水产养殖业的应用提供更大的空间。在水质在线监测方面,数字图像处理技术是基于计算机视觉,以专家经验为基础,对池塘水色进行优劣分级,达到对池塘水色的准确快速判别。
结合某地区的多个罗非鱼池塘水样的数据,实现以下目标:
- 对水样图片进行切割,提取水样图片中的特征。
- 基于提取的特征数据,构建水质评价模型。
- 对构建的模型进行评价,评价模型对于水色的识别效率。
二、分析方法与过程
通过拍摄水样,采集得到水样图像,而图像数据的维度过大,不容易分析,需要从中提取水样图像的特征,提取反映图像本质的一些关键指标,以达到自动进行图像识别或分类的目的。显然,图像特征提取是图像识别或分类的关键步骤,图像特征提取的效果如何直接影响到图像识别和分类的好坏。
图像特征主要包括有颜色特征、纹理特征、形状特征、空间关系特征等。与几何特征相比,颜色特征更为稳健,对于物体的大小和方向均不敏感,表现出较强的鲁棒性。本案例中由于水色图像是均匀的,故主要关注颜色特征。颜色特征是一种全局特征,描述了图像或图像区域所对应的景物的表面性质。一般颜色特征是基于像素点的特征,所有属于图像或图像区域的像素都有各自的贡献。在利用图像的颜色信息进行图像处理、识别、分类的研究中,在实现方法上已有大量的研究成果,主要采用颜色处理常用的直方图法和颜色矩方法等。
颜色直方图是最基本的颜色特征表示方法,它反映的是图像中颜色的组成分布,即出现了哪些颜色以及各种颜色出现的概率。其优点在于它能简单描述一幅图像中颜色的全局分布,即不同色彩在整幅图像中所占的比例,特别适用于描述那些难以自动分割的图像和不需要考虑物体空间位置的图像。其缺点在于它无法描述图像中颜色的局部分布及每种色彩所处的空间位置,即无法描述图像中的某一具体的对象或物体。
基于颜色矩提取图像特征的数学基础在于图像中任何的颜色分布均可以用它的矩来表示。根据概率论的理论,随机变量的概率分布可以由其各阶矩唯一的表示和描述。一副图像的色彩分布也可认为是一种概率分布,那么图像可以由其各阶矩来描述。颜色矩包含各个颜色通道的一阶距、二阶矩和三阶矩,对于一副RGB颜色空间的图像,具有R、G和B三个颜色通道,则有9个分量。
颜色直方图产生的特征维数一般大于颜色矩的特征维数,为了避免过多变量影响后续的分类效果,在本案例中选择采用颜色矩来提取水样图像的特征,即建立水样图像与反映该图像特征的数据信息关系,同时由有经验的专家对水样图像根据经验进行分类,建立水样数据信息与水质类别的专家样本库,进而构建分类模型,得到水样图像与水质类别的映射关系,并经过不断调整系数优化模型,最后利用训练好的分类模型,用户就能方便地通过水样图像,自动判别出该水样的水质类别。
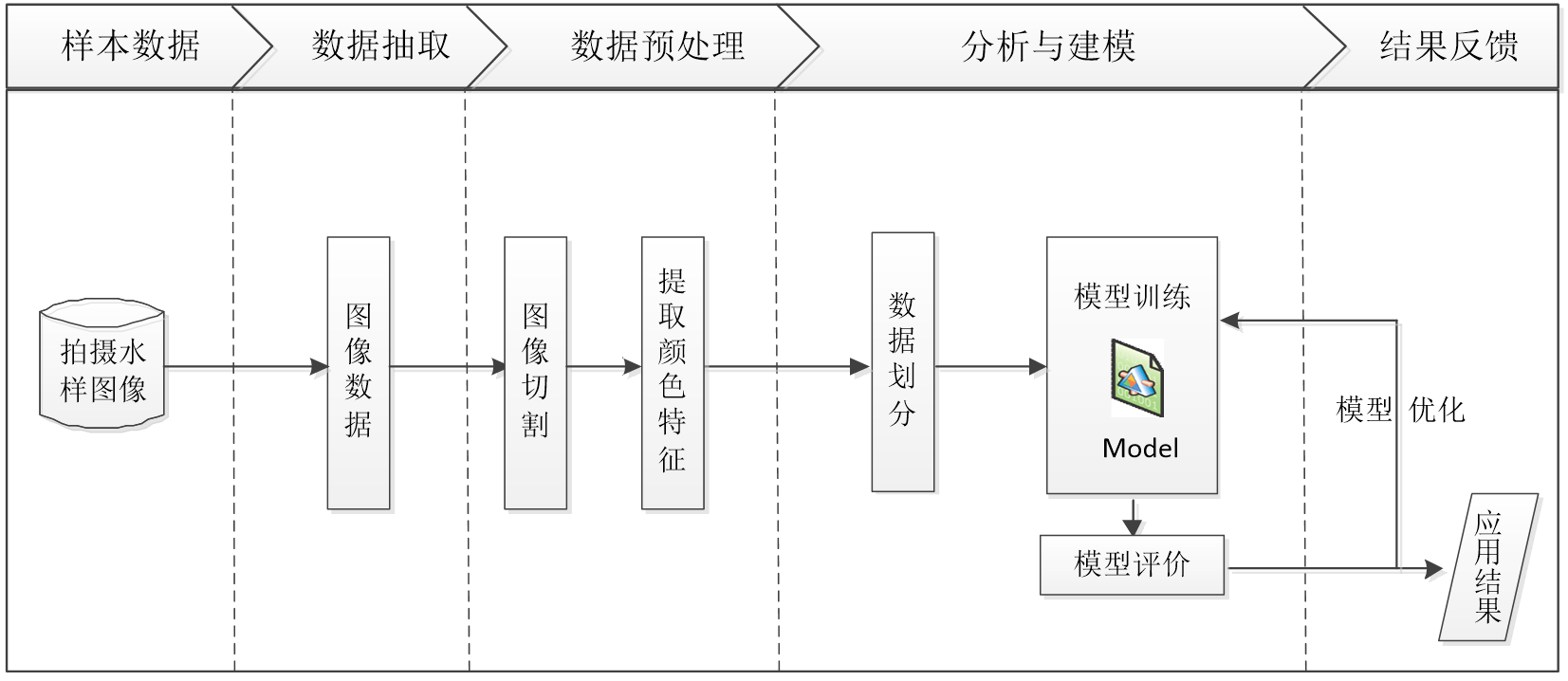
基于水色图像特征提取的水质评价步骤如下:
- 从采集到的原始水样图像中进行选择性抽取形成建模数据。
- 对步骤1形成的数据集进行数据预处理,包括图像切割和颜色矩特征提取。
- 利用步骤2形成的已完成数据预处理的建模数据,划分为训练集与测试集。
- 利用步骤3的训练集构建分类模型。
- 利用步骤4的构建好的分类模型进行水质评价。
基于水色图像特征提取的水质评价流程图如下:
各阶颜色矩的计算公式
- 一阶颜色矩采用一阶原点矩,反映了图像的整体明暗程度

- 二阶颜色矩采用的是二阶中心距的平方根,反映了图像颜色的分布范围

- 三阶颜色矩采用的是三阶中心距的立方根,反映了图像颜色分布的对称性

三、上机实验
1、实验目的
加深对决策树原理的理解及使用。
2、实验内容
实验数据是截取后的图像的颜色矩特征,包括一阶矩、二阶矩、三阶矩,同时由于图像具有R、G和B三个颜色通道,所以颜色矩特征具有9个分量。结合水质类别和颜色矩特征构成专家样本数据,以水质类别作为目标输出,构建决策树模型,并利用混淆矩阵评价模型优劣。
注意:数据80%作为训练样本,剩下的20%作为测试样本。
3、实验方法与步骤
- 把经过预处理的专家样本数据“test/data/moment.csv”使用pandas中的read_csv函数读入当前工作空间。
- 把工作空间的建模数据随机分为两部分,一部分用于训练,一部分用于测试。
- 使用scikit-learn里的DecisionTreeClassifier函数以及训练数据构建决策树模型,使用predict函数和构建的决策树模型分别对训练数据进行分类,使用scikit-Learn的子库metrics的confusion_matrix函数求出混淆矩阵,如果仅仅是想知道准确率,可以用metrics的accuracy_score函数返回。
- 使用predict函数和步骤(3)构建好的决策树模型分别对测试数据进行分类,参考步骤(3)得到模型分类正确率和混淆矩阵。
学习资料:https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html#sklearn-tree-decisiontreeclassifier(学习使用scikit-learn里的DecisionTreeClassifier函数)
References
[2]L. Breiman, J. Friedman, R. Olshen, and C. Stone, “Classification and Regression Trees”, Wadsworth, Belmont, CA, 1984.
[3]T. Hastie, R. Tibshirani and J. Friedman. “Elements of Statistical Learning”, Springer, 2009.
[4]L. Breiman, and A. Cutler, “Random Forests”, https://www.stat.berkeley.edu/~breiman/RandomForests/cc_home.htm
4、上机实验——源代码及结果
方法一
进行图像切割及特征提取:
import numpy as np import os,re from PIL import Image # 图像切割及特征提取 path = '../chap9/images/' # 图片所在路径 # 自定义获取图片名称函数 def getImgNames(path=path): ''' 获取指定路径中所有图片的名称 :param path: 指定的路径 :return: 名称列表 ''' filenames = os.listdir(path) imgNames = [] for i in filenames: if re.findall('^\d_\d+\.jpg$', i) != []: imgNames.append(i) return imgNames # 自定义获取三阶颜色矩函数 def Var(data=None): ''' 获取给定像素值矩阵的三阶颜色矩 :param data: 给定的像素值矩阵 :return: 对应的三阶颜色矩 ''' x = np.mean((data-data.mean())**3) return np.sign(x)*abs(x)**(1/3) # 批量处理图片数据 imgNames = getImgNames(path=path) # 获取所有图片名称 n = len(imgNames) # 图片张数 data = np.zeros([n, 9]) # 用来装样本自变量 labels = np.zeros([n]) # 用来放样本标签 for i in range(n): img = Image.open(path+imgNames[i]) # 读取图片 M,N = img.size # 图片像素的尺寸 img = img.crop((M/2-50,N/2-50,M/2+50,N/2+50)) # 图片切割 r,g,b = img.split() # 将图片分割成三通道 rd = np.asarray(r)/255 # 转化成数组数据 gd = np.asarray(g)/255 bd = np.asarray(b)/255 data[i,0] = rd.mean() # 一阶颜色矩 data[i,1] = gd.mean() data[i,2] = bd.mean() data[i,3] = rd.std() # 二阶颜色矩 data[i,4] = gd.std() data[i,5] = bd.std() data[i,6] = Var(rd) # 三阶颜色矩 data[i,7] = Var(gd) data[i,8] = Var(bd) labels[i] = imgNames[i][0] # 样本标签
将数据拆分成训练集和测试集,并使用scikit-learn里的DecisionTreeClassifier函数以及训练数据构建决策树模型
from sklearn.model_selection import train_test_split # 数据拆分,训练集、测试集 data_tr,data_te,label_tr,label_te = train_test_split(data,labels,test_size=0.2, random_state=10) from sklearn.tree import DecisionTreeClassifier # 模型训练 model = DecisionTreeClassifier(random_state=5).fit(data_tr, label_tr)
使用predict函数和构建的决策树模型分别对训练数据进行分类,使用scikit-Learn的子库metrics的confusion_matrix函数求出混淆矩阵
# 水质评价 from sklearn.metrics import confusion_matrix pre_te = model.predict(data_te) # 混淆矩阵 cm_te = confusion_matrix(label_te,pre_te) print(cm_te) from sklearn.metrics import accuracy_score # 准确率 print(accuracy_score(label_te,pre_te))

水质评价的混淆矩阵如上图所示,分类准确率为70.73%,说明水质评价模型对于新增的水色图像的分类效果较好,可将模型应用到水质自动评价系统,实现水质评价。(注意,由于用随机函数来打乱数据,因此重复试验所得到的结果可能有所不同。)
方法二


import numpy as np import os, re from PIL import Image def get_ImgNames(path): """ 获取图片名称 :param path: 路径 :return: 名称列表 """ # os.listdir用于返回该路径下所包含的文件或文件夹的名字列表 filenames = os.listdir(path=path) imgnames = [] for i in filenames: # 在返回的文件名字中寻找正则表达式所匹配的所有字符串,如果不存在,返回空列表 if re.findall('^\d_\d+\.jpg$', i) != []: imgnames.append(i) return imgnames def Var(data=None): """ 获取三阶颜色矩 :param p: 数据 :return: 返回三阶颜色矩 """ x = np.mean((data - data.mean()) ** 3) return np.sign(x) * np.abs(x) ** 1 / 3 def imageCutting_FeatureExtraction(path, imgnames=None): """ 图像切割与基于颜色矩进行特征提取 :param path: 路径 :param imgnames: 所有图片的名称 :return: 返回特征提取后的9个分量,以及对应标签 """ # 获取图片的数目 n = len(imgnames) data = np.zeros((n, 9)) # 用来存放特征提取后的分量 label = np.zeros((n)) # 用来存放样本标签 # 对每一张图片进行图像分割,并计算9个分量 for i in range(n): # 打开图像文件 img = Image.open(path + imgnames[i]) # 获取图片的尺寸 M, N = img.size # 图像切割提取图样中间部分,img.crop返回图像的矩阵区域,参数为 (left, upper, right, lower)的元祖 img = img.crop((M / 2 - 50, N / 2 - 50, M / 2 + 50, N / 2 + 50)) # 将图像分割成3个通道, r, g, b = img.split() # 转化为数组数据并归一化,获得对应的像素矩阵 rd = np.array(r, dtype=np.float32) / 255 gd = np.array(g, dtype=np.float32) / 255 bd = np.array(b, dtype=np.float32) / 255 # 计算一阶颜色矩 data[i, 0] = rd.mean() data[i, 1] = gd.mean() data[i, 2] = bd.mean() # 计算二阶颜色矩 data[i, 3] = rd.std() data[i, 4] = gd.std() data[i, 5] = bd.std() # 计算三阶颜色矩 data[i, 6] = Var(rd) data[i, 7] = Var(gd) data[i, 8] = Var(bd) # 获取样本标签-每个图片名的第一个数字代表类别 label[i] = imgnames[i][0] return data, label if __name__ == '__main__': # 获取所有图片的名称 imgNames = get_ImgNames(path='../chap9/images') # 图像切割与特征提取 data, label = imageCutting_FeatureExtraction(path='../chap9/images/', imgnames=imgNames) print(data) print(label)
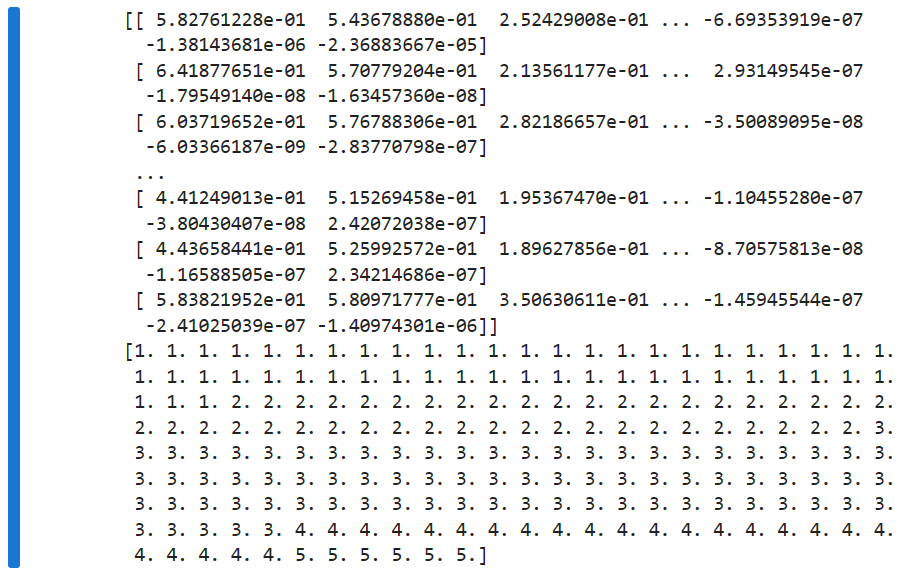
from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import confusion_matrix, accuracy_score # 划分数据集 # shuffle=True尽可能每一类别都取到或者采用分层抽样 data_tr, data_te, label_tr, label_te = train_test_split(data, label, test_size=0.2, shuffle=True) model = DecisionTreeClassifier(random_state=1234) model.fit(data_tr, label_tr) # 预测 pred_te = model.predict(data_te) # 混淆矩阵 cm = confusion_matrix(label_te, pred_te) print('混淆矩阵为\n', cm) # 准确率 acc = accuracy_score(label_te, pred_te) print('准确率为\n', acc) print("——————————————————————by number35任")

可见打乱后,准确率更高,效果更好。
方法三:分层抽样
StratifiedKFold分层的K折交叉和验证,是将训练集划分为训练集与验证集,保证它们中的比例。根据分层抽样思想自定义函数,保证训练集与测试集的类别比例与原数据集中的相等。
import math import numpy as np import os, re from PIL import Image import pandas as pd def get_ImgNames(path): """ 获取图片名称 :param path: 路径 :return: 名称列表 """ # os.listdir用于返回该路径下所包含的文件或文件夹的名字列表 filenames = os.listdir(path=path) imgnames = [] for i in filenames: # 在返回的文件名字中寻找正则表达式所匹配的所有字符串,如果不存在,返回空列表 if re.findall('^\d_\d+\.jpg$', i) != []: imgnames.append(i) return imgnames def Var(data=None): """ 获取三阶颜色矩 :param p: 数据 :return: 返回三阶颜色矩 """ x = np.mean((data - data.mean()) ** 3) return np.sign(x) * np.abs(x) ** 1 / 3 def imageCutting_FeatureExtraction(path, imgnames=None): """ 图像切割与基于颜色矩进行特征提取 :param path: 路径 :param imgnames: 所有图片的名称 :return: 返回特征提取后的9个分量,以及对应标签 """ # 获取图片的数目 n = len(imgnames) data = np.zeros((n, 9)) # 用来存放特征提取后的分量 label = np.zeros((n)) # 用来存放样本标签 # 对每一张图片进行图像分割,并计算9个分量 for i in range(n): # 打开图像文件 img = Image.open(path + imgnames[i]) # 获取图片的尺寸 M, N = img.size # 提取图样中间部分,img.crop返回图像的矩阵区域,参数为 (left, upper, right, lower)的元祖 img = img.crop((M / 2 - 50, N / 2 - 50, M / 2 + 50, N / 2 + 50)) # 将图像分割成3个通道, r, g, b = img.split() # 转化为数组数据并归一化,获得对应的像素矩阵 rd = np.array(r, dtype=np.float32) / 255 gd = np.array(g, dtype=np.float32) / 255 bd = np.array(b, dtype=np.float32) / 255 # 计算一阶颜色矩 data[i, 0] = rd.mean() data[i, 1] = gd.mean() data[i, 2] = bd.mean() # 计算二阶颜色矩 data[i, 3] = rd.std() data[i, 4] = gd.std() data[i, 5] = bd.std() # 计算三阶颜色矩 data[i, 6] = Var(rd) data[i, 7] = Var(gd) data[i, 8] = Var(bd) # 获取样本标签 label[i] = imgnames[i][0] return data, label def split_train_test(data, test_size=0.2): """ 保证训练集与测试集的类别比例与原数据集中的相等 :param data: 特征向量 :param label: 标签 :param test_size: 测试集比例 :return: 训练集与测试集 """ label = set(data.iloc[:, -1]) data_tr = pd.DataFrame() data_te = pd.DataFrame() for i in label: data_i = data[data.iloc[:, -1] == i] # 标签是i的数据集长度 length = len(data_i) # 切割的数据长度 split_length = math.floor(length * test_size) tr = data_i.iloc[:split_length, :] te = data_i.iloc[split_length:, :] data_tr = data_tr.append(tr) data_te = data_te.append(te) return data_tr.iloc[:, :-1], data_te.iloc[:, :-1], data_tr.iloc[:, -1], data_te.iloc[:, -1] if __name__ == '__main__': # 获取所有图片的名称 imgNames = get_ImgNames(path='../chap9/images') # 图像切割与特征提取 data, label = imageCutting_FeatureExtraction(path='../chap9/images/', imgnames=imgNames) print(data) print(label) from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import confusion_matrix, accuracy_score data = pd.DataFrame(np.hstack((data, label.reshape(-1, 1)))) # 划分数据集 data_tr, data_te, label_tr, label_te = split_train_test(data, test_size=0.2) model = DecisionTreeClassifier(random_state=1234) model.fit(data_tr, label_tr) # 预测 pred_te = model.predict(data_te) # 混淆矩阵 cm = confusion_matrix(label_te, pred_te) print('混淆矩阵为\n', cm) # 准确率 acc = accuracy_score(label_te, pred_te) print('准确率为\n', acc) print("——————————————————————by number35任")


 浙公网安备 33010602011771号
浙公网安备 33010602011771号