第四章 数据预处理
4.1 数据清洗
4.1.1 缺失值处理
下面结合具体案例介绍拉格朗日插值法
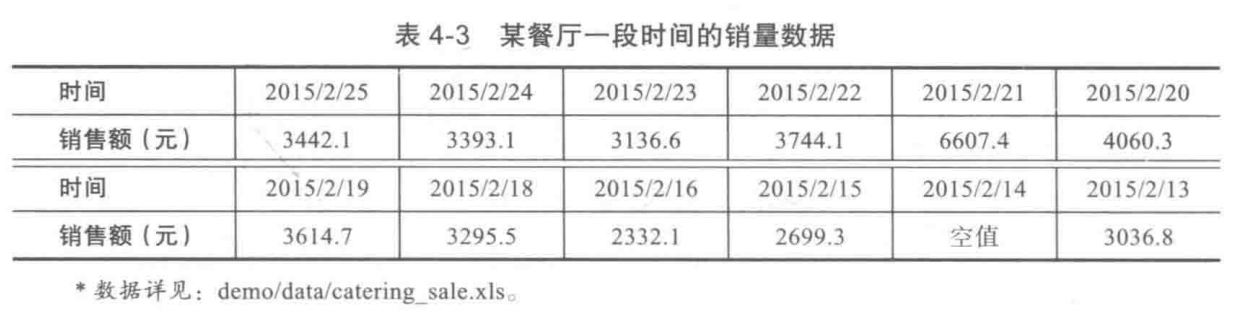
餐饮系统中的销量数据可能会出现缺失值,表4-3为某餐厅一段时间内的销量数据其中2015年2月14日的数据缺失,用拉格朗日插值法对缺失值进行插补,如代码清单4-1所示。
4.1.2 异常值处理
4.2 数据集成
数据挖掘需要的数据往往分布在不同的数据源中,数据集成就是将多个数据源合并存放在一个一致的数据存储位置(如数据仓库)中的过程
在数据集成时,来自多个数据源的现实世界实体的表达形式是不一样的,有可能不匹配,要考虑实体识别问题和属性冗余问题,从而将源数据在最底层上加以转换、提炼和集成。
(先变换,后动作)
4.2.1 实体识别
实体识别:是数据挖掘中60%的工作量,因为需要检测和解决数据单位不统一、同名异义、异名同义的冲突
4.2.2 冗余属性识别
涉及到用pandas工作
4.2.3 数据变换
数据变换主要是对数据进行规范化处理,将数据转换成“适当的”形式,以适用于挖掘任务及算法的需要
新概念:数据终台
4.2.4 简单函数变换
简单函数变换是对原始数据进行某些数学函数变换,常用的包括平方、开方、取对数、差分运算等,往往会有很好的效果
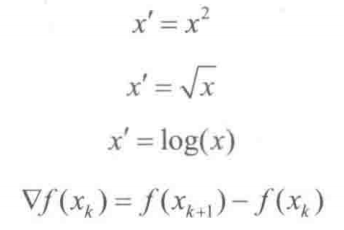
4.2.5 规范化
数据标准化(归一化)处理是数据挖掘的一项基础工作。不同评价指标往往具有不同的量纲,数值间的差别可能很大,不进行处理可能会影响数据分析的结果。为了消除指标之间的量纲和取值范围差异的影响,需要进行标准化处理,将数据按照比例进行缩放,使之落入一个特定的区域,便于进行综合分析,如将工资收人属性值映射到 [-1,1] 或者 [0,1] 内。
数据规范化对于基于距离的挖掘算法尤为重要。
下面介绍三种规范化方法:最小-最大规范化,零-均值规范化、小数定标规范化。
注意事项:
根据公式进行分析——
最小-最大规范化:max-min不能太小
零-均值规范化:标准差不能太小
小数定标规范化
4.2.6 连续属性离散化
思考:如何将各个属性映射到分类值上,分几类最合适
一些数据挖掘算法,特别是某些分类算法,如ID3 算法、Apriori算法等,要求数据是分类属性形式。这样,常常需要将连续属性变换成分类属性,即连续属性离散化。
4.2.7 属性构造
在数据挖掘过程中,为了帮助用户提取更有用的信息,挖掘更深层次的模式,提高挖掘结果的精度,需要利用已有的属性集构造出新的属性,并加入到现有的属性集合中。
根据现实情况具体构造新属性。
4.2.8 小波变换
泛函、复变函数,对噪声处理,对股票的分析
(1)基于小波变换的特征提取方法
(2)小波基函数
(3)小波变换
--可逆的


(4)基于小波变换的多尺度空间能量分布特征提取方法
4.3 数据归约
--降低数据规模,把大数据变成小数据(用的时候要想起来有这个工具)
4.3.1 属性归约
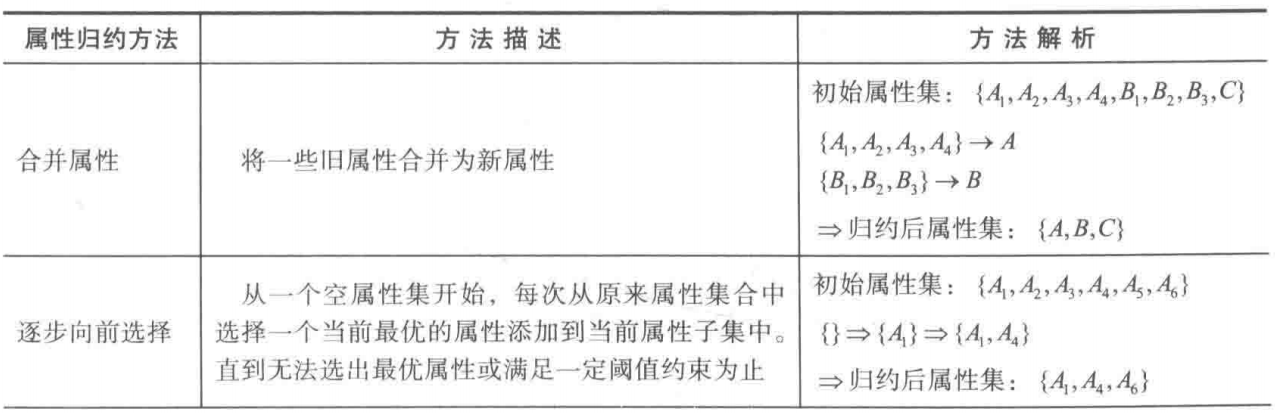
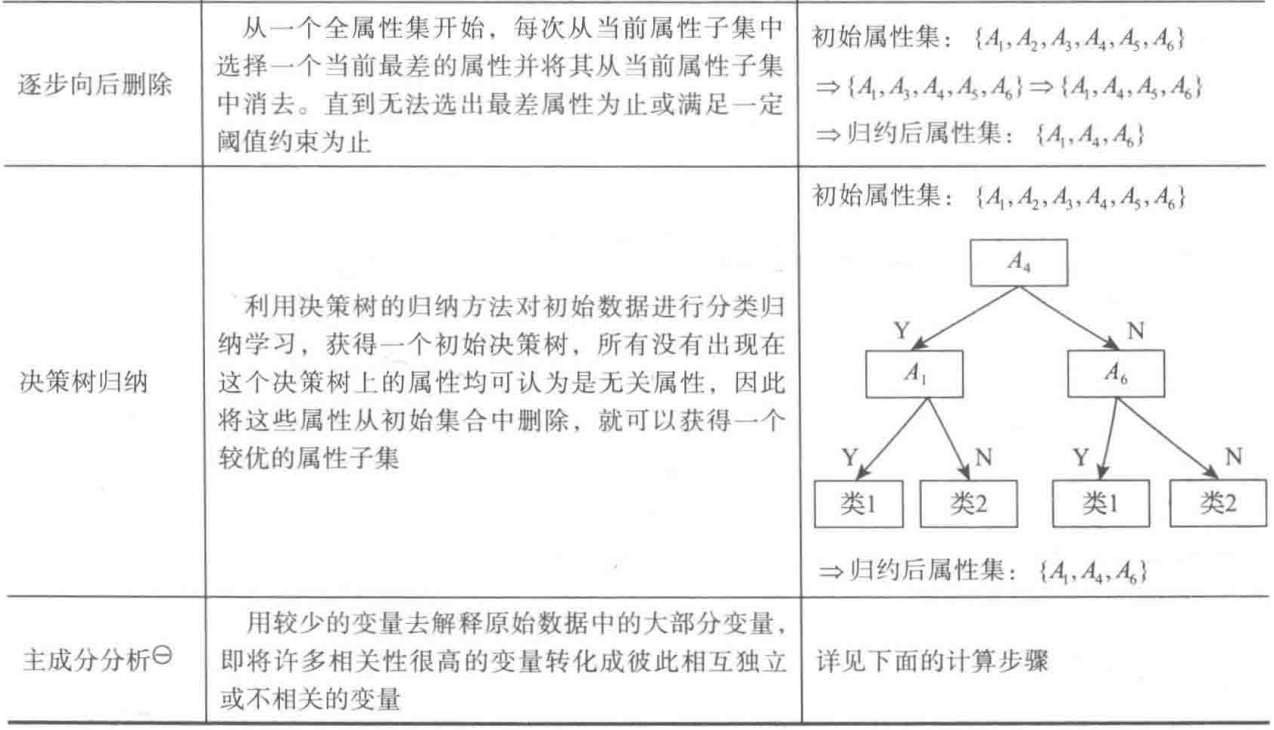
属性归约的常用方法:合并属性,逐步向前选择,逐步向后删除,决策树归纳,主成分分析。
4.3.2 数值归约
4.4 Python主要数据预处理函数

推荐学习网站(当做字典or学习手册):https://docs.scipy.org/doc/scipy/tutorial/index.html#user-guide


 浙公网安备 33010602011771号
浙公网安备 33010602011771号