from sklearn.model_selection import cross_val_predict
import pandas as pd
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_excel(r'D:\Machine Learning\35\hunxiao.xls')
y_train=df['real_labels'].tolist()
y_train_pre=df['pre_labels'].tolist()
#构建混淆矩阵
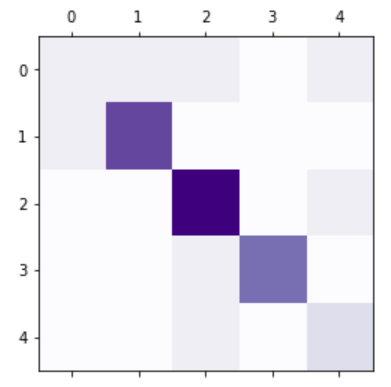
conf_mx=confusion_matrix(y_train,y_train_pre)
plt.matshow(conf_mx,cmap=plt.cm.Purples)
plt.show()
![]()
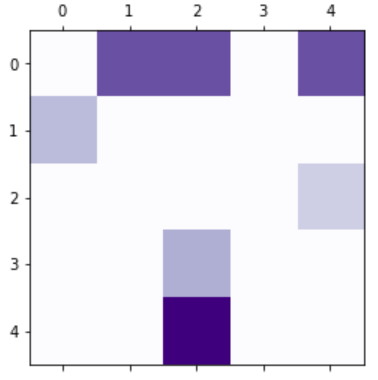
#将混淆矩阵中的每个值除以相应类中的数量,比较的就是错误率
row_sums=conf_mx.sum(axis=1,keepdims=True)
norm_conf_mx=conf_mx/row_sums
np.fill_diagonal(norm_conf_mx,0)
plt.matshow(norm_conf_mx,cmap=plt.cm.Purples)
plt.show()
# 所有的分类 label
labels = list(set(y_train_pre))
![]()
import itertools
# 绘制混淆矩阵
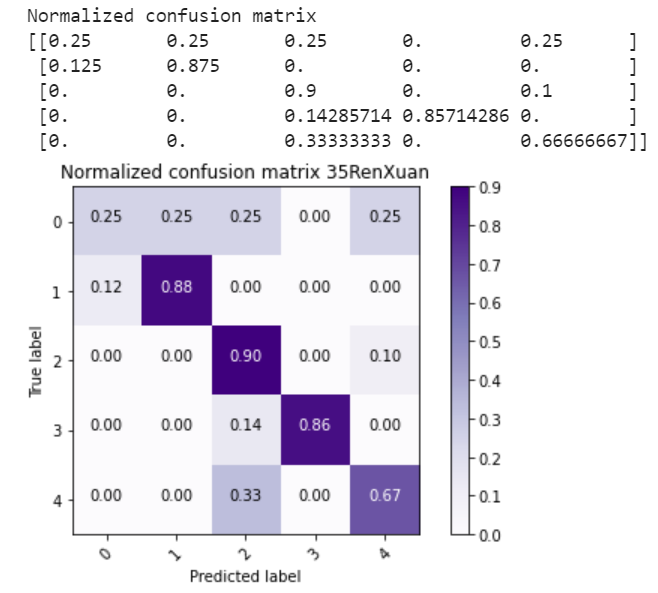
def plot_confusion_matrix(cm, classes, normalize=False, title='Normalized confusion matrix', cmap=plt.cm.Purples):
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
print(cm)
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()#侧边的颜色带
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
plot_confusion_matrix(conf_mx,labels,normalize=True,title='Normalized confusion matrix 35RenXuan')
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号