Hadoop MapReduce的Shuffle过程
一、概述
理解Hadoop的Shuffle过程是一个大数据工程师必须的,笔者自己将学习笔记记录下来,以便以后方便复习查看。
二、
MapReduce确保每个reducer的输入都是按键排序的。系统执行排序、将map输出作为输入传给reducer的过程称为Shuffle。
2.1 map端
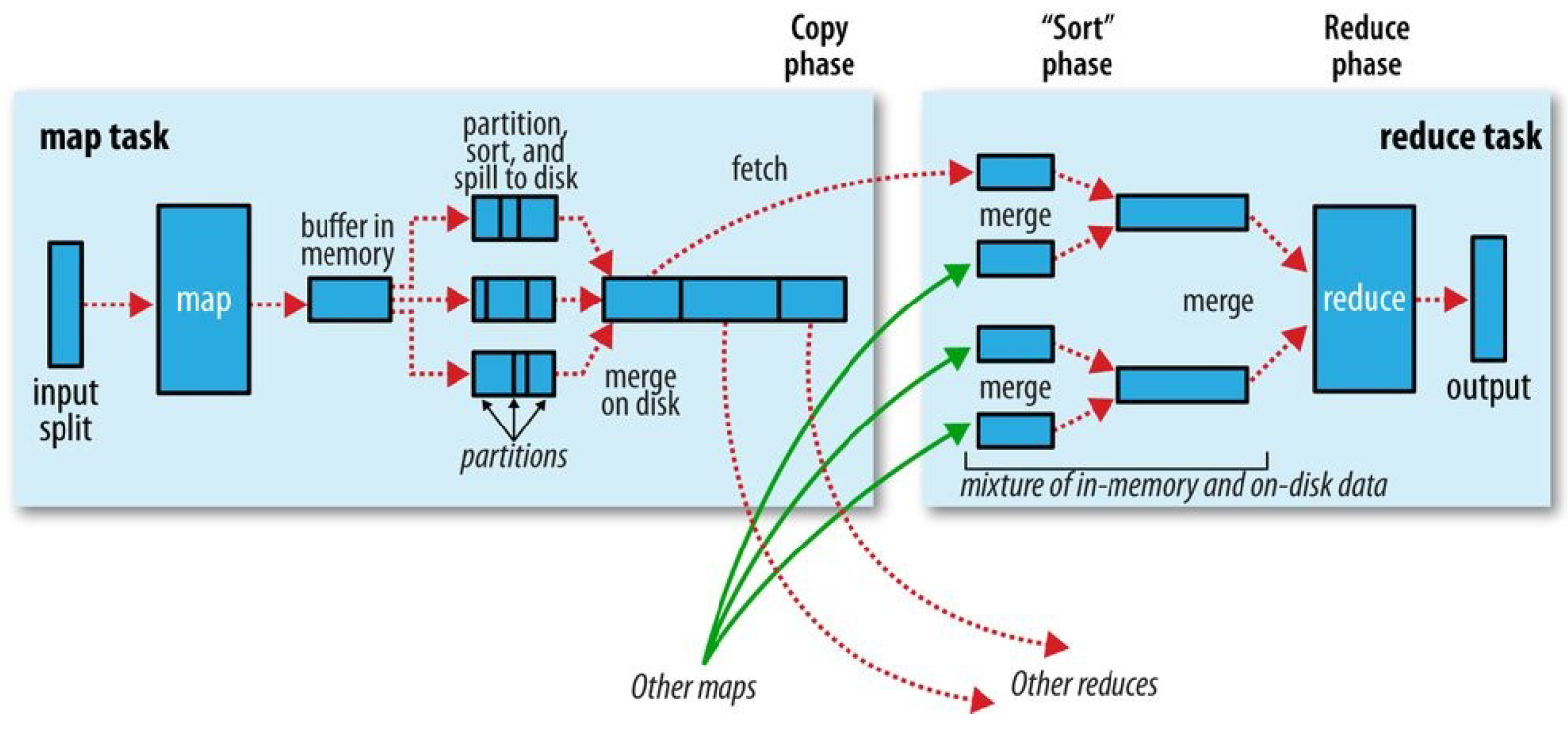
map函数开始产生输出时,利用缓冲的方式写到内存并排序具体分一下几个步骤。
1.map数据分片:把输入数据源进行分片,根据分片来决定有多少个map,每个map任务都有一个环形内存缓冲区用于存储任务输出,默认情况下缓冲区大小为100MB,可通过mapreduce.task.io.sort.mb来调整。
2.map排序:当map缓冲区大小达到阈值时(mapreduce.map.sort.spill.percent),就会将内存的数据溢写到磁盘,根据reducer的来划分成相应的partition,在内存中按键值进行排序,如果有combiner函数,在排序后就会应用,排序后写入分区磁盘文件中。溢写的过程中,map会阻塞直到写磁盘过程完成。每次内存缓冲区到达溢出阈值,就会新建一个溢出文件件,在map写完最后一个输出记录之后,会有几个溢出文件,在任务完成之前溢出文件会被合并成一个已分区且已经排序的输出文件。mapreduce.task.io.sort.factor控制着一次最多能合并多少溜,默认10。mapreduce.map.output.compress进行压缩,提高写磁盘速度。
2.2reduce端
1.reduce复制:reducer通过http得到输出文件的分区,用于文件分区的工作线程数量由任务的mapreduce.shuffle.max.threads属性控制。每个map任务的完成时间不同,在每个任务完成时,reduce任务就开始复制其输出,这就是reduce任务的复制阶段,reduce的复制线程数量mapreduce.reduce.shuffle.parallelcopies决定。
复制详解:如果map输出很小,会被复制到reduce任务JVM的内存,否则输出被复制到磁盘。如果内存缓冲区达到阈值大小(mapreduce.reduce.shuffle.merge.percent)或达到map输出阈值(mapreduce.reduce.merge.inmem.threshold),则合并溢出写到磁盘中,如果指定combiner,则在合并期间运行它。随着磁盘上副本增多,后台线程会将他们合并为更大的,排序的文件。
2.reduce合并排序:这个阶段合并map输出,维持其顺序排序,这是循环进行的,如果有50个map输出,合并因子是10(mapreduce.task.io.sort.factor),合并将进行5次,最后有5个中间文件。
3.reduce:直接把数据输入reduce函数,从而省略了一次磁盘的往返行程。
至此mapreduce过程完毕,具体参考Hadoop权威指南第四版。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号