week3b Resilient Distributed Dataset (RDD) 上
Resilient Distributed Dataset (RDD)
https://www.cse.unsw.edu.au/~cs9313/20T2/slides/L3.pdf
1.Features of RDD
•In memory computation:
不同于mapreduce将intermediate result放入hard disk, RDD直接在memory中操作
write and read in memory is 1000 times faster than read and write in hard disk.
•Partitioning
partition是RDD的fundamental unit
•Fault tolerance
节点丢失后可重建
•Immutability
被创建后不可变,即使数据被共享也不会被改变
•Persistence
RDD memery 不够时,数据会被写入disk;另一种是用户要求将data写入disk或者将RDD复制到不同机器
•Coarse-grained operations
operations will be applied on all the dataset
DFS是用find-grained operations : operations可以作用于 Part of the dataset
•Location-stickiness
2. Create RDDs
1)并行化驱动程序中的现有集合 通常,Spark会根据集群自动设置分区数量
2) 在外部存储系统中引用数据集。HDFS、HBase或任何提供Hadoop输入格式的数据源。默认情况下,Spark为文件的每个块(block)创建一个分区(partition)
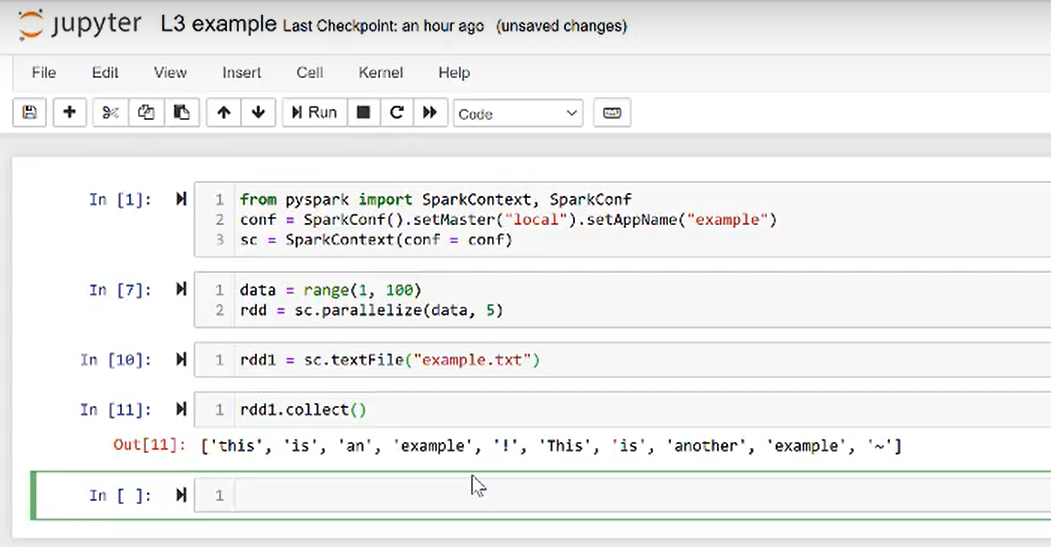
3. RDD operations
1. Transformations:
所有的 transformation 不会更改input RDD
1) functions: 输入为RDD,输出为一个或多个RDDs
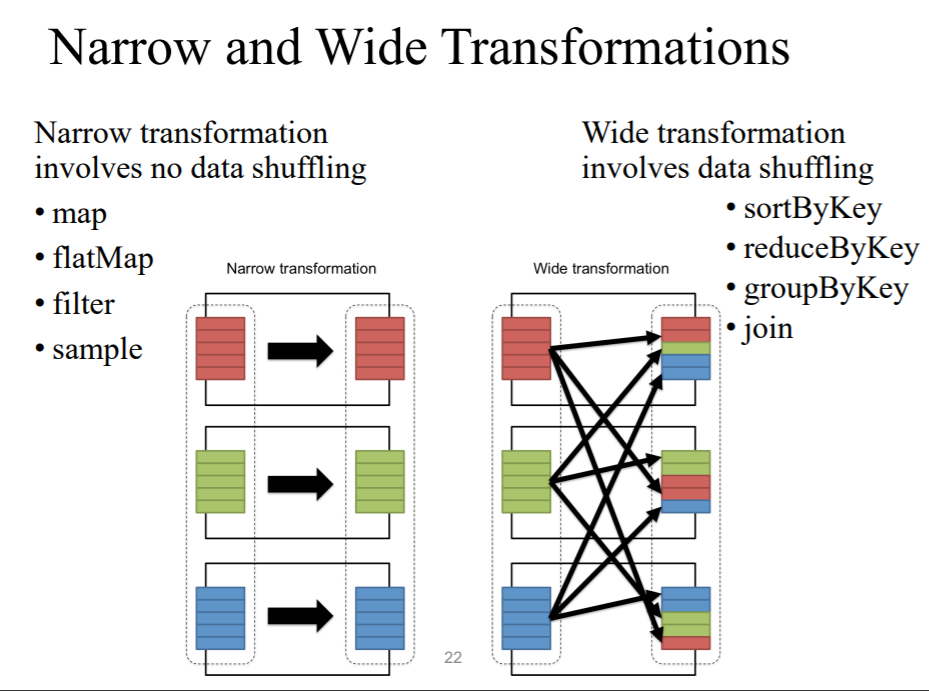
2)Narrow Transformation
3) Wide Transformation
2. Actions:
通常,在很多transformations之后,需要使用Actions获得一些信息,input是RDD,输出储存在storage system或者disks
1)RDD operations that produce non-RDD values
2)returns final result of RDD computations


 浙公网安备 33010602011771号
浙公网安备 33010602011771号