Python高级应用程序设计任务
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
名称:爬取厦门人才网中企业招聘要求等信息
2.主题式网络爬虫爬取的内容与数据特征分析
本次爬虫主要爬取厦门人才网网站中的企业招聘要求和岗位分布等信息
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
本次设计方案主要依靠request库对目标页面进行信息的爬取采集,再用BeautifulSoup对数据进行清洗,最后将结果打印出来。技术难点主要包括对数据的清洗以及对打印结果的排版。
整个框架分为六个模块:爬虫调度器、URL管理器、HTML下载器、HTML解析器、数据存储器、数据可视化
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
2.Htmls页面解析
1.主题页面的结构特征
2.Htmls页面解析
(1)通过在浏览器中用鼠标右键点击查看“查看元素”选项或按“F12”快捷键打开网页源代码
(2)用requests.get(url)命令向服务器提交请求,然后将响应的网页信息交由beautifulSoup解析,提取出HTML结构和源代码,最后用soup.prettify()方法输出源码


3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
查找方法find_all()
(必要时画出节点树结构)
查找方法find_all()
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
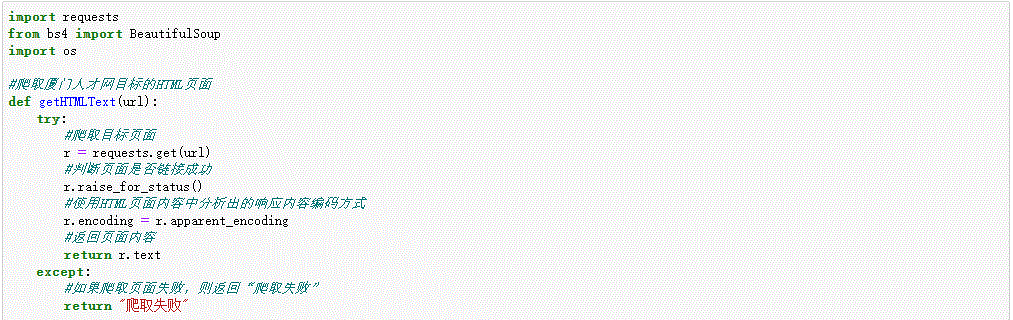
2.对数据进行清洗和处理


3.文本分析(可选):jieba分词、wordcloud可视
无
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)



5.数据持久化




6.附完整程序代码
import requests from bs4 import BeautifulSoup import os #爬取厦门人才网目标的HTML页面 def getHTMLText(url): try: #爬取目标页面 r = requests.get(url) #判断页面是否链接成功 r.raise_for_status() #使用HTML页面内容中分析出的响应内容编码方式 r.encoding = r.apparent_encoding #返回页面内容 return r.text except: #如果爬取页面失败,则返回“爬取失败” return "爬取失败" #爬取数据,对数据进行清洗和处理 def getData(wlist,mlist,clist,plist,elist,html): ulist = [] #创建BeautifulSoup对象 soup = BeautifulSoup(html,"html.parser") #遍历所有属性为class="bg"和data-selected="0"的tr标签 for tr in soup.find_all("tr",attrs = {"class":"bg","data-selected":"0"}): #将爬取到的工作名称存储在wlist列表中 #wlist.append(div.a.string.strip()) for a in tr.find_all("a",{"target":"_blank"}): ulist.append(a.get_text().strip()) for i in range(0,len(ulist),9): wlist.append(ulist[i]) for i in range(1,len(ulist),9): clist.append(ulist[i]) for i in range(2,len(ulist),9): plist.append(ulist[i]) for i in range(3,len(ulist),9): mlist.append(ulist[i]) for i in range(4,len(ulist),9): elist.append(ulist[i]) return wlist,clist,plist,mlist,elist #打印工作信息函数 def printUnivList(wlist,mlist,clist,plist,elist,num): for i in range(num): print("````````````````````````````````````````````````````````````````````````````") print("公司名称:{}".format(clist[i])) print("岗位名称:{}".format(wlist[i])) print("薪资待遇:{}".format(mlist[i])) print("工作地点:{}".format(plist[i])) print("学历要求:{}".format(elist[i])) #数据存储 def dataSave(wlist,mlist,clist,plist,elist,keyword,num): try: #创建文件夹 os.mkdir("C:\招聘信息") except: #如果文件夹存在,则什么都不做 "" try: #创建文件用于存储爬取到的数据 with open("C:\\招聘信息\\"+keyword+".txt","w") as f: for i in range(num): f.write("````````````````````````````````````````````````````````````````````````````\n") f.write("公司名称:{}\n".format(clist[i])) f.write("岗位名称:{}\n".format(wlist[i])) f.write("薪资待遇:{}\n".format(mlist[i])) f.write("工作地点:{}\n".format(plist[i])) f.write("学历要求:{}\n".format(elist[i])) except: "存储失败" #用来存储工作岗位 wlist = [] #用来存储薪资 mlist = [] #用来存储工作地点 plist = [] #用来存放学历 elist = [] #用来存放公司名称 clist = [] #厦门人才网的URL链接 head = "https://www.xmrc.com.cn/net/info/Resultg.aspx?a=a&g=g&recordtype=1&searchtype=1&keyword=" job = input("请输入工作名称:") mid = "&releasetime=365&worklengthflag=0&sortby=updatetime&ascdesc=Desc&PageIndex=" page = 5 num = page * 30 #获取第1-5页的工作信息 for i in range(1,page+1): url = head + job + mid + str(page) html = getHTMLText(url) getData(wlist,mlist,clist,plist,elist,html) printUnivList(wlist,mlist,clist,plist,elist,num) dataSave(wlist,mlist,clist,plist,elist,job,num)
# 导入第三方模块 import matplotlib.pyplot as plt # 设置绘图的主题风格(不妨使用R中的ggplot分隔) plt.style.use('ggplot') # 构造数据 edu = [0.2515,0.3724,0.3204,0.0557] labels = ['大专','本科','硕士研究生','其他'] explode = [0,0.1,0,0] # 用于突出显示大专学历人群 colors=['#9999ff','#ff9999','#7777aa','#2442aa'] # 自定义颜色 # 中文乱码和坐标轴负号的处理 plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] plt.rcParams['axes.unicode_minus'] = False # 将横、纵坐标轴标准化处理,保证饼图是一个正圆,否则为椭圆 plt.axes(aspect='equal') # 控制x轴和y轴的范围 plt.xlim(0,4) plt.ylim(0,4) # 绘制饼图 plt.pie(x = edu, # 绘图数据 explode=explode, # 突出显示大专人群 labels=labels, # 添加教育水平标签 colors=colors, # 设置饼图的自定义填充色 autopct='%.1f%%', # 设置百分比的格式,这里保留一位小数 pctdistance=0.8, # 设置百分比标签与圆心的距离 labeldistance = 1.15, # 设置教育水平标签与圆心的距离 startangle = 180, # 设置饼图的初始角度 radius = 1.5, # 设置饼图的半径 counterclock = False, # 是否逆时针,这里设置为顺时针方向 wedgeprops = {'linewidth': 1.5, 'edgecolor':'green'},# 设置饼图内外边界的属性值 textprops = {'fontsize':12, 'color':'k'}, # 设置文本标签的属性值 center = (1.8,1.8), # 设置饼图的原点 frame = 1 )# 是否显示饼图的图框,这里设置显示 # 删除x轴和y轴的刻度 plt.xticks(()) plt.yticks(()) # 添加图标题 plt.title('厦门人才网工作岗位学历要求') # 显示图形 plt.show()
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.经过对主题数据的分析与可视化,可以得到哪些结论?
结论:这次爬取的厦门人才网的数据进行了数据的清洗、分析和可视化,在这个过程中有很多的问题,比如在数据可视化的部分,由于厦门人才网的数据相对于其他的招聘网站内容会比较少,所以在可视化的过程中很难完成,查阅了许多资料才得以完成。
2.对本次程序设计任务完成的情况做一个简单的小结。
小结:在开始爬取厦门人才网的时候,我提前查阅了一些关于网络爬虫的资料,也看了许多的爬虫视频。在数据爬取、分析和可视化的时候,我感觉还是比较顺利完成,相对比较困难的就是数据可视化,在这一方面花了许多的时间。经过这个是我程序设计,我得到了许多收获,不仅学习了网络爬虫的基本要领,更重要的是丰富了知识。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号