


CNN作为denoiser的优势总结
图像恢复的MAP推理公式:
$\hat{x}\text{}=\text{}$arg min$_{x}\frac{1}{2}||\textbf{y}\text{}-\text{}\textbf{H}x||^{2}\text{}+\text{}\lambda\Phi(x)$
正则化项$\Phi(x)$对应恢复的表现扮演了至关重要的角色:
$\textbf{z}_{k+1}\text{}=\text{}Denoiser(\textbf{x}_{k+1},\sqrt{\lambda/\mu})$
然后介绍现在的降噪先验只要采取model-based 优化方法去解决inverse problem,包括:
-- total variation(TV)法 ==》 常常制造watercolor-like 鬼影、伪影
-- 高斯混合模型(Gaussian mixture model,GMM)
-- K-SVD ==》高计算消耗
-- 非局部均值(Non-local means) ==》如果图像不具有自相似属性,会过度平滑不规则的结构
-- BM3D==》 如果图像不具有自相似属性,会过度平滑不规则的结构
图像的颜色先验是一个十分重要的考虑因素,因为图像大多数图像是RGB格式。
而由于不同图像通道之间的相关性,联合处理图像的不同通道常常会产生更好的表现比独立处理每个颜色通道。
许多工作都只对灰度图像进行建模,而对于彩色图像的建模较少;
作者指出CBM3D 因为联合处理了RGB通道,收获了不错的效果,同时作者提出可以使用判别学习方法去自动化的揭示潜在的彩色图像先验,而不是依靠手工设计的pipeline;
CNN降噪先验具有速度、表现、判别彩色图像建模的优势,同时CNN去学习判别式降噪器(discriminative denoiser)有一些原因:
-- CNN 的前向传播由于GPU的存在而并行计算
-- CNN 表现出了强大的先验建模能力with deep architecture
-- CNN利用外部先验,作为了BM3D为代表的内部先验的补充
-- 利用判别式学习的优势
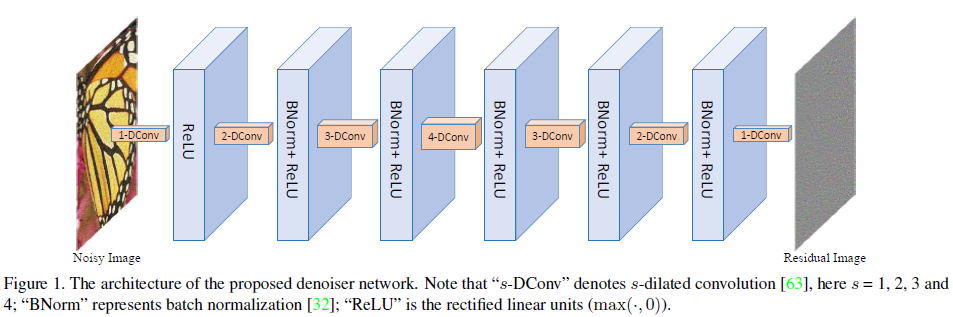
模型结构
CNN denoiser 如上图所示,网络包含七层,其中第一层是"扩张卷积(扩张指标为1,感知域还是3*3)+RELU",2-6层为“扩张卷积(扩张指标分别为2 3 4 3 2)+BN+RELU”, 最后一层为“扩展卷积(1),相当于正常的卷积运算,且每个中间层的特征图的数量都为64
扩张卷积filter and 增大的感知域
-- 在图像降噪中,上下文的信息能够促进毁坏像素的重建;
-- 为了捕获上下文的信息,通过前向的卷积操作去增大感知域是一个成功的方法;
有两种基本的增大感知域的方法:
-- 一个是增大filter size 弊端:会引入更多的参数,增大了计算负担
-- 一个是增大模型的深度
使用扩张卷积去获取filter size 和模型深度的平衡, 在保持 3*3 filter 的基础上 增大感知域, 整个7层网络实现了 33*33 的感知域, 相当于16层的3*3普通卷积;
其中扩张卷积的filter size 和 扩张指标s 之间的关系为: size = (2s+1)*(2s+1)
使用BN和残差学习加快训练
对于高斯降噪问题,结合BN和残差学习是十分有帮助的,他们都能够互相的获益(在他的论文中有讲Residual learning of deep CNN for image denoising.) 对于模型的迁移也有用;
残差学习方式,就是模型的目标不是直接学习产生降噪的图片,而是学习噪声即残差,即输入的带噪声的图片和干净图片的差。
使用小尺寸的图像作为训练集去避免边缘伪影
-- 由于CNN的特点,如果没有合适的处理,CNN的降噪图片将会产生边缘伪影;
-- 对称pandding 和 zero padding是两种解决这个问题的方法
-- 对于扩张指数为4的操作,在边缘pads 4 zeros,那其他的扩张指数呢?
-- 经验主义的使用了小尺寸的训练样本 去避免边缘伪影,原因包括:
-- 将大尺寸的图像crop 成小尺寸的patches,有利于CNN去看到更多的边沿信息,比如将70*70的patches crop成四个非重叠的35*35的patches,边缘信息被扩大了;
-- 就patch的大小可以作对比试验进行验证;
-- 当训练的patch尺寸小于感知域后,这个性能会下降;
学习实际的降噪器模型with 小间隔的噪声水平
-- 想要得到精确的子问题的解是非常困难且time-consuming的去优化的,使用不精确但是快速的子问题的解能够加快收敛(两篇文献:The augmented lagrange multiplier method for exact recovery of corrupted low-rank matrices.和 From learning models of natural im age patches to whole image restoration.)
-- 所以 没有必要去学习很多判别式降噪模型for 每个噪声水平。
-- 尽管$\textbf{z}_{k+1}\text{}=\text{}Denoiser(\textbf{x}_{k+1},\sqrt{\lambda/\mu})$ 是一个降噪器,但他与传统的高斯降噪有着不同的目标。
-- 传统的高斯降噪是恢复出潜在的干净图像,无论要去噪的图像的噪声类型和噪声水平如何,这里的去噪器都会发挥自己的作用。也就是说,不管这个图像有没有噪声,都会发挥作用!
-- 所以一个理想的判别降噪器应该使用当前的噪声水平进行训练:
训练了一系列的噪声水平在0-50同时独立的以2为间隔的模型,产生了25个模型为图像的先验进行建模;迭代方案的存在,使他恢复足以满足。
实验
图像降噪:
-- 将每个图片 crop 成了35*35的patches,因为使用残差学习的方式,损失函数:
$\textit{l}(\Theta)\text{}=\text{}\frac{1}{2N}\sum_{i=1}^{N}||f(y_{i};\Theta)\text{}-\text{}(y_{i}\text{}-\text{}x_{i})||^{2}$
-- 训练结束的标志 训练损失在五个连续的epoch固定
-- 使用了旋转翻转等数据扩充技巧;
-- 从不同方法的PSNR 进行了对比, 分别书灰度图和彩色图
-- 从不同方法的运行时间进行了对比
图像去模糊:
模糊核的选择:
-- 一个常见的模糊的高斯模糊核,标准差为1.6, 来自论文(Understanding and evaluating blind deconvolution algorithms)的前两个的真实模糊核;
-- 我们只需将颜色去噪器插入到HQS框架中;
-- 在公式6中:
![]()
-- 两个参数中,$\lambda$ 与$\sigma^{2}$相联系同时在迭代中保持固定,其中$\mu$控制着降噪器的噪声水平;
公式6(a)的快速解法:
$x_{k+1}=(H^{T}H+\mu I)^{-1}(H^{T}y+\mu z_{k}) \text{ }\text{ }\text{ }\text{ }\text{ }\text{ }(7)$
-- 由于hqs框架是基于去噪的,因此我们将每次迭代中去噪的噪声级隐式的确定为μ。
-- 在我们的实验设置中,根据噪声水平,它以指数形式从49衰减到[1,15]中的值。
-- 实验代码核心迭代部分
%模拟仿真的模糊噪声图片
k = fspecial('gaussian', 25, 1.6);%相当于是模糊算子
y = imfilter(im2double(x), k, 'circular', 'conv') + sigma*randn(size(x));
%denominator 表示是H^{T}H, H模糊算子与他的共轭矩阵相乘
V = psf2otf(k,[w,h]);%psf2otf(PSF) 其作用是将一个空间点扩散函数转换为频谱面的光学传递函数,执行的也是对PSF的FFT变换,变为了频域;
denominator = abs(V).^2;%y = abs(3+4i) y=5
%H^{T}*y H的共轭矩阵乘以输入y
upperleft = conj(V).*fft2(y); % conj(V) V=5-2i ==> 5+2i
%训练的特点噪声水平\sigma的一组denoiser,其\sigma以指数形式的衰减的不同模型;
modelSigmaS = logspace(log10(modelSigma1),log10(modelSigma2),totalIter);
%\lamba与噪声水平\sigma^2有关且在迭代中保持固定,\mu控制着降噪器的噪声水平,%rho隐式的表示\mu,见下面的计算方法与降噪器的噪声水平和噪声水平有关
rho = lamda*255^2/(modelSigmaS(itern)^2);%[243.742,267.099,292.694,320.742,351.476]
upperleft =
for itern = 1:totalIter
%%% step 1
rho = lamda*255^2/(modelSigmaS(itern)^2);
z = real(ifft2((upperleft + rho*fft2(z))./(denominator + rho)));
if ns(itern+1)~=ns(itern)
[net] = loadmodel(modelSigmaS(itern),CNNdenoiser);
net = vl_simplenn_tidy(net);
if useGPU
net = vl_simplenn_move(net, 'gpu');
end
end
%%% step 2
res = vl_simplenn(net, z,[],[],'conserveMemory',true,'mode','test');
residual = res(end).x;
z = z - residual;
end
真实模糊图像的测试
设置了两个重要的估计图像噪声水平 和 降噪器去噪水平的 超参数:
% There are two important parameters to tune:
% (1) image noise level of blurred image: Isigma and
% (2) noise level of the last denoiser: Msigma.
%使用了 别人的方法 产生的模糊核 图像作为先验的条件
%% read blurred image and its estimated kernel
% blurred image
Iname = 'im01_ker01';
y = im2single(imread(fullfile(folderTestCur,[Iname,'.png'])));
% estimated kernel
%k = imread(fullfile(folderTestCur,[Iname,'_kernel.png']));
k = imread(fullfile(folderTestCur,[Iname,'_out_kernel.png']));
if size(k,3)==3
k = rgb2gray(k);
end
k = im2single(k);
k = k./(sum(k(:))); %归一化
%比较重要的部分是边缘的处理
%% handle boundary
boundary_handle = 'case2';
switch boundary_handle
case {'case1'} % option (1), edgetaper to better handle circular boundary conditions, (matlab2015b)
% k(k==0) = 1e-10; % uncomment this for matlab 2016--2018?
ks = floor((size(k) - 1)/2);
y = padarray(y, ks, 'replicate', 'both');
for a=1:4
y = edgetaper(y, k);
end
case {'case2'} % option (2)
H = size(y,1); W = size(y,2);
y = wrap_boundary_liu(y, opt_fft_size([H W]+size(k)-1));
end
需要明白为什么需要进行边缘条件的变化,是让模糊核完全重合和图像,所以需要用模糊核 进行 一些 padding 操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号