实用程序:进度可视化文件大小计算(从卡顿到高效——文件夹大小统计的优化之路)
@
前言
如果你常处理数据备份、数据库整理或大型项目文件,一定遇过这样的窘境:想知道一个包含数万个子文件夹的目录总大小,双击属性后等待十几分钟甚至更久,屏幕却只有 “正在计算” 的转圈图标 —— 既不知道还要等多久,也不确定程序是不是卡住了。
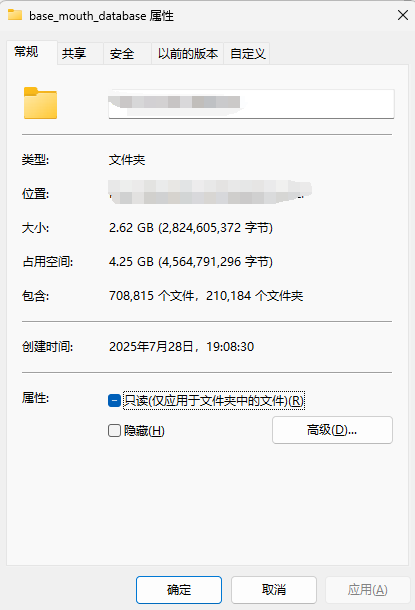
近期处理数据库时遇到了这个问题:需要统计目录的大小,而这个目录下足足有大量子文件夹且子文件夹内部也含有大量数据。最初用系统自带的 “属性” 功能,等了 10 分钟还没出结果;尝试简单的 Python 脚本,要么前期收集文件路径时卡顿,要么进度条不显示实时大小,完全摸不透进度。最终通过优化进度条逻辑,多线程工作,最终实现了 “秒级反馈、倍速计算” 的效果。具体流程如下:
一、初始方案
1、通过os.walk遍历文件夹,先遍历收集所有内部文件路径;
2、用tqdm包装文件遍历过程,显示 “处理文件数” 的进度条;
3、累加每个文件的大小,最后转换为易读格式(GB/TB)输出;
import os
from tqdm import tqdm
def get_folder_size(folder_path):
"""
计算文件夹指定文件夹的总大小,并显示进度条
参数:
folder_path: 文件夹路径
返回:
文件夹总大小(字节)
"""
# 检查路径是否存在
if not os.path.exists(folder_path):
print(f"错误: 路径 '{folder_path}' 不存在")
return 0
# 检查是否是文件夹
if not os.path.isdir(folder_path):
print(f"错误: '{folder_path}' 不是一个文件夹")
return 0
# 首先收集所有文件路径,用于进度条
file_paths = []
for root, dirs, files in os.walk(folder_path):
for file in files:
file_path = os.path.join(root, file)
file_paths.append(file_path)
total_size = 0
# 使用tqdm创建进度条
for file_path in tqdm(file_paths, desc="计算中", unit="个文件"):
try:
# 获取文件大小并累加
file_size = os.path.getsize(file_path)
total_size += file_size
except OSError as e:
print(f"\n无法访问文件 '{file_path}': {e}")
return total_size
def format_size(size_bytes):
"""
将字节大小转换为易读的格式
参数:
size_bytes: 字节数
返回:
格式化后的大小字符串
"""
# 定义单位和转换因子
units = ['B', 'KB', 'MB', 'GB', 'TB']
size = size_bytes
unit_index = 0
# 转换单位直到合适的规模
while size >= 1024 and unit_index < len(units) - 1:
size /= 1024
unit_index += 1
return f"{size:.2f} {units[unit_index]}"
if __name__ == "__main__":
# 在此处直接设置要统计的文件夹路径
# 例如:folder_path = "C:/Users/YourName/Documents"
# 或在Linux/macOS上:folder_path = "/home/yourname/documents"
folder_path = "请替换为你的文件夹路径"
print(f"将计算文件夹: {folder_path} 的大小")
# 计算文件夹大小
total_size = get_folder_size(folder_path)
# 显示结果
if total_size > 0:
formatted_size = format_size(total_size)
print(f"\n文件夹 '{folder_path}' 的总大小: {formatted_size}")
这个过程看似没有什么问题,但是在第一步的时候,由于文件夹内部的文件数量实在太多(最后计算文件数共),第一过程便已经非常耗时,而这个过程是不在tqdm的包装中,需要卡顿很久的时间,运行效果基本就是卡在那边没有动静
二、方案优化
1、优化遍历逻辑,实现遍历进度可视
在明白问题的原因(内部文件数量太多,遍历过程耗时)后,通过一个简单的改动调整:
1、在第一次遍历的时候,只遍历第一级文件夹,记录第一级文件夹的路径,而非像原本逻辑那样遍历所有的内部文件夹乃至内部文件夹的内部文件。由于第一级文件夹的数量相对而言较少(只有四万多),所以遍历第一级文件夹的过程是很快的基本可以忽略不计
2、然后利用tqdm包装进度条的时候,for循环遍历的不是全部的内部文件路径,而是第一级文件夹的路径,在每一个第一级文件夹中在进行内部遍历(此处可以考虑用一个新的第二级进度条)来显示某一个第一级文件夹的计算进度,会使得结果更加直观(遇到较大第一级文件夹的时候更新不卡顿)
实现代码如下:
import os
import sys
from tqdm import tqdm
def format_size(size_bytes):
"""将字节大小转换为易读的格式"""
units = ['B', 'KB', 'MB', 'GB', 'TB']
size = size_bytes
unit_index = 0
while size >= 1024 and unit_index < len(units) - 1:
size /= 1024
unit_index += 1
return f"{size:.2f} {units[unit_index]}"
def calculate_directory_size(directory, total_size_ref):
"""计算单个目录的大小,实时更新总大小引用"""
dir_size = 0
for root, dirs, files in os.walk(directory):
for file in files:
file_path = os.path.join(root, file)
try:
file_size = os.path.getsize(file_path)
dir_size += file_size
total_size_ref[0] += file_size # 使用列表引用更新总大小
except OSError:
continue
return dir_size
def get_folder_size(folder_path):
"""计算文件夹总大小,确保实时显示累加进度和大小"""
if not os.path.exists(folder_path):
print(f"错误: 路径 '{folder_path}' 不存在")
return 0
if not os.path.isdir(folder_path):
print(f"错误: '{folder_path}' 不是一个文件夹")
return 0
# 获取第一级子文件夹和根目录文件
items = os.listdir(folder_path)
first_level_dirs = []
total_size = [0] # 使用列表存储,以便在函数内部修改
# 计算根目录文件大小
for item in items:
item_path = os.path.join(folder_path, item)
if os.path.isfile(item_path):
try:
total_size[0] += os.path.getsize(item_path)
except OSError:
continue
elif os.path.isdir(item_path):
first_level_dirs.append(item_path)
# 没有子文件夹的情况
if not first_level_dirs:
return total_size[0]
# 显示初始信息
print(f"发现 {len(first_level_dirs)} 个子文件夹,正在计算大小...")
print(f"初始文件大小: {format_size(total_size[0])}")
# 处理所有第一级子文件夹
progress_bar = tqdm(first_level_dirs, desc="处理中", unit="个文件夹")
for i, dir_path in enumerate(progress_bar):
# 计算子文件夹大小,同时更新总大小
calculate_directory_size(dir_path, total_size)
# 更新进度条,包含当前总大小
current_size = format_size(total_size[0])
progress_bar.set_description(f"处理中 - 总大小: {current_size}")
# 每处理100个子文件夹额外打印一次,确保用户能看到
if i % 100 == 0 and i > 0:
print(f"已处理 {i+1}/{len(first_level_dirs)} 个子文件夹,当前总大小: {current_size}")
return total_size[0]
if __name__ == "__main__":
# 设置要统计的文件夹路径
folder_path = "F:/LIP-REAINDG-DATABASES-ACLP/mouth" # 直接使用您提供的路径
print(f"正在计算文件夹: {folder_path} 的大小")
# 计算并显示结果
total_size = get_folder_size(folder_path)
if total_size > 0:
formatted_size = format_size(total_size)
print(f"\n文件夹 '{folder_path}' 的总大小: {formatted_size}")
实现结果如下:

可以看到在一开始运行程序的时候,进度条就已经展示出来了,并且以较快的速度进行每个内部文件夹以及文件的遍历。
2、使用多线程以及优化IO操作实现进一步速度优化
针对 “文件大小统计是 IO 密集型任务” 的特性,用多线程并行处理子文件夹,并替换更高效的 IO 遍历函数。
多线程并行:用ThreadPoolExecutor创建线程池,默认线程数为 “CPU 核心数 ×5”(IO 密集型任务适合多线程,避免 IO 等待浪费时间);
高效 IO 遍历:用os.scandir替代os.listdir+os.path组合 ——os.scandir一次调用就能获取文件属性(如是否为文件 / 文件夹、大小),比传统方式快 2-3 倍;
减少锁竞争:每个线程先独立计算完子文件夹大小,再通过锁机制更新总大小(避免每个文件都加锁,减少性能损耗)。
具体实现代码如下(线程数设为64)
import os
import sys
import threading
from concurrent.futures import ThreadPoolExecutor, as_completed
from tqdm import tqdm
def format_size(size_bytes):
"""将字节大小转换为易读的格式"""
units = ['B', 'KB', 'MB', 'GB', 'TB']
size = size_bytes
unit_index = 0
while size >= 1024 and unit_index < len(units) - 1:
size /= 1024
unit_index += 1
return f"{size:.2f} {units[unit_index]}"
def calculate_directory_size(directory):
"""计算单个目录的大小(纯计算,不更新总进度)"""
total_size = 0
file_count = 0
with os.scandir(directory) as entries:
for entry in entries:
try:
if entry.is_file(follow_symlinks=False):
total_size += entry.stat().st_size
file_count += 1
elif entry.is_dir(follow_symlinks=False):
sub_size, sub_count = calculate_directory_size(entry.path)
total_size += sub_size
file_count += sub_count
except OSError:
continue
return total_size, file_count
def get_folder_size(folder_path, max_workers=None):
"""
计算文件夹总大小(多线程优化版)
参数:
folder_path: 文件夹路径
max_workers: 最大线程数,默认使用CPU核心数*5
"""
if not os.path.exists(folder_path):
print(f"错误: 路径 '{folder_path}' 不存在")
return 0
if not os.path.isdir(folder_path):
print(f"错误: '{folder_path}' 不是一个文件夹")
return 0
# 获取第一级子文件夹和根目录文件
first_level_dirs = []
root_files_size = 0
root_file_count = 0
with os.scandir(folder_path) as entries:
for entry in entries:
try:
if entry.is_file(follow_symlinks=False):
root_files_size += entry.stat().st_size
root_file_count += 1
elif entry.is_dir(follow_symlinks=False):
first_level_dirs.append(entry.path)
except OSError:
continue
total_size = root_files_size
total_file_count = root_file_count
dir_count = len(first_level_dirs)
if dir_count == 0:
return total_size, total_file_count
print(f"发现 {dir_count} 个子文件夹,使用多线程计算大小...")
print(f"初始文件大小: {format_size(total_size)},初始文件数: {total_file_count}")
lock = threading.Lock()
progress = tqdm(total=dir_count, desc="处理中", unit="个文件夹")
def process_dir(dir_path):
dir_size, file_count = calculate_directory_size(dir_path)
with lock:
nonlocal total_size, total_file_count
total_size += dir_size
total_file_count += file_count
current_size = format_size(total_size)
progress.set_description(f"处理中 - 总大小: {current_size}")
progress.update(1)
return dir_size, file_count
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = [executor.submit(process_dir, dir_path) for dir_path in first_level_dirs]
for _ in as_completed(futures):
pass
progress.close()
return total_size, total_file_count
if __name__ == "__main__":
# 设置要统计的文件夹路径
folder_path = r""
print(f"正在计算文件夹: {folder_path} 的大小")
# 计算并显示结果(线程数默认使用CPU核心数*5,可根据需要调整)
total_size, total_file_count = get_folder_size(folder_path, max_workers=64)
if total_size > 0:
formatted_size = format_size(total_size)
print(f"\n文件夹 '{folder_path}' 的总大小: {formatted_size}")
print(f"文件总数: {total_file_count}")
实现效果如下:

总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号