机器视觉:Vision Transformer——打破CNN垄断的视觉革命先锋
引言
在计算机视觉(CV)领域的漫长发展中,卷积神经网络(CNN)凭借其固有的平移等变性和局部归纳偏置,长期占据绝对主导地位。从LeNet到ResNet,再到EfficientNet,CNN的网络结构迭代不断推动着视觉任务性能的突破。然而,2020年一款全新模型的出现,彻底打破了这一格局——它将自然语言处理(NLP)领域的Transformer架构直接引入视觉任务,在大规模数据支撑下实现了超越传统CNN的性能表现,它就是Vision Transformer(简称ViT)。ViT的诞生不仅打通了CV与NLP两大领域的技术壁垒,更开启了视觉模型发展的全新范式。本文将从ViT的起源、定义、核心原理、应用现状、后续演变及总结等方面,进行全面详细的解读。
@
一、ViT的诞生:一篇论文掀起的视觉革命
Vision Transformer的概念首次正式提出于2020年由Google Brain团队发表的论文《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》,该论文最终被国际顶级会议ICLR 2021接收,成为ViT领域的开山之作。在此之前,Transformer虽已在NLP领域一统江湖,但在CV领域的应用多局限于与CNN结合的混合架构(如Detr),尚未出现纯Transformer架构在图像识别任务中超越CNN的案例。
这篇论文的核心贡献在于证明了“无需依赖CNN的归纳偏置,纯Transformer架构仅通过处理图像块序列,就能在图像识别任务中取得优异性能”。其核心思路是将图像分割为固定大小的图像块(Patch),通过线性嵌入将每个图像块转换为向量,再借鉴NLP中Transformer的输入形式,添加位置编码(Positional Encoding)以保留空间信息,最后将处理后的序列输入标准Transformer Encoder进行特征提取,最终通过分类头完成图像识别任务。
论文通过大量对比实验验证了ViT的性能:当在大规模数据集(如JFT-300M)上预训练后,ViT在多个下游图像识别任务中表现超越当时最先进的CNN模型。其中,最佳配置的ViT模型在ImageNet数据集上实现88.55%的准确率,在ImageNet-ReaL(清理后的真实标签数据集)上准确率达90.72%,在CIFAR-100数据集上准确率为94.55%,在包含19个任务的VTAB评估套件上准确率达77.63%。更重要的是,ViT在达到同等性能时,训练所需的计算资源仅为传统CNN的1/2至1/4。这些突破性结果,直接颠覆了“CNN是视觉任务最优架构”的固有认知。
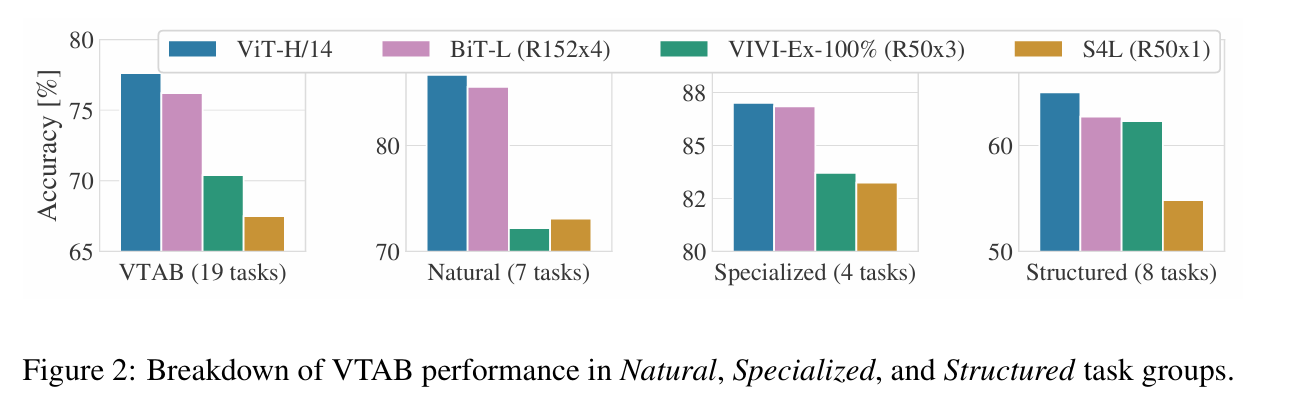
图 2 将 VTAB 任务分解为对应组别,并在该基准上与此前的当前最优(SOTA)方法进行对比:BiT、VIVI(Tschannen 等人,2020 年提出的在 ImageNet 和 Youtube 上联合训练的 ResNet 模型)以及 S4L(Zhai 等人,2019a 提出的基于 ImageNet 的监督 + 半监督学习方法)。ViT-H/14 在自然类和结构化类任务上优于 BiT-R152x4 及其他方法,而在专业类任务上,排名前两位的模型性能相近。
二、ViT的核心定义与工作原理
Vision Transformer(ViT)是一种将Transformer架构直接应用于图像数据的视觉模型,它通过将图像转换为序列化的图像块,利用自注意力机制捕捉图像全局特征,从而实现各类视觉任务。与CNN依赖局部卷积操作不同,ViT的核心优势在于能够高效建模图像中远距离区域的依赖关系,这一特性使其在需要全局理解的视觉任务中具备天然优势。其完整工作流程可分为四个核心步骤:
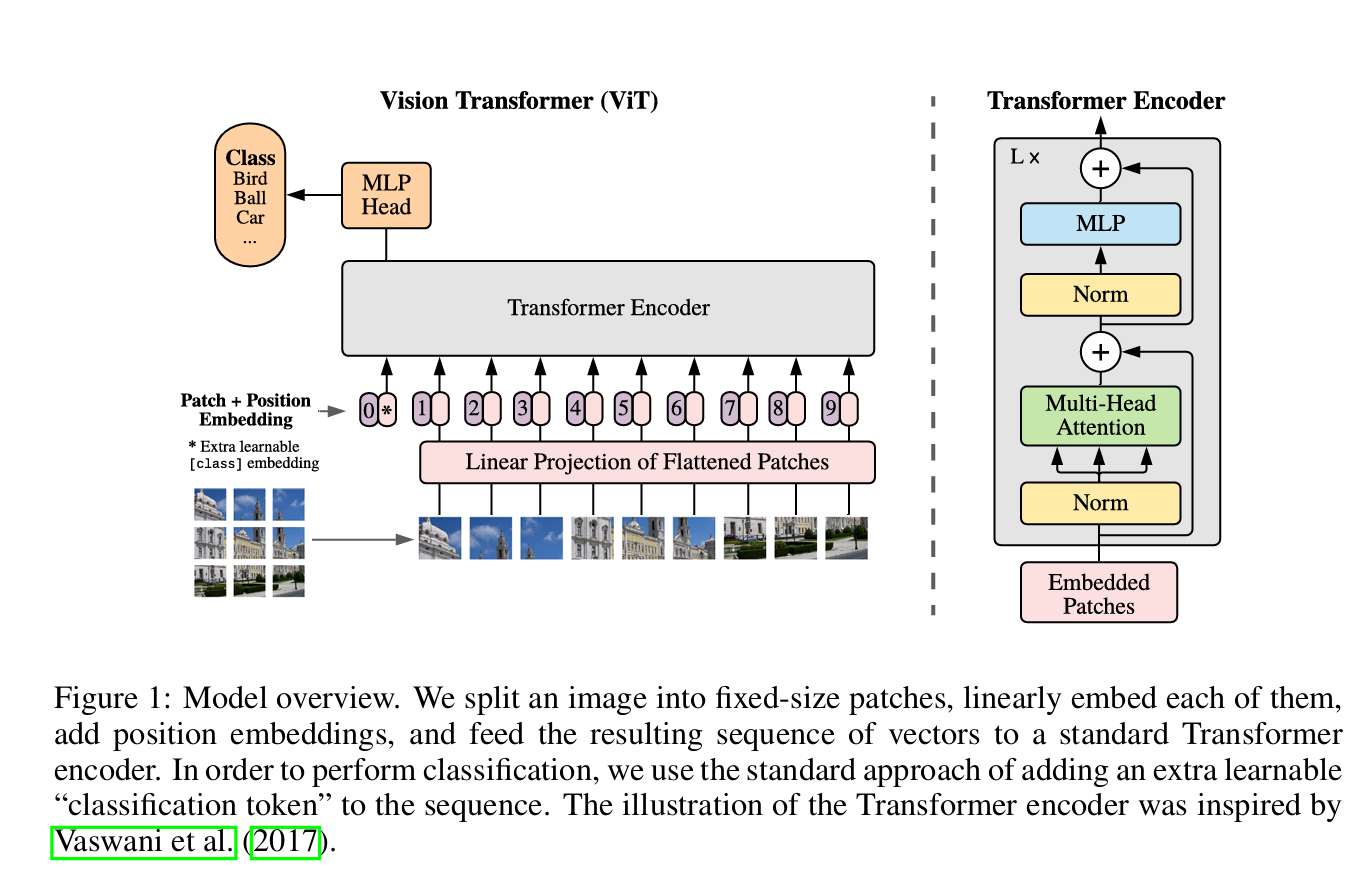
图 1:模型概述。我们将图像分割为固定大小的补丁块,对每个补丁块进行线性嵌入,添加位置嵌入,并将得到的向量序列输入标准 Transformer 编码器。为实现分类,我们采用标准方法,在序列中添加一个额外的可学习 “分类令牌”。Transformer 编码器的示意图参考了 Vaswani 等人(2017 年)的设计。
-
图像预处理:将图像转换为“单词”序列
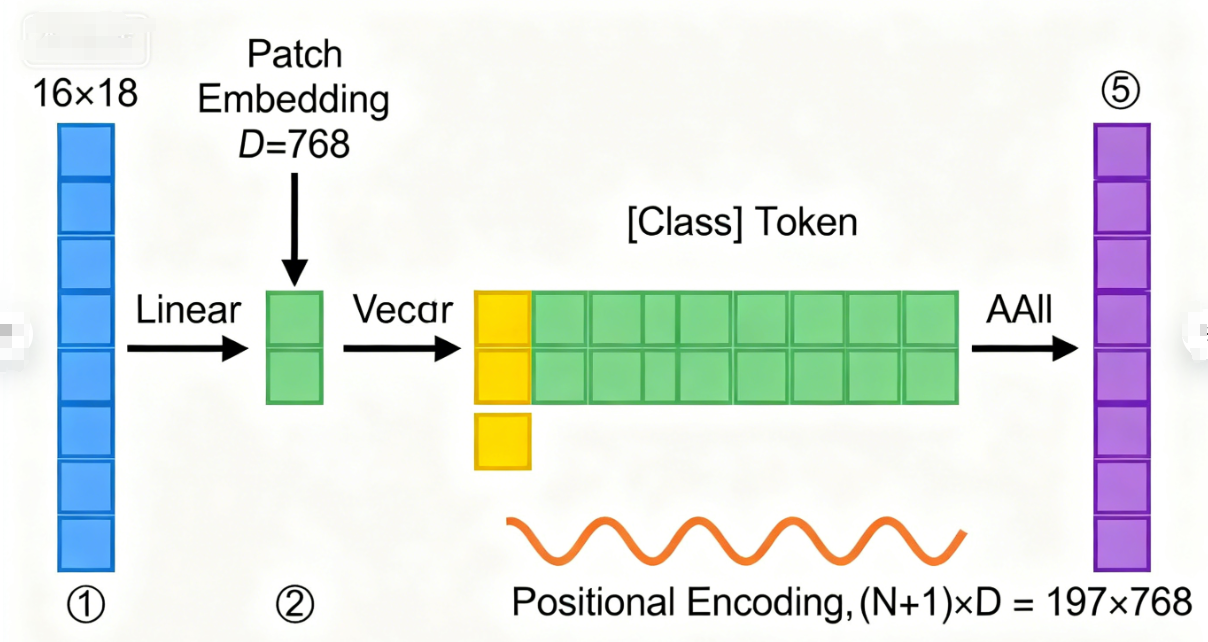
ViT首先摒弃了CNN的卷积下采样思路,采用类似NLP中“文本分词”的方式处理图像。具体而言,对于输入尺寸为H×W×C(高度×宽度×通道数)的图像,模型会将其均匀分割为N个大小相等的图像块(Patch),每个图像块的尺寸为P×P×C。例如,对于224×224×3的标准图像,若设置patch大小为16×16,则可分割为14×14=196个图像块。
![在这里插入图片描述]()
随后,每个图像块通过线性投影层转换为固定维度的向量(称为Patch Embedding),这一过程相当于NLP中对单词的嵌入编码。为了让模型区分不同图像块的空间位置,ViT会在Patch Embedding序列的开头添加一个可学习的“分类标记”(Class Token),同时为所有嵌入向量添加位置编码(Positional Encoding)——位置编码通常采用固定的正弦余弦编码或可学习的参数,用于保留图像块的空间位置信息。最终,得到的输入序列维度为(N+1)×D,其中D为嵌入向量维度,N为图像块数量。
![在这里插入图片描述]()
-
Transformer Encoder:全局特征提取核心
ViT的Encoder结构与NLP中的标准Transformer Encoder完全一致,由多个“多头自注意力(Multi-Head Self-Attention, MSA)+多层感知机(Multi-Layer Perceptron, MLP)”模块堆叠而成,每个模块前均加入层归一化(Layer Normalization),并采用残差连接(Residual Connection)稳定训练。
多头自注意力机制是Encoder的核心,它允许每个图像块的嵌入向量同时关注序列中所有其他图像块的信息,从而捕捉图像的全局依赖关系。与CNN的局部感受野不同,这种全局注意力机制让ViT能够直接建模远距离图像区域之间的关联,例如在识别“猫”时,可同时关联其头部、躯干和四肢的特征。MLP模块则由两个线性层和GELU激活函数组成,用于对自注意力输出的特征进行非线性变换和维度扩展。
论文中提供了三种典型的ViT配置:Base(12层Encoder,12个注意力头,D=768)、Large(24层Encoder,16个注意力头,D=1024)、Huge(32层Encoder,16个注意力头,D=1280),不同配置通过调整深度和宽度适应不同复杂度的任务。 -
分类头:任务输出层
经过Encoder处理后,序列中“分类标记”对应的输出向量已融合了所有图像块的全局特征,ViT将该向量输入一个简单的分类头(通常为“线性层+Softmax”结构),即可得到图像在各类别上的概率分布,完成分类任务。对于目标检测等复杂任务,只需将分类头替换为对应的任务头(如检测头、分割头),并调整输入处理方式即可。

三、ViT的应用现状:从图像识别到多领域落地
自ViT提出以来,凭借其优异的性能和灵活的架构,已在计算机视觉的多个核心领域实现规模化应用,相关技术指标被不断刷新。以下结合具体领域及数据,介绍其应用现状:
1. 图像分类:刷新权威数据集基准
图像分类是ViT的首发任务,也是其性能优势最突出的领域。除了前文提到的ViT在ImageNet等数据集的突破外,后续优化模型进一步刷新了基准:
-
ViT基础模型:在JFT-300M(3.03亿张图像)上预训练后,ImageNet-1K(1000类,130万张图像)准确率达88.55%,超越同期最优ResNet模型(87.7%)。
-
DeiT(Data-efficient Image Transformers):针对ViT对大规模数据的依赖问题优化,在仅使用ImageNet-1K数据训练的情况下,DeiT-B模型实现83.1%的准确率,接近同期ResNet-50的性能(82.1%),且推理速度提升10倍。
2. 目标检测与语义分割:突破空间建模瓶颈
通过结合特征金字塔等技术,ViT在目标检测和语义分割等需要精细空间信息的任务中实现突破,代表性模型包括Swin Transformer、ViT-Adapter等:
-
Swin Transformer:在COCO 2017目标检测数据集上,Swin-L模型实现63.1的mAP(平均精度),较同期最优CNN模型Faster R-CNN(ResNeXt-101)提升4.3个mAP;在语义分割任务中,Swin-L在ADE20K数据集上实现54.5的mIoU(平均交并比),提升3.2个mIoU。
![在这里插入图片描述]()
-
ViT-Adapter:在COCO数据集上,ViT-Base配置的ViT-Adapter实现51.1的mAP,较原始ViT提升18.4个mAP,证明ViT通过适配改造可有效适配检测任务。

四、ViT的后续演变:从优化到泛化的技术路径
ViT的成功并非终点,而是视觉Transformer发展的起点。针对原始ViT存在的“对大规模数据依赖强、空间建模精度不足、计算成本高”等问题,研究者们从多个方向进行优化,形成了丰富的技术分支,核心演变路径可概括为四类:
1. 引入归纳偏置:融合CNN优势
原始ViT缺少CNN固有的平移等变性等归纳偏置,导致小数据场景下泛化能力不足。为此,研究者通过引入空间结构信息优化模型:
-
Swin Transformer:提出“移位窗口自注意力”(Shifted Window Attention)机制,将图像划分为非重叠窗口,在窗口内计算自注意力以降低成本,同时通过窗口移位实现跨窗口信息交互,既保留CNN的局部建模优势,又兼顾全局依赖捕捉。我们将在下一篇博客里面详细讲解swin transformers的原理以及应用
-
ConvViT:在ViT的自注意力模块中插入轻量级卷积层,通过卷积捕捉局部特征,增强模型的平移等变性,在CIFAR-10数据集上,ConvViT较原始ViT准确率提升2.1个百分点。
2. 轻量化设计:适配边缘设备
原始ViT(尤其是Large/Huge配置)计算成本高,难以部署在移动端等边缘设备。轻量化模型通过简化结构、减少参数实现效率提升:
- MobileViT:将ViT的自注意力模块与MobileNet的深度可分离卷积结合,模型参数量仅为0.5M-2.3M,在ImageNet-1K上准确率达75.4%-81.3%,与MobileNetV3(参数量1.6M-5.4M)相比,参数量减少60%,准确率提升1.2-3.4个百分点。
3. 自监督学习:降低数据依赖
针对原始ViT依赖大规模标注数据的问题,自监督学习技术成为重要突破方向,通过无标注数据预训练提升模型泛化能力:
-
MAE(Masked Autoencoder):借鉴BERT的掩码策略,随机掩码80%的图像块,让模型通过剩余图像块重建原始图像,在ImageNet-1K上,MAE预训练的ViT-B模型微调后准确率达83.6%,较有监督预训练提升2.5个百分点。
-
SimMIM:通过掩码图像块并预测其像素值,在仅使用ImageNet-1K无标注数据预训练的情况下,ViT-B模型微调后准确率达83.8%,接近使用ImageNet-21K有标注数据的预训练效果。
4. 跨模态融合:打通视觉与语言
ViT的序列化处理方式使其天然适合跨模态任务,成为视觉-语言融合模型的核心组件:
- CLIP(Contrastive Language-Image Pre-training):采用ViT作为视觉编码器,与语言编码器共同训练,实现“图像-文本”的跨模态匹配,在零样本学习任务中,CLIP在ImageNet-1K上准确率达76.2%,超越传统有监督模型。
五、总结与展望
Vision Transformer的出现,是计算机视觉领域的一次范式革命。它打破了CNN长达十余年的垄断地位,证明了Transformer架构在视觉任务中的巨大潜力。从核心原理来看,ViT通过“图像分块-序列编码-全局注意力”的创新思路,解决了传统CNN全局特征建模能力不足的问题;从性能表现来看,在大规模数据支撑下,ViT及其衍生模型在图像分类、目标检测、医学影像等多个领域实现性能突破;从技术演变来看,轻量化、自监督、跨模态等方向的优化,不断拓展着ViT的应用边界。
然而,ViT的发展仍面临诸多挑战:一是小数据场景下的泛化能力仍需提升,如何在有限标注数据下发挥其优势是关键;二是计算成本问题,尽管轻量化模型取得进展,但复杂任务中ViT的推理速度仍落后于专用CNN;三是可解释性不足,自注意力机制的“黑箱”特性使其难以应用于医疗等对可解释性要求极高的领域。
未来,ViT的发展将呈现三大趋势:一是“CNN与Transformer的深度融合”,通过互补优势构建更高效的混合架构;二是“高效推理技术的突破”,结合量化、剪枝、神经架构搜索等技术降低部署成本;三是“多模态与通用人工智能的结合”,以ViT为核心构建统一的多模态模型,推动通用视觉智能的发展。可以预见,Vision Transformer不仅是当下的技术热点,更将成为未来计算机视觉发展的核心基石。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号