
【论文笔记-44~54】多语言实体链接
~2011
1. Cross-Language Entity Linking
文章核心观点:
本文介绍了一种新的跨语言实体链接任务,旨在将不同语言的文档中的命名实体与英文知识库中的实体描述进行匹配。作者提出了一种利用统计音译和跨语言信息检索的方法来解决这一任务,并在21种语言上进行了实验验证。实验结果显示,该方法平均性能可以达到英文单语言基线的94%,在个别语言上性能介于86%到99%之间。此外,文章还探讨了训练数据量对分类器性能的影响,以及利用相关语言进行训练的可行性。总体来说,本文为跨语言实体链接任务提供了有效的解决思路和实验验证。
方法:
- 候选识别:使用快速的名称匹配技术从知识库中识别出可能对应输入实体的知识库节点。具体技术包括:查询名称与候选名称的精确匹配、已知别名或昵称查找、查询与候选之间的字符4-gram数量、以及查询与候选之间IDF加权词的数量。
- 候选排名:使用监督机器学习对每个候选进行打分,并选择得分最高的一个作为输出。特征函数基于查询的内在属性、知识库候选的内在属性以及查询与候选之间的比较。
- 跨语言候选识别:先将查询名称翻译成英文,然后应用单语言的英文启发式方法。
- 上下文匹配:将跨语言上下文匹配视为跨语言信息检索问题,使用概率结构化查询方法。对维基百科文章进行索引,学习平行文本中的单词翻译概率,并实现概率结构化查询。
- 关系特征:将知识库中的事实作为“文档”,与查询文档计算文档相似度。
- 命名实体特征:对查询文档进行命名实体识别,并从输出中创建特征。
- 实体类型特征:检查知识库实体的类型是否与查询一致。
- 无匹配特征:一些特征可以指示是否存在匹配的知识库条目。
使用支持向量机进行排名学习。
方法补充:我们使用平行文档集合和众包来生成其他语言中的地面真实情况。我们工作所基于的一个基本见解是,如果我们使用平行文本集合的英文部分构建一个实体链接测试集,我们可以利用为英文特别开发现成的注释者和工具,然后将英文结果投影到其他语言上。因此,我们应用英文NER在文本中找到人名(Ratinov和Roth,2009),我们的英文实体链接系统识别候选实体ID,以及亚马逊Mechanical Turk上的英文注释者选择每个名称的正确kbid。最后,我们使用在伯克利词对齐器(Haghighi等人,2009)中实现的标准统计词对齐技术,将英文名称提及映射到非英文文档中的相应名称。
转移范例:标签
转移资源:翻译,词对齐
评估语言:en +(见下图)
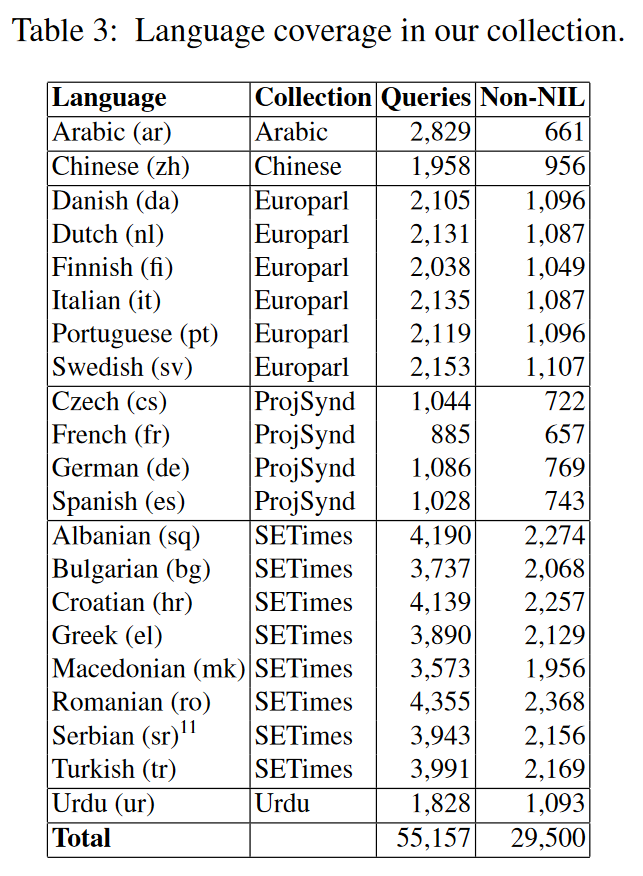
评估数据集:TAC-KBP 2010,self-generated
2012~2018
X. SemEval-2015 Task 13: Multilingual All-Words Sense Disambiguation and Entity Linking
在这篇论文中,我们描述了在SemEval 2015任务13:多语言词义消歧中的组织和所获得的结果。我们对结果的分析揭示了WSD(词义消歧)和EL(实体链接)任务整合中的有趣方面,例如语义签名、PPR(个性化页面排名)和用于名词和命名实体消歧的相似性度量的效用,以及用于动词、形容词和副词消歧的Lesk基础度量。另一个从这项任务中出现的有趣结果是,监督方法很难在多语言环境中泛化。实际上,参加这项任务的监督系统只考虑了英语。此外,这项任务再次确认了WordNet首感启发式方法是一个难以击败的硬基线。不幸的是,没有特定领域的消歧系统参加这项任务。然而,在生物医学领域,参与系统的表演质量比在其他考虑的领域中更高。
作为未来的研究方向,我们希望继续探究这一新联合任务的性质,并集中研究命名实体消歧和词义消歧之间的区别,特别关注非欧洲语言。
2. Cross-lingual wikification using multilingual embeddings
核心观点:这篇文章介绍了一种基于多语言嵌入的跨语言维基链接方法。作者提出了一种学习多语言词嵌入和维基百科标题嵌入的方法,并将外语文档中的提及与英文维基百科标题进行匹配。实验结果表明,这种方法在各种语言的维基百科数据集上的表现优于多个基准线,并在TAC 2015实体链接任务中取得了最先进的性能。文章的主要贡献包括提出了基于多语言嵌入的维基链接方法,能够应用于所有维基百科语言;以及证明了仅利用维基百科文档和语言链接就可以学习出高质量的多语言嵌入。总体来说,这项工作提供了一种简单高效的跨语言维基链接方法,并取得了非常出色的效果。
方法:
- 单语言嵌入学习:利用Skip-Gram模型为每种语言学习词和标题的嵌入。
- 多语言嵌入学习:利用CCA方法将不同语言的嵌入投影到同一空间,其中使用维基百科标题的跨语言链接作为词典。
- 候选生成:基于外语维基百科的锚文本和英语标题链接构建索引,为提及生成候选标题。
4.3 候选排名:使用多语言嵌入计算提及和候选标题之间的相似度特征,训练一个排名模型输出最终分数。
选择最佳候选:选择具有最高相关分数的候选标题作为答案,如果无适当候选,则输出NIL。 - 实验验证:在12种语言的维基百科数据集和TAC KBP2015实体链接数据集上验证该方法的有效性。
转移范例:参数
转移资源:multilingual word embeddings,Wikipedia
评估语言:
评估数据集:TAC KBP2015,self-generated
不足:难以处理目标语言的实体提及有相应英文页面但没有本页面的情况。
相关工作:略
待补充:CCA方法。
3. Neural cross-lingual entity linking
文章核心观点:
这篇文章介绍了一种神经跨语言实体链接模型,其主要贡献如下: 1. 该模型通过训练上下文和候选文档之间的细粒度相似性,能够有效区分具有相似文本描述的候选实体。 2. 模型结合了卷积网络、张量网络等技术来编码上下文信息,并计算多个相似性分数,进而提升链接性能。 3. 该模型实现了零样本学习,通过多语言词嵌入,使得在英语上训练的模型可以直接应用于其他语言,无需重新训练。 4. 在英语和跨语言(西班牙语、中文)的基准数据集上,该模型都取得了 state-of-the-art 的结果。 5. 实验结果表明,多视角上下文匹配和词汇分解与组合技术对实体链接性能提升效果显著。 6. 该模型在跨语言实体链接任务中,采用的多语言词嵌入优于其他两种方法。 综上所述,该文章提出的神经跨语言实体链接模型具有创新之处,并取得了出色的链接性能。
方法:
- 快速匹配搜索:利用构建的锚文本-标题索引,为每个查询提及快速获取候选链接。
- 上下文建模:基于查询提及的核心引文链,提取相关句子作为上下文,使用CNN编码句子上下文,同时使用LSTM建模提及周围的精细上下文。
- 特征抽象层:计算句子上下文和候选链接的标题、首段之间的相似度,以及精细上下文和候选链接的相似度,作为输入特征。
- 语义相似度和差异度:使用词汇分解组合(LDC)和跨视角上下文匹配(MPCM)进一步计算语义相似度和差异度特征。
- 模型训练:利用二分类训练数据集训练模型,目标是最小化损失函数。
- 解码:对每个查询提及运行快速匹配,生成候选链接,利用模型计算每个候选链接的分数,选取分数最高的作为输出。
- 跨语言应用:使用跨语言嵌入,使得在英文训练的模型可以应用于其他语言,实现零样本学习。
转移范例:参数
转移资源:multilingual word embeddings
评估语言:英语,西班牙,中文
评估数据集:TAC 2015
不足:
相关工作:
- 早期实体链接工作,如Bunescu和Pasca 2006、Mihalcea和Csomai 2007,主要侧重于计算源文档上下文和候选维基百科标题上下文之间的相似度。
- 近期实体链接研究更加注重全局消歧算法,如Globerson et al. 2016、Milne and Witten 2008、Cheng and Roth 2013、Sil and Yates 2013。这些方法捕捉给定文档中标题之间的连贯性,但计算成本更高。
Ratinov et al. 2011认为全局系统相对于局部系统只提供了较小的改进。Sun et al. 2015使用神经张量网络建模提及和上下文之间的语义交互,但在当前工作中表现不佳。Tsai and Roth 2016提出跨语言链接器,使用跨语言嵌入,但需要针对每种新语言重新训练模型。 - 最近的工作如Lin et al. 2017、Pan et al. 2017、Tan et al. 2017、Gupta et al. 2017,涉及不同的链接问题,与通用的文档实体链接有所不同。
- 词汇分解组合(LDC)和跨视角上下文匹配(MPCM)的近期工作。
- 跨语言实体链接评估始于2011年的TAC KBP EL Track,目标语言包括西班牙语和中文。大多数顶级系统先在外语环境中进行链接,然后通过维基百科的跨语言链接找到对应的英文标题。另一些系统先将查询文档翻译成英文,再进行英文链接。
2019~2020
4. Zero-shot neural transfer for cross-lingual entity linking
文章核心观点:
这篇文章主要研究了零样本跨语言实体链接方法,旨在将源语言中的实体提及映射到目标语言知识库中的对应条目。文章提出了一种基于枢纽语言的实体链接方法,该方法利用高资源“枢纽”语言的信息来训练字符级的神经网络实体链接模型,并将其零样本地迁移到低资源的源语言。在9种低资源语言的实验中,该方法相较于基准系统,将实体链接准确率平均提高了17%。此外,文章还研究了使用跨语言的语音表示,并在使用不同书写系统的语言之间进行迁移时,取得了平均准确率提高了36%的成果。这一研究为低资源语言之间的实体链接提供了有效的方法。
方法:
- 选择枢轴语言:选择一个与源低资源语言(LRL)密切相关的高资源语言(HRL),例如HRL与LRL属于同一语系。
- 训练相似度编码器:使用HRL与英语的双语词典,训练字符级的相似度编码器,该编码器能够将HRL和英语的实体映射到向量表示空间,并使两者相似。
- 零样本迁移:直接使用训练好的HRL编码器对源语言实体进行编码,并使用英语编码器对知识库条目进行编码,计算相似度,实现从HRL到LRL的零样本迁移。
- 使用枢轴语言:将源语言实体编码与HRL中的平行实体编码计算相似度,然后根据HRL与英语的词典获取英语知识库条目,实现从LRL到HRL再到英语的枢轴链接。
- 整合相似度计算:将直接迁移的相似度和枢轴链接的相似度进行比较,选择较大者作为最终相似度,从而获取链接结果。
- 多枢轴语言模型融合:训练多个枢轴语言的模型,并使用语言谱系距离对相似度进行加权,选择加权后得分最高的条目作为链接结果。
方法补充:词典是枢纽语言到英语之间的
转移范例:参数
转移资源:multilingual word embeddings,双语词典,Language features
评估语言:提格里尼亚语、老挝语、维吾尔语、泰卢固语、旁遮普语、爪哇语、马拉地语、孟加拉语和乌克兰语
评估数据集:self-generated, DARPA LORELEI pro-
gram(https://www.darpa.mil/program/
low-resource-languages-for-emergent-incidents)
相关工作:跨语言实体链接。自2011年以来,TAC-KBP实体链接共享任务就包含了中文/西班牙语到英语的实体链接(Ji, Grishman, 和 Dang 2011)。大约在同一时间,McNamee等人(2011)引入了跨语言实体链接作为一项新任务,并设计了一种基于维基百科语言链接的候选检索技术。最近,Pan等人(2017)使用逐字翻译,在282种语言对中进行了大规模的多语言实体链接工作,而Tsai和Roth(2018)开发了更好的名称翻译,以提高现有基于翻译的实体链接技术的性能。Sil等人(2017)提出的基于多语言词嵌入和维基百科链接的神经模型,在TAC2015数据集上取得了最先进的结果。
5. Entity linking in 100 languages
核心观点:这篇文章提出了一个全新的多语言实体链接形式,即将104种语言的实体提及与一个语言无关的知识库WikiData进行链接。文章通过训练一个双编码器模型,改进了特征表示和负样本挖掘,并添加了一个辅助的实体配对任务,实现了100多种语言和2000万个实体的实体检索。该模型在零样本和少样本检索方面具有挑战性,因此文章还提供了一个新的多语言数据集Mewsli-9。实验结果显示,该模型在多语言环境下实现了最先进的性能,优于之前的跨语言链接系统,并展现出较强的跨语言迁移能力
方法:
- 定义任务:将实体链接任务从跨语言链接重新定义为多语言链接,即链接文本中的实体提及到语言无关的知识库(WikiData)中的对应实体。
- 构建监督数据集:利用Wikipedia页面中的锚文本构建大规模多语言训练数据集。
设计模型架构:采用基于BERT的双编码器模型,包括上下文编码器(mention encoder)和实体编码器(entity encoder),用于编码文本和实体描述。 - 模型训练:采用负采样、多任务学习等策略训练双编码器模型。
- 模型评估:在跨语言实体链接数据集和多语言新闻数据集上评估模型性能,同时进行了模型选择和错误分析。
- 实验结果:实验结果显示,该方法在100多种语言和2000万实体上实现了有效的实体链接,同时优于传统跨语言链接方法。
- 提出观点:文章指出传统方法过于依赖英语知识库,而该方法可以更好地处理罕见实体和低资源语言,并强调了零样本和少样本评估的重要性。
转移范例:参数
转移资源:Pre-trained multilingual language models,Wikipedia
评估语言: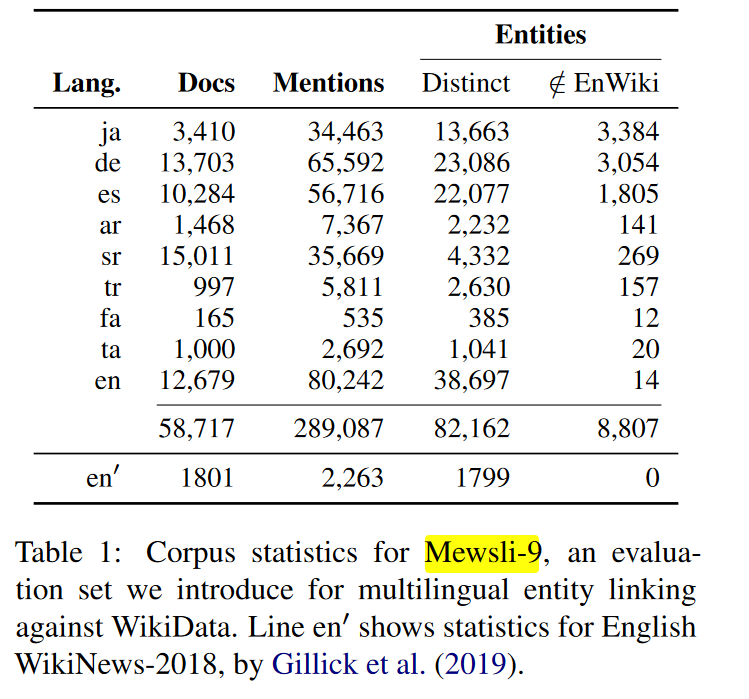
评估数据集:TR2016hard,英语WikiNews-2018,self-generated
不足:作者指出,模型目前主要使用无结构的文本信息,未来可以探索利用知识库中的关系信息。
X. Improving Candidate Generation for Low-resource Cross-lingual Entity Linking
核心观点:这篇文章主要研究了如何提高低资源跨语言实体链接中的候选实体生成方法。针对当前模型存在的问题,提出了三种改进方法:1) 在训练数据中加入提及-实体对,提供显式监督;2) 收集英语维基百科的实体别名,丰富实体表示;3) 使用基于字符n-gram的模型替代LSTM,提高对字符串的建模能力。实验结果表明,这三种方法在7种低资源语言的数据集上,平均提高了16.9%的top-30金候选召回率。整体而言,该文为低资源跨语言实体链接的候选生成方法提供了有效的改进。
方法:针对低资源跨语言实体链接的候选词生成任务,提出了以下三种改进方法:
- 引入提及-实体配对:在训练过程中引入提及-实体配对,提供明确的监督信息,以更好地学习实体提及与知识库条目之间的差异。
- 使用英文Wikidata的别名:收集英文Wikidata中的实体别名,并将其作为知识库条目的等价表示,以覆盖源语言中的各种实体提及变体。
- 基于字符n-gram的编码模型:用基于字符n-gram的编码模型CHARAGRAM替换LSTM,以更直接地学习字符串的表示,从而提高模型在低资源语言中的泛化能力。
2021~2022
6. Learning Domain-Specialised Representations for Cross-Lingual Biomedical Entity Linking
核心观点:本文介绍了一个跨语言的生物医学实体链接任务(XL-BEL),建立了涵盖10种语言的评估基准。研究评估了现有的单语言和多语言模型在XL-BEL任务上的表现,并提出了一个扩展了SAP技术的多语言模型。实验结果表明,多语言UMLS知识有助于提升模型在所有语言上的表现,同时结合通用领域翻译数据能进一步促进表现提升。此外,大规模模型在资源匮乏的语言中表现更好。最终,本文建立了一个新的跨语言生物医学实体表示评估基准,并提出了一种有效的跨语言知识转移方案,对多语言和特定领域表示学习具有启发意义。
方法:
- 语言不可知的SAP:利用UMLS中所有语言的同义词,而不是只使用英语同义词。具体步骤包括:
在一个mini-batch中,为每个名字构建三元组(锚点,正样本,负样本)。
只选择正样本比负样本距离锚点更远(至少一个margin λ)的三元组,这些是更具有信息量的“hard”三元组。
使用多相似性损失(Multi-Similarity Loss)从这些三元组中学习。 - SAP结合通用翻译数据:将通用领域的单词和短语翻译对也转换成SAP的输入格式。具体步骤包括:
为每对翻译(xp, xq)创建一个唯一的伪标签yxp,xq。
生成两个新的名称-标签实例(xp, yxp,xq)和(xq, yxp,xq)。
其他步骤与SAP相同。
补充:UMLS指的是统一医学语言系统(Unified Medical Language System)。这是一套大型的生物医学知识图谱
转移范例:参数
转移资源:Pre-trained multilingual language models,机器翻译(通用领域翻译来提高领域专业化表示模型的跨语言能力),词典(UMLS同义词集)
评估语言:英语、西班牙语、德语、芬兰语、俄语、土耳其语、韩语、中文、日语、泰语
评估数据集:self-generated
7. Towards zero-resource cross-lingual entity linking
核心观点:这篇文章研究了面向低资源跨语言实体链接的方法。主要内容包括: 1. 通过实验发现,现有跨语言实体链接系统的性能在低资源语言下大幅下降,其中候选生成系统的限制尤为显著。 2. 提出了三种改进候选生成和消歧的方法,包括结合两种不同的候选生成系统、设计语言无关的消歧特征、以及使用迭代神经网络进行特征组合。在四种低资源语言上的实验表明,这些方法可以将端到端的链接准确率提高6-23%。 3. 研究结果表明,面向低资源的跨语言实体链接需要更多关注候选生成方法,并提出了切实可行的方法来改进低资源下的跨语言实体链接性能。
转移范例:参数
转移资源:multilingual word embeddings,Wikipedia
评估语言:en,es,zh,ti,om,rw,si
评估数据集:TAC-KBP 2011,TAC-KBP2015,DARPA-LRL
8. Multilingual Autoregressive Entity Linking
文章核心观点:
这篇文章介绍了一个名为mGENRE的多语言实体链接系统。该系统使用序列到序列模型,以自回归的方式逐个生成实体名称的token,以完成实体链接任务。与之前的单语言实体链接模型GENRE相比,mGENRE考虑了知识库中每个实体的所有语言名称,并在预测时对所有语言进行概率积分,以充分利用源语言和目标名称之间的语言联系。实验结果显示,mGENRE在三个多语言实体链接数据集上取得了新的最优性能。特别值得一提的是,在零样本设置下,mGENRE可以显著提高50%以上的平均准确率。综合来看,mGENRE通过序列到序列生成方式,成功扩展了单语言实体链接模型到多语言环境,并取得了出色的性能。
方法:
- 输入文本:系统接收包含实体提及的文本作为输入。
- 序列到序列解码:采用序列到序列的解码器生成实体的名称,逐个标记、从左到右进行预测。
- 实体名称匹配:系统将预测出的实体名称与知识库中的所有实体名称进行匹配,每个实体在知识库中具有多个语言的名称。
- 语言选择:系统可以预测实体名称的语言,并与语言ID一起生成唯一标识符,也可以将语言作为隐变量,在预测时进行边缘化。
- 候选筛选:可选步骤,使用候选列表来限制解码空间的搜索范围。
- 输出预测:系统输出知识库中与输入文本中的实体提及对应的实体ID。
- 模型训练:使用Wikipedia超链接作为监督信号,采用标准的序列到序列训练目标。
- 解码策略:在预测时使用约束波束搜索进行高效搜索。
- 零样本设置:在零样本设置下,将语言作为隐变量,在预测时对所有语言进行边缘化,以提升性能。
转移范例:参数
转移资源:Pre-trained multilingual language models,Wikipedia,
评估语言:阿拉伯语、英语、波斯语、德语、日语、塞尔维亚语、西班牙语、泰米尔语、土耳其语、捷克语、法语、意大利语、波兰语、葡萄牙语、俄语和中文
评估数据集:Mewsli-9,TR2016hard,TAC-KBP2015,Wikinews-7
不足:作者指出,在训练中未专门针对罕见实体进行优化,而Botha等人(2020)的方法在该方面表现更佳。因此,作者计划未来加入类似的策略,以提高在罕见实体上的性能。
2023~2024
9. mReFinED: An Efficient End-to-End Multilingual Entity Linking System
文章核心观点:
这篇文章介绍了mReFinED,这是一个端到端的跨语言实体链接系统。文章的主要贡献包括: 1. 提出了mReFinED,这是首个从文本到链接的端到端的跨语言实体链接模型。它扩展了单语言的ReFinED模型到多语言,并提出了一个引导实体识别框架来解决端到端实体链接中的未标注实体提及问题。 2. mReFinED在端到端实体链接任务中表现优于当前最优的多语言实体链接系统,同时在推断速度上提高了44倍。 3. 引导实体识别框架显著改善了Wikipedia中的命名实体和普通名词实体的检测,与之前的多语言实体识别方法相比有较大提升。 4. mReFinED综合利用实体类型、描述和先验知识来提高实体消歧的准确性,并在多个跨语言实体链接数据集上验证了其效果。 总体来说,该文章提出了首个端到端的跨语言实体链接系统mReFinED,并通过引导学习框架解决了未标注数据的问题,使得mReFinED在性能和效率上均有显著提升。
方法:
- 引导实体提及检测:利用现有多语言实体识别模型对维基百科语料进行注释,以创建引导数据集。
- 多任务训练:利用引导数据集训练新的实体提及检测模型,同时进行实体类型预测、实体描述编码和实体消歧等任务。
- 端到端训练:在多任务训练中,mReFinED模型通过编码实体提及、编码实体描述、预测实体类型和计算实体消歧分数等步骤进行训练。
- 推理速度:mReFinED通过一次前向传播编码所有实体提及,从而实现了快速推理,速度比现有方法快44倍。
- 实验结果:在Mewsli-9和TR2016hard数据集上,mReFinED模型优于现有方法的端到端实体链接性能。
- 实体提及检测:mReFinED模型的实体提及检测部分优于现有多语言模型,可以缓解数据集中的未标记实体提及问题
转移范例:参数
转移资源:Pre-trained multilingual language models,Wikipedia,
评估语言:阿拉伯语、德语、英语、西班牙语、波斯语、法语、意大利语、日语、塞尔维亚语、泰卢固语和土耳其语
评估数据集:Mewsli-9,TR2016hard
优势:mReFinED的推理速度比mGENRE快44倍,这得益于mReFinED能够通过单次前向传播编码所有实体提及。
10. Controllable Contrastive Generation for Multilingual Biomedical Entity Linking
文章核心观点:
这篇文章介绍了一种名为Con2GEN的基于提示的受控对比生成方法,旨在解决多语言生物医学实体链接任务中的歧义问题。该框架利用序列到序列模型,将文本中的实体提及映射到多语言知识库中的标准概念。与仅基于表面形式的匹配方法不同,Con2GEN通过预定义的自然语言模板注入实体的多维信息,如名称、类型和语言,以实现更准确的跨语言实体消歧。同时,引入对比学习缓解了生成模型中的曝光偏差问题。在3个公开的多语言生物医学实体链接数据集上,Con2GEN模型相较于多个基准模型取得了明显的性能提升。实验结果表明,该方法在利用实体多维信息进行消歧方面是有效的。
方法:
- 编码输入文本:首先使用多层的Transformer编码器对输入的生物医学文本进行编码,生成隐藏向量表示。
- 解码生成:在解码阶段,采用基于提示的受控对比解码算法,结合预定义的自然语言模板,逐步生成目标实体。该算法能够根据模板限制解码空间,并注入多维信息。
- 训练阶段:在训练阶段,Con2GEN采用对比学习策略,通过构建正负样本对来优化模型,以提高其对困难负样本的判别能力。
- 解码算法:解码算法使用基于Trie树的搜索策略,在每个解码步骤中,只输出模板允许的合法token,以确保生成有效实体。
- 多维信息注入:在解码过程中,将实体的多维信息(如名称、类型、语言)注入模板,作为提示引导生成过程,以减少歧义。
转移范例:参数
转移资源:Pre-trained multilingual language models
评估语言:英语 (EN)
西班牙语 (ES)
德语 (DE)
芬兰语 (FI)
俄语 (RU)
土耳其语 (TR)
韩语 (KO)
中文 (ZH)
日语 (JA)
泰语 (TH)
法语 (FR)
荷兰语 (NL)
评估数据集:XL-BEL,Mantra GSC
11. TeaBERT: An Efficient Knowledge Infused Cross-Lingual Language Model for Mapping Chinese Medical Entities to the Unified Medical Language System
文章核心观点:
这篇文章提出了一种名为TeaBERT的新型跨语言预训练语言模型,用于将中文医疗实体映射到英文的统一医学语言系统(UMLS)。该模型利用了UMLS同义词和翻译知识,采用对比学习训练策略,有效地将中文和英文医疗实体对齐到嵌入空间。实验结果表明,TeaBERT在中文医疗实体映射任务上明显优于其他跨语言模型,并实现了新的最佳性能。该模型不需要针对特定任务进行微调,可直接进行跨语言映射,并有效降低了人力成本。此外,该研究还提出了基于主成分分析的嵌入向量降维优化方案,以降低模型对硬件的需求。综合来看,TeaBERT为跨语言医疗实体映射任务提供了高效、准确的新方法。
方法:
- 数据准备:从UMLS元词汇中收集所有英语医疗实体,并使用翻译引擎将其翻译成中文,形成翻译增强训练集。
- 模型训练:采用对比学习方法,利用UMLS同义词和翻译知识,在嵌入空间中对同义医疗实体进行拉近,对非同义实体进行推开,通过在线硬三元组采样技术动态选择困难的样本进行训练。
- 模型评估:在ICD10-CN、CHPO和RealWorld-v2数据集上评估TeaBERT的性能,结果表明其准确率显著优于其他跨语言模型。
- 推理优化:使用主成分分析白化降低嵌入向量维度,减少内存使用和推理时间,同时保持映射性能。
- 可视化分析:利用t-SNE可视化不同模型对UMLS医疗实体的编码,结果显示TeaBERT能更好地聚集同义跨语言医疗概念
转移范例:参数
转移资源:Pre-trained multilingual language models,机器翻译
评估语言:西班牙,英文
评估数据集:ICD10-CN,CHPO,self-generated

 浙公网安备 33010602011771号
浙公网安备 33010602011771号