【论文笔记-34~43】多语言共指消解
~2011
1. Multilingual Coreference Resolution
核心观点:这篇文章介绍了SWIZZLE系统,这是一个基于双语语料库训练的多语言共指解析系统。作者首先使用COCKTAIL系统在英语和罗马尼亚语的单语语料上独立进行共指解析,然后基于双语对齐语料库开发新的解析规则,以识别跨语言的共指关系。实验结果表明,SWIZZLE系统在英语和罗马尼亚语的共指解析准确率上都优于单语解析。文章还介绍了SWIZZLE所使用的数据驱动方法、多语言资源以及多语言共指解析的解决方案。总的来说,这篇文章提出了一个利用双语语料库提高共指解析性能的新方法。
方法:
- 首先,SWIZZLE系统独立地应用COCKTAIL中的启发式方法,对英语和罗马尼亚语文本进行共指解析,分别得到两份共指链表。
- 然后,SWIZZLE系统比较英语和罗马尼亚语文本中的共指表达及其先行词,以确定以下几种情况:
- 情况1:两个共指表达对应于彼此的翻译,即英语和罗马尼亚语文本中的共指表达都有翻译对应的先行词。在这种情况下,直接将两个共指表达视为彼此的翻译。
- 情况2:两个共指表达没有翻译对应的先行词,但都对应于现有的共指链。在这种情况下,会根据COCKTAIL中用于解析英语和罗马尼亚语文本的启发式方法的优先级来决定选择哪个先行词。
- 情况3:至少一个共指表达对应于一个新的共指链,即没有对应于现有链的共指表达。在这种情况下,会根据COCKTAIL中的启发式方法选择优先级最高的先行词。
- 通过比较和分析英语和罗马尼亚语文本中的共指表达及其先行词,SWIZZLE系统可以生成新的启发式方法,从而利用双语数据集进一步优化共指解析的性能。
- 最后,SWIZZLE系统将生成的新的启发式方法应用于英语和罗马尼亚语文本的共指解析中,从而实现多语言共指解析。
转移范例:标签,参数
转移资源:平行语料库,双语词典
评估语言:英语,罗马尼亚语
评估数据集:MUC-6,MUC-7
备注:罗马尼亚语数据通过人工标注得到
2012~2018
2. Translation-based projection for multilingual coreference resolution
核心观点:
本文探讨了在没有任何目标语言注释数据的情况下,如何进行跨语言指代消解。作者提出了一种基于机器翻译的投影方法,其步骤包括将目标语言文本机器翻译到源语言,利用源语言的指代消解工具生成指代注释,并将这些注释投影回目标语言。实验结果表明,即使没有任何目标语言注释数据,这种方法也可以获得与监督方法相当的性能。作者认为这种方法可以扩大指代消解技术在不同语言中的应用范围,为缓解注释数据瓶颈提供了一种可行的方案。
本文方法:
- 机器翻译:将目标语言文本机器翻译成源语言文本,如将西班牙语或意大利语文本翻译成英语。
- 源语言核心参照解析:在源语言文本上运行核心参照解析器,如使用Reconcile系统在英语文本上生成核心参照链。
- 投影回目标语言:通过词对齐,将源语言文本中的核心参照注释投影回目标语言文本,如将英语核心参照链投影回西班牙语或意大利语。
- 利用目标语言工具:在目标语言有工具可用时,先提取目标语言文本中的名词短语,然后投影到源语言文本,最后在源语言文本上运行核心参照解析器,再投影回目标语言。
- 训练目标语言解析器:使用投影得到的注释训练目标语言的核心参照解析器,如训练西班牙语或意大利语的核心参照解析器。
转移范例:标签
转移资源:机器翻译
评估语言:西班牙语,意大利语
评估数据集:SemEval-2010
3. Latent Trees for Coreference Resolution
核心观点:本文提出了一种新的机器学习方法,用于多语言无限制核心实体识别。该方法基于两种关键建模技术:潜在的核心实体树和基于熵的特征诱导。通过在候选实体对生成、基本特征设置和基于熵的特征诱导等步骤中应用这些技术,可以有效地解决多语言无限制核心实体识别问题。在实验评估中,该方法在包含阿拉伯语、中文和英语的CoNLL-2012共享任务数据集上取得了最佳表现,相比其他方法性能显著提高。该研究的主要贡献包括提出了一种基于潜在的核心实体树的方法,以及一种自动生成高预测力的特征的熵引导特征诱导方法。
方法:
提及检测:使用一组规则在给定的文档中检测候选提及,包括从依存句法树中提取名词短语、保留代词、保留实体、保留所有格标记等。
候选对生成:根据一组过滤规则,从提及列表中生成候选提及对。过滤规则包括距离规则、命名实体规则、头词匹配规则等。
基本特征设置:为每个候选对设置70个基本特征,这些特征包括词汇特征、句法特征、语义特征和位置特征。
熵引导特征诱导:利用决策树自动生成特征模板,然后从这些模板中生成新的特征,这些特征有助于模型学习非线性分类器。熵引导特征诱导方法自动生成特征模板,并从这些模板中生成新的特征。这些特征模板是通过在训练数据集上学习决策树得到的,决策树可以自动发现不同语言数据之间的共性和差异,因此生成的特征模板也可以跨语言使用。
结构化感知机训练:使用结构化感知机学习一个参数化的结构化分类器,用于预测隐含参照树。这包括学习约束参照树和预测非约束参照树。
预测隐含参照树:使用约束参照树作为当前迭代的真实参照树,使用非约束参照树作为预测参照树。预测过程使用Chu-Liu-Edmonds算法在修改后的权重图上进行。
模型更新:根据真实参照树和预测参照树的差异,更新结构化感知机的参数。
重复迭代:重复步骤5-7,直到收敛。
提取核心词义聚类:使用预测的隐含参照树提取文档中的核心词义聚类。
转移范例:特征
转移资源:Universal features(通用依存解析)
评估语言:阿拉伯语、中文和英语。
评估数据集:CoNLL-2012
4. Neural Cross-Lingual Coreference Resolution And Its Application To Entity Linking
核心观点:本文介绍了一种基于神经网络的跨语言共指消解模型。该模型使用多语言嵌入和语言无关特征,在英语训练集上训练,并在中国和西班牙测试集上获得了竞争性的结果。在实体链接任务中,该模型实现了优于2015年TAC竞赛最优系统的效果,且无需使用中文或西班牙文的标注数据。实验结果显示,该跨语言共指模型在内在评估和外在评估中表现良好,有助于提高跨语言实体链接任务的性能。
方法:1. 对于每个实体对(e1, e2),计算实体内部的词对(m1, m2),并提取其特征表示。这些特征包括字符串匹配、距离、指代类型等语言无关特征,以及平均词嵌入表示。 2. 训练模型...
转移范例:参数
转移资源:Universal features(字符串匹配、距离、缩写和发言人检测等),multilingual word embeddings
评估语言:英语、中文和西班牙语
评估数据集:TAC-2015
2019~2020
2021~2022
5. Multilingual Coreference Resolution with Harmonized Annotations
核心观点:
这篇文章研究了使用多语言训练数据集CorefUD进行跨语言转移学习的有效性。主要内容包括: 1. 介绍了CorefUD数据集,该数据集通过统一格式转换了11种语言的17个数据集,并采用了基于聚类表示共指的方法。 2. 使用了一个基于BERT的端到端共指解析模型,并进行了单语言和多语言实验,其中多语言实验分为斯拉夫语言和全部语言两类。 3. 实验结果显示,对于数据量较小的语言(如俄语和德语),多语言模型相比单语言模型有较大提升(约2-6% F1),表明共指标注的统一有利于跨语言迁移学习。 4. 文章还讨论了单例对实验结果的影响,并提出了未来工作的方向,包括对CorefUD中其他语言的实验和零样本跨语言迁移学习。 综上所述,文章研究了CorefUD数据集在多语言共指解析任务上的应用,并证明了多语言训练可以提升小数据量语言的性能。
转移范例:参数
转移资源:Parallel corpora,Pre-trained multilingual language models
评估语言:捷克语、俄语、波兰语、德语、西班牙语和加泰罗尼亚语
评估数据集:CorefUD
2023~2024
6. Ensemble Transfer Learning for Multilingual Coreference Resolution
核心观点:这篇文章提出了一个用于多语言共指消解的集成转移学习框架。主要贡献包括: 1. 提出了一个简单的无权平均方法,有效组合了多种转移学习技术。 2. 设计了一个新的基于维基百科的转移学习方法,可以利用维基百科的超链接启动共指消解模型。 3. 实验证明所提出的方法非常有效,为非英语语言的实体共指消解提供了有价值的见解。实验结果显示,最佳集成方法在三个数据集上均取得了新的 state-of-the-art 结果。 4. 该框架是通用的,可以与其它学习技术(如自蒸馏)配合使用。 综上所述,该文章提出了一个有效组合多种转移学习方法的集成框架,并设计了一个新的基于维基百科的转移学习技术,实验结果证明了所提出方法对非英语语言的实体共指消解非常有效。
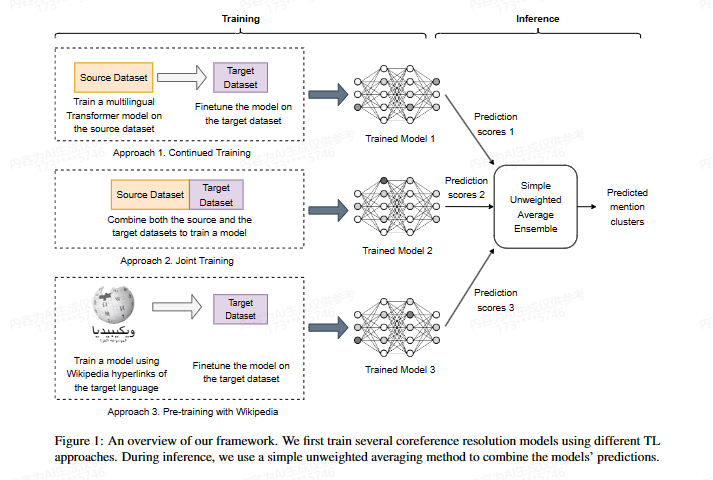
方法:
- 持续训练:在源语言数据集上预训练模型,然后在目标语言数据集上微调。
- 联合训练:在源语言和目标语言数据集的并集上训练模型。
- 基于维基百科的迁移学习方法:
- 利用维基百科页面中的锚文本及其指向的页面,构建远程监督数据集。
- 在远程监督数据集上预训练模型,然后在目标语言数据集上微调。
- 基于跨度的端到端共指解析方法
- 使用多语言Transformer编码器,为每个输入token形成上下文化表示。
- 计算每个候选span的表示,包括span的起始和结束token的表示,span内部表示的加权和,以及span大小特征。
- 对候选span进行提及评分,并保留评分高的span作为提及候选。
- 对每个提及候选,计算其与前序提及的链接分数,并预测其前指。
转移范例:参数
转移资源:Wikipedia,Pre-trained multilingual language models
评估语言:英语,阿拉伯语,荷兰语,西班牙语
评估数据集:OntoNotes,SemEval
7. McGill at CRAC 2023: Multilingual Generalization
of Entity-Ranking Coreference Resolution Models
核心观点:这篇文章介绍了一项关于多语言共指消解的CRAC 2023共享任务。文章描述了作者参与该任务的实体排序模型,该模型在17个数据集上进行了联合训练,覆盖了12种语言。作者探讨了数据预处理、预训练编码器以及数据混合等设计决策,并最终取得了该任务的第四名成绩,F1得分为65.43,比基线提高了8.47。研究结果表明,该模型在不同语言数据集上的表现存在较大差异,模型在资源较少的数据集上表现更好。
方法:
- 数据预处理
- 将数据集从CoNLL-U格式转换为标准化JSON格式
- 使用预训练编码器的分词器进行独立分词。
- 拼接所有token生成文档的token序列。
- 从原始数据中提取speaker信息,并在每个句子的开头添加speaker标签。
- 为每种语言定义一个latent vector,并拼接在实体-mention评分函数的输入中。
- 将零代词表示为下划线’_'.
- 预训练编码器
- 实验了XLM-RoBERTa和MT5两种预训练编码器。
- 联合训练
- 实验了均匀采样、按数据集大小比例采样和按最大阈值采样三种联合训练方法
- 在开发集上评估了这三种采样方法的效果,并发现按最大阈值采样效果最佳
转移范例:参数
转移资源:Pre-trained multilingual language models
评估语言:加泰罗尼亚语 (ca)
捷克语 (cs)
德语 (de)
英语 (en)
西班牙语 (es)
法语 (fr)
匈牙利语 (hu)
拉脱维亚语 (lt)
挪威语 (no)
波兰语 (pl)
俄语 (ru)
土耳其语 (tr)
评估数据集:CorefUD 1.1
8. ÚFAL CorPipe at CRAC 2023: Larger Context Improves Multilingual Coreference Resolution
核心观点:这篇文章是关于多语言共指解析任务CRAC 2023的获胜系统CorPipe。CorPipe首先进行提及检测,然后基于检测到的提及进行共指解析。它使用了一个大型预训练的语言模型mT5来获取上下文表示,并训练了模型来执行两个子任务。系统的主要改进包括使用了更大的输入和提及解码以支持集成。实验结果显示,CorPipe系统在CRAC 2023任务中取得了领先地位,并进行了广泛的ablation实验来评估各个组件的效果。该系统的源代码已公开。
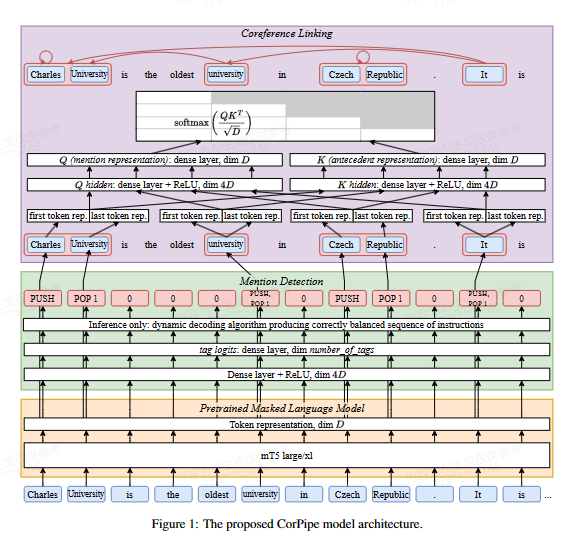
方法:
- 数据准备:
- 使用CorefUD 1.1数据集,包含17个不同语言的语料库,共12种语言。
- 进行多语言训练,利用所有可用的语料库。
- 预训练语言模型:
- 使用mT5预训练语言模型,这是目前最大的多语言预训练模型之一。
- mT5模型能够处理超过512个subword的输入,对于共指解析任务有益。
- 提及检测:
- 在预训练模型的基础上,添加一个分类头,用于预测每个token的标签。
- 标签使用一种基于栈的BIO扩展编码,包括PUSH、POP和POP(i)指令,用于打开和关闭提及。
- 在训练时使用标签平滑技术。
- 提及解码
- 在推理时,使用约束解码算法和Viterbi解码,以产生正确平衡的标签序列。
- 与训练时使用的CRF解码器相比,这种方法更适合集成多个模型。
- 共指链接
- 使用提及检测结果,基于最大前项原则在检索到的提及之间建立共指链接。
- 使用预训练模型的表示来编码每个提及,并进行相似度计算。
- 模型训练
- 使用Adafactor优化器和倾斜三角学习率调度进行模型训练。
- 在训练时限制上下文长度为512个subword,在推理时扩展到2560个subword。
- 进行多语言训练,利用不同的语料库混合比例。
- 集成
- 通过集成多个模型和检查点来进一步提高性能。
转移范例:参数
转移资源:Pre-trained multilingual language models
评估语言:加泰罗尼亚语 (ca)
捷克语 (cs)
德语 (de)
英语 (en)
西班牙语 (es)
法语 (fr)
匈牙利语 (hu)
拉脱维亚语 (lt)
挪威语 (no)
波兰语 (pl)
俄语 (ru)
土耳其语 (tr)
评估数据集:CorefUD 1.1
9. Parallel Data Helps Neural Entity Coreference Resolution
核心观点:这篇文章主要研究了如何利用平行数据来提升神经实体共指解析的性能。具体来说,文章提出了一种跨语言的共指解析模型,能够从未标注的平行数据中学习跨语言共指知识。该模型在OntoNotes 5.0英文数据集上进行了实验,结果表明,相比仅使用单语标注数据的模型,跨语言模型取得了稳定的提升,证实平行数据可以提供额外的共指知识,有助于共指解析。文章还进行了进一步分析,验证了跨语言共指模块能够学习有限的跨语言共指知识。总的来说,这项研究证明了利用平行数据提升神经共指解析是可行的,为未来相关研究提供了有益的参考。
动机:
- 标注数据瓶颈:神经共指模型主要依赖大量标注数据,但标注工作既费时又昂贵,因此需要探索新的数据利用方法。
- 平行数据的潜在价值:平行数据中包含潜在跨语言的共指知识,尚未被充分利用。
- 端到端神经共指模型:已有工作主要关注统计模型,尚无研究将平行数据应用到端到端的神经共指模型中。
方法:
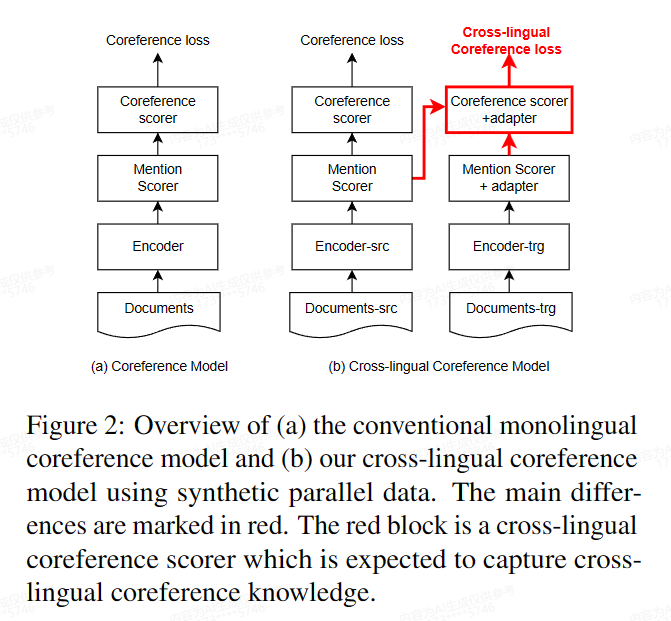
- 扩展神经共指模型neural-coref:在原有的源语言侧的文本编码器、提及评分器和共指评分器基础上,添加目标语言侧的文本编码器,并为目标语言侧的提及评分器和共指评分器添加适配器,以处理目标语言数据。
- 计算跨语言共指分数:在训练过程中,源语言侧和目标语言侧的提及之间计算共指分数,无监督学习跨语言共指知识。
- 训练模型:同时优化源语言侧的共指损失和跨语言共指损失,实现跨语言共指知识的传递。
- 推断:在推断时,仅使用源语言侧的模块,以利用单语标注数据训练和跨语言共指知识。
相关工作:
- 利用平行数据投影共指标注:
de Souza和Orasan (2011) 提出利用平行语料中的翻译对齐信息来投影共指标注。
Rahman和Ng (2012) 提出基于翻译的共指标注投影方法。
Martins (2015) 提出使用后验正则化方法进行共指解析器的跨语言转移。
Grishina和Stede (2015, 2017) 提出知识精简的跨语言共指链投影方法。 - 利用平行数据中的跨语言共指知识:
Hardmeier等人 (2013) 指出平行数据中包含跨语言的共指知识。
Lapshinova-Koltunski等人 (2018) 发布了一个英语-德语的平行语料库,其中包含共指标注。 - 利用平行数据改进神经共指识别:
本文是首个将平行数据中的跨语言共指知识应用到端到端的神经共指模型中的工作,通过添加目标语言侧的编码器和适配器,实现跨语言共指的建模,并在实验中取得了性能提升。
转移范例:参数
转移资源:机器翻译,Pre-trained multilingual language models
评估语言:英语,阿拉伯语、加泰罗尼亚语、中文、荷兰语、法语、德语、意大利语、俄语和西班牙语
评估数据集:OntoNotes 5.0
备注:
- 使用预训练的神经机器翻译模型,为英语数据生成9种语言的平行数据集
- 由于没有标注的跨语言核心指代数据,该模型在没有任何监督的情况下计算目标跨度和源跨度之间的核心指代得分。
X. Coreference Resolution through a seq2seq Transition-Based System
核心观点:这篇文章总结了一场关于多语言共指消解的共享任务,这是继去年后的第二届共享任务。今年的共享任务使用了最新版本的CorefUD数据集,包含17个数据集和12种语言。参与者需要构建可训练的系统来检测提及并基于同一性共指进行分组。评估指标采用了基于头部匹配的方法,共7个系统参加了比赛。结果显示,CorPipe系统表现最佳,在所有指标上都领先其他系统。文章还提供了不同系统和语言在各个数据集上的详细结果,以及进一步分析,为多语言共指消解领域提供了有价值的比较和进展。
10. Coreference Resolution through a seq2seq Transition-Based System
核心观点:这篇文章介绍了一种基于文本到文本(seq2seq)范式的共指消解系统,其主要内容和贡献包括: 1. 将共指消解建模为文本到文本问题,输入句子文本,输出一系列动作,这些动作将当前句子中的提及与上下文中的提及建立链接。 2. 提出了三种基于转移的文本到文本系统,包括Link-Append、Link-only和Mention-Link-Append,实验结果表明Link-Append效果最佳。 3. 在CoNLL-2012数据集上取得了state-of-the-art的结果,F1得分分别为英语83.3、阿拉伯语68.5、中文74.3。在SemEval-2010多语言数据集上也取得了较好的零样本和少样本迁移结果。 4. 分析表明,系统效果的关键在于文本到文本的设计选择,如直接预测链接而不是先预测提及,以及记录之前的共指决策状态。 5. 该系统可以很好地利用现代文本到文本预训练模型,实现高性能的共指消解,提供了新的思路和改进空间。
方法:
- 输入编码:将前i句的文本和已构建的核心引用簇作为输入,使用#分隔符,并使用|标记当前句子开始,**标记当前句子结束。
- 模型输出一系列动作,以分号分隔,后接终止符号SHIFT。每个动作包括链接当前句子中的提及到之前句子中的提及,或创建新的核心引用簇。
- 动作类型:
- 链接动作:将当前句子中的提及链接到之前句子中的提及。
- 附加动作:将当前句子中的提及附加到之前已创建的核心引用簇。
- 提及动作:创建新的单例核心引用簇。
- 训练示例生成:
- 按句子中提及的结束位置顺序处理提及。
- 如果提及在之前的文档中已有相同核心引用簇,则使用附加动作;否则使用链接动作。
- 如果提及是新的,则使用提及动作。
- 解码:
- 模型以贪婪方式逐个预测动作,直到预测到SHIFT。
- 每预测一个动作,更新当前输入,以便模型考虑之前的核心引用簇。
- 使用mT5作为基础模型,并通过微调在CoNLL-2012数据集上训练模型
转移范例:参数
转移资源:Pre-trained multilingual language models
评估语言:英语,阿拉伯语、中文。
加泰罗尼亚语 (Catalan)
荷兰语 (Dutch)
德语 (German)
意大利语 (Italian)
西班牙语 (Spanish)
评估数据集:CoNLL-2012,SemEval 2010

 浙公网安备 33010602011771号
浙公网安备 33010602011771号