
【论文笔记-21~33】多语言关系抽取
~2011
1. A cross-lingual annotation projection approach for relation detection
摘要:尽管在过去十年中对关系提取进行了广泛的研究,基于监督学习的统计系统仍然受限,因为它们需要大量的训练数据才能达到高性能。在本文中,我们开发了一种跨语言注释投影方法,该方法利用平行语料库来启动一个关系检测器,而不需要为资源匮乏的语言进行大量的注释工作。为了使我们的方法更加可靠,我们引入了三种简单的投影噪声减少方法。我们的方法的优点通过一个新的韩语关系检测任务得到了证明。
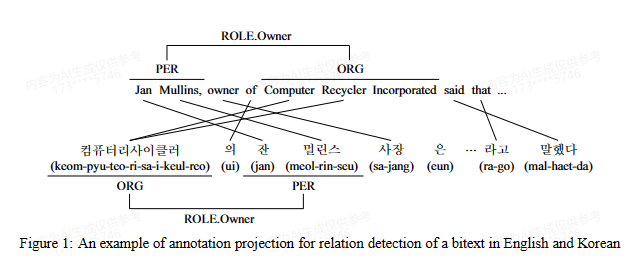
方法:爬虫得到平行语料库,对英语进行实体标注(斯坦福解析器),在ACE2003上训练和测试一个英语关系识别模型(基于树核的支持向量机),通过对齐将英语投影到韩语形成数据集(手动+投影),同样训练并测试韩语的一个基于树核的支持向量机模型
转移范例:标签
转移资源:平行语料库,词对齐(giza++),字典(作为补充)
评估语言:英语->韩语
评估数据集:ACE2003,self-generated
2012~2018
2. Multilingual open relation extraction using cross-lingual projection
摘要:开放域关系提取系统能够在不依赖任何底层模式的情况下识别句子中的关系和参数短语。然而,由于它们严重依赖于语言工具,如词性标注器和依存关系解析器,目前最先进的关系提取系统仅限于英语。我们提出了一种跨语言注释投影方法,用于语言无关的关系提取。我们在手动注释的测试集上评估了我们的方法,并在三种类型不同的语言上展示了结果。我们发布了从维基百科中提取的这十种语言的手动注释和提取出的关系。© 2015 计算语言学协会。
挑战:首先,由于词对齐是多对多的,每个英语词可能映射到多个源语言词,导致投影歧义;其次,词级映射可能导致源语言句子中的非连续短语,这在语义上难以解释。
方法:给定一个源语言句子,谷歌翻译API翻译成目标语言;然后使用OLLIE系统(Mausam et al., 2012)对英语句子进行开放域关系抽取;最后由于上述挑战,引入了一种新颖的算法,它结合了基于BLEU评分(2002年Papineni等)的短语相似度度量,以执行跨语言关系投影。给定一个源语言句子,其翻译以及词对齐,我们首先使用短语提取算法(Och和Ney,2004年)提取短语对P。在提取的每个短语对(phrs, phrt) ∈ P中,phrs和phrt分别是s和t中的连续词序列。接下来,我们根据提取的短语对确定arg1、rel和arg2的翻译。
对于每个英语短语p ∈ {arg1, rel, arg2},我们首先获取短语对(phrs, phrt) ∈ P,其中phrt相对于p的BLEU评分最高,且p ∩ phrt ̸= ∅,即两个短语至少有一个词重叠。这一条件是必要的,因为我们在使用平滑的BLEU评分时,即使没有词重叠,也可能获得非零的BLEU评分。如果P中有多个短语对对应相同的目标短语phrt,我们选择最短的源语言短语(phrs)。然而,如果目标短语p与P中的任何目标短语都没有词重叠,我们使用基于词对齐的投影方法。
转移范例:标签
转移资源:机器翻译,词对齐
评估语言:英语->Russian, French and Hindi
评估数据集:self-generated
3. Multilingual relation extraction using compositional universal schema
摘要:通用模式通过联合嵌入来自输入知识库的所有关系类型以及在原始文本中观察到的文本模式,构建实体和关系的知识点(KB)。在以前的大多数通用模式应用中,每个文本模式都被表示为单一嵌入,这阻止了对未见模式的泛化。最近的工作采用神经网络捕捉模式的组合语义,为所有可能的输入文本提供泛化。作为回应,本文引入了对通用模式关系提取的覆盖范围和灵活性的重大改进:对训练中未见实体的预测以及对没有注释的领域的多语言迁移学习。我们通过在英语和西班牙语TAC KBP基准上进行广泛的实验来评估我们的模型,使用没有手工编写模式或额外注释的方法,超越了TAC 2013插槽填充的顶级系统。我们还考虑了一个多语言设置,其中英语训练数据实体与种子KB重叠,但西班牙语文本不重叠。尽管没有西班牙语数据的注释,我们训练了一个准确的预测器,并通过在语言之间绑定词嵌入获得了额外的改进。此外,我们发现多语言训练提高了英语关系提取的准确性。因此,我们的方法适用于在多种语言和领域中构建广泛覆盖的自动化知识库。©2016 计算语言学协会。
方法:通过规则匹配抽取出西班牙句子中的实体对和文本模式,然后将文本模式编码为向量表示(LSTMs),并与知识库中的关系嵌入进行相似度计算,以预测句子中的关系(超过阈值则取知识库关系嵌入)。通过跨语言词嵌入绑定(Mikolov et al.2013)使语义相似的文本模式编码到更接近的向量空间中,从而提高关系抽取的准确性。
转移范例:标签
转移资源:机器翻译(得到的词典),多语言词嵌入
评估语言:英语->西班牙
评估数据集:TAC KBP 2013和2014,TAC KBP 2012
4. Neural Relation Extraction with Multi-lingual Attention
摘要:关系提取已被广泛用于从普通文本中发现未知的关系事实。大多数现有方法专注于利用单语言数据进行关系提取,忽略了来自各种语言文本的大量信息。为了解决这个问题,我们引入了一个多语言神经关系提取框架,该框架采用单语言注意力机制来利用单语言文本中的信息,并进一步提出跨语言注意力机制来考虑跨语言文本之间的信息一致性和互补性。在真实世界数据集上的实验结果表明,我们的模型可以利用多语言文本,并与基线相比在关系提取上持续取得显著的改进。本文的源代码可以从 https://github.com/thunlp/MNRE 获得。© 2017 计算语言学协会。
不同:上面2,3论文学习一个新的语言预测模型在现有知识库上,通过利用跨语言实体的统一表示学习。与这些工作不同,我们的框架旨在共同建模多种语言文本,以提高远程监督下的关系提取。
方法:使用CNN对句子进行编码后,应用单语言注意力和跨语言注意力来捕捉那些具有准确关系模式的信息性句子,使得关系抽取模型可以同时利用每种语言内部以及不同语言之间的信息。
转移范例:参数转移
转移资源:Wikidata,百度百科,维基百科(将中文百度百科、英文维基百科与Wikidata对齐生成)
评估语言:英语,中文
评估数据集:self-generated
2019~2020
5. Cross-lingual Structure Transfer for Relation and Event Extraction
作者:Ananya Subburathinam, Di Lu, Heng Ji, Jonathan May, Shih-Fu Chang, Avirup Sil, Clare Voss
摘要:
从低资源和低标注语言源中识别复杂的语义结构,如实体关系和事件,本身就是一项具有挑战性的信息提取任务。我们研究了跨语言结构迁移技术对这些任务的适用性。我们利用了与关系和事件相关的语言通用特征,包括符号(包括词性标注和依存路径)和分布式(包括类型表示和上下文化表示)信息。通过将所有实体提及、事件触发器和上下文表示为这个复杂且结构化的多语言共享空间,并使用图卷积网络,我们可以从源语言注释中训练关系或事件提取器,并将其应用于目标语言。
在英、中、阿三种语言之间进行广泛的跨语言关系和事件迁移实验表明,我们的方法在两个任务上都取得了与目前最先进的监督模型相媲美的性能,这些监督模型是从多达3000个手工注释的提及中训练的:关系提取达到62.6%的F分数,事件参数角色标注达到63.1%的F分数。从英语迁移到中文的事件参数角色标注模型与从中文训练的模型取得了相似的性能。
因此,我们发现语言通用符号表示和分布式表示在跨语言结构迁移中是互补的。
方法:
1.构建语言通用表示:将任何语言的每个句子转换成基于通用依存解析的语言通用树结构。
2.对于树结构中的每个节点,从多语言词嵌入、语言通用词性标注嵌入、依存角色嵌入和实体类型嵌入的拼接中创建一个表示,以便所有句子,无论其语言,都在一个共享的语义空间中表示
3.采用GCN通过利用从依存解析树中获取的邻居信息来生成上下文化的词表示
4.使用这个共享的语义空间,用高资源语言的训练数据训练关系和事件参数提取器,并将结果提取器应用于没有任何关系或事件参数标注的低资源语言文本
转移范例:参数转移
转移资源:Universal features(通用依存解析),multilingual word embeddings
评估语言:中,英,阿
评估数据集:ACE 2005
相关工作:
跨语言结构迁移:
利用双语词典进行跨语言迁移,如Hsi等人(2016)。
利用平行数据进行跨语言迁移,如Chen和Ji(2009)。
利用机器翻译进行跨语言迁移,如Faruqui和Kumar(2015)。
利用多语言词嵌入进行跨语言迁移,如Mikolov等人(2013)、Rothe等人(2016)。
语义角色标注跨语言迁移:
利用词对齐进行跨语言迁移,如Van der Plas等人(2011)。
利用双语词典进行跨语言迁移,如Kozhevnikov和Titov(2013)。
利用通用依存进行跨语言迁移,如Prazák和Konopík(2017)。
利用多语言词嵌入进行跨语言迁移,如Mulcaire等人(2018)。
6. An Empirical Study of Pre-trained Transformers for Arabic Information Extraction
摘要:多语言预训练的Transformer,如mBERT(Devlin et al.,2019)和XLM-RoBERTa(Conneau et al.,2020a),已被证明可以有效地实现跨语言零样本迁移学习。然而,它们在阿拉伯语信息抽取(IE)任务上的表现还不是很清楚。本文我们预训练了一个定制的双语BERT,称为GigaBERT,专门为阿拉伯语自然语言处理和英-阿零样本迁移学习设计。我们研究了GigaBERT在命名实体识别、词性标注、论元角色标注和关系抽取这四个IE任务上的零样本迁移学习效果。我们的最佳模型在监督学习和零样本迁移设置下都显著优于mBERT、XLM-RoBERTa和AraBERT(Antoun et al.,2020)。我们已将我们的预训练模型公开在https://github.com/lanwuwei/GigaBERT。
动机:改进跨语言零样本迁移学习的效果,特别是在阿拉伯语信息抽取任务中。
方法:本文提出了一种名为GigaBERT的定制双语BERT模型。
- 使用Gigaword语料库、维基百科和Oscar语料库进行预训练。
- 构建了一个包含50k词汇的统一词汇表,区分英文字母大小写,阿语不区分。
- 在英阿平行数据上继续预训练,生成代码混合数据,以增强跨语言迁移能力。
转移范例:参数转移
转移资源:Pre-trained multilingual language models,双语词典
评估语言:英,阿
评估数据集:ACE 2005
相关工作:略
2021~2022
7. GATE: Graph Attention Transformer Encoder for Cross-lingual Relation and Event Extraction
摘要:在跨语言关系和事件提取任务中,本文提出了基于图注意力Transformer编码器(GATE)的方法。GATE利用自注意力机制,明确融合结构信息,学习不同语法距离的词之间的关系。在ACE05数据集上进行了实验,涉及三种类型不同的语言:英语、中文和阿拉伯语。结果显示,GATE大幅超过了最近提出的三个方法。通过细致的分析,我们发现GATE产生的鲁棒表示有利于跨语言迁移。
动机:本文提出GATE方法的动机在于,目前跨语言关系和事件提取的研究主要依赖于图卷积网络(GCNs)结合通用依存句法分析来学习语言无关的句子表示,以便实现跨语言的迁移。然而,GCNs在建模长距离依赖或依存树中不直接连接的词时存在困难。为了解决这一问题,本文提出了利用自注意力机制,通过明确融合结构信息来学习不同语法距离的词之间的关系。因此,本文的动机在于提出一种更好的方法来学习跨语言的关系和事件提取任务,特别是在处理长距离依赖或非直接连接的词方面,相比GCNs方法具有优势。
方法:
- 输入表示。利用Universal Dependency解析将句子转换为通用树结构,使用多语言预训练模型提取词表示(只提供特征,不微调),并拼接通用特征,包括词性标签、依存关系标签和实体类型。
- 图注意力机制:基于依存树计算词之间的语法距离,并根据距离阈值δ来控制词之间的注意力权重,更近的词获得更高的权重,更远的词获得更低的权重。
- 多头注意力结构:允许不同头之间的信息传播,学习不同提及类型与目标标签之间的关系。
转移范例:参数转移
转移资源:Universal features(通用依存解析),multilingual word embeddings,Pre-trained multilingual language models
评估语言:英,中,阿
评估数据集:ACE 2005
相关工作:略
8. Crosslingual Transfer Learning for Relation and Event Extraction via Word Category and Class Alignments
摘要:
本文提出了一个用于关系和事件提取(REE)任务的新型跨语言表示学习对齐方法。先前的方法在跨语言REE中存在单语言偏差问题,因为仅使用源语言数据进行模型训练。为了克服这个问题,一种方法是在目标语言中使用未标注的数据来辅助跨语言表示的对齐,例如通过欺骗一个语言判别器。然而,由于这种方法没有考虑到类别信息,目标语言的某个类别示例可能会错误地对齐到源语言的不同类别示例。
为了解决这个问题,我们提出了一种新颖的跨语言对齐方法,利用REE任务的类别信息进行表示学习。具体来说,我们为REE任务中的每个类别学习两个版本的表示向量,一个基于源语言示例,另一个基于目标语言示例。随后,将对应类别的表示向量进行对齐,以实现跨语言的类别感知对齐。此外,我们还提出进一步对齐源语言和目标语言示例中基于上下文化的表示向量,用于语言通用的词类别(例如词性标注和依存关系)。因此,我们提出了一个新颖的过滤机制,通过对抗学习来促进基于上下文化的表示向量学习词类别表示。我们在关系提取、事件检测和事件参数提取任务上进行了广泛的跨语言实验,涉及英语、中文和阿拉伯语。结果表明,所提出的方法显著优于当前最先进的方法,并在这些设置中取得了显著的性能提升。
方法:
- 计算类别表示向量:对于每个类别,分别计算源语言和目标语言的类别表示向量。源语言的表示向量通过对标注数据进行平均得到,而目标语言的表示向量则通过对未标注数据进行加权平均得到。
- 对齐类别表示向量:将源语言和目标语言的类别表示向量进行对齐,以使对应类别的表示向量更加接近,实现类别感知的对齐。(利用通用词性(UPOS)和依存关系作为语言无关的知识,mBERT负责提供情景化表示以促进对齐)
- 上下文信息过滤:采用对抗训练的方式,过滤词类别表示中的上下文信息,使其更纯粹地表示词类别信息。
转移范例:参数转移
转移资源:multilingual word embeddings,Universal features(通用依存解析),Pre-trained multilingual language models
评估语言:英,中,阿
评估数据集:ACE 2005
相关工作:
跨语言学习:
Joulin等人 (2018) 提出了基于检索的双语词映射学习。
Ni和Florian (2019) 提出了基于双语词嵌入映射的跨语言关系提取。
Subburathinam等人 (2019) 提出了跨语言结构迁移进行关系和事件提取。
Ahmad等人 (2021) 提出了基于图注意力机制的跨语言关系和事件提取。
M’hamdi等人 (2019) 提出了基于BERT-CRF的跨语言事件检测。
Liu等人 (2019) 提出了跨语言事件检测的神经方法。
语言表示对齐:
Chen等人 (2019) 提出了多源跨语言模型迁移。
Huang等人 (2019) 提出了跨语言多级对抗迁移。
Keung等人 (2019) 提出了基于上下文嵌入的零资源跨语言分类。
Lange等人 (2020) 提出了多语言模型对齐的对抗方法。
Cao等人 (2020) 提出了联合学习对齐和摘要的方法。
9. PARE: A Simple and Strong Baseline for Monolingual and Multilingual Distantly Supervised Relation Extraction
摘要:神经模型进行远监督关系提取(DS-RE)时,通常会独立地编码每个句子中的实体对,然后再进行实体对级别的聚合关系预测。由于在编码阶段,这些方法不允许从包中其他句子传递信息,我们认为它们没有充分利用可用的包数据。为了解决这个问题,我们探索了一个简单的基准方法(PARE),其中将包中所有句子连接成一个段落,并使用BERT进行联合编码。我们利用候选关系作为查询,使用注意力机制聚合上下文嵌入的token,以对整个段落进行总结,从而预测候选关系。我们发现,我们的简单基准解决方案在单语言和多语言DS-RE数据集上都优于现有的state-of-the-art DS-RE模型,实现了高达5个百分点的AUC增益。
动机:略
方法:
- 段落构建:与PARE相同,将提及给定实体对(e1, e2)的所有句子t∈B(e1, e2)拼接成一个段落P(e1, e2),包括来自不同语言的句子。
- 段落编码:使用多语言BERT (mBERT)对段落P(e1, e2)进行编码,生成每个词的上下文嵌入表示z。
- 段落摘要:
- 为每个关系r维护一个可训练的查询向量r。
- 计算查询向量r与段落中每个词的注意力权重α。
- 根据注意力权重聚合词的上下文嵌入,得到关系r的段落摘要表示z(e1, r, e2)。
- 关系预测:
- 将关系r的段落摘要表示z(e1, r, e2)输入到MLP(多层感知机)中,预测三元组(e1, r, e2)的置信度p。
- 在预测阶段,如果p大于阈值(0.5),则认为(e1, r, e2)成立。
转移范例:参数转移
转移资源:Pre-trained multilingual language models
评估语言:英文、西班牙文、德文和法文
评估数据集:DiS-ReX
10. Cross-lingual transfer learning for relation extraction using Universal Dependencies
摘要:这篇论文主要关注跨语言关系抽取任务,旨在识别文本中实体之间的语义关系。该任务的目标是利用高资源语言的注释数据来训练低资源语言的分类器。相关方法通常需要平行数据或机器翻译器将源语言的数据投射到目标语言。然而,对于低资源语言来说,平行数据和机器翻译器的可用性和质量是一个巨大挑战。本文提出了一种新颖的迁移学习方法,其关键思想是利用树形数据表示,这对于分类语义关系非常有信息量,并且在不同语言之间是共享的。所有训练和测试数据都采用这种表示。作者提出使用通用依存(UD)解析,这是一种对句法结构进行语言无关形式化的方法。在UD解析树上配备多语言词嵌入为跨语言关系抽取任务提供了理想的表示。作者提出了两个深度网络来使用这种表示。第一个网络利用UD树的最短依存路径,而第二个网络使用基于UD的位置嵌入。实验使用SemEval 2010任务的8训练数据,法文和波斯文作为测试语言。结果显示,法文和波斯文测试数据的F1得分分别为63.9%和56.2%,分别比基线高14.4%和17.9%。这项工作可以被视为对跨语言任务的进一步研究的一个简单但强大的基线。
方法:
- 使用通用依存(UD)解析树和双语词嵌入来表示数据,以获得跨语言的共享表示。
- 网络结构1 - CNN+U-SDP: 提取UD解析树中最短依存路径(U-SDP)上的上下文词,将U-SDP以及两个实体对应的左右上下文词分别输入到卷积层,并拼接各层的输出作为分类特征。
- 网络结构2 - CNN+U-DIS: 计算句子中每个词相对于两个实体的依存距离(U-DIS),并将其编码为嵌入向量,与词嵌入一起作为网络的第一层输入。同时将词的通用词性标签和依存类型也编码为嵌入向量输入网络。
转移范例:参数转移
转移资源:multilingual word embeddings,Universal features(通用依存解析)
评估语言:英语、法语、阿拉伯语和波斯语
评估数据集:SemEval 2010、ACE 2004
相关工作:
跨语言关系抽取方法:
Faruqui和Kumar(2015):使用机器翻译将数据从源语言翻译到目标语言,并投影源语言的实体和关系注释。
Kim等人(2014):利用源语言和目标语言的平行语料,将源语言的实体注释投影到目标语言,并用目标语言训练关系抽取系统。
Zou等人(2018):使用生成对抗网络(GAN)将源语言的特征表示转移到目标语言。
基于依存路径的方法:
Cai等人(2016):使用依存路径的CNN和双向LSTM进行关系分类。
Xu等人(2015):学习依存路径的鲁棒表示。
其他相关方法:
Min等人(2017):提出了一种用于跨语言关系抽取的双语转移学习算法。
Taghizadeh等人(2018):使用通用特征空间展示不同语言的数据,并利用SVM进行跨语言关系抽取。
基于通用依存关系的方法:
Taghizadeh和Faili(2021):提出了一种基于通用依存关系的转移学习方法。
2023~2024
11. GranCATs: Cross-Lingual Enhancement through Granularity-Specific Contrastive Adapters
摘要:多语言语言模型(MLLMs)在各种跨语言下游任务中取得了显著的成功,为不同语言之间的知识传递提供了便利。然而,现有的MLLMs在捕获不同语言家族之间的句级和段级对齐方面存在困难。为了解决这个问题,我们提出了GranCATs,即针对不同粒度的对比适配器。我们收集了一个新的数据集,提供了每个样本在短语级、句级和段级三个不同粒度的观察,并采用对比学习作为预训练任务来训练GranCATs。我们的目标是增强MLLMs在更广泛的跨语言任务中的适应能力,使其能够更好地捕捉不同粒度下的全局信息。广泛的实验表明,在实体对齐、关系提取、句子分类和检索以及问答等不同语言任务中,带有GranCATs的MLLMs都取得了显著的性能提升。这些结果验证了我们的GranCATs在增强不同文本粒度下的跨语言对齐方面的有效性,并将这种知识有效地传递给下游任务。
动机:现有的多语言语言模型(MLLMs)虽然取得了显著的成功,但其在跨语言下游任务中的转移效果并非在所有语言间都一致,尤其是在不同语言家族之间。作者发现现有的MLLMs在捕获不同语言家族之间的句级和段级对齐方面存在困难。
方法:
- 构建数据集:收集一个英对平行语料库,其中每个样本都包含短语级、句级和段级三个不同粒度的文本,涵盖29种语言,覆盖了15个语系。
- 构建GranCATs结构:包括短语级对比适配器(CATs-PH)、句级对比适配器(CATs-ST)和段级对比适配器(CATs-PG)。
- 预训练过程:
- 短语级:使用Wikipedia中的对齐实体作为短语级输入,在英对平行语料库上训练CATs-PH。
- 句级:使用Wikipedia中的摘要句子作为句级输入,在英对平行语料库上训练CATs-ST。
- 段级:使用Wikipedia中的实体描述作为段级输入,在英对平行语料库上训练CATs-PG。
- 下游任务微调:将GranCATs与MLLM主干模型一起在特定下游任务上进行微调。
转移范例:参数转移
转移资源:Wikipedia,Pre-trained multilingual language models
评估语言:English,French,German,Spanish,Turkish
评估数据集:RELX
12. Prompt-Learning for Cross-Lingual Relation Extraction
摘要:
跨语言关系提取(XRE)是自然语言处理中的一项关键任务,其目标是从一种语言的关系提取模型中实现零样本迁移到另一种语言。尽管近年来基于提示学习的知识迁移在多语言预训练语言模型(PLM)到各种下游任务中取得了显著进展,但将多语言PLM与提示有效结合用于改进XRE的研究仍然有限。在本文中,我们基于Prompt-Tuning提出了一种新颖的XRE算法,称为Prompt-XRE。为了评估其有效性,我们设计并实现了几种提示模板,包括硬提示、软提示和混合提示,并在广泛使用的多语言PLM上进行实证测试,特别是mBART。在低资源ACE05基准测试中,我们在多种语言上进行的大量实验表明,我们的Prompt-XRE算法显著优于仅使用多语言PLM以及其他现有模型,在XRE任务上取得了最先进的性能。为了进一步展示Prompt-XRE在大规模数据集上的泛化能力,我们构建并发布了一个新的XRE数据集-WMT17-EnZh XRE,其中包含从WMT 2017平行语料库中提取的90万英中平行句子对。在WMT17-EnZh XRE上的实验也证明了Prompt-XRE与其他竞争基准相比的有效性。我们的代码和新构建的数据集可自由获取。
动机:尽管基于提示学习的知识迁移在多语言预训练语言模型到各种下游任务中取得了进展,但将多语言PLM与提示有效结合用于改进跨语言关系提取的研究仍然有限。
方法:
- 关系提取任务定义:定义关系提取任务为识别文本中实体提及对之间的关系类型,将文本和关系标签组合作为输入和输出。
- 利用Seq2Seq网络:使用Seq2Seq网络结构进行关系提取,编码器编码输入句子,解码器生成关系类型。
- 提示调优策略:设计提示调优策略,将关系提取任务转化为预训练语言模型的更一致形式,以实现零样本迁移。
- 提示模板设计:设计硬提示、软提示和硬-软混合提示模板,在编码器和解码器输入中添加提示信息。硬提示使用自然语言,软提示使用特殊标记,硬-软提示结合使用。
- 硬提示(Hard Prompt):手动设计的提示,使用自然语言。
- 软提示(Soft Prompt):使用人工标记作为模板,而不是离散的标记。
- 硬-软提示(Hard-Soft Prompt):结合自然语言和手动设计的非离散标记的提示。
其它:
关系提取的微调:给定一个用于RE的预训练语言模型(PLM) M。早期的微调方法首先将实例x = {e1, e2, e3, es, ...., eo, ....., en}转换为PLM输入序列,例如“ x ”。模型M的输出隐藏向量将输入序列编码为venc = {v, v1, v2, vs, ...., vo, ....., v}。然后输入venc和“ x ”到模型M的解码器中以获得vdec。下面的公式表示关系类型y的条件概率:p(y|x) = Softmax(Wvdec)。
基于提示的微调:提示调整被提出作为缩小上游活动和预训练之间差距的一种方式。最困难的任务是创建一个适当的标签V和模板t(·),它们共同被称为提示P。模板将每个x的出现映射到一个输入提示,xprompt = T(x)。模板t(·)特别指的是在哪里以及添加多少额外的词。V表示模型M的词汇表中的一组标记词,其中M P : Υ → V是一个将标签词V链接到任务标签的注入映射。在传统方法中,除了保留xprompt的原始标签外,一个或多个[MASK]被放置在M的边界上以填充标记词。然而,我们的方法使用[MASK]作为一个标记来提示模型M,并用于将模型输入分割为实体或句子。由于M可以预测正确的标签,我们能够在掩蔽位置的V的概率分布中形式化p(y|x),即,p(y|x)=p(M P (y)|xprompt)。图1展示了我们基于mBART模型的提示调整PLMs用于分类。
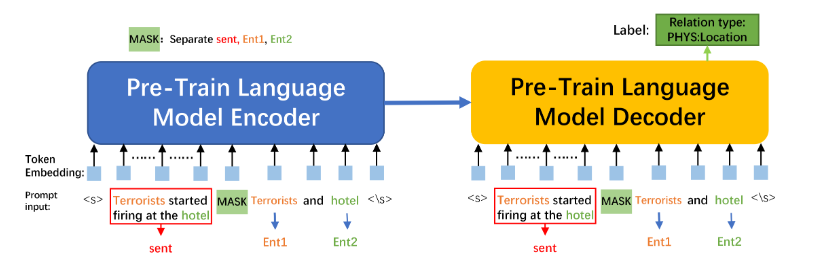
转移范例:参数转移
转移资源:Pre-trained multilingual language models
评估语言:英语、中文和阿拉伯语
评估数据集:ACE05,self-generated
13. Constructing Code-mixed Universal Dependency Forest for Unbiased Cross-lingual Relation Extraction
摘要:
最近的跨语言关系提取(XRE)研究积极利用了跨语言一致的通用依存(UD)结构特征。然而,由于语言之间的不可避免的差异,这种方法可能会受到偏倚的转移,如目标语言偏见或源语言偏见。为了实现无偏倚的UD特征转移,我们构建了一种基于代码混合的UD森林,首先将源语言句子翻译成目标语言,并分别解析出源语言和目标语言的UD树,然后合并源语言和目标语言的UD结构形成一个统一的代码混合UD森林。实验证明,代码混合UD森林可以有效消除UD特征在训练和预测阶段之间的差距,有助于实现无偏倚的UD特征转移,从而显著提高XRE的性能。
动机:
目标语言偏见(Target-biased):当源语言训练好的模型直接用于目标语言时,模型可能无法很好地处理目标语言的语法特征,导致模型表现不佳。
源语言偏见(Source-biased):直接合成目标语言的数据进行训练,可能导致模型忽略了源语言中有效的语法特征,从而影响模型的表现。
因此,消除目标语言偏见和源语言偏见对于实现有效的跨语言关系提取具有重要意义。本文提出的代码混合的UD森林方法,通过融合源语言和目标语言的语法特征,有助于消除这种偏见,实现无偏倚的跨语言关系提取。
方法:
- 源语言句子到目标语言句子的翻译:使用机器翻译系统将源语言句子翻译成目标语言句子,形成源语言-目标语言平行句子对。
- 获取词对齐分数:使用词对齐工具获得源语言和目标语言句子之间的词对齐分数。
- 解析UD树:分别使用源语言和目标语言的UD解析器解析源语言句子和目标语言句子的UD树。
- 投影和合并训练数据标签:将源语言训练数据的标签投影到目标语言伪句子,合并源语言和目标语言的标签形成代码混合的标签。
- 构建代码混合的UD森林:基于源语言和目标语言的UD树,采用广度优先遍历的方法构建代码混合的UD森林。对齐的节点进行合并,非对齐的节点进行复制。
- 组装代码混合文本:基于源语言文本和目标语言伪句子,构建代码混合文本,用于模型输入。
- 编码代码混合的UD森林:使用图注意力网络(GAT)对代码混合的UD森林进行编码。
- 关系提取模型训练和预测:使用源语言训练数据训练关系提取模型,在目标语言预测时使用目标语言句子和编码后的代码混合的UD森林。
转移范例:标签,参数转移
转移资源:Machine translation,Word alignments,Universal features(通用依存解析),
评估语言:英语(EN)、中文(ZH)和阿拉伯语(AR)
评估数据集:ACE05

 浙公网安备 33010602011771号
浙公网安备 33010602011771号