《别让数据坑了你!用置信学习找出错误标注》作者:JayLou娄杰。置信学习/带噪学习
原文链接:https://mp.weixin.qq.com/s/svo0_mJ0RwOUA7hgc0doCw
论文链接:https://arxiv.org/abs/1911.00068
带噪学习:https://github.com/subeeshvasu/Awesome-Learning-with-Label-Noise
开源工具:https://github.com/cgnorthcutt/cleanlab
错误标注很普遍,如下图所示,QuickDraw、MNIST和Amazon Reviews数据集中就存在错误标注。


置信学习三个步骤:
- Count:估计噪声标签和真实标签的联合分布;
- Clean:找出并过滤掉错误样本;
- Re-Training:过滤错误样本后,重新调整样本类别权重,重新训练;
Count包括四步骤:
- 交叉验证
- 得到n个样本,m个类别的n*m的矩阵
- 统计每个人工标定类别j的平均概率tj作为置信度阈值
- 计算每个样本真实类别,最大概率pij且pij大于tj
- 计算计数矩阵(类似混淆矩阵)
- 标定计数矩阵,让计数矩阵的总和与数据总量相同
- 估计噪声标签和真实标签的联合分布,也就是将计数矩阵归一化得到Q
Clean有4种方法:
- 过滤最大pij和人工标记不一致的数据;
- 过滤计数矩阵中非对角单元的样本;
- 对于类别c,选取n*p个样本过滤,其中p是联合分布矩阵中除Q(c,c)之外的概率和;
- 对于计数矩阵非对角单元,选取n*p个样本过滤,p是联合分布矩阵中计数矩阵的单元对应的概率;
Re-Training
- 根据Q修正loss权重
- 采取Co-Teaching框架
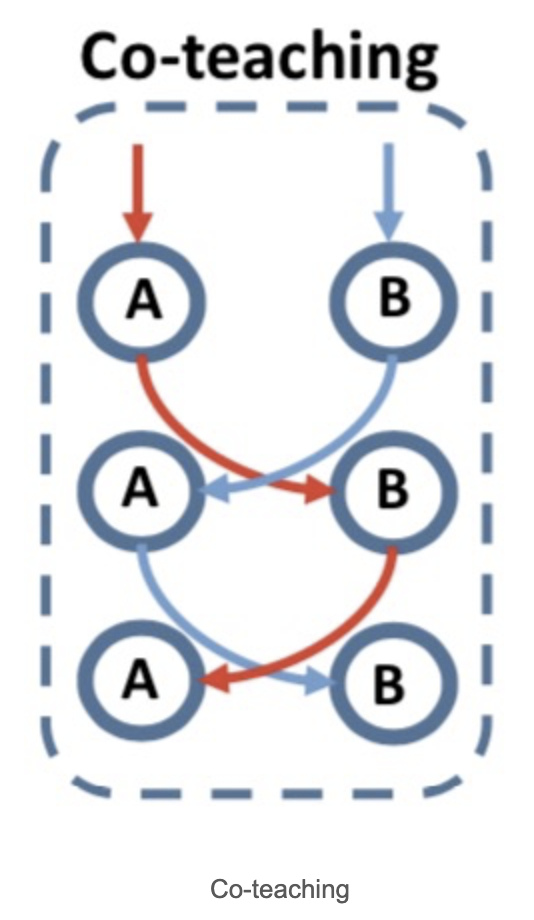
本方法和置信学习中的SOTA方法Mentornet相比,噪声数据占比40%时,多组实验平均提升34%。

找我内推: 字节跳动各种岗位
作者:
ZH奶酪(张贺)
邮箱:
cheesezh@qq.com
出处:
http://www.cnblogs.com/CheeseZH/
*
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号